dataframe专题

pandas DataFrame keys的使用小结
《pandasDataFramekeys的使用小结》pandas.DataFrame.keys()方法返回DataFrame的列名,类似于字典的键,本文主要介绍了pandasDataFrameke... 目录Pandas2.2 DataFrameIndexing, iterationpandas.DataF

Python中DataFrame转列表的最全指南
《Python中DataFrame转列表的最全指南》在Python数据分析中,Pandas的DataFrame是最常用的数据结构之一,本文将为你详解5种主流DataFrame转换为列表的方法,大家可以... 目录引言一、基础转换方法解析1. tolist()直接转换法2. values.tolist()矩阵
Python使用Pandas库将Excel数据叠加生成新DataFrame的操作指南
《Python使用Pandas库将Excel数据叠加生成新DataFrame的操作指南》在日常数据处理工作中,我们经常需要将不同Excel文档中的数据整合到一个新的DataFrame中,以便进行进一步... 目录一、准备工作二、读取Excel文件三、数据叠加四、处理重复数据(可选)五、保存新DataFram

【python pandas】 Dataframe的数据print输出 显示为...省略号
pandas.set_option() 可以设置pandas相关的参数,从而改变默认参数。 打印pandas数据事,默认是输出100行,多的话会输出….省略号。 那么可以添加: pandas.set_option('display.max_rows',None) 这样就可以显示全部数据 同样,某一列比如url太长 显示省略号 也可以设置。 pd.set_option('display.

SparkRDD转DataSet/DataFrame的一个深坑
大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! By 大数据技术与架构 场景描述:本文是根据读者反馈的一个问题总结而成的。 关键词:Saprk RDD 原需求:希望在map函数中将每一
Pyspark DataFrame常用操作函数和示例
针对类型:pyspark.sql.dataframe.DataFrame 目录 1.打印前几行 1.1 show()函数 1.2 take()函数 2. 读取文件 2.1 spark.read.csv 3. 获取某行某列的值(具体值) 4.查看列名 5.修改列名 5.1 修改单个列名 5.2 修改多个列名 5.2.1 链式调用 withColumnRenamed 方法 5.2.2 使用
rdd,dataframe,dataset之间的区别
在spark中,RDD、DataFrame、Dataset是最常用的数据类型,本博文给出笔者在使用的过程中体会到的区别和各自的优势 共性: 1、RDD、DataFrame、Dataset全都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利 2、三者都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action如foreach时,三者才会开始
pandas.concat实现竖着拼接、横着拼接DataFrame
1、concat竖着拼接(默认的竖着,axis=0) 话不多说,直接看例子: import pandas as pddf1=pd.DataFrame([10,12,13])df2=pd.DataFrame([22,33,44,55])df3=pd.DataFrame([90,94]) df1 0010112213 df2 0022133244355 df3
Anndata: AttributeError: ‘DataFrame’ object has no attribute ‘dtype’
Anndata: AttributeError: ‘DataFrame’ object has no attribute ‘dtype’ 背景解决方法 背景 在使用anndata做切片时,比如下面这样的例子 sub_rna = rna[:10] # rna is anndata 出现如下报错: AttributeError: ‘DataFrame’ object has

spark之DataFrame
1、DataFrame的优点 DataFrame的推出,让Spark具备了处理大规模结构化数据的能力,不仅比原有的RDD转化方式更加简单易用,而且获得了更高的计算性能。Spark能够轻松实现从MySQL到DataFrame的转化,并且支持SQL查询。Spark使用全新的SparkSession接口替代Spark1.6中的SQLContext及HiveContext接口来实现其对数据加载、转换、处
如何为 Polar DataFrame 着色
继续使用 Polars 库,同时能够为表格添加颜色和样式 本文中的示例展示了 Polars 表格在样式调整前后的对比 欢迎来到雲闪世界。自 2022 年 Polars 库发布以来,它作为超高速 DataFrame 库迅速流行起来。与 Pandas 相比,白熊经过测试,速度更快。根据Polars 官方网站的说法,它声称性能提升了 30 倍以上。 然而,没有什么是
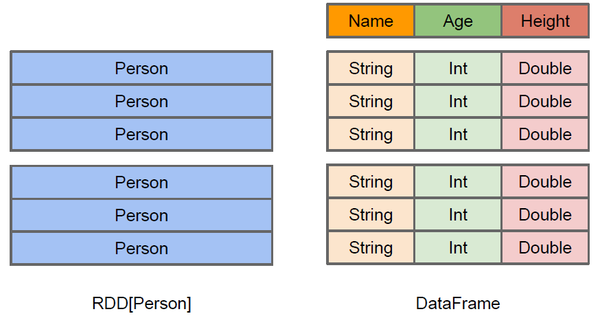
Spark RDD、DataFrame、DataSet区别和联系
左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。DataFrame多了数据的结构信息,即schema。RDD是分布式的Java对象的集合。DataFrame是分布式的Row对象的集合。Data
25. 重命名dataframe的索引
哈喽,大家好,我是木头左! 1. 为什么要重命名dataframe的索引? 在数据分析过程中,经常会遇到需要对dataframe进行重命名索引的情况。以下是一些常见的原因: 提高代码的可读性:使用有意义的索引名称可以使代码更易于理解和维护。避免重复索引:当多个dataframe具有相同的列名时,重命名索引可以避免混淆。与其他库的兼容性:某些库可能要求使用特定的索引名称或格式。 2.
如何理解spark中RDD和DataFrame的结构?
RDD中可以存储任何的单机类型的数据,但是,直接使用RDD在字段需求明显时,存在算子难以复用的缺点。 例如,现在RDD存的数据是一个Person类型的数据,现在要求所有每个年龄段(10年一个年龄段)的人中最高的身高与最大的体重。 使用RDD接口,因为RDD不了解其中存储的数据的具体结构,数据的结构对它而言是黑盒,于是这就需要用户自己去写一个很特化的聚合的函数来完成这样的功能。 而有了Dat
24. 重置dataframe的索引
哈喽,大家好,我是木头左! 在数据分析和处理过程中,经常需要对dataframe进行各种操作,其中之一就是重置索引。重置索引可以帮助更好地管理和组织数据,提高数据处理的效率。本文将详细介绍如何使用pandas库中的reset_index()函数来重置dataframe的索引。 1. reset_index()函数简介 reset_index()函数是pandas库中的一个内置函数,用于重
Pandas之DataFrame操作
Pandas是Python下一个开源数据分析的库,它提供的数据结构DataFrame极大的简化了数据分析过程中一些繁琐操作。 1. 基本使用:创建DataFrame. DataFrame是一张二维的表,大家可以把它想象成一张Excel表单或者Sql表。Excel 2007及其以后的版本的最大行数是1048576,最大列数是16384,超过这个规模的数据Excel就会弹出个框框“此文本包含多
python pandas.DataFrame 数据合并
# -*- coding: utf-8 -*-# encoding=utf-8from __future__ import divisionimport numpy as npimport xlwtimport os# 导入matplot 函数import matplotlib.pyplot as matplot_pyplot# 导入拉格朗日插值函数from scipy.int

