本文主要是介绍【论文笔记】CAT-Net: Compression Artifact Tracing Network for Detection and Localization of Image Splicing,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CAT-Net:用于图像拼接检测和定位的压缩伪迹跟踪网络
发布于WACV2021
代码链接:https://github.com/mjkwon2021/CAT-Net
摘要
检测和定位图像拼接已经成为打击恶意伪造的重要手段。局部拼接区域的一个主要挑战是区分真实和篡改的区域的固有属性,如压缩伪迹。我们提出了CAT-Net,一个包含RGB和DCT流的端到端全卷积神经网络,以共同学习RGB和DCT域压缩伪影的取证特征。每个流考虑多重分辨率来处理拼接对象的各种形状和大小。DCT流在双JPEG检测时被预先训练以利用JPEG伪影。该方法在JPEG或非JPEG图像的局部拼接区域的定位上优于最先进的神经网络。
引言
给定一个可能被拼接的图像(图1©),我们的目标是生成一个掩码来定位可能被篡改的图像部分(图1(d))。为了区分拼接区域和真实区域,重要的是分析相机或图像编辑软件内部处理引起的统计指纹(如传感器图案噪声、彩色滤波器阵列的插值迹、压缩伪影等)。现代数码相机通常压缩图像以减少存储空间,JPEG压缩由于其效率,在大多数情况下被使用。然而,由于信息丢失,这会生成各种JPEG伪迹,尽管它们通常是肉眼不可见的。因此,分析JPEG压缩构件可以帮助定位伪造区域。

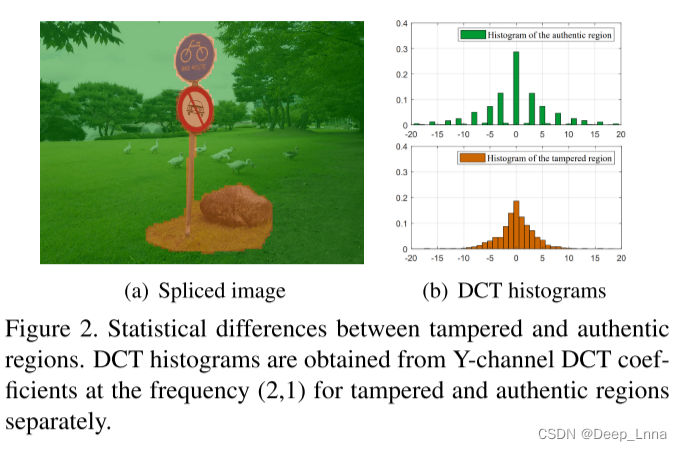
