detection专题

时间序列|change point detection
change point detection 被称为变点检测,其基本定义是在一个序列或过程中,当某个统计特性(分布类型、分布参数)在某时间点受系统性因素而非偶然因素影响发生变化,我们就称该时间点为变点。变点识别即利用统计量或统计方法或机器学习方法将该变点位置估计出来。 Change Point Detection的类型 online 指连续观察某一随机过程,监测到变点时停止检验,不运用到

MACS bdgdiff: Differential peak detection based on paired four bedGraph files.
参考原文地址:[http://manpages.ubuntu.com/manpages/xenial/man1/macs2_bdgdiff.1.html](http://manpages.ubuntu.com/manpages/xenial/man1/macs2_bdgdiff.1.html) 文章目录 一、MACS bdgdiff 简介DESCRIPTION 二、用法

Learning Memory-guided Normality for Anomaly Detection——学习记忆引导的常态异常检测
又是一篇在自编码器框架中研究使用记忆模块的论文,可以看做19年的iccv的论文的衍生,在我的博客中对19年iccv这篇论文也做了简单介绍。韩国人写的,应该是吧,这名字听起来就像。 摘要abstract 我们解决异常检测的问题,即检测视频序列中的异常事件。基于卷积神经网络的异常检测方法通常利用代理任务(如重建输入视频帧)来学习描述正常情况的模型,而在训练时看不到异常样本,并在测试时使用重建误

REMEMBERING HISTORY WITH CONVOLUTIONAL LSTM FOR ANOMALY DETECTION——利用卷积LSTM记忆历史进行异常检测
上海科技大学的文章,上海科技大学有个组一直在做这方面的工作,好文章挺多的还有数据集。 ABSTRACT 本文解决了视频中的异常检测问题,由于异常是无界的,所以异常检测是一项极具挑战性的任务。我们通过利用卷积神经网络(CNN或ConvNet)对每一帧进行外观编码,并利用卷积长期记忆(ConvLSTM)来记忆与运动信息相对应的所有过去的帧来完成这项任务。然后将ConvNet和ConvLSTM与

COD论文笔记 ECCV2024 Just a Hint: Point-Supervised Camouflaged Object Detection
这篇论文的主要动机、现有方法的不足、拟解决的问题、主要贡献和创新点: 1. 动机 伪装物体检测(Camouflaged Object Detection, COD)旨在检测隐藏在环境中的伪装物体,这是一个具有挑战性的任务。由于伪装物体与背景的细微差别和模糊的边界,手动标注像素级的物体非常耗时,例如每张图片可能需要 60 分钟来标注。因此,作者希望通过减少标注负担,提出了一种仅依赖“点标注”的弱

COD论文笔记 Adaptive Guidance Learning for Camouflaged Object Detection
论文的主要动机、现有方法的不足、拟解决的问题、主要贡献和创新点如下: 动机: 论文的核心动机是解决伪装目标检测(COD)中的挑战性任务。伪装目标检测旨在识别和分割那些在视觉上与周围环境高度相似的目标,这对于计算机视觉来说是非常困难的任务。尽管深度学习方法在该领域取得了一定进展,但现有方法仍面临有效分离目标和背景的难题,尤其是在伪装目标与背景特征高度相似的情况下。 现有方法的不足之处: 过于

Detection简记3-Region Proposal by Guided Anchoring
创新点 1.新的anchor 分布策略:Guided Anchoring 2.feature adaption module,根据潜在的anchor精调特征 总结 Guided Anchoring:流程如图所示 特征图F1接两个分支:位置预测分支产生物体可能存在的位置的概率图,形状预测分支预测物体的形状,独立于位置。根据两个分支的输出,得到anchor。 位置预测分支: 1X1的卷积+si

Detection简记2-DAFE-FD: Density Aware Feature Enrichment for Face Detection
创新点 1.使用密度估计模型增强检测中的特征图 总结 整个流程还是很清晰的。 conv1-3的特征图经过密度估计模块由检测器D1进行检测。 D2-4分别是四个检测器。 FFM是特征融合模块,将不同层不同大小的特征融合。 FFM网络结构如下: 首先使用1X1的卷积减少两组特征的厚度到128,然后使用双线性插值统一两组特征图的尺寸,然后相加。类似于cvpr2017的SSH。 多尺度检测器的网

