本文主要是介绍【Python】使用pip安装seaborn sns及失败解决方法与sns.load_dataset(“tips“),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

😎 作者介绍:我是程序员洲洲,一个热爱写作的非著名程序员。CSDN全栈优质领域创作者、华为云博客社区云享专家、阿里云博客社区专家博主。
🤓 同时欢迎大家关注其他专栏,我将分享Web前后端开发、人工智能、机器学习、深度学习从0到1系列文章。
🌼 同时洲洲已经建立了程序员技术交流群,如果您感兴趣,可以私信我加入社群,可以直接vx联系(文末有名片)v:bdizztt
🖥 随时欢迎您跟我沟通,一起交流,一起成长、进步!点此也可获得联系方式~
本文目录
- 前言
- 一、Seaborn简介
- 二、代码示例
- 三、安装失败
- 问题1:pip安装错误
- 问题2:缺少依赖库
- 问题3:Seaborn版本与依赖库不兼容
- 总结
前言
Seaborn是Python中一个基于matplotlib的统计数据可视化库,它提供了一系列高级接口,用于制作有吸引力且富有表现力的统计图形。
Seaborn的sns模块包含了许多用于绘图的函数,同时提供了一些内置的数据集,例如著名的"tips"数据集。
本文将介绍如何使用pip安装Seaborn,并解决使用sns.load_dataset(“tips”)时可能遇到的一些问题。
一、Seaborn简介
Seaborn库由Michael Waskom发起,是Pandas、SciPy和matplotlib的扩展,用于制作统计图形,它能够与Pandas DataFrame对象紧密集成,使得数据可视化变得简单直观。
使用pip包管理器来安装Seaborn。在命令行中输入以下命令:
pip install seaborn
然后代码的时候导入即可:
import seaborn as sns
# seaborn的常用别名为sns。
二、代码示例
首先我们去从github上下载这个文件,官方给的范例数据库:
https://github.com/mwaskom/seaborn-data/
找到load_dataset()在本地的数据库地址。
get_data_home()函数的作用就是获取load_dataset() 的数据库地址。
>>>sns.utils.get_data_home()
之后就会出现已下形式的地址
<你的驱动器>:\Users<你的用户名>\seaborn-data
‘C:\Users\user-zhou\seaborn-data’
将下载的文件夹解压,然后把内容复制到数据库地址下。
import seaborn as sns
import matplotlib
#应用默认的主题,当然还有其他主题可以自由选择
sns.set_theme()
#载入一个范例数据集,这个数据库默认是没有的,需要自己github到下载
