本文主要是介绍大模型备案重难点最详细说明【评估测试题+附件】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2024年3月1日,我国通过了《生成式人工智能服务安全基本要求》(以下简称《AIGC安全要求》),这是目前我国第一部有关AIGC服务安全性方面的技术性指导文件,对语料安全、模型安全、安全措施、词库/题库要求、安全评估等方面提出了具体规范和要求。
(一)适用主体
《AIGC安全要求》的适用主体包括两类:
1. 生成式人工智能服务
定义:利用生成式人工智能技术向中华人民共和国境内公众提供生成文本、图片、音频、视频等内容的服务。
其中,需要特别关注,如何认定“向境内提供服务”的范围。根据企业的实务场景,我们理解需要“从宽”去定义上述概念,包括网页端的地区选项设置有“中国”的选项、网页或产品说明提供中文选项、支付方式包含有支付宝、微信选项、注册方式允许中国手机号码等,都可能会被认定为向中国境内提供服务。
2. 服务提供者
定义:以交互界面、可编程接口等形式提供生成式人工智能服务的组织或个人。
根据《AIGC安全要求》,个人也可成为监管对象。只要是以交互界面、可编程接口等形式提供服务,无论是组织还是个人,都符合“服务提供者”的定义。

(二)语料安全
《AIGC安全要求》针对语料安全,在语料来源授权合法、安全评估核验、不良语料类型三个方面提出了重点要求,具体要求包括:
1. 授权合法
语料的来源需要有合法的、明确的授权,确保其符合“授权、同意、告知”的合法性原则。根据语料的来源属性分类,具体的要求梳理如下:
| 语料来源 | 含义 | 合规要求 |
| 开源语料 | 是训练数据的主要来源,指开放的,任何人得以获取的语料 | 应具有该语料来源的开源许可协议或相关授权文件,建议重点关注: (a)Robots协议; (b)协议明确“个人已拒绝授权采集的个人信息”。 |
| 自采语料 | 是指自行生产或直接从互联网采集的语料 | 应具有采集记录,不应采集他人已明确不可采集的语料 |
| 商业语料 | 是自采语料的对应概念,指通过与第三方语料提供方进行交易获得的语料 | 应有具备法律效力的交易合同、合作协议等,且当交易方或合作方不能提供语料来源、质量、安全等方面的承诺以及相关证明材料时,不应使用该语料,这就要求相关方对交易方或合作方所提供的语料、承诺、材料进行审核 |
| 使用者输入语料 | 是指将使用者输入的信息作为语料 | 应具有使用者授权记录 |
2. 安全评估与核验
对于采集的语料,需要严格控制违法不良信息的比率。语料采集前,需要进行针对违法不良信息进行安全评估,采集后输入语料库之后需要进行再次核验。
