本文主要是介绍如何为 Polar DataFrame 着色,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
继续使用 Polars 库,同时能够为表格添加颜色和样式

欢迎来到雲闪世界。自 2022 年 Polars 库发布以来,它作为超高速 DataFrame 库迅速流行起来。与 Pandas 相比,白熊经过测试,速度更快。根据Polars 官方网站的说法,它声称性能提升了 30 倍以上。
然而,没有什么是完美的。Polars 库似乎有一些限制。
在表格样式方面,Polars 提供的选项较少,而 Pandas 则有内置样式器。如果要为 Polars DataFrame 着色,一种简单的解决方案是将表格转换为 Pandas。
但是等等...如果某些代码需要稍后运行怎么办?
本文中的示例展示了 Polars 表格在样式调整前后的对比
这意味着我们必须运行 Pandas,这会导致速度大幅下降。另一种选择是在设置样式后将表格转换回 Polars。然后,如果我们想要设置结果的样式,则必须重复相同的过程。尽管这些解决方案有效,但它们非常不方便。 幸运的是,有一个名为“ Great Tables ”的包可以直接应用于 Polars 表。此包允许我们在使用 Polars 库时创建美观的表格。 本文将逐步指导如何使用 Great Tables 包来设置 Polars 表格的样式。 让我们开始吧!!
导入库
首先获取我们要使用的库。Great Tables 包是在MIT许可下使用的。
numpy as np
import polars as pl
import polars.selectors as cs
import re
import wikipedia
import pandas as pdfrom great_tables import GT
from great_tables import style, loc获取数据
为了说明本文解释的方法可以应用于现实世界的数据,我将使用来自维基百科的“按国家划分的风力发电量”数据。 首先,让我们使用Wikipedia 库来检索 HTML 数据。然后,我们将使用 Pandas 读取数据,然后将其转换为 Polars DataFrame。Wikipedia 中的数据在CC BY-SA 4.0国际许可下使用。 如果您想尝试其他数据集,可以跳过此步骤。
wikiurl = 'https://en.wikipedia.org/wiki/Wind_power_by_country'
tables = pd.read_html(wikiurl)
df = pl.DataFrame(tables[4])
df
添加图片注释,不超过 140 字(可选)
由于行数较多,我将重点关注Cap. (GW)值高于 5 的国家。显示世界数据的第一行也将被删除。以下代码显示如何过滤 Polars DataFrame。 如果您想选择其他列或使用其他值进行过滤,请随意修改下面的代码。
no_list = ['World']
df = df.filter(pl.col('Cap. (GW)') > 6)
