localization专题

【论文阅读】Single-Stage Visual Query Localization in Egocentric Videos
paper: code: 简介: 长篇自我中心视频的视觉查询定位需要时空搜索和指定对象的定位。之前的工作开发了复杂的多级管道,利用完善的对象检测和跟踪方法来执行 VQL(视觉查询定位)。然而,每个阶段都是独立训练的,管道的复杂性导致推理速度缓慢。我们提出了 VQLoC,这是一种新颖的单阶段 VQL 框架,可进行端到端训练。我们的关键思想是首先建立对查询视频关系的整体理解,然后以单次方式执行时

论文笔记 DenseCap: Fully Convolutional Localization Networks for Dense Captioning
李飞飞组的文章,是一篇很有意思的文章,主要介绍了一种CNN解决密集字幕任务的方法。密集字幕任务主要含两个方面: (1)单个单词描述的目标检测任务;(2)对整个图像的一个预测区域的字幕标注任务。具体任务需求如下: 文章主要提出了全卷积定位网络(FCLN)架构,无需外部区域的建议,并可以用单轮优化进行端对端的训练。该架构包含一个卷积网络,一个新的密集定位层,一个生成标签序列的递归神经网络的语言

unity开发 --------- NGUI(Localization、UILocalize)
unity开发 --------- NGUI NGUI支持动态加载资源功能。比如语言选择:假如当前语言为中文,当将语言更改为英文时,所有UI上的文字也立即变成了英文。此功能是用Localization和UILocalize两个脚本配合完成的。 Localization中记录多种配置方案,当更改配置方案时,由Localization发送通知,通知各UILocalize更新。 NGU
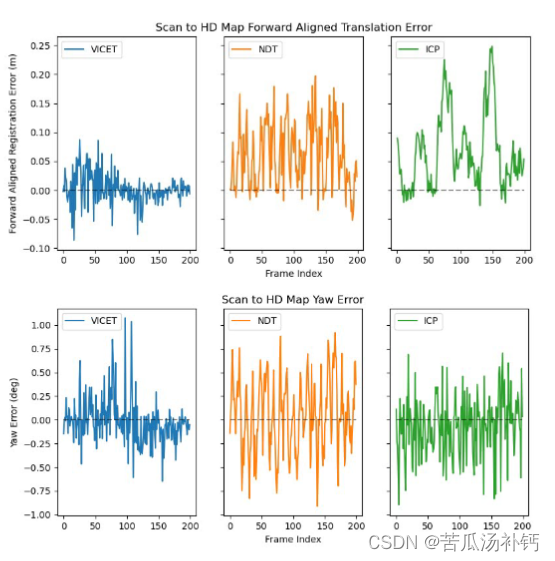
论文阅读:Correcting Motion Distortion for LIDAR HD-Map Localization
目录 概要 Motivation 整体架构流程 技术细节 小结 论文地址:http://arxiv.org/pdf/2308.13694.pdf 代码地址:https://github.com/mcdermatt/VICET 概要 激光雷达的畸变矫正是一个非常重要的工作。由于扫描式激光雷达传感器需要有限的时间来创建点云,所以一次扫描过程中传感器的运动会导致点云发生畸变,这种现
![[深度学习论文笔记]Temporal Localization of Fine-Grained Actions in Videos by Domain Transfer from Web Images](https://img-blog.csdnimg.cn/20190103195855504.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTAxNTg2NTk=,size_16,color_FFFFFF,t_70)
[深度学习论文笔记]Temporal Localization of Fine-Grained Actions in Videos by Domain Transfer from Web Images
[ACM MM 15] Temporal Localization of Fine-Grained Actions in Videos by Domain Transfer from Web Images Chen Sun, Sanketh Shettyy, Rahul Sukthankary and Ram Nevatia from USC & Google paper link Moti

SLAM(Simultaneous Localization and Mapping)技术详解
第一部分:SLAM简介与核心概念 1.1 引言 SLAM(Simultaneous Localization and Mapping),即同时定位与地图构建,是机器人、自动驾驶、增强现实等领域的关键技术之一。它使机器能够在未知环境中自主移动,并构建出周围环境的地图。本文将深入探讨SLAM技术背后的原理,并通过Python代码示例来帮助读者更好地理解。 1.2 核心概念 1.2.1 定位(L