具体而言,如采集前评估得出违法不良信息超过5%,则该来源不得被采集;如若采集后核验违法不良信息超过5%,则该来源不得被使用。虽然两步走的设置看似天衣无缝,但从部分企业的尽调结果来看,相应管控和筛查的工作目前仍未到位。语料安全作为生产资料的重要组成部分,评估不当很可能导致紧随其后的产品研发环节就出现问题。
除此以外,还需要遵循在内容过滤、知识产权、个人信息、标注安全等方面的合规要求:

*图示:语料来源合规要求
因此,企业需要在首次安全评估之后保持对语料来源的持续敏感度。并在之后的操作处理中进行持续性的内容过滤,采取关键词、分类模型、人工抽检等方式过滤违法不良信息。对于涉及知识产权和个人信息的语料,还应当设置专门的负责人和管理策略,在使用之前注意该语料是否存在侵犯他人权利的情况,并与相关方提前协商,告知有关风险或取得其授权同意,并取得正式性的记录文件;要求语料提供方提供语料来源、质量安全等承诺以及相关证明材料并进行审核。
3. 不良语料类型
对于具体需要规避的语料类型,《AIGC安全要求》附录A列举了涉及语料及生成内容安全的类型,共分为5类31种,制定了特别的安全需求:
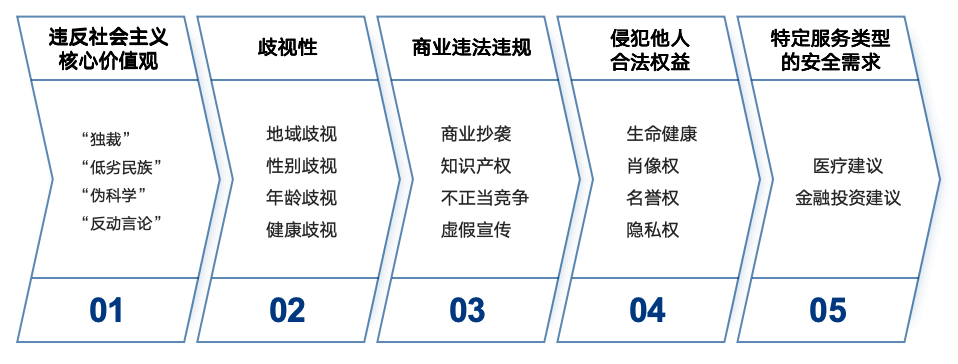
*图示:不良语料类型
需要特别关注的是,本次不良语料类型特别提出了针对“特定服务类型”的安全需求。
例如,针对医疗建议类的算法和问答建议,当前不少医疗健康产品和服务当中,开发了智能健康管家等功能,涉及根据用户的健康分析报告,提出对应的诊疗分析、用药建议等,对于这一类功能,需要特别谨慎对待其是否可能出现非专业性、误导性的用药和诊断结论,否则可能导致“无病呻吟”或“病急乱投医”的情况。
例如,针对金融投资建议类的算法和分析建议,需要遵循银行、保险、金融等方面对于投资者、投保人的合法权益保护,避免违反相关的监管规定,为了业务竞争而向投资者、投保人等通过AI作出涉及不正当竞争、违反金融风险管控的分析或违规引导。
(三)模型安全
除语料安全外,模型安全也是AIGC服务或服务提供者应当考虑的重要因素。提供者不仅应当在其服务过程中,提供安全、稳定、持续的服务,保障用户的正常使用;如若需要基于第三方基础模型提供服务,提供者还必须使用已经主管部门备案的基础模型。
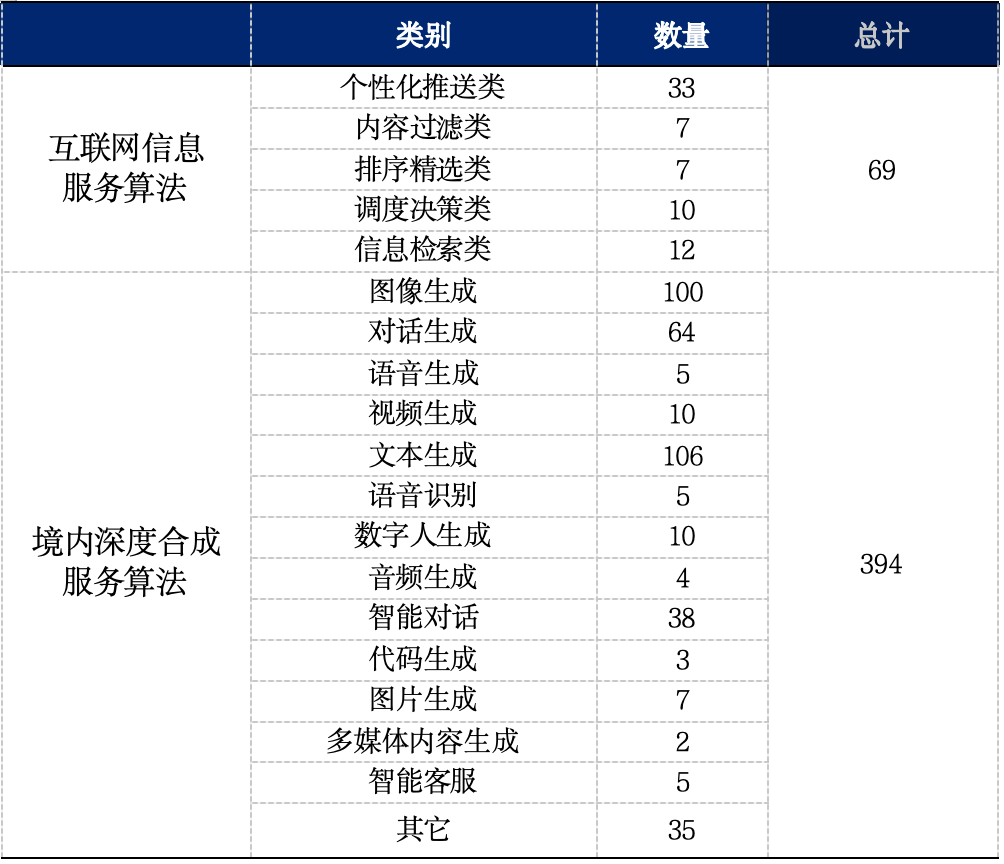
*统计:截至2024年5月通过网信办备案的算法模型情况
而针对AIGC模型产出的内容,也应从内容的安全性、准确性和可靠性三个角度予以关注:
首先在安全性方面,《AIGC安全要求》规定应当对每次对话使用者输入的信息进行安全性检测,引导模型生成积极正向内容,并建立常态化检测测评手段,针对发现的安全问题及时整改;其次,在准确性方面,应采取技术措施提高生成内容响应使用者输入意图的能力,以及生成内容与科学常识和主流认知的符合程度;最后,在可靠性方面,也应采取技术措施提高生成内容格式框架的合理性和有效内容含量。
(四)安全措施要求