双JPEG检测,即,确定一个JPEG图像是否被压缩了一两次,可以帮助识别拼接伪造。与真实区域相比,拼接到另一幅图像上的区域在y通道上的DCT系数分布可能有统计学上的差异(图2)。真实区域被双重压缩:首先在相机中,然后作为伪造的一部分再次压缩,在直方图中留下周期性的模式。拼接区域的行为类似于单个压缩,位于次级量化表之后。传统上,DCT直方图被用来检测双JPEG压缩。即使在深度学习时代,深度神经网络也倾向于要求将经过预处理的直方图作为输入,因为与像素不同,由于DCT系数去相关性较大,天真地给出DCT系数作为输入通常效果不佳。由于使用直方图,所有这些方法都产生小块预测。因此,我们采用DCT系数的二值体表示来获得像素预测,这最初是为隐写分析设计的。这允许将语义分割网络与双JPEG检测概念相结合,提供像素级预测。
本文提出压缩伪迹跟踪网络(CAT-Net),一种端到端的全卷积神经网络,用于检测和定位拼接区域。该网络包括RGB流、DCT流和最终融合阶段。RGB流学习视觉伪影,DCT流学习压缩伪影(即DCT系数分布)。我们预训练DCT流用于双JPEG检测,并使用它作为拼接定位的初始化。融合阶段融合来自两个流的多个分辨率特征,生成最终的掩模。
主要贡献
- CAT-Net首次结合RGB和DCT域对拼接对象进行局部定位。使用不同基准数据集进行的大量实验表明,与基线相比,CAT-Net取得了最先进的性能,并且对于JPEG和非JPEG图像具有稳定的性能。
- 设计了DCT流来学习压缩伪迹,这些伪迹是基于DCT系数的二进制体积表示来跟踪双压缩线索的。在检测双JPEG压缩方面,该方法优于使用直方图表示的最先进的网络。
相关工作
图像伪造定位方法可分为分块分类、补丁匹配和端到端神经网络方法。
按块分类发现了使用每个块分类进行特定操作的伪造分布,例如双重JPEG压缩、图像重采样、对比度增强和多次操作。将图像分割成几个固定大小的块,对操作区域进行定位,并对每个块的检测结果进行组合。对每个块进行独立的检测,因此不能得到整体的图像统计数据。