深入理解 YARN Resource Localization
一个Applciation运行在YARN上的流程为,从YARN Client向ResourceManager提交任务,将Applciation所需资源提交到HDFS中,然后ResourceManager启动APPMaster,APPMaster通知各个NodeManager启动container执行具体到计算任务。在启动container之前需要从HDFS上下载该container执行所依赖的资
Large Language Models for Test-Free Fault Localization
基本信息 这是24年2月发表在ICSE `24会议(CCF A)的一篇文章,作者团队来自美国卡内基梅隆大学。 博客创建者 武松 作者 Aidan Z.H. Yang,Claire Le Goues,Ruben Martins,Vincent J. Hellendoorn 标签 软件错误定位、大语言模型、深度学习、神经网络模型 1 摘要 软件错误定位 (Fault Localiza

robot_localization包的使用
robot_localization包没有限制传感器的数据输入。 支持的状态估计节点数据类型: • nav_msgs/Odometry • geometry_msgs/PoseWithCovarianceStamped • geometry_msgs/TwistWithCovarianceStamped • sensor_msgs/Imu 状态向量:[x y z α β γ x˙ y˙ z˙

mageNet Object Localization Challenge
竞争描述 虽然人们很容易辨别出照片中细微的差别,但电脑仍然有办法。视觉上相似的东西很难让电脑计算,就像这堆重叠的香蕉。 或者想想这张照片,一个狐狸家族伪装在野外-狐狸在哪里结束,草在哪里开始? 注释。 由于这种竞争,仅2010年至2014年,图像分类误差就减少了4.2倍(从28.2%降至6.7%),定位误

Adversarial Complementary Learning for Weakly Supervised Object Localization模型解析(基于对抗互补学习的弱监督目标定位)
GitHub - junkwhinger/adversarial_complementary_learning 1.背景: 学习仅使用图像级监督来定位感兴趣的对象的深度模型非常困难 早先处理方式: 根据预先训练的卷积分类网络生成类的定位图,通过用一个全局平均池化层和一个全连接层来替换分类网络的最后几层(AlexNet和VGG-16),从而聚合最后一个卷积层的特征用来生成CAM. 存在的问
Stable Diffusion WebUI 中英文双语插件(sd-webui-bilingual-localization)并解决了不生效的情况
本文收录于《AI绘画从入门到精通》专栏,专栏总目录:点这里。 大家好,我是水滴~~ 本文介绍一款中英文对照插件 sd-webui-bilingual-localization,该插件可以让你的 Stable Diffusion WebUI 界面同时显示中文和英文,让我们方便了使用的同时,也能让我们熟悉原始的英文界面。 安装完插件后,也有存在不生效的情况,本文也给出了解决方案,希望能对你

CAM论文笔记--Learning Deep Features for Discriminative Localization
CAM:Learning Deep Features for Discriminative Localization 背景 论文主要针对图片中不同类别物体定位的弱监督学习问题,提出了基于分类网络的图片识别与定位。 分类网络如VGGnet和Alexnet等基本由卷积操作对图片的特征进行提取,在网络末端使用全连接层进行信息综合和分类。在监督学习中,分类问题需要带类别标签的数据集,定位问题需
robot_localization:使用
转自:https://blog.csdn.net/viphl/article/details/116651921 robot_localization包没有限制传感器的数据输入。 支持的状态估计节点数据类型: • nav_msgs/Odometry • geometry_msgs/PoseWithCovarianceStamped • geometry_msgs/TwistWithCova
![缺陷定位论文阅读:[Dongsun Kim] [TSE在投] DC: A Divide-and-Conquer Approach to IR-based Bug Localization](https://img-blog.csdnimg.cn/20190214112131595.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl8zOTI3ODI2NQ==,size_16,color_FFFFFF,t_70)
缺陷定位论文阅读:[Dongsun Kim] [TSE在投] DC: A Divide-and-Conquer Approach to IR-based Bug Localization
文章目录 前言0 阅读方案1. D&C: A Divide-and-Conquer Approach to IR-based Bug Localization1.1 基本信息1.2 文章内容1.3 几个QA1.4 感想 前言 每天都得阅读一定数量的论文。 在此阅读: 1)D&C: A Divide-and-Conquer Approach to IR-based Bug Lo

文献学习《Past, Present, and Future of Simultaneous Localization And Mapping》
文献学习《Past, Present, and Future of Simultaneous Localization And Mapping: Towards the Robust-Perception Age》 1 Introduction2 现代SLAM系统剖析3 长时间的自治3.1 鲁棒性3.2 可扩展性 4 表示法4.1 度量地图模型4.2 语义地图模型 5 ACTIVE SLAM