在适用模型和输出内容的过程中,AIGC相关主体还应当满足《AIGC安全要求》对于“模型适用安全措施”的规定,及时建立起与技术安全要求配套的技术措施、管理措施和相应保护措施。

1. Opt-out功能
其中,需要重点关注的是“Opt-out”机制的建立要求。不同于我国目前一般采用的“Opt-in”机制(即用户自主选择是否提供信息,不得默认设置为提供),当前在AIGC的信息输入节点,仅要求提供显著的、便捷的供使用者关闭信息输入的路径即可,需要保障使用者可以随时方便关闭信息输入的功能。
2. 供应链安全
在全球化的贸易背景下,包括GPU芯片在内的半导体技术已成为科技领域的核心竞争力。GPU芯片涉及AI模型训练、数据中心、智能交通、游戏等多个下游行业,这些芯片根据应用场景又细分为云端芯片和终端芯片,其中终端芯片广泛应用于嵌入式系统、移动设备、智能制造和家居智能等细分领域。
因此,在《AIGC安全要求》中,重点突出了芯片、软件、工具、算力等方面在供应链安全方面的合规要求,也是对于中国企业在采购、研发、使用、出口相关服务和产品的同时,需要从业务连续性、稳定性的角度,做好对供应链方面的风险排查,避免因对于业务所在国家地区管制规则要求的不熟悉而引发市场准入,甚至是直接影响业务的风险。
(五)词库要求
《AIGC安全要求》在词库方面要求设立关键词库、生成内容测试题库、拒答测试题库和分类模型等。其中,关键词库的总规模不少于10000个关键词,且关键词库应至少覆盖《AIGC安全要求》附录A.1以及A.2中的17种安全风险,附录A.1中每一种安全风险的关键词均不宜少于200个,附录A.2中每一种安全风险的关键词均不宜少于100个。这些模型对于语料内容过滤,生成内容安全评估等,应完整覆盖本文件附录A中全部31种安全风险。
(六)安全评估要求
针对最后一项安全评估要求,《AIGC安全要求》第九章内容对评估的方法、语料评估、生成内容评估和问题解答评估都作出了规定,这也是对于《AIGC暂行办法》的细化。
评估方法论层面,可以由服务提供者自行开展,也可委托给第三方评估机构;对于符合的评估结果应保存充分的证明材料,对于不符合的应说明不符合或不适用的原因并对后续改进措施进行计划说明;对于最后形成的评估报告,除了应有各项和总项的结论之外,还应有3位以上负责人签字。
而对于细化层面的安全评估,《AIGC安全要求》确立了如要求语料安全评估的人工抽检和技术抽检的标准,生成内容安全评估的人工抽检、关键词抽检和分类模型抽检的标准,以及问题拒答评估的应拒答测试题库和非拒答测试题库的标准等。
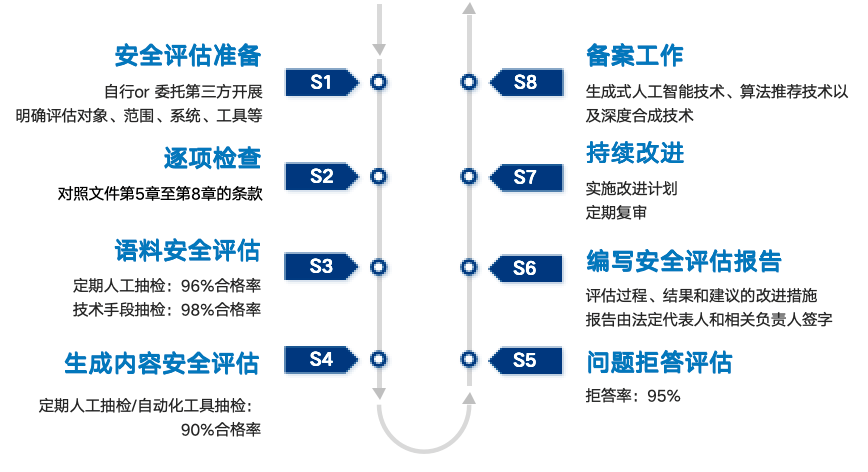
*图示:AIGC安全评估要求




这篇关于大模型备案重难点最详细说明【评估测试题+附件】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







