本文主要是介绍Spark RDD、DataFrame、DataSet区别和联系,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
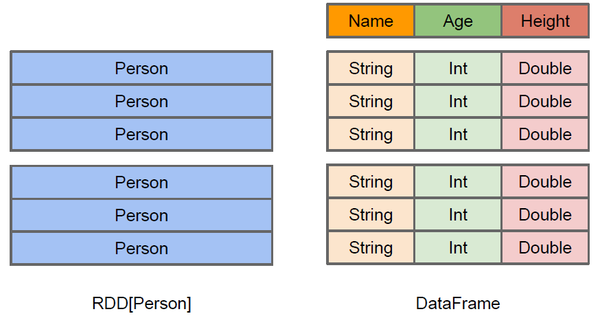
RDD
优点:
-编译时类型安全编译时就能检查出类型错误
-面向对象的编程风格
直接通过类名点的方式来操作数据
缺点:
-序列化和反序列化的性能开销无论是集群间的通信, 还是IO操作都需要对对象的结构和数据进行序列化和反序列化.
-GC的性能开销
频繁的创建和销毁对象, 势必会增加GC
---------------------------------------------------------------------------------------------------------------------------
DataFrame
DataFrame引入了schema和off-heap
schema : RDD每一行的数据, 结构都是一样的,这个结构就存储在schema中。 Spark通过schema就能够读懂数据, 因此在通信和IO时就只需要序列化和反序列化数据, 而结构的部分就可以省略了。
off-heap : 意味着JVM堆以外的内存, 这些内存直接受操作系统管理(而不是JVM)。Spark能够以二进制的形式序列化数据(不包括结构)到off-heap中, 当要操作数据时,就直接操作off-heap内存。由于Spark理解schema,所以知道该如何操作。
off-heap就像地盘,schema就像地图,Spark有地图又有自己地盘了,就可以自己说了算了,不再受JVM的限制,也就不再收GC的困扰了。
通过schema和off-heap,DataFrame解决了RDD的缺点,但是却丢了RDD的优点。DataFrame不是类型安全的,API也不是面向对象风格的。
---------------------------------------------------------------------------------------------------------------------------
DataSet
DataSet结合了RDD和DataFrame的优点,并带来的一个新的概念Encoder。
当序列化数据时,Encoder产生字节码与off-heap进行交互,能够达到按需访问数据的效果,而不用反序列化整个对象。Spark还没有提供自定义Encoder的API,但是未来会加入。
---------------------------------------------------------------------------------------------------------------------------
RDD和DataSet
DataSet以Catalyst逻辑执行计划表示,并且数据以编码的二进制形式被存储,不需要反序列化就可以执行sorting、shuffle等操作。
DataSet创立需要一个显式的Encoder,把对象序列化为二进制,可以把对象的scheme映射为Spark SQL类型,然而RDD依赖于运行时反射机制。
DataSet比RDD性能要好很多。
DataFrame和DataSet
Dataset可以认为是DataFrame的一个特例,主要区别是Dataset每一个record存储的是一个强类型值而不是一个Row。因此具有如下三个特点:
DataSet可以在编译时检查类型
DataSet是面向对象的编程接口。
后面版本DataFrame会继承DataSet,DataFrame是面向Spark SQL的接口。
DataFrame和DataSet可以相互转化,df.as[ElementType]这样可以把DataFrame转化为DataSet,ds.toDF()这样可以把DataSet转化为DataFrame。
这篇关于Spark RDD、DataFrame、DataSet区别和联系的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