df = df.filter(~pl.col('Country').is_in(no_list))
df使用出色的表格显示 Polars DataFrame 现在 Polars 表已经准备好了,让我们尝试使用 Great Tables 包显示该表。
gt_df = GT(df)
gt_df
添加图片注释,不超过 140 字(可选)
接下来,让我们做一些基本的修改,例如添加标题并将% cap. growth列中的最大值加粗。
list_cap = list(df['% cap. growth'])
max_idx = str(list_cap.index(max(list_cap))) ## Get the maximum valuestr_txt = 'gt_df\
.tab_header(title = "Wind power generation by country 2023")\
.tab_style(style.text(weight = "bold", color="black"), \
loc.body("% cap. growth", '+ max_idx + '))'tb = eval(str_txt)
tb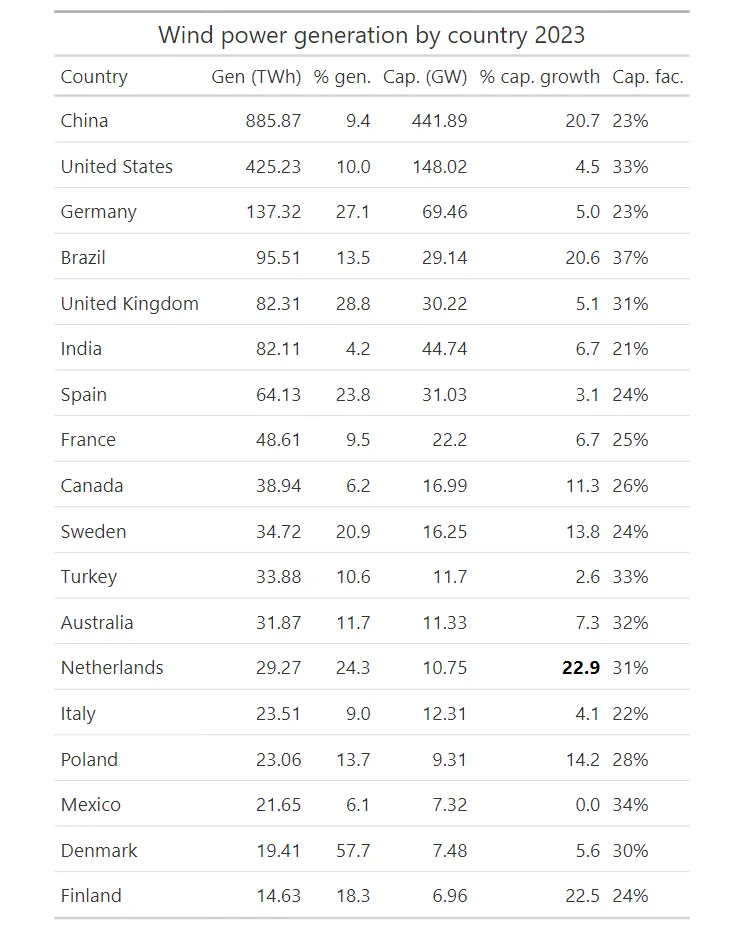
添加图片注释,不超过 140 字(可选)
使用精美表格为 Polars DataFrame 着色 为了给表格着色,我们需要从调色板中创建颜色列表。如以下代码所示,本文将使用“夏季”调色板。也可以使用其他调色板,例如“ coolwarm ”或“ viridis ”。 提取的颜色数量为 101 种,因为下一步我们将把列中的最小-最大值缩放到 0-100。然后,枚举获得的颜色列表以创建字典以供稍后使用。
import seaborn as sns
colors = list(sns.color_palette(palette='summer_r', n_colors=101).as_hex())
dict_colors = dict(enumerate(colors))下一步,我们将缩放% cap. growth列中的值。最小值为 0,最大值为 100。之后,使用颜色词典为每个缩放值分配颜色代码。
n_cap = max(list_cap) - min(list_cap)percentage_cap = [int((i-min(list_cap))*100/n_cap) for i in list_cap]
colors_cap = [dict_colors.get(p) for p in percentage_cap]接下来是着色过程,将使用 for 循环函数创建多个文本代码。每个代码用于根据颜色词典为每一行分配一种颜色。之后,将每个创建的文本合并为一个文本代码进行运行。
keep_txt = []
col_name = '% cap. growth'
idx = list(range(len(df)))str_txt = 'gt_df\
.tab_header(title = "Wind power generation by country 2023")\
