评估专题

PR曲线——一个更敏感的性能评估工具
在不均衡数据集的情况下,精确率-召回率(Precision-Recall, PR)曲线是一种非常有用的工具,因为它提供了比传统的ROC曲线更准确的性能评估。以下是PR曲线在不均衡数据情况下的一些作用: 关注少数类:在不均衡数据集中,少数类的样本数量远少于多数类。PR曲线通过关注少数类(通常是正类)的性能来弥补这一点,因为它直接评估模型在识别正类方面的能力。 精确率与召回率的平衡:精确率(Pr
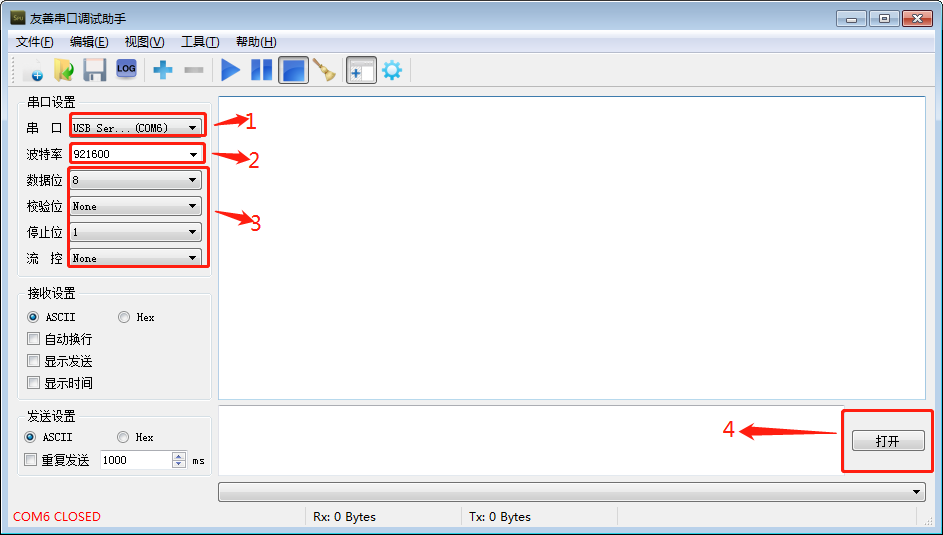
安卓开发板_联发科MTK开发评估套件串口调试
串口调试 如果正在进行lk(little kernel ) 或内核开发,USB 串口适配器( USB 转串口 TTL 适配器的简称)对于检查系统启动日志非常有用,特别是在没有图形桌面显示的情况下。 1.选购适配器 常用的许多 USB 转串口的适配器,按芯片来分,有以下几种: CH340PL2303CP2104FT232 一般来说,采用 CH340 芯片的适配器,性能比较稳定,价
随着人们网络安全意识提高,软件架构设计与评估也成为重中之重
目录 案例 【题目】 【问题 1】(13 分) 【问题 2】(12分) 【答案】 【问题 1】答案 【问题 2】答案 相关推荐 案例 阅读以下关于软件架构设计与评估的叙述,回答问题 1 和问题 2。 【题目】 某电子商务公司为正更好地管理用户,提升企业销售业绩,拟开发一套用户管理系统。该系统的基本功能是根据用户的消费级别、消费历史、信

基于yolov8的包装盒纸板破损缺陷测系统python源码+onnx模型+评估指标曲线+精美GUI界面
【算法介绍】 基于YOLOv8的包装盒纸板破损缺陷检测系统是一种高效、智能的解决方案,旨在提高生产线上包装盒纸板的质量检测效率与准确性。该系统利用YOLOv8这一前沿的深度学习模型,通过其强大的目标检测能力,能够实时识别并标记出包装盒纸板上的各种破损缺陷,如划痕、撕裂、孔洞等。 在系统中,首先需对包含破损缺陷的包装盒纸板图像进行数据采集和标注,形成训练数据集。随后,利用这些数据进行模型训练,使