Multi-human Fall Detection and Localization in Videos
摘要 背景:深度学习对人类行为和活动识别应用的好处的探索一直存在延迟。在这些领域中,跌倒检测因其出色的公用事业而受到关注。跌倒检测可以在养老院、有公共摄像头的区域和独居老人的家中等设施中实施,因为绝大多数与跌倒有关的死亡发生在这些地点。 目标:YOLO目标检测算法与时间分类模型和卡尔曼滤波跟踪算法相结合,用于检测视频流上的跌倒。 方法:采用本文方法时,需要进行以下步骤:(1)在图像中定位发生
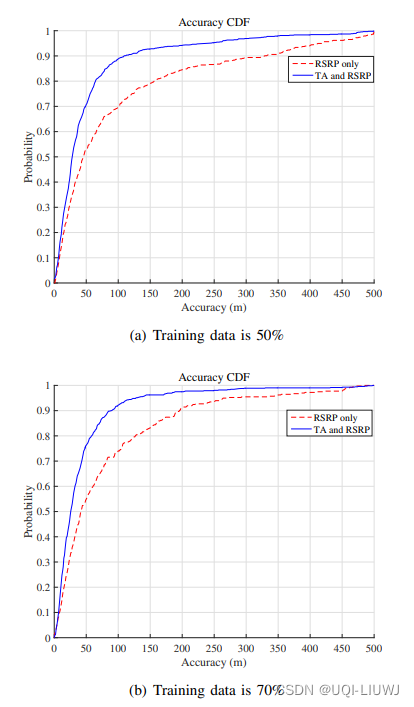
论文笔记:Accurate Localization using LTE Signaling Data
1 intro 论文提出LTELoc,仅使用信令数据实现精准定位 信令数据已经包含在已在LTE系统中,因此这种方法几乎不需要数据获取成本仅使用TA(时序提前)和RSRP【这里单位是瓦】(参考信号接收功率) TA值对应于信号从手机到达基站所需的时间长度 ——>考虑到光速,它相当于用户设备与基站之间的距离在4G LTE网络中,TA值介于0到63之间,每个步骤代表一个比特周期(大约0.5208μs)的

论文阅读:Long-Term Visual Simultaneous Localization and Mapping
论文摘要指出,为了在长期变化的环境中准确进行定位,提出了一种新型的长期视觉SLAM(同步定位与地图构建)系统,该系统具备地图预测和动态物体移除功能。系统首先设计了一个高效的视觉点云匹配算法,将2D像素信息和3D体素信息有效融合。其次,使用贝叶斯持久性过滤器对地图点进行静态、半静态和动态分类,并移除动态点以消除其影响。通过对半静态地图点的时间序列建模,可以获得全局预测地图。最后,将预测的全局地图整合