块匹配从图像块中提取统计特征,并度量块之间的一致性。高度不一致的补丁被认为是被操作过的(例如,从另一个图像拼接)。预定义的特征提取器或神经网络用于提取合适的特征进行匹配。Huh et al.提出了一种自监督的方法来训练模型,以确定图像在EXIF元数据方面是否一致。但是,块匹配定位需要对每个块对计算一致性,并且通过聚合所有块对的结果来得到实际的伪造位置,需要花费大量的时间进行后期处理。
神经网络极大地改进了目标检测和语义分割的性能,因此使用这些技术开发了图像伪造定位方法。在RGB-N中,将SRM内核添加到对象检测模型中,提取拼接、复制-移动和删除伪造的边界框。Bi等人提出了一种基于U-Net的分割网络来对图像拼接进行定位。它与一般的语义分割网络一样,只使用RGB像素域信息。Wu et al.利用SRM核进行特征提取,利用约束卷积进行像素级异常检测,提出ManTraNet。尽管他们认为JPEG压缩是一种训练特征提取器的操作,但它无法区分单个和双JPEG压缩。因此,JPEG图像的定位性能降低。
我们提出了一种新的方法来检测和定位JPEG图像上的图像拼接,克服了以往工作的局限性。为了快速推理和像素预测,我们采用了一个考虑多分辨率特征的分割网络。为了使网络对JPEG压缩具有鲁棒性,我们利用量化DCT系数的二值体表示在DCT域提取JPEG伪图像。
提出的方法
网络结构
图3显示CAT-Net由RGB流、DCT流和最终融合阶段组成。从JPEG文件输入中提取RGB像素值、量化的y通道DCT系数和y通道量化表。RGB像素值被送入RGB流,其他数据被送入DCT流。RGB流专注于视觉线索,而DCT流专注于压缩伪影。然后将流输出融合生成最终输出。
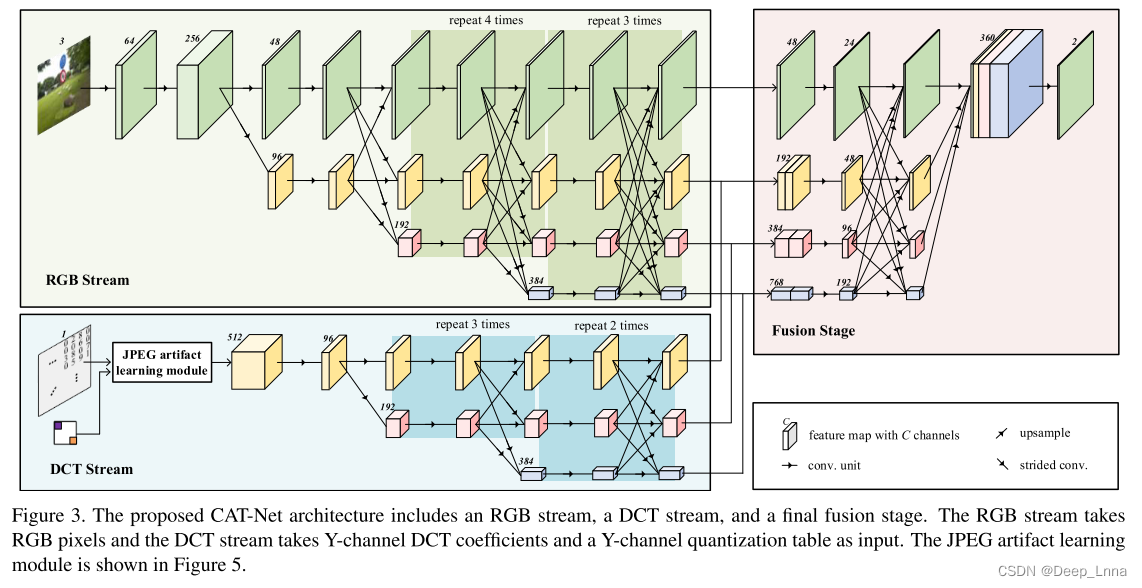
我使用HRNet作为CAT-Net的backbone,它最初是为计算机视觉问题而设计的。我们将HRNet引入到取证问题中,因为它在整个过程中保持了高分辨率的表示,并采用了一种新的融合方法来结合多个分辨率特征并捕获整体图像。这有助于在不丢失取证调查所需的精细伪影的情况下捕捉整体结构。此外,HRNet使用步长为2的卷积来下采样特征图,而不使用池化层。最近的研究表明,对于需要微妙信号的任务来说,池化是不可取的,因为池化强化了内容并抑制了类似噪声的信号。虽然这种行为对计算机视觉任务是可取的,但它不适合取证任务,因为噪声是一个重要的线索。