数据安全评估工程师CCRC-DSA怎么考?
数据安全评估工程师的职责涉及对数据安全风险进行专业评估。 他们通过深入分析企业的数据资产,识别潜在风险,并设计相应的防范措施。 此岗位要求从业者具备深厚的计算机科学与网络安全专业知识以及丰富的实践经历。 对于想要成为数据安全评估工程师的人来说,基本条件包括:1. 教育背景:通常需要本科以上学历,以计算机科学、信息安全或网络工程等相关专业为佳。 2. 技能水平:必须掌握操作系统、数据库、

基于yolov8的NEU-DET钢材缺陷检测系统python源码+onnx模型+评估指标曲线+精美GUI界面
【算法介绍】 基于YOLOv8的NEU-DET钢材缺陷检测系统是一种创新的解决方案,旨在通过深度学习技术实现对钢材表面缺陷的自动检测和识别。该系统利用YOLOv8算法,该算法以其高效、准确和实时检测的特点著称。 NEU-DET数据集为该系统提供了丰富的训练资源,涵盖了热轧带钢的六种典型表面缺陷,包括轧制氧化皮、斑块、开裂、点蚀表面、内含物和划痕,每种缺陷均有大量样本,确保了模型的全面性和准确性

IMU腕带评估轮椅用户运动健康
近期,美国的研究团队利用惯性测量单元(IMU)和机器学习来准确评估手动轮椅使用者的运动健康状况,这在康复训练和慢性病管理领域具有广阔的应用前景。 研究小组将运用高性能的IMU传感器固定到轮椅使用者佩戴的手腕带上,用来监测并记录轮椅推进过程中的运动数据。实验设置了不同强度的六分钟推力测试,结果证实仅使用IMU传感器就能准确捕捉到轮椅使用者的速度、距离和节奏变化,为心血管健康评估提供

基于yolov8的电动车佩戴头盔检测系统python源码+onnx模型+评估指标曲线+精美GUI界面
【算法介绍】 基于YOLOv8的电动车佩戴头盔检测系统利用了YOLOv8这一先进的目标检测模型,旨在提高电动车骑行者的安全意识,减少因未佩戴头盔而导致的交通事故风险。YOLOv8作为YOLO系列的最新版本,在检测速度和精度上均进行了优化,特别适用于处理复杂场景中的小目标检测。 该系统通过收集并标注包含电动车骑行者图像的数据集,对YOLOv8模型进行训练,使其能够准确识别骑行者是否佩戴头盔。在实

基于yolov8的西红柿缺陷检测系统python源码+onnx模型+评估指标曲线+精美GUI界面
【算法介绍】 基于YOLOv8的西红柿缺陷检测系统是一个利用深度学习技术的创新项目,旨在通过自动化和智能化的方式提高西红柿缺陷检测的准确性和效率。该系统利用YOLOv8目标检测算法,该算法以其高效性和准确性在目标检测领域表现出色。YOLOv8不仅继承了YOLO系列模型的优势,还引入了新的骨干网络、Anchor-Free检测头以及优化后的损失函数,这些改进使得模型在复杂环境下的检测性能更加优越。
PMF源解析软件下载、安装、运行;Fpeak模式运行结果优化及误差评估;大气颗粒物理化性质等基础知识和通过PMF方法对其来源解析
目录 专题一 PMF源解析技术简要及其输入文件准备 专题二 PMF源解析技术的原理,PMF软件的实操及应用举例 专题三 PMF源解析结果的优化及误差评估 更多应用 颗粒物污染不仅对气候和环境有重要影响,而且对人体健康有严重损害,尤其在一些重污染天气,如灰霾和沙尘暴等。为了高效、精准地治理区域大气颗粒物污染,首先需要了解颗粒物的来源。因此,颗粒物源解析成为目前解决大气颗粒物污染的关键技

基于yolov5的西红柿成熟度检测系统python源码+onnx模型+评估指标曲线+精美GUI界面
【算法介绍】 基于YOLOv5的西红柿成熟度检测系统是一个利用先进深度学习技术的创新项目,旨在提高西红柿成熟度检测的准确性和效率。该系统以YOLOv5为核心算法,该算法由Ultralytics公司于2020年发布,并在YOLOv3的基础上进行了显著改进。YOLOv5以其高效性和准确性在实时目标检测领域备受关注,特别适用于农业视觉检测任务。 该系统通过收集并预处理大量不同成熟度的西红柿图像数据,

