本文主要是介绍人工智能中两个较为常见的评估模型性能指标(EVS、MAE),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、解释方差(EVS)
官方社区链接:sklearn.metrics.explained_variance_score-scikit-learn中文社区
explained_variance_score是一个用于评估回归模型性能的指标,它衡量的是模型预测值与实际值之间关系的密切程度。具体来说,解释方差分数表示模型预测值中有多少方差可以通过实际数据的方差来解释。
解释方差(Explained Variance)的计算公式如下:
![]()
其中:
- y 是观测值的真实目标变量(即测试集中的标签)。
-
是模型预测的目标变量。
该指标的取值范围从 0 到 1。
值越接近 1,表示模型的预测值与实际值之间的差异越小,模型的解释能力越强,即模型能够更好地捕捉数据中的变异性。
在 scikit-learn 中,explained_variance_score 函数的使用方法如下:
from sklearn.metrics import explained_variance_score# 真实目标值数组
y_true = [1,2,31,34,2]
# 模型预测的目标值数组
y_pred = [1,2,30,34,4]# 计算解释方差分数
explained_variance = explained_variance_score(y_true, y_pred)
print(explained_variance)这个函数会返回一个介于 0 和 1 之间的浮点数,表示模型的解释方差分数。
总结一下,越接近于1预测的越牛逼,越接近于0越完蛋。
2、平均绝对误差(MAE)
mean_absolute_error 是一个用于评估回归模型性能的指标,它衡量的是模型预测值与实际值之间差异的平均大小。平均绝对误差(Mean Absolute Error, MAE)是所有数据点的绝对误差之和除以数据点的总数。
平均绝对误差的计算公式如下:
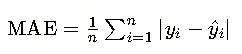
其中:
- n 是数据点的总数。
- yi 是第 i 个观测值的真实目标变量。
是第 i 个观测值的模型预测目标变量。
MAE 指标的值越小越好,它能够量化模型预测的准确度。由于它是绝对误差的平均,所以对异常值(outliers)的影响比均方误差(MSE)小。
在 scikit-learn 中,mean_absolute_error 函数的使用方法如下:
from sklearn.metrics import mean_absolute_error# 真实目标值数组
y_true = [1,2,31,34,2]
# 模型预测的目标值数组
y_pred = [1,2,30,34,4]# 计算平均绝对误差
mae = mean_absolute_error(y_true, y_pred)
print(mae)这个函数会返回一个浮点数,表示模型的平均绝对误差;
当预测值,和初始值相同时,结果为 0 ,也就是最小值为 0 ;
但是两者之间的差距可以无限大,所以最大值无上限。
这篇关于人工智能中两个较为常见的评估模型性能指标(EVS、MAE)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