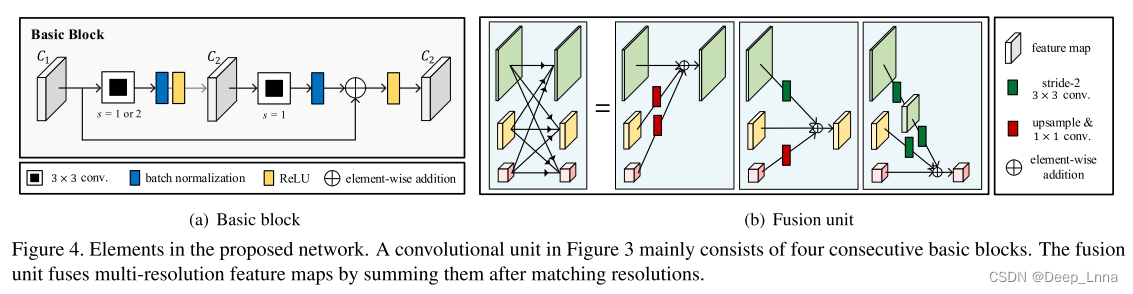
该网络包括两个要素:卷积单元和融合单元。图3中的每个卷积单元由图4(a)中所示的四个连续基本块组成,只有少数例外,如第一部分和最后一部分。图4(b)示出了融合单元,其在通过双线性内插(上采样)或步长卷积(下采样)匹配分辨率之后通过对多分辨率特征求和来融合多分辨率特征图。
RGB流结构与HRNet相同,只是删除了最后一部分。RGB流采用RGB像素值作为输入,并且第一卷积单元将分辨率降低4倍。从高分辨率路径开始,逐步经历由高到低逐个添加分辨率路径、多分辨率路径并联的网络。每个决议保留到最后,产生1/4、1/8、1/16和1/32个决议。
DCT流捕获压缩伪影,即y通道DCT系数的统计分布。该结构是HRNet的三分辨率变体,其中第一个卷积单元被JPEG伪迹学习模块替换(图5)。该流中的所有卷积单元都由四个基本块组成(图4(a)),无一例外。JPEG伪迹学习模块首先使用f: ZH×W→{0,1}(T+1)×H×W转换DCT系数的输入数组M为一个二进制体积,即
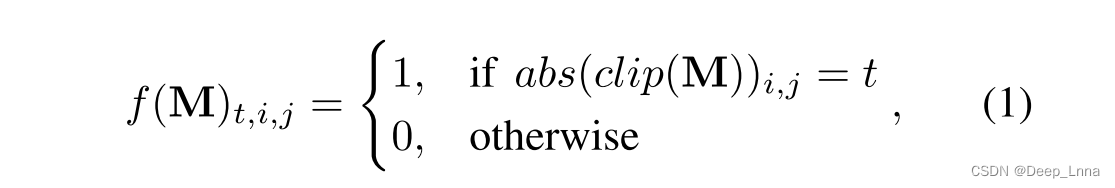
其中clip(·)将数组元素剪辑到区间[−T, T],而abs(·)是元素的绝对值。我们通过实验确定最佳的T值为20。这种二值体表示类似于DCT直方图,但允许网络学习相邻DCT系数之间的关系。DCT直方图以小块的方式合并信息,而这种表示方式保持了适合于分割的图像分辨率。
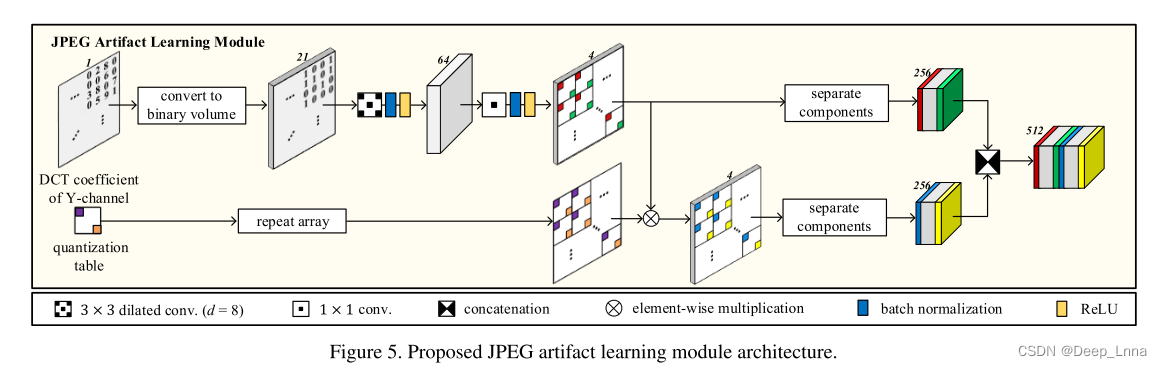