一文让你记住Pyspark下DataFrame的7种的Join 效果
最近看到了一片好文,虽然很简单,但是配上的插图可以让人很好的记住Pyspark 中的多种Join 类型和实际的效果。原英文链接 Introduction to Pyspark join types - Blog | luminousmen 。 假设使用如下的两个DataFrame 来进行展示 heroes_data = [('Deadpool', 3), ('Iron man', 1),('G

python之dataframe需要注意的细节
(1)通过as_index=False,groupby的列名'GLBDOMAIN'将不作为索引出现在结果中 agv_1930_df=data_1930_df.groupby(['GLBDOMAIN'],as_index=False)[['EDGE_BW']].mean() (2)按行删除存在缺失数据的行(dataframe) data_1930_df.dr

python之dataframe的行列转换(将多列转换成多行将多行转换成多列)
1、将多列转换成多行 data=pd.read_excel(path) data=data.set_index(['flag','region']) data=data.stack() data.index=data.index.rename('Time',level=2) data.name='ed_bw' data=data.reset_index() 2、将多行转换成多

18. 分割dataframe:让数据分析更高效
哈喽,大家好,我是木头左! 如何分割dataframe? 在pandas中,可以使用groupby函数来分割dataframe。groupby函数可以将dataframe中的行按照指定的列进行分组,然后可以对每个组进行各种操作。 下面是一个简单的例子,将一个包含年龄和性别的dataframe按照性别进行分割: import pandas as pd# 创建一个包含年龄和性别的data

基于swifter多内核的加速Pandas DataFrame操作运行
swifter是提高pandas性能的第三方包,主要是apply函数。 接口支持范围: 运行环境和安装 操作系统是Win10 64,pandas版本是2.2.2,swifter版本是1.4.0。 pip安装 $ pip install -U pandas # upgrade pandas$ pip install swifter # first time installation$

Pandas DataFrame 数据转换处理和多条件查询
工作中需要处理一个比较大的数据,且当中需要分析的日期类型字段为字符串型,需要进行转换,获得一个新的字段用于时间统计。我们应用 datetime.datetime.strptime 函数进行转换。 数据读取与时间列补充代码如下: import pandas as pdimport datetimedf = pd.read_csv('SCADA_HISTORY.csv')# 给DataFram
python中dataframe的iloc和loc的使用区别
文章目录 `.iloc` 和 `.loc` 的基本用法`.iloc``.loc` 示例代码和解释使用 `.iloc`使用 `.loc` 总结 .iloc 和 .loc 的基本用法 .iloc 用于通过位置(整数位置)来选择数据。iloc 索引基于行和列的整数位置。 常用语法 data.iloc[i, j]:选择第 i 行第 j 列的元素,若索引下标从0开始,对应的是第
Python的sqldf( ) 像SQL一样操作DataFrame
当你对Python的DataFrame操作不熟悉,或者对pandas应用不熟悉时,想一想,要是能像sql操作表一样多好! python中的sqldf()跟R语言中的sqldf一样就是为了方便操作表格,用sql的语法来操作表格 。 from pandasql import sqldf 问题:现在有两个表,想将A表与B表左外连接 。 如下即可: merge_data_sql = sqldf("
Python将DataFrame的每一行组成元组
# merge_result is DataFramemerge_result_tuples = [tuple(xi) for xi in merge_result.values] # output: (datetime.date(2018, 11, 19), Timestamp('2018-11-19 07:37:31'), 1231, 89244241)