论文速读|重新审视奖励设计与评估:用于强健人型机器人站立与行走控制的方法
论文地址:https://arxiv.org/pdf/2404.19173 这篇论文为类人机器人站立和行走(SaW)控制器的持续可衡量改进奠定了基础。通过引入一套定量实际基准测试方法,作者展示了现有控制器的优缺点,并通过基准测试指导新控制器的训练,最终实现了增强的控制器,成功处理了所有测试的扰动。结果表明,当前的RL控制器在能量效率和仿真到现实差距方面存在局限性。未来的工作应专注于在不牺牲

基于yolov8的水面垃圾水面漂浮物检测系统python源码+onnx模型+评估指标曲线+精美GUI界面
【算法介绍】 基于YOLOv8的水面垃圾与漂浮物检测系统是一种高效、智能的监测解决方案。该系统利用YOLOv8这一前沿的深度学习模型,结合智能视频分析技术,对河道、湖泊等水面的垃圾漂浮物进行实时监测与识别。 YOLOv8作为YOLO系列的最新迭代,以其高准确度和实时检测能力著称。通过复杂的网络架构、优化的训练流程和强大的特征提取能力,YOLOv8能够在各种光照和水质条件下,准确识别包括生活垃圾

2.6 大模型数据基础:大模型评估数据详解
本系列目录 《带你自学大语言模型》系列部分目录及计划,完整版目录见:带你自学大语言模型系列 —— 前言 第一部分 走进大语言模型(科普向) 第一章 走进大语言模型 1.1 从图灵机到GPT,人工智能经历了什么?——《带你自学大语言模型》系列 1.2 如何让机器说人话?万字长文回顾自然语言处理(NLP)的前世今生 —— 《带你自学大语言模型》系列 第二部分 构建大语言模型(技术向)

PyTorch Demo-2 : 分类模型评估
1. 预训练模型加载和预测 1.1 加载预训练参数 根据训练函数中保存的训练参数,使用 torch.load() 进行读取,再加载 model.load_state_dict() 。 def load_pretrained_model(model, path):"""Load the pretrained model:param model: the defined model:param

大模型备案重难点最详细说明【评估测试题+附件】
2024年3月1日,我国通过了《生成式人工智能服务安全基本要求》(以下简称《AIGC安全要求》),这是目前我国第一部有关AIGC服务安全性方面的技术性指导文件,对语料安全、模型安全、安全措施、词库/题库要求、安全评估等方面提出了具体规范和要求。 (一)适用主体 《AIGC安全要求》的适用主体包括两类: 1. 生成式人工智能服务 定义:利用生成式人工智能技术向中华人民共和国境内公众提供生成文

基于yolov8的路面垃圾检测系统python源码+onnx模型+评估指标曲线+精美GUI界面
【算法介绍】 基于YOLOv8的路面垃圾检测系统是一种利用深度学习技术实现的高效、精准的路面垃圾检测解决方案。该系统采用了YOLOv8目标检测算法,该算法在速度和精度上均表现出色,能够实时或近实时地检测路面上的垃圾。 系统通过训练YOLOv8模型,使其能够识别并定位多种类型的路面垃圾,如塑料袋、纸屑等。在实际应用中,系统可以支持图片、视频以及摄像头的输入,通过界面实时显示目标位置、检测结果、和

语言质量评估对欧洲游戏推广的重要性
语言质量评估在欧洲推广游戏中的重要性怎么强调都不为过。欧洲是一个文化和语言多样化的市场,整个大陆有200多种语言。因此,要提供一款与不同地区玩家产生共鸣的本地化游戏,不仅需要准确的翻译,还需要细致的语言质量评估。这一过程对于确保游戏吸引当地观众、保持其初衷并提供无缝和身临其境的体验至关重要。 语言质量评估包括评估翻译内容的准确性、流畅性和文化相关性。对于瞄准欧洲市场的游戏开发商和发行商来说,