对二进制体应用连续卷积。这里使用的是扩展卷积,它原本是为了增加CNN的感受野而设计的。然而,本文提出的网络使用8-扩展卷积,以提取相同频率基衍生的DCT系数中的特征。通过1 × 1卷积,feature map通道的数量减少到4个,feature map是分叉的。对于分叉的路径,将JPEG报头得到的8 × 8量化表乘以相应的频率分量。这类似于JPEG解码中DCT系数的去量化过程。对于另一条路径,表不相乘。两个路径的每个64 (= 8 × 8)频率分量被分离。注意,前面的操作是按频率进行的,因此8 × 8块中的每个值代表一个频率分量。分离组件的形状从4 ×H ×W变为256 × h/8 × w/8,大大降低了分辨率。最后,在该模块中,将两条路径的特征映射进行通道维级联。输出传递DCT流的剩余路径。
在训练过程中,将输入图像裁剪成固定的尺寸以构造一个具有批处理维的张量。值得注意的是,矩形裁剪区域必须与8 × 8网格对齐,因为JPEG将图像编码为8 × 8块。这使得通道分离张量的每个通道代表一个频率分量。这也允许RGB流学习JPEG阻塞工件和可视化工件。输出特征图的分辨率分别为(1/4,1/8,1/16,1/32)和(1/8,1/16,1/32)的RGB和DCT流。两流特征映射在通道维度上按分辨率级联,并传递到最终融合阶段(图3),其结构与最终HRNet阶段相同,但通道数量不同。所有四个分辨率特征图最终都以双线性提前上采样,以匹配最高分辨率,并连接,并通过最后的卷积层。最终的输出是每一类的2 × H/4 × w/4对数数组(真实的和篡改的)。
处理非JPEG图像
虽然我们的网络使用量化表作为输入,但网络也可以处理非JPEG图像。由于非JPEG图像不包含量化的DCT系数,它们是从RGB像素计算出来的,类似于JPEG编码器。我们认为这些图像的量化表都是1,对应JPEG质量为100。为了实现一个简单的实现,我们在网络前端放置了一个JPEG编码器,并使用质量因子100将非JPEG图像压缩为JPEG图像,而不使用色度子采样。这将自动创建量化的DCT系数和一个全为1的量化表。
