dataset专题

HTML5自定义属性对象Dataset
原文转自HTML5自定义属性对象Dataset简介 一、html5 自定义属性介绍 之前翻译的“你必须知道的28个HTML5特征、窍门和技术”一文中对于HTML5中自定义合法属性data-已经做过些介绍,就是在HTML5中我们可以使用data-前缀设置我们需要的自定义属性,来进行一些数据的存放,例如我们要在一个文字按钮上存放相对应的id: <a href="javascript:" d

论文精读-Supervised Raw Video Denoising with a Benchmark Dataset on Dynamic Scenes
论文精读-Supervised Raw Video Denoising with a Benchmark Dataset on Dynamic Scenes 优势 1、构建了一个用于监督原始视频去噪的基准数据集。为了多次捕捉瞬间,我们手动为对象s创建运动。在高ISO模式下捕获每一时刻的噪声帧,并通过对多个噪声帧进行平均得到相应的干净帧。 2、有效的原始视频去噪网络(RViDeNet),通过探

SparkRDD转DataSet/DataFrame的一个深坑
大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! By 大数据技术与架构 场景描述:本文是根据读者反馈的一个问题总结而成的。 关键词:Saprk RDD 原需求:希望在map函数中将每一

rdd,dataframe,dataset之间的区别
在spark中,RDD、DataFrame、Dataset是最常用的数据类型,本博文给出笔者在使用的过程中体会到的区别和各自的优势 共性: 1、RDD、DataFrame、Dataset全都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利 2、三者都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action如foreach时,三者才会开始

大数据-118 - Flink DataSet 基本介绍 核心特性 创建、转换、输出等
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis (已更完)Kafka(已更完)Spark(已更完)Flink(正在更新!) 章节内容 上节我们完成了如下的内容: Flink Sink J

PyTorch数据加载:自定义数据集【Dataset:处理每个原始样本】【DataLoader:每次生成batch_size个样本】【collate_fn:重新设置一个Batch中所有样本的加载格式】
一、自定义Dataset Dataset是一个包装类: 用来将数据包装为Dataset类,然后传入DataLoader中,我们再使用DataLoader这个类来更加快捷的对数据进行操作。可以通过继承Dataset来将数据集的源文件、规模和其他非必要的功能打包,从而供DataLoader使用。 1、“文本分类”任务下使用自定义Dataset class.txt:所有类别 finance
DataSet和DataTable的关系
C#中的DataTable 在C#中,DataTable 是 System.Data 命名空间下的一个类,它是 DataSet 的一个组件,用于存储表格形式的数据。DataTable 可以独立于数据库使用,也可以与数据库表相关联,用于数据的读取、更新、插入和删除操作。 以下是 DataTable 的一些基本用法: 创建 DataTable: DataTable table = new
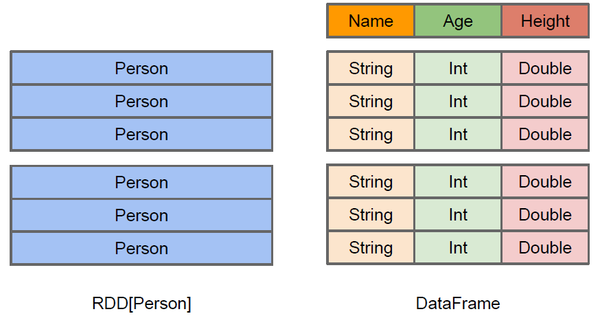
Spark RDD、DataFrame、DataSet区别和联系
左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。DataFrame多了数据的结构信息,即schema。RDD是分布式的Java对象的集合。DataFrame是分布式的Row对象的集合。Data
tensorflow.data.dataset
这篇博客讲的很清楚。 注:buffer_size表示在shuffle时缓冲池的大小,影响随机顺序。 The buffer_size in Dataset.shuffle() can affect the randomness of your dataset, and hence the order in which elements are produced.
Pytorch:复写Dataset函数详解,以及Dataloader如何调用
在 PyTorch 中,Dataset 和 DataLoader 是数据加载和处理的重要组件。下面详细介绍 Dataset 类的作用及其 __len__() 和 __getitem__() 方法,以及它们如何与 DataLoader 协作,包括数据打乱(shuffle)和批处理(batching)等功能。 Dataset 类 Dataset 是一个抽象基类,用于表示一个数据集。你需要继承这个基
理解Spark中RDD(Resilient Distributed DataSet)
1。Spark围绕弹性分布式数据集(RDD)的概念展开,RDD是一个可以并行操作的容错的容错集合。 创建RDD有两种方法:并行化驱动程序中的现有集合,或引用外部存储系统中的数据集,例如共享文件系统,HDFS,HBase或提供Hadoop InputFormat的任何数据源。 val sc = spark.sparkContext // 已有内部数据源val data = Array(1, 2,