DS简记1-Real-time Joint Object Detection and Semantic Segmentation Network for Automated Driving
创新点 1.更小的网络,更多的类别,更复杂的实验 2. 一体化 总结 终于看到一篇检测跟踪一体化的文章 网络结构如下: ResNet10是共享的Encoder,yolov2 是检测的Deconder,FCN8 是分割的Deconder。 其实很简单,论文作者也指出:Our work is closest to the recent MultiNet. We differ by focus
![[论文笔记]Arbitrary-Oriented Scene Text Detection via Rotation Proposals](https://img-blog.csdn.net/20171124154517721?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxMzI1MDQxNg==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center)
[论文笔记]Arbitrary-Oriented Scene Text Detection via Rotation Proposals
Arbitrary-Oriented Scene Text Detection via Rotation Proposals 论文地址:https://arxiv.org/abs/1703.01086 github地址:https://github.com/mjq11302010044/RRPN 该论文是基于faster-rcnn框架,在场景文字识别领域的应用。 创新点:生成带文字
![[源码分析]Text-Detection-with-FRCN](https://img-blog.csdn.net/20170326003840157)
[源码分析]Text-Detection-with-FRCN
Text-Detection-with-FRCN项目是基于py-faster-rcnn项目在场景文字识别领域的扩展。对Text-Detection-with-FRCN的理解过程,本质上是对py-faster-rcnn的理解过程。我个人认为,初学者,尤其是对caffe还不熟悉的时候,在理解整个项目的过程中,会有以下困惑: 1.程序入口 2.数据是如何准备的? 3.整个网络是如何构建的? 4.

(已开源-CVPR 2024)YOLO-World: Real-Time Open-Vocabulary Object Detection
169期《YOLO-World Real-Time Open-Vocabulary Object Detection》 You Only Look Once (YOLO) 系列检测模型是目前最常用的检测模型之一。然而,它们通常是在预先定义好的目标类别上进行训练,很大程度上限制了它们在开放场景中的可用性。为了解决这一限制,本文引入了 YOLO-World,通过视觉语言建模和大规模数

YOLO前篇---Real-Time Grasp Detection Using Convolutional Neural Networks
论文地址:https://arxiv.org/abs/1412.3128 1. 摘要 比目前最好的方法提高了14%的精度,在GPU上能达到13FPS 2. 基于神经网络的抓取检测 A 结构 使用AlexNet网络架构,5个卷积层+3个全连接层,卷积层有正则化和最大池化层网络结构示意图如下 B 直接回归抓取 最后一个全连接层输出6个神经元,前4个与位置和高度相关,另外2个用来表示方向

【读点论文】Scene Text Detection and Recognition: The Deep Learning Era
Scene Text Detection and Recognition: The Deep Learning Era Abstract 随着深度学习的兴起和发展,计算机视觉发生了巨大的变革和重塑。场景文本检测与识别作为计算机视觉领域的一个重要研究领域,不可避免地受到了这波革命的影响,从而进入了深度学习时代。近年来,该社区在思维方式、方法论和性能方面取得了长足的进步。本综述旨在总结和分析深度学
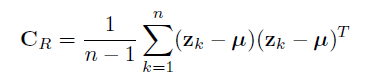
Region Covariance: A Fast Descriptor for Detection and Classification算法总结
传统的像素级特征比如颜色、梯度、滤波响应等等它们对光照变化和非刚性运动的描述不够鲁棒,而在像素级特征之上延伸出的直方图表述了一种无参的联合分布,然而随着特征数目的增加,联合分布的表达是呈指数增加的。另外,关键点的检测以及描述在匹配局部图像上非常有效,然而它们只包含了局部信息,没有利用全局的信息。 与直方图类似,协方差也能作为特征描述,并且协方差的特征维度要小很多。实验证明,协方差特征比其他特征性

AST: Asymmetric Student-Teacher Networks for Industrial Anomaly Detection代码运行
环境 設置遠程路徑 conda create --name zgp_ast python=3.7.7 pip install -r requirements.txt PIL>=7.1.2改爲Pillow>=7.1.2 Building wheels for collected packages: efficientnet-pytorchBuilding wheel for efficient

Relation Networks for Object Detection
目录 1. Background 2. Object Relation Module 3. Duplicate removal 4. Experiment 5. Summary 参考 主要贡献点有两条: 1. 提出了一种relation module,可以在以往常见的物体特征中融合进物体之间的关联性信息,同时不改变特征的维数,能很好地嵌进目前各种检测框架,提高性能 2.