这是基于压缩假设的:虽然拼接的图像以未压缩的图像格式保存,但用于拼接伪造的两个源(真实)图像在获取过程中最初在相机中压缩。处理后的图像的文件扩展名无关紧要,也就是说,我们不假设伪造者以特定格式保存伪造的图像。
双JPEG检测的训练
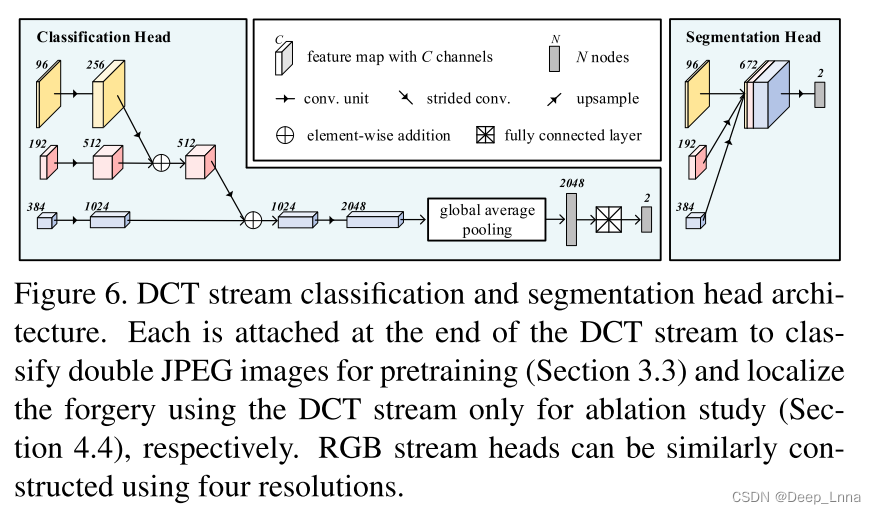
DCT流权值通过双JPEG检测的预训练初始化。任务是对给定的JPEG图像是否被压缩过一次或两次进行分类。图6显示了分类头被附加在DCT流的末尾,因为这是一个二元分类任务。关于此任务的预训练有助于流捕获丰富的压缩伪迹。
我们在包含1.054M单压缩和双压缩JPEG图像的数据集上训练和测试DCT流,该数据集具有混合质量参数。他们使用1120个量化表压缩的原始图像,其中不仅包括51个标准表(Q50-Q100),还包括从公共取证web服务中请求的图像获得的非标准表。表1显示了本文提出的DCT流(93.93%)的双JPEG检测性能,与基线相比,这是最先进的性能。虽然我们使用的系数范围更小,但我们提出的网络优于使用直方图的最先进的神经网络。因此,对于双JPEG检测,二进制体表示是DCT直方图的一个很好的替代方案。
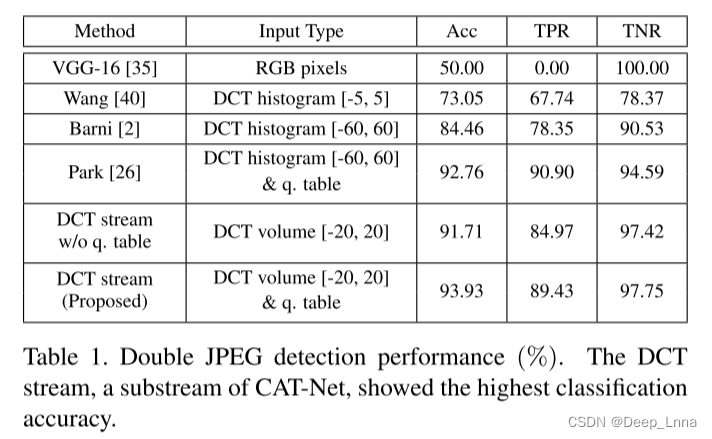
我们也研究了没有量化表乘法的网络,以评估使用量化表的有效性。这与原始DCT流的不同之处在于,图5中的量化表路径和连接被删除了。使用量化表提高了双JPEG检测精度。因此,我们首次采用量化表进行伪造定位。
实验
数据集
表2总结了实验中使用的拼接数据集。我们还首次报告了y通道量化表的数量。使用各种量化表(包括标准表和自定义表)来模拟真实世界的伪造。
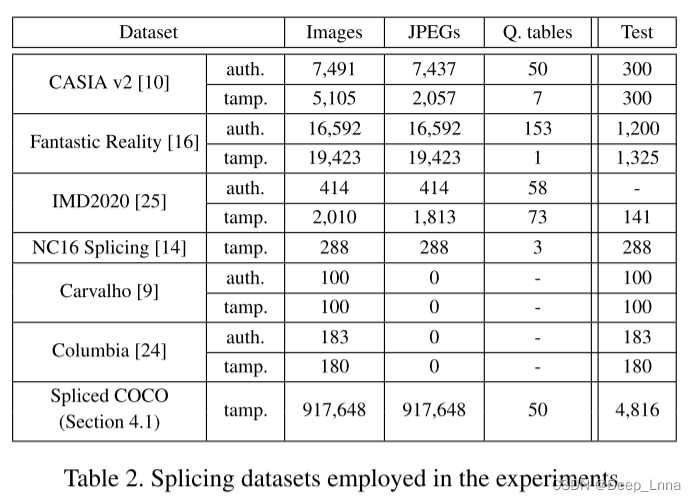