.tab_style(style.text(weight="bold", color="white"),loc.body("% cap. growth",'+ max_idx + '))'for i,c in zip(idx, colors_cap):txt='.tab_style(style.fill("'+ c +'"),loc.body(columns="'+ col_name +'",rows='+ str(i) + '))'keep_txt.append(txt)df_txt = str_txt + ''.join(keep_txt)
tb = eval(df_txt)
tb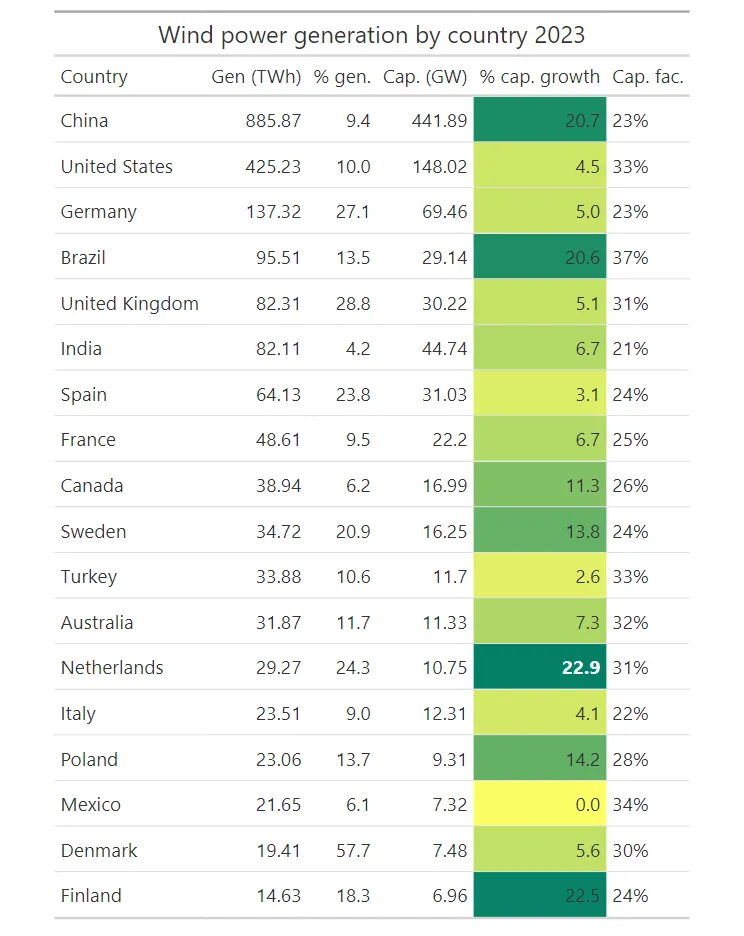
添加图片注释,不超过 140 字(可选)
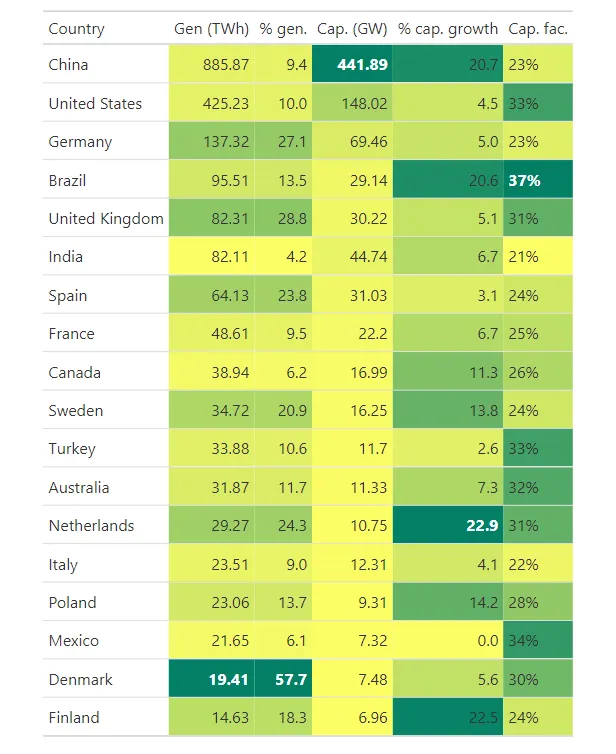
从结果中,我们很容易发现,2023 年荷兰的资本增长率最高。深绿色区域还帮助我们看到荷兰附近其他高值国家。相反,亮黄色区域告诉我们低值在哪里。 现在让我们对% gen列应用相同的过程来显示此类别中百分比最高的国家。
list_gen = list(df['% gen.'])
n_gen = max(list_gen) - min(list_gen)
colors_gen = [dict_colors.get(int((i-min(list_gen))*100/n_gen)) for i in list_gen]col_name = '% gen.'
idx_gen = str(list_gen.index(max(list_gen)))
txt_bold='.tab_style(style.text(weight="bold",color="white"),loc.body("'+ col_name +'",'+ idx_gen + '))'keep_txt = []
idx = list(range(len(df)))for i,c in zip(idx, colors_gen):txt='.tab_style(style.fill("'+ c +'"),loc.body(columns = "'+ col_name +'",rows='+ str(i) + '))'keep_txt.append(txt)df_txt2 = df_txt + txt_bold + ''.join(keep_txt)
tb = eval(df_txt2)
tb
添加图片注释,不超过 140 字(可选)
我们很快注意到,丹麦在% gen列中的值最高。通过此列中的颜色,我们可以知道,没有其他国家的% gen值接近丹麦,因为没有其他深绿色显示。 现在您已经了解了为 DataFrame 着色的步骤和获得的结果。接下来,让我们将相同的概念应用于其他列。 然后,我们来谈谈在餐桌上添加颜色的好处。
list_gen = list(df['% gen.'])
n_gen = max(list_gen) - min(list_gen)
colors_gen = [dict_colors.get(int((i-min(list_gen))*100/n_gen)) for i in list_gen]col_name = '% gen.'