行为识别实战第二天——Yolov5+SlowFast+deepsort: Action Detection(PytorchVideo)
Yolov5+SlowFast+deepsort 一、简介 YoloV5+SlowFast+DeepSort 是一个结合了目标检测、动作识别和目标跟踪技术的视频处理框架。这一集成系统利用了各自领域中的先进技术,为视频监控、体育分析、人机交互等应用提供了一种强大的解决方案。 1. 组件说明: YoloV5: Yolo(You Only Look Once)是一个流行的实时目标检测

【论文阅读】YOLOv10: Real-Time End-to-End Object Detection
文章目录 摘要一、介绍二、相关工作三、方法3.1无nms培训的一致性双重任务3.2 整体效率-精度驱动的模型设计 四、实验4.1实现细节4.2与最先进水平的比较4.3模型分析 五、结论 YOLOv10:实时端到端对象检测 摘要 在过去的几年里,由于在计算成本和检测性能之间取得了有效的平衡,YOLOs已经成为实时目标检测领域的主导范式。研究人员已经对yolo的架构设计、优化目
MS COCO数据集目标检测评估(Detection Evaluation)
MS COCO (Microsoft Common Objects in Context) 是一个广泛应用于计算机视觉领域的数据集和评估平台,尤其是在目标检测、分割和人体关键点检测等任务中。COCO数据集和其评估方法被广泛用于学术研究和工业应用。以下是对MS COCO数据集目标检测评估、人体关键点评估、输出数据的结果格式以及如何参加比赛的详细阐述和总结。 1. MS COCO数据集目标检测评估(

【人工智能】Transformers之Pipeline(十二):零样本物体检测(zero-shot-object-detection)
目录 一、引言 二、零样本物体检测(zero-shot-object-detection) 2.1 概述 2.2 技术原理 2.3 应用场景 2.4.1 pipeline对象实例化参数 2.4.2 pipeline对象使用参数 2.4 pipeline实战 2.5 模型排名 三、总结 一、引言 pipeline(管道)是huggingface trans
Object Detection -- 论文YOLO(You Only Look Once: Unified, Real-Time Object Detection)解读(链接)
https://blog.csdn.net/u011974639/article/details/78208773

论文笔记 A Large Contextual Dataset for Classification,Detection and Counting of Cars with Deep Learning
ECCV 2016的文章,首先建立了一个从上到下照的车辆影像数据集(即鸟瞰视角),并提出ResCeption神经网络进行训练,进一步建立residual learning with Inception-style layers,进行车辆数目的计算。该方法为车辆数目的计算的一种新方式:通过定位和密度估计方法。对于新的场景或新的目标计数也同样适用。 文章主要关注3个任务点:(1)两类的分类问题(2)

论文笔记 HyperNet: Towards Accurate Region Proposal Generation and Joint Object Detection
提出的HyperNet网络基于设计的Hyper特征,这种特征主要先集合分等级的特征图,然后将其压缩到一个空间。这种Hyper特征同时具有足够深和很好的语义信息,在PASCAL VOC 2007和2012上可以通过每张图产生仅仅100个proposal,而达到很好的精度和效果,同时可以达到实时,GPU下 5 fps的速度。 Hyper方法主要的贡献有: (1)在仅仅 50 proposal情况下

《You Only Look Once: Unified, Real-Time Object Detection》YOLO一种实时目标检测方法 阅读笔记(未完成版)
文章目录 1. one-stage与two-stage检测算法1. 模型过程1.1 grid cell1.2 bounding box与confidence score1.3 类别预测1.4 预测目标 2. 网络的学习2.1 网络输出的数据与预测集数据2.2 损失函数2.3 网络的设计 1. one-stage与two-stage检测算法 two-stage: one-st
CVPR2023检测相关Detection论文速览上
Paper1 AUNet: Learning Relations Between Action Units for Face Forgery Detection 摘要原文: Face forgery detection becomes increasingly crucial due to the serious security issues caused by face manipulati