I3D视频分类论文梗概及代码解读Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
论文https://arxiv.org/pdf/1705.07750.pdf,from DeepMind ,CVPR2017 代码https://github.com/LossNAN/I3D-Tensorflow 2017年视频分类最好的网络,同时提供了VGG的预训练模型,网络端到端,简单易懂,便于部署及工程化。只是跑一下基本有个Tensorflow,单显卡就能训练和测试,效果还好,一绝。本文

论文笔记 A Large Contextual Dataset for Classification,Detection and Counting of Cars with Deep Learning
ECCV 2016的文章,首先建立了一个从上到下照的车辆影像数据集(即鸟瞰视角),并提出ResCeption神经网络进行训练,进一步建立residual learning with Inception-style layers,进行车辆数目的计算。该方法为车辆数目的计算的一种新方式:通过定位和密度估计方法。对于新的场景或新的目标计数也同样适用。 文章主要关注3个任务点:(1)两类的分类问题(2)
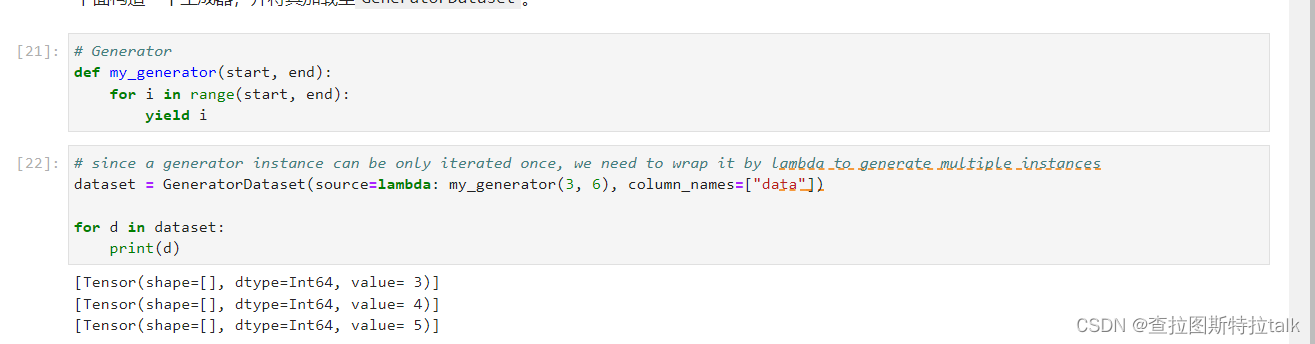
深度学习之数据集 Dataset总结
数据集 Dataset MindSpore提供了基于Pipeline的数据引擎,通过Dataset和Transforms实现高效的数据预处理。它提供了内置的文本、图像、音频等数据集加载接口,并提供了自定义数据集加载接口。此外,MindSpore的领域开发库也提供了大量的预加载数据集,可以使用API一键下载使用。本教程将详细介绍不同的数据集加载方式、数据集常见操作和自定义数据集方法。 %%cap
[LightOJ 1274] Beating the Dataset (期望DP)
LightOJ - 1274 题目等价于,给定一个开头为 1的 01串, 求其中相邻两个字符不相等的期望对数 一开始煞笔了,其实 YES和 NO的个数是可以直接算出来的 算出来之后,设 dp[i][j][k] dp[i][j][k]为第 i i位,jj表示当前是 YES(1)或 NO(0) k k表示 ii位及以前一共有多少个 YES,然后倒着就推出来了 下一位出现 0
HTML5 新的API 窗口可视区 scrollIntoView dataset calssList
scrollIntoView方法有两个参数 布尔值 true 和 false 使用true或者空会让调用这个方法的元素和浏览器顶部对齐 出现在可视区,使用参数false 也会出现可视区,但是不会和顶部对齐,它会和顶部有一段的距离。 调用方法: document.getElementsByTagName("ul")[0].scrollIntoView(true); ul就会出现在可视区