idx_gen = str(list_gen.index(max(list_gen)))
txt_bold='.tab_style(style.text(weight="bold",color="white"),loc.body("'+ col_name +'",'+ idx_gen + '))'keep_txt = []
idx = list(range(len(df)))for i,c in zip(idx, colors_gen):txt='.tab_style(style.fill("'+ c +'"),loc.body(columns = "'+ col_name +'",rows='+ str(i) + '))'keep_txt.append(txt)df_txt2 = df_txt + txt_bold + ''.join(keep_txt)
tb = eval(df_txt2)
tb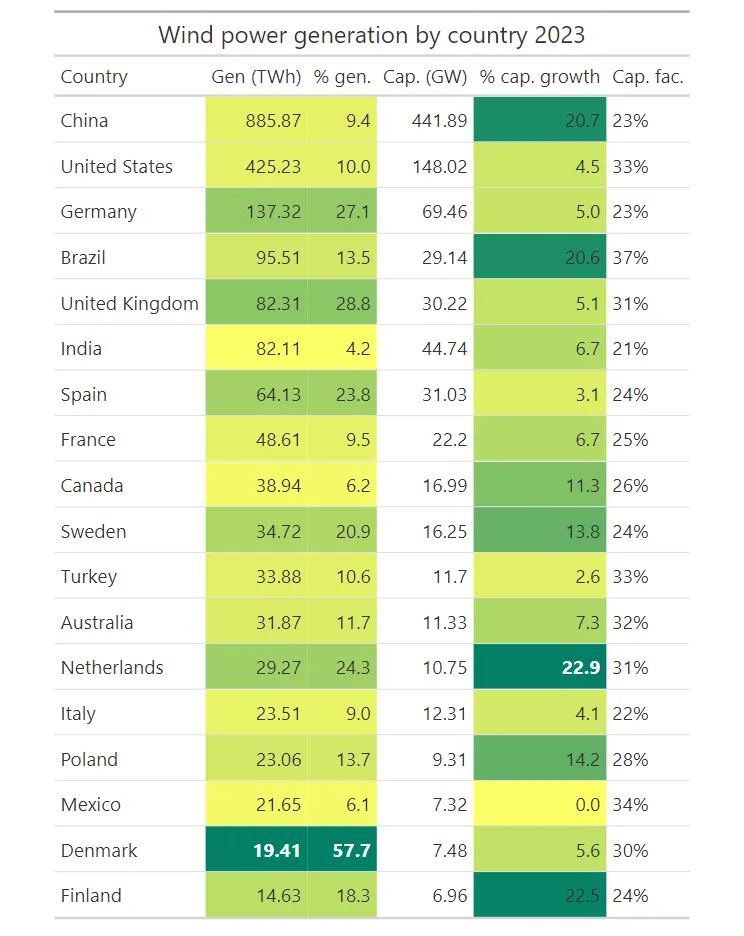
添加图片注释,不超过 140 字(可选)
list_gen = list(df['Cap. (GW)'])
n_gen = max(list_gen) - min(list_gen)
colors_gen = [dict_colors.get(int((i-min(list_gen))*100/n_gen)) for i in list_gen]col_name = 'Cap. (GW)'
idx_gen = str(list_gen.index(max(list_gen)))
txt_bold='.tab_style(style.text(weight = "bold",color="white"),loc.body("'+ col_name +'",'+ idx_gen + '))'keep_txt = []
idx = list(range(len(df)))for i,c in zip(idx, colors_gen):txt='.tab_style(style.fill("'+ c +'"), loc.body(columns="'+ col_name +'",rows='+ str(i) + '))'keep_txt.append(txt)df_txt4 = df_txt3 + txt_bold + ''.join(keep_txt)