基于yolov5的猪只识别计数检测系统python源码+onnx模型+评估指标曲线+精美GUI界面
【算法介绍】 基于YOLOv5的猪只识别计数检测系统是一种创新的农业应用解决方案,它结合了深度学习和计算机视觉技术,专为提高养猪业的管理效率和精确度而设计。该系统利用YOLOv5这一先进的目标检测模型,能够实时、准确地在图像或视频中识别并计数猪只。 YOLOv5以其轻量级、高速和准确的特点著称,特别适合用于复杂多变的农场环境。通过摄像头采集的图像数据,系统能够自动检测并标记出每一头猪的位置和数

基于yolov5的煤矿传送带异物检测系统python源码+onnx模型+评估指标曲线+精美GUI界面
【算法介绍】 基于YOLOv5的煤矿传送带异物检测系统是一种高效、智能的监测解决方案,专为煤矿等复杂工业环境设计。该系统利用YOLOv5深度学习算法,结合现场摄像头,对煤矿传送带上的异物进行实时监测与识别。 YOLOv5以其出色的检测速度和准确性著称,通过将原始图像划分为多个网格,并在每个网格中预测可能的目标边界框,实现对传送带上大块煤、矸石、锚杆、槽钢等异物的快速识别。系统能够自动区分正常物

基于智能巡检机器人的算力评估指标及其应用场景分析
随着工业自动化和智能化的发展,智能巡检机器人在各类复杂环境中的应用日益广泛。机器人通常需要在复杂、多变的环境中自主执行任务,如设备检测、数据采集、故障诊断等。为了确保巡检机器人的高效运行,计算能力(算力)的评估和优化显得尤为重要。 智能巡检机器人概述 智能巡检机器人是一类能够在无人干预下自动执行巡检任务的机器人系统,广泛应用于工业自动化领域。巡检机器人配备了多种传感器和

在keras中使用tensorflow自带的评估标准
在keras中使用tensorflow自带的标准 Metrics是衡量一个神经网络性能的重要指标,然而在keras环境下,仅有有限个评估标准可以使用。Tensorflow自带了很多的评估标准,因此就产生了一个问题,能否在keras中使用tensorflow自带的评估标准? 多的不说,直接上代码! // 首先将tensorflow的函数封装成为keras下的函数def as_k

系统架构师考试学习笔记第三篇——架构设计高级知识(10)系统质量属性与架构评估
本章知识点: 第10课时主要学习软件系统质量属性、系统架构评估以及ATAM方法评估实践等内容。 本课时内容侧重于概念知识,根据以往全国计算机技术与软件专业技术资格(水平)。考试的出题规律,考查的知识点多来源于教材,扩展内容较少。根据考试大纲,本课时知识点会涉及单项选择题(约占8~15分)和下午案例题(25分),论文也会有覆盖。本课时知识架构如图10.1所示。

命名实体识别(NER)-模型评估:词级别评估、实体级别评估【Precision、Recall、F1】
一、概述 命名实体识别的评判标准:实体的边界是否正确;实体的类型是否标注正确。主要错误类型包括: 文本正确,类型可能错误;反之,文本边界错误,而其包含的主要实体词和词类标记可能正确。 对于二分类的模型,预测结果与实际结果分别可以取0和1。我们用N和P代替0和1,T和F表示预测正确和错误。将他们两两组合,就形成了下图所示的混淆矩阵(注意:组合结果都是针对预测结果而言的)。 由于1和0是数字

从一到无穷大 #34 从Columnar Storage Formats评估到时序存储格式的设计权衡
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。 文章目录 引言Parquet / ORC功能与结构对比差异Indexes and Filters压缩影响 TsFile总结 引言 随着 Parquet,ORC,TsFile等开源存储格式的发展,各家时序厂商的压缩

基于yolov5的明厨亮灶阳光厨房老鼠检测系统python源码+onnx模型+评估指标曲线+精美GUI界面
【算法介绍】 基于YOLOv5的明厨亮灶阳光厨房老鼠检测系统是一种高效、智能的食品安全监测解决方案。该系统利用YOLOv5网络模型,结合深度学习技术,实现对厨房环境的实时监控与智能分析。 YOLOv5以其高速和高精度的特性,在实时目标检测任务中表现出色。该系统通过安装在前端的智能摄像头,实时采集厨房画面,并利用YOLOv5算法对视频流中的图像进行快速处理。一旦检测到老鼠生物,系统会立即检测到相