【Python】使用pip安装seaborn sns及失败解决方法与sns.load_dataset(“tips“)
😎 作者介绍:我是程序员洲洲,一个热爱写作的非著名程序员。CSDN全栈优质领域创作者、华为云博客社区云享专家、阿里云博客社区专家博主。 🤓 同时欢迎大家关注其他专栏,我将分享Web前后端开发、人工智能、机器学习、深度学习从0到1系列文章。 🌼 同时洲洲已经建立了程序员技术交流群,如果您感兴趣,可以私信我加入社群,可以直接vx联系(文末有名片)v:bdizztt 🖥 随时欢迎您跟我沟通

HTML5自定义属性对象Dataset简介
一、html5 自定义属性介绍 我之前翻译的“你必须知道的28个HTML5特征、窍门和技术”一文中对于HTML5中自定义合法属性data-已经做过些介绍,就是在HTML5中我们可以使用data-前缀设置我们需要的自定义属性,来进行一些数据的存放,例如我们要在一个文字按钮上存放相对应的id: <a href="javascript:" data-id="2312">测试</a> 这
BubbleML: A Multiphase Multiphysics Dataset and Benchmarks for Machine Learning
我们使用以下六个分类标准: 研究方法: 这个标准根据如何收集和分析数据来区分研究方法。 实验研究,如参考文献[64]中的研究,涉及在受控环境中研究人员操纵变量并观察结果的物理实验。这种方法对于收集真实世界的数据很有价值,但可能成本高且耗时。模拟研究利用计算模型来模拟相变现象。本文介绍的 BubbleML 数据集就是这种方法的一个例子,它提供了一种经济有效的方法来生成具有精确地面真实信息的大量数据
在DataSet中访问多个表
ADO.Net模型有一个很大的优点,就是DataSet对象可以跟踪多个表和它们之间的关系。这表示可以在一个操作的不同程序段之间传递完整的相关数据集,体系结构内在地维护数据之间关系的完整性。 ADO.Net中的DataRelation对象用于描述DataSet中的多个DataTables对象之间的关系。每个DataSet都包含DataRelations的Relations集合,以查找和操纵相关表。

Datacamp 笔记代码 Unsupervised Learning in Python 第一章 Clustering for dataset exploration
更多原始数据文档和JupyterNotebook Github: https://github.com/JinnyR/Datacamp_DataScienceTrack_Python Datacamp track: Data Scientist with Python - Course 23 (1) Exercise Clustering 2D points From the scatte

google speech command dataset的生成
GitHub - hyperconnect/TC-ResNet: Code for Temporal Convolution for Real-time Keyword Spotting on Mobile Devices 模型要分出几类: def prepare_words_list(wanted_words): """Prepends common tokens to the cu
Flink DataSet语义注解
专栏原创出处:github-源笔记文件 ,github-源码 ,欢迎 Star,转载请附上原文出处链接和本声明。 本节内容对应官方文档 ,本节内容对应示例源码 语义注解可用于为 Flink 提供有关函数行为的提示。它们告诉系统函数读取和评估函数输入的哪些字段,以及未修改的函数将哪些字段从其输入转发到输出。 语义注解是加快执行速度的强大方法,因为它们使系统能够推理出在多个操作之间重用排序
Flink DataSet分布式缓冲
专栏原创出处:github-源笔记文件 ,github-源码 ,欢迎 Star,转载请附上原文出处链接和本声明。 本节内容对应官方文档 ,本节内容对应示例源码 [[toc]] DataSet 分布式缓冲 Flink 提供了一个分布式缓存,类似于 hadoop,可以使用户在并行函数中很方便的读取本地文件,并把它放在 taskManager 节点中,防止 task 重复拉取。 执行机
Flink DataSet广播变量
专栏原创出处:github-源笔记文件 ,github-源码 ,欢迎 Star,转载请附上原文出处链接和本声明。 本节内容对应官方文档 ,本节内容对应示例源码 DataSet广播变量 重要信息:一台计算机上的并行任务之间共享广播变量数据结构。修改其内部状态的任何访问都需要由调用者手动同步 示例代码: /** 广播变量** @author Li.Wei by 2019/11/