【Unity 实用工具篇】✨| I2 Localization 实现本地化及多种语言切换,快速上手
前言 【Unity 实用工具篇】| I2 Localization 实现本地化及多种语言切换,快速上手一、多语言本地化插件 I2 Localization1.1 介绍1.2 效果展示1.3 使用说明及下载 二、插件资源简单介绍三、通过示例快速上手3.1 添加 Languages语种3.2 添加 Term资源3.3 静
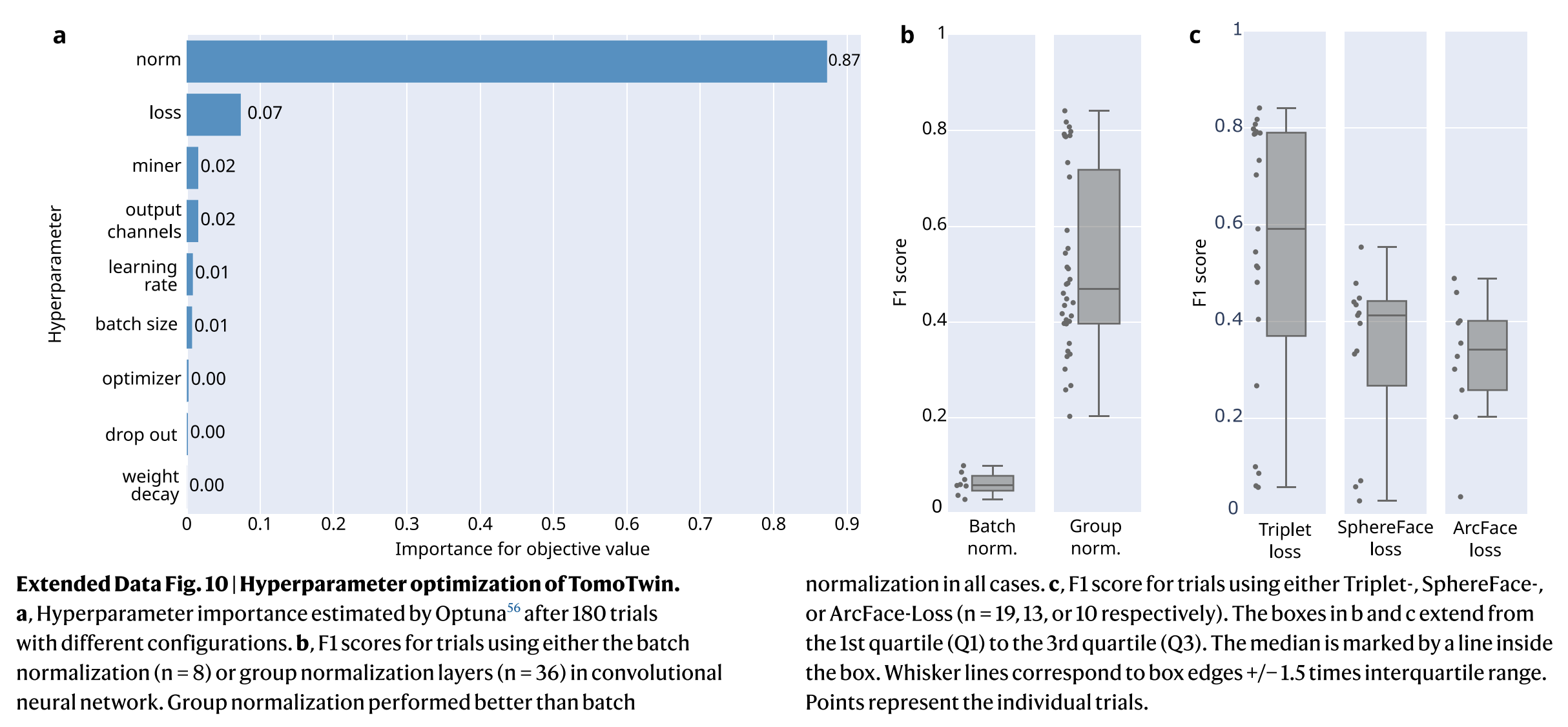
【论文阅读】TomoTwin: generalized 3D localization of macromolecules in cryo-ET with structural data mining
题目 TomoTwin: generalized 3D localization of macromolecules in cryo-electron tomograms with structural data mining 利用结构数据挖掘对冷冻电子断层扫描中的大分子进行广义3D定位 发表期刊:Nature Methods 发表时间:2023.5.15 发表单位:德国多特蒙德马克斯普朗克分

Online_Video Moment Localization via Deep Cross-modal Hashing论文阅读2
膨胀卷积 Dilated Convolution是在标准卷积的Convolution map的基础上注入空洞,以此来增加感受野(reception field)。因此,Dilated Convolution在Standard Convolution的基础上又多了一个超参数(hyper-parameter)称之为膨胀率(dilation rate),该超参数指的是kerne的间隔数量。 论文相
Online_Video Moment Localization via Deep Cross-modal Hashing论文阅读1
这里写目录标题 各类标志局部特征与全局特征Bi-TCN 待补充 各类标志 未修剪的视频集合 代表第k个视频。 对于第k个视频有多少个查询。 对于一个视频的查询集。 由人员标定的,第k个视频,针对查询集的所有目标片段。 第j个目标片段的开始时间和结束时间。 训练好的跨模态哈希网络的出的候选时刻集。 由C3D产生的第k个视频的局部特征集合,Rx是 VEN:

Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation 论文理解
Introduction 目前场景文本检测分为两个分支,第一个分支基于通用对象检测器(SSD,YOLO 和DenseBox ),如TextBoxes ,FCRN 和EAST 等,它们直接预测候选边界框。第二个分支基于语义分割,它们生成分割图并通过后处理生成最终文本框。作者的动机主要来自两个观察结果:1)矩形可以由角点确定,无论矩形的大小,宽高比或方向如何; 2)区域分割图可以提供有效的文本位置信
关于iOS App 国际化和本地化 的一些总结:国际化 vs 本地化(Internationalization vs Localization)
最近项目要实现国际化和本地化,查找了很多资料,发现网上说的都不是很清楚,所以专门开一个帖子,对有用的资料做一个简单地笔记: 我的参考链接: 1,在xcode下Localization 参考: 具体介绍了xcode6下一步步使用新的 .xlffi文件实现本地化的步骤 2,其他用到的工具(genstringsde,xib 、sb的本地化 ),及一些可能的情况处理,可以参考这个帖子。 这里写链
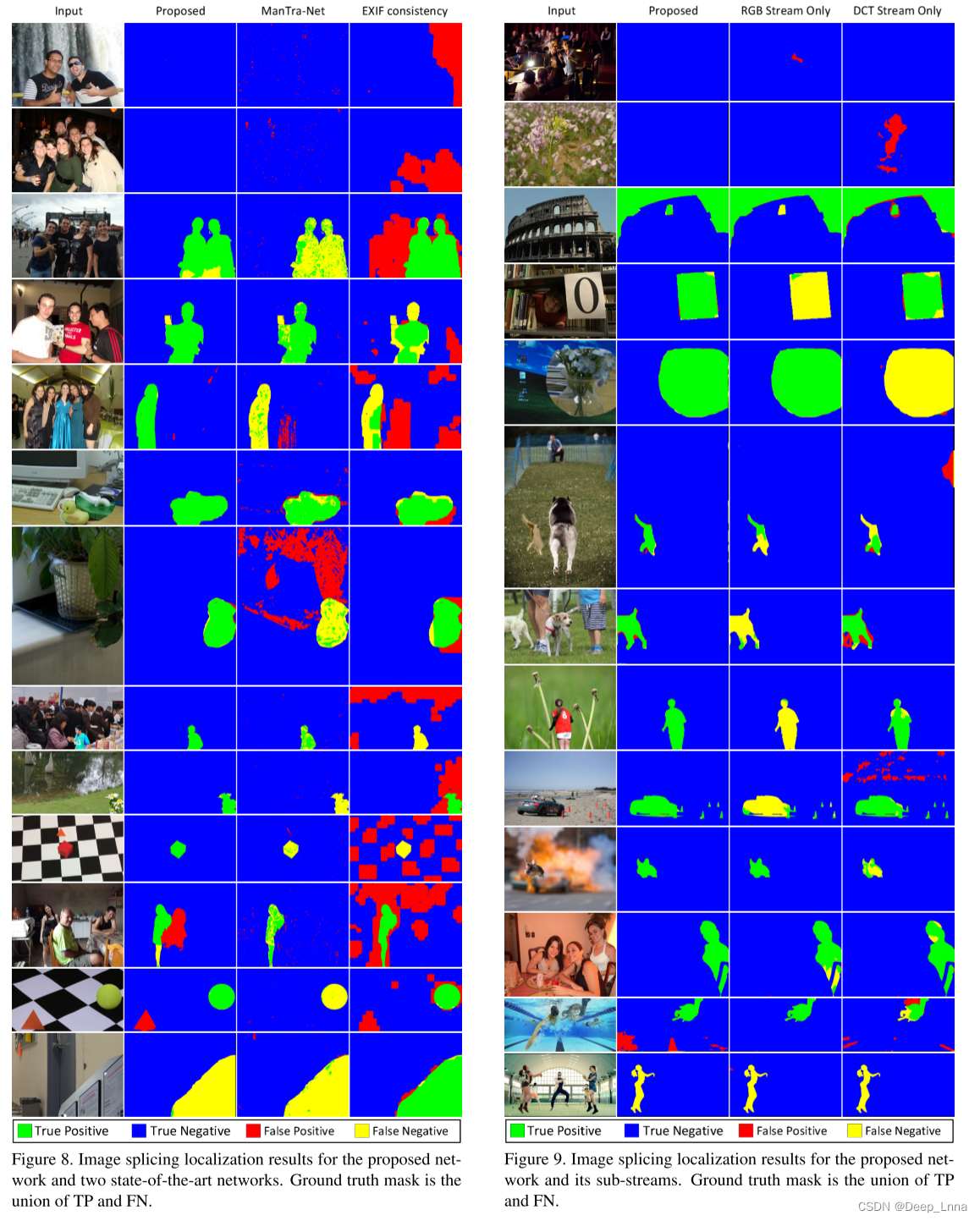
【论文笔记】CAT-Net: Compression Artifact Tracing Network for Detection and Localization of Image Splicing
CAT-Net:用于图像拼接检测和定位的压缩伪迹跟踪网络 发布于WACV2021 代码链接:https://github.com/mjkwon2021/CAT-Net 摘要 检测和定位图像拼接已经成为打击恶意伪造的重要手段。局部拼接区域的一个主要挑战是区分真实和篡改的区域的固有属性,如压缩伪迹。我们提出了CAT-Net,一个包含RGB和DCT流的端到端全卷积神经网络,以共同学习RGB和DCT域