tips = sns.load_dataset("tips")
#创建数据可视化图片
sns.relplot(data=tips,x="total_bill", y="tip", col="time",hue="smoker", style="smoker", size="size",
)
#如果在matplotlib模式下使用Jupyter / IPython接口展示那就不需要这一条
#其他情况都请加上这一句,要不然图片不会在窗口展示,后面会说到原理
matplotlib.pyplot.show()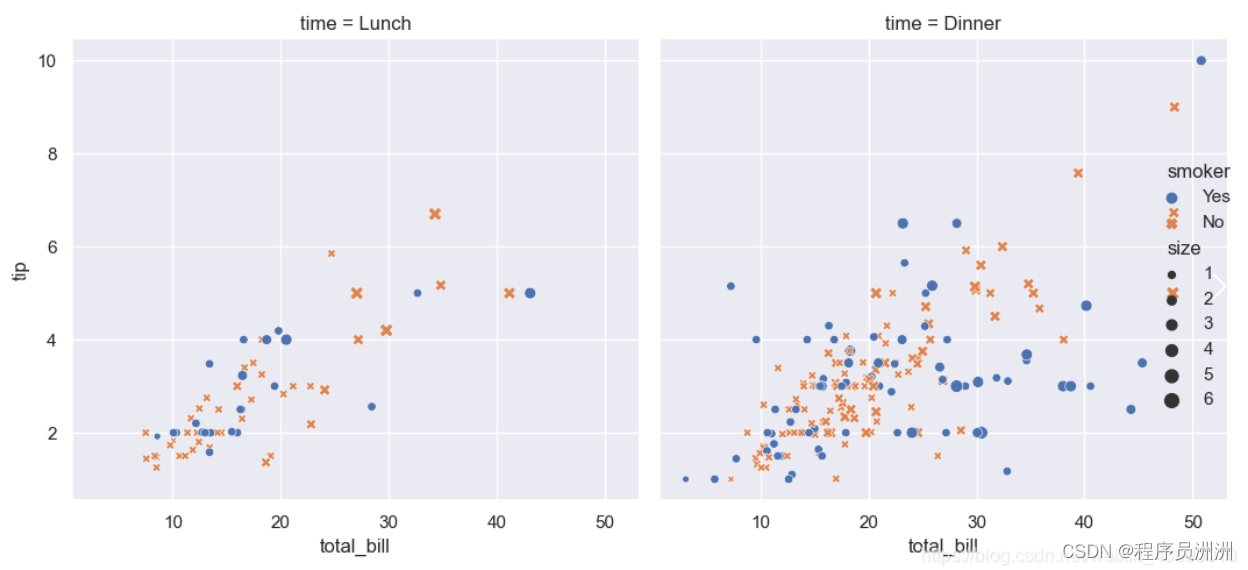
import seaborn as sns
import matplotlib.pyplot as pltdf = sns.load_dataset("penguins")
sns.pairplot(df, hue="species")
plt.show()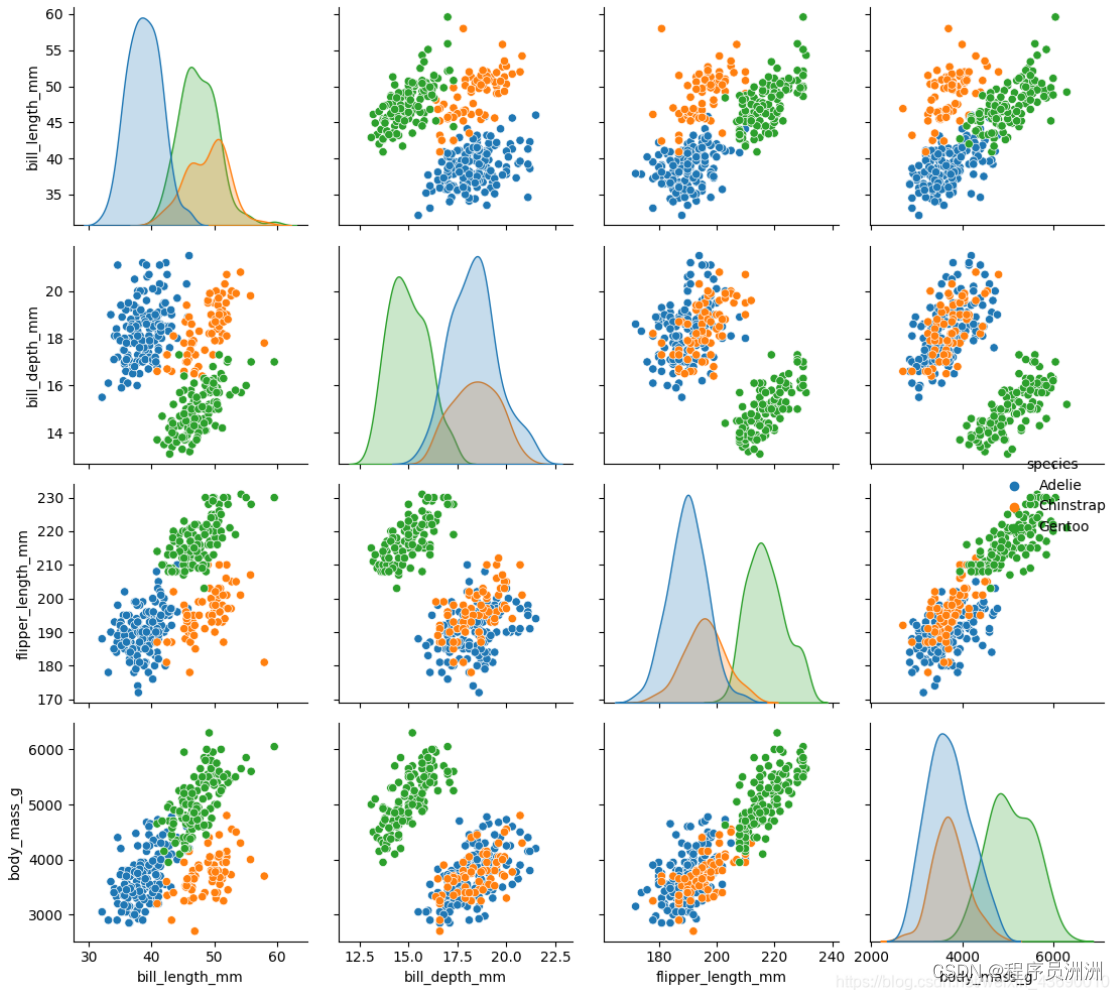
三、安装失败
问题1:pip安装错误
可能的原因:网络问题、pip版本过旧、权限不足等。
解决方法:
- 确保网络连接正常。
- 更新pip到最新版本:pip install --upgrade pip。
- 使用管理员权限运行命令行。
- 使用conda安装。
- 换梯子,大家懂得。
- 自己手机买个短时流量包,用手机热点也可以。
问题2:缺少依赖库
可能的原因:Seaborn依赖于matplotlib、Pandas、SciPy等库。
使用以下命令安装Seaborn的依赖库:
pip install matplotlib pandas scipy numpy
注意这四个库都是不可缺少的。
问题3:Seaborn版本与依赖库不兼容
可能的原因:安装的Seaborn版本与依赖库版本不兼容。
安装特定版本的Seaborn,例如:
pip install seaborn==0.11.0
总结
📝Hello,各位看官老爷们好,我已经建立了CSDN技术交流群,如果你很感兴趣,可以私信我加入我的社群。
📝社群中不定时会有很多活动,例如每周都会包邮免费送一些技术书籍及精美礼品、学习资料分享、大厂面经分享、技术讨论谈等等。
📝社群方向很多,相关领域有Web全栈(前后端)、人工智能、机器学习、自媒体副业交流、前沿科技文章分享、论文精读等等。
📝不管你是多新手的小白,都欢迎你加入社群中讨论、聊天、分享,加速助力你成为下一个大佬!
📝想都是问题,做都是答案!行动起来吧!欢迎评论区or后台与我沟通交流,也欢迎您点击下方的链接直接加入到我的交流社群!~ 跳转链接社区~

这篇关于【Python】使用pip安装seaborn sns及失败解决方法与sns.load_dataset(“tips“)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





