本文主要是介绍论文笔记 A Large Contextual Dataset for Classification,Detection and Counting of Cars with Deep Learning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ECCV 2016的文章,首先建立了一个从上到下照的车辆影像数据集(即鸟瞰视角),并提出ResCeption神经网络进行训练,进一步建立residual learning with Inception-style layers,进行车辆数目的计算。该方法为车辆数目的计算的一种新方式:通过定位和密度估计方法。对于新的场景或新的目标计数也同样适用。
文章主要关注3个任务点:(1)两类的分类问题(2)目标的检测与定位(3)车辆的计数
数据集介绍
整篇文章最大的贡献之一,就是给出的数据集==该数据集分辨率为每个像素对应地面15cm,因此车辆的大小范围基本是24-48像素。其中,有两个数据集(Vaihingen, Columbus)是灰度图像,其余四个均为RGB彩色图像。因为数据集的尺度比较一致,同时车辆大小比较单一,因此不需要尺度上的变换,而重点放在检测算法精度,以及车辆外形与旋转带来的问题。
数据集为像素级别的标签,同时每一个车在其中心位置标记一点。large trucks都被忽略掉,同时Vans and pickups被同样标记为正样本,而负样本包含boats, trailers and construction vehicles。
同时,为了在大尺度遥感影像中对训练和检测patch进行区分,将影像划分成1024*1024大小的网格,对这些网格进行标记哪些是训练区域,哪些是检测区域,使得训练与检测patch进行区分不重叠。虽然训练与检测的两种patch不重叠,但是训练样本之间可重叠,检测样本之间也可以重叠,并在停车场等密集区域,确保样本之间存在重叠。图像大小均为2048*2048,因此第4个网格的patch作为testing patch,而前3个为训练patch。
下图即为训练与检测patch的分布示意图,图中蓝色区域为training patch areas,红色区域为testing patch areas:

同时,数据集中的图片场景如下图展示:

Classification
在训练分类时,提出了一种上下文相关的分类训练方法,每15度方向的车辆作为一个整体进行训练,来获得模型的旋转不变性。训练中主要使用了308,988 training patches 和 79,447 testing patches,通过训练判断patch的中心区域是否包含车辆目标. 其训练模型如下右图:
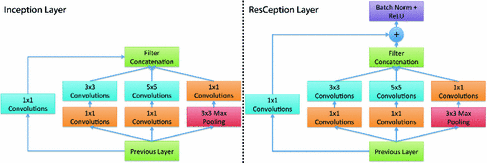
其中,左图为标准的Inception layer,右图为本文提出的ResCeption layer方法,可以看出右图最主要的不同是一个1*1的卷积层被用作是一个投影的residual shortcut。
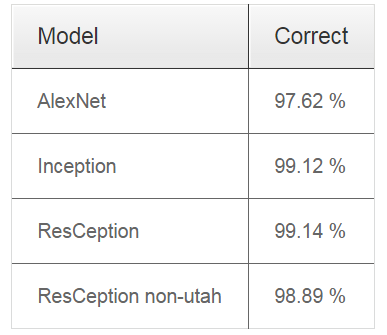
不同网络结构下的分类结果:
Detection
首先作者简要说明,其实验发现,标签的加入对于分类结果的精度,并没有很大的提高,因此对于分类任务,无需加入标签训练。然后作者进行检测任务下的实验。
在检测训练时,主要对softmax输出层计算一个热度图,其loss函数如下:
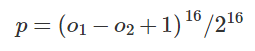
其中,等式左边p代表第p个像素位置,右边(o1)代表softmax输出层中存在车辆,(o2)代表不存在车辆。

如图,左边为热度图结果,右边为检测结果的一个举例,存在部分误检情况。
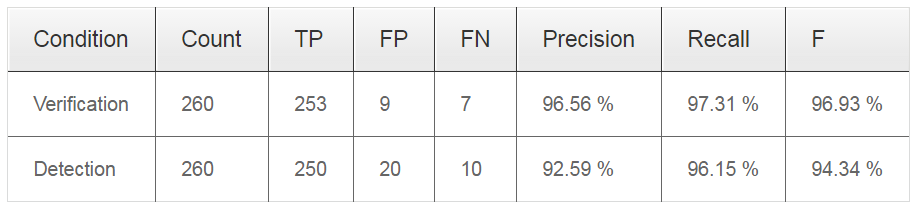
检测结果表:
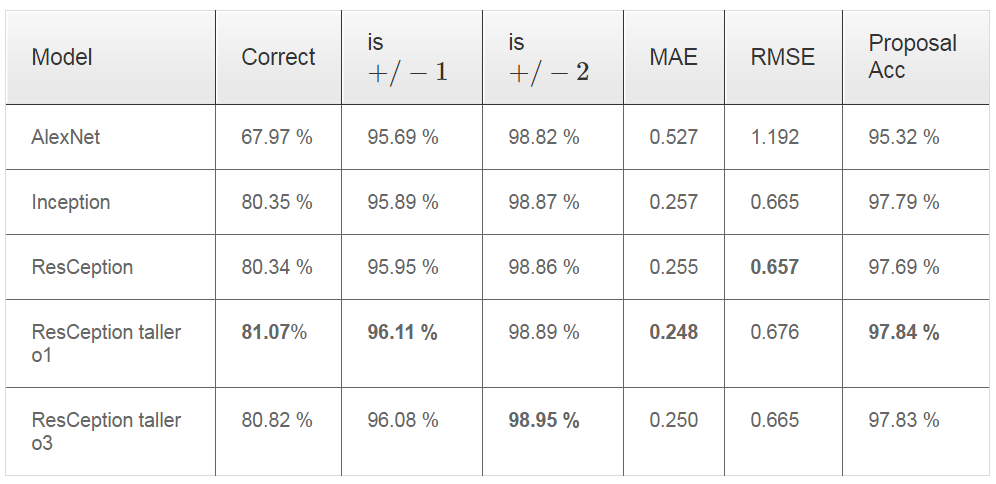
Counting
在计数部分,主要对大部分像素存在图像内的车辆进行计数,同时为了使得网络能力更强,类似更深的ResNet想法,文章提出了一个double tall GoogLeNet like network,即将ResCeption layer重复使用两次,从原来的11层变成22层。文章进行了一系列的实验部分,分为几种情况,博客这里仅仅展示一种,详情实验结果参考文章。。。。
其计数分别结果如下:
计数示意图如下:

左下角数字即为计数结果,蓝色和绿色边界是为了区分每一个stride的大小,从图也可以看出stride之间存在重叠。6个stride共检测出74个车辆,实际为77.
这篇关于论文笔记 A Large Contextual Dataset for Classification,Detection and Counting of Cars with Deep Learning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