使用CASIA v2 (auth./tamp.)、Fantastic Reality (auth./tamp.)、IMD2020 (tamp.)和Spliced COCO (tamp.)作为训练集;剩下的数据集只用于测试。表2中最右边的一列显示了用于测试的图像数量。与之前的图像伪造定位研究相比,我们也使用了真实的图像。我们希望这能帮助网络学习篡改区域和真实区域之间的绝对边界,而不是相对边界来预测每幅图像中最可疑的区域。
实现细节
我们对RGB流进行ImageNet分类的预训练,对DCT流进行双JPEG分类,从而初始化网络的权值。为了更好地处理数据集大小的多样性,我们在每个数据集中采样了均衡数量的图像来构造一个epoch。训练图像被裁剪成512×512补丁,并与8×8网格对齐。使用全分辨率图像进行测试,这是可能的,因为所提出的网络是完全卷积的。
评价指标
mIoU、p-mIoU衡量篡改图像,像素精度Acc(G,P)、p-Acc(G,P)来检测真实图像。
结果
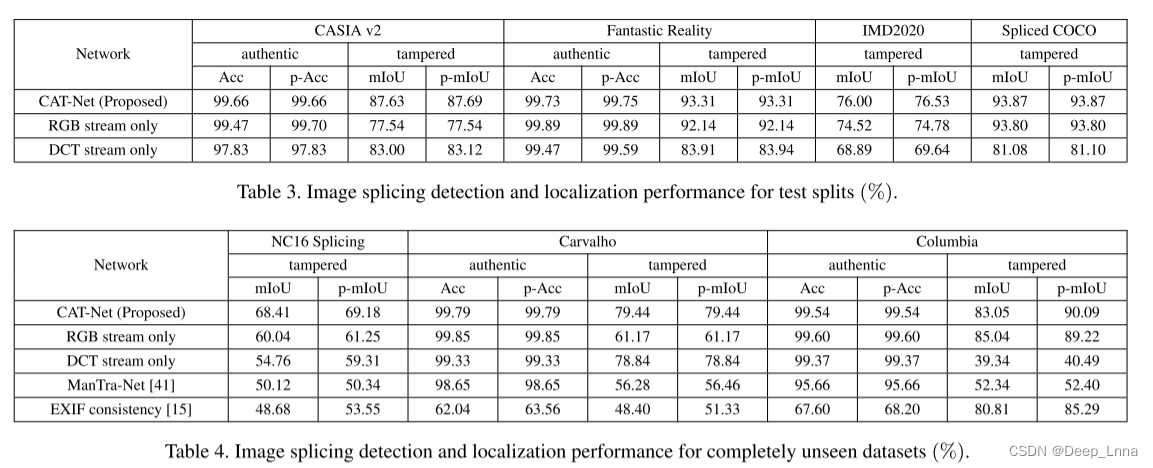
表3和表4分别显示了测试拼接和完全不可见图像的结果。我们测试了ManTra-Net和EXIF的一致性,以将CAT-Net与当前最先进的图像处理检测器进行比较。这两个网络的结果只报告完全看不见的数据集,以确保公平比较。我们还报告了用于消融研究的两个CAT-Net子流的性能,并对JPEG压缩进行了鲁棒性测试(图7)。
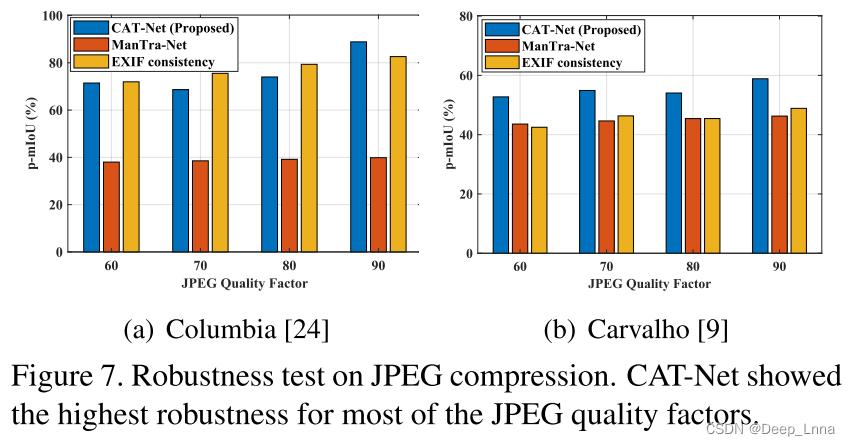
图8和9显示了一些典型的预测结果。
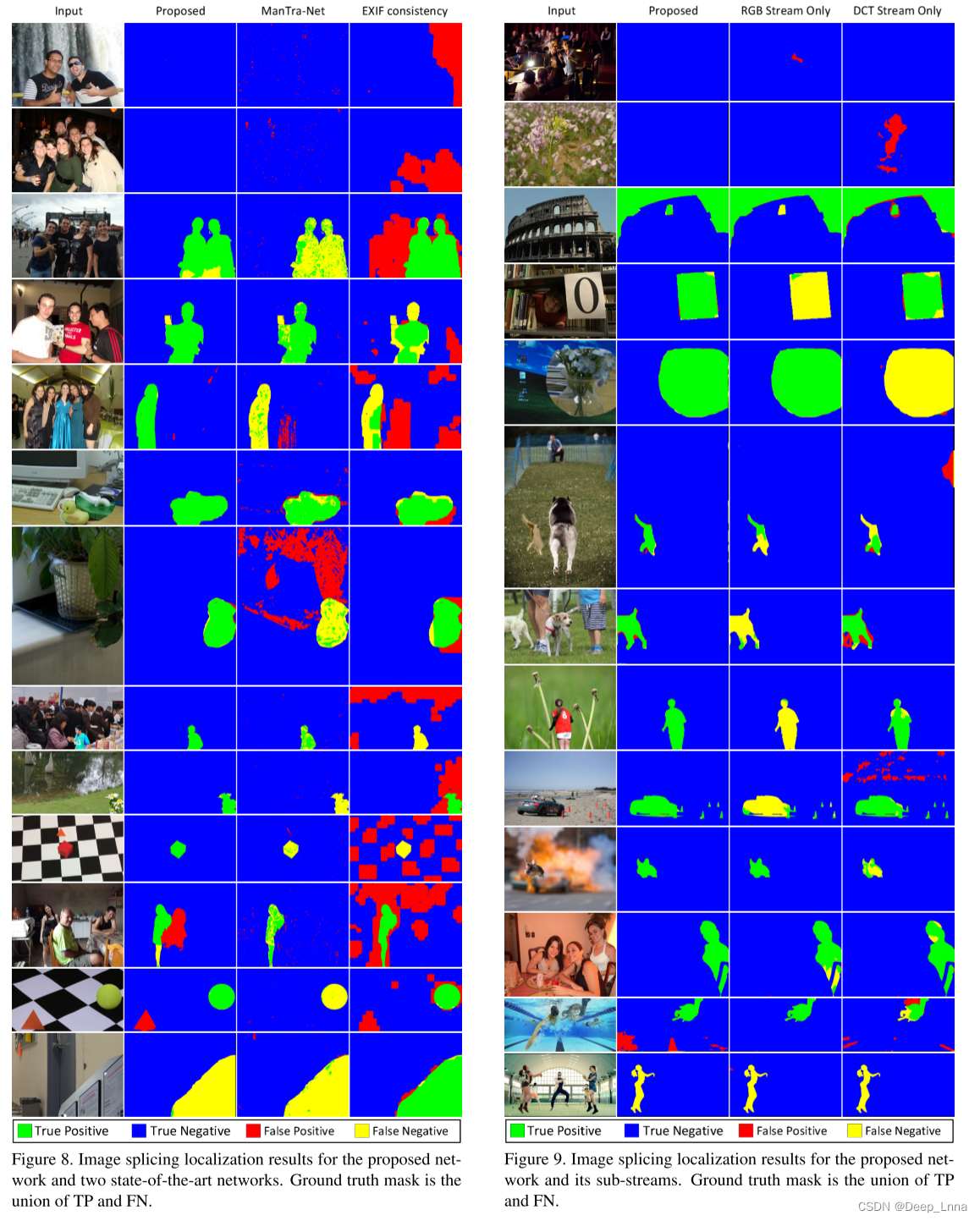
表4和图8显示,与目前最先进的神经网络相比,CAT-Net在几乎所有的数据集上在真实和篡改的图像表现都要好。比较网络总是检测到一些区域被篡改,因为它们是异常检测器,即使是真实的图像。然而,由于CAT-Net是一个分割模型,并且我们在训练中使用了真实的图像,因此产生的假阳性较少。对于被篡改的图像,CAT-Net和其他网络之间的差异要大得多。因此,即使压缩了伪造图像,如NC16拼接,CAT-Net也能非常有效地跟踪精细轨迹。因此,CAT-Net在检测和定位真实世界图像拼接伪造方面取得了最先进的性能。