tb = eval(df_txt4)
tb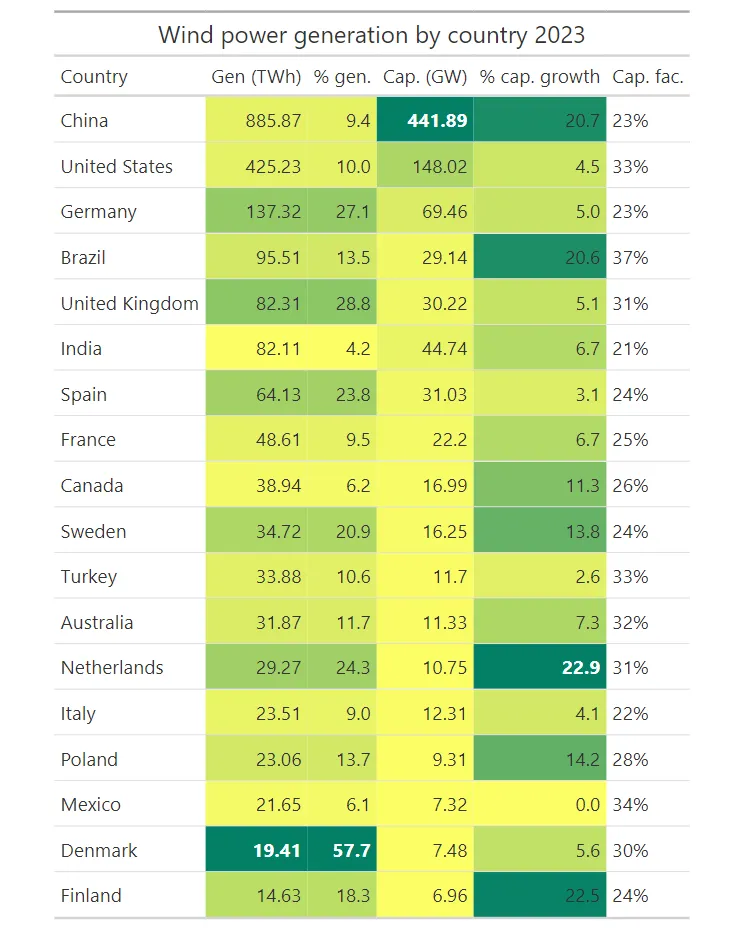
添加图片注释,不超过 140 字(可选)
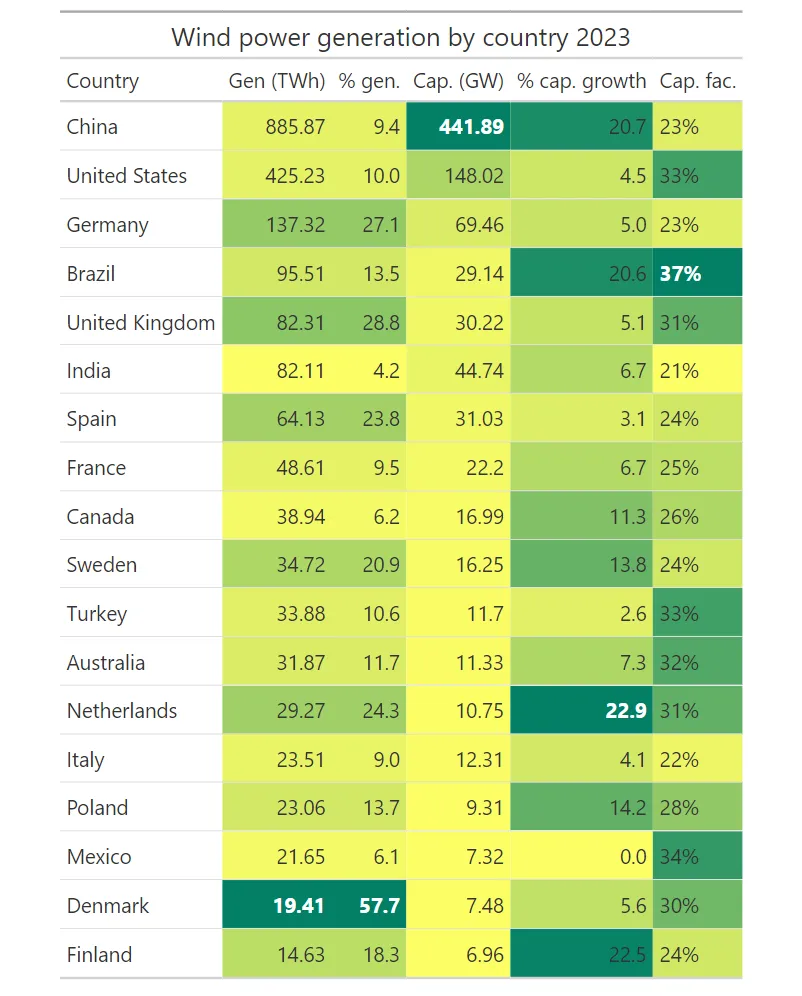
最后,对每一列应用相同的方法后,我们将得到一个如下所示的表格。
list_gen = [int(i[0:2]) for i in list(df['Cap. fac.'])]
n_gen = max(list_gen) - min(list_gen)
colors_gen = [dict_colors.get(int((i-min(list_gen))*100/n_gen)) for i in list_gen]col_name = 'Cap. fac.'
idx_gen = str(list_gen.index(max(list_gen)))
txt_bold='.tab_style(style.text(weight="bold",color="white"),loc.body("'+ col_name +'",'+ idx_gen + '))'keep_txt = []
idx = list(range(len(df)))for i,c in zip(idx, colors_gen):txt='.tab_style(style.fill("'+ c +'"),loc.body(columns="'+ col_name +'",rows='+ str(i) + '))'keep_txt.append(txt)df_txt5 = df_txt4 + txt_bold + ''.join(keep_txt)
tb = eval(df_txt5)
tb瞧…!!
添加图片注释,不超过 140 字(可选)
从结果可以看出,突出显示表格有助于我们浏览表格。可以快速注意到每列中的最高值。添加颜色标尺还可以帮助我们找到高值和低值的位置。 此外,与原来的表格相比,这些颜色使表格看起来更有趣。
感谢关注雲闪世界。(Aws解决方案架构师vs开发人员&GCP解决方案架构师vs开发人员)
这篇关于如何为 Polar DataFrame 着色的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