表3、4和图9显示了RGB流和DCT流互补配合提高网络性能。例如,在Carvalho(tamp.)中,DCT流表现更好;而在NC16 Splicing(tamp.)中,RGB流表现更好。在这两种情况下,全网络表现最好。如4.1节所述,Columbia违反了压缩假设。在这里,DCT流不能很好地预测,因为图像在开始时没有压缩,没有留下压缩伪影。然而,在RGB流的帮助下,全网络(CAT-Net)在这个数据集上表现良好。
图7显示了使用质量系数60-90压缩Columbia和Carvalho对JPEG压缩的鲁棒性。当应用额外的压缩时,Columbia的三种网络性能都降低了,因为它是由两个不同的摄像机在没有压缩的情况下进行拼接的。在Carvalho中,额外的压缩肯定会降低性能,但变化较小,因为图像有初始压缩痕迹,这有助于网络检测拼接的对象。CAT-Net在各种质量因素上都取得了良好的性能。
总结
提出了对给定图像上的拼接区域进行定位的CAT-Net。CAT-Net首次尝试同时考虑RGB和DCT域,从而有效地学习通过RGB和DCT流保留在每个域的视觉和压缩伪影的取证特征。特别是DCT流,包含JPEG工件学习模块,在检测双JPEG压缩时取得了出色的性能。我们首次将迁移学习从双JPEG检测任务应用到图像伪造定位任务中。这有助于网络区分拼接区域和真实区域之间的统计指纹。与目前的网络相比,CAT-Net在不同数据集上实现了JPEG或非JPEG图像的局部拼接区域的最先进的性能。
这篇关于【论文笔记】CAT-Net: Compression Artifact Tracing Network for Detection and Localization of Image Splicing的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





