rdd专题

RDD的map和flatMap
在 Apache Spark 中,map 和 flatMap 是 RDD(弹性分布式数据集)中最常用的转换操作之一。 map 假设你有一个包含整数的 RDD,你想要计算每个元素的平方。 from pyspark import SparkContextsc = SparkContext(appName="MapExample")# 创建一个包含整数的 RDDnumbers = sc.para

rdd,dataframe,dataset之间的区别
在spark中,RDD、DataFrame、Dataset是最常用的数据类型,本博文给出笔者在使用的过程中体会到的区别和各自的优势 共性: 1、RDD、DataFrame、Dataset全都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利 2、三者都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action如foreach时,三者才会开始

Spark Mllib之数据类型 - 基于RDD的API
微信公众号:数据挖掘与分析学习 MLlib支持存储在单个机器上的局部向量和矩阵,以及由一个或多个RDD支持的分布式矩阵。局部向量和局部矩阵是用作公共接口的简单数据模型。其底层线性代数运算由Breeze提供。在监督学习中使用的训练示例在MLlib中称为“labeled point”。 1.局部向量(Local Vector) 局部向量具有整数类型和基于0的索引和双精度浮点型,存储在单个机器上。
Spark Mllib之基本统计 - 基于RDD的API
1.概要统计(Summary statistics) 我们通过Statistics中提供的函数colStats为RDD [Vector]提供列摘要统计信息。 colStats()返回MultivariateStatisticalSummary的一个实例,其中包含列的max,min,mean,variance和非零数,以及总计数。 SparkConf conf = new SparkConf

Spark02:RDD的实现
公众号:数据挖掘与机器学习笔记 1.作业调度 在执行转换操作的RDD时,调度器会根据RDD的“血统”来构建若干由stage组成的有向无环图(DAG),每个stage阶段包含若干个连续窄依赖转换。调度器按照DAG顺序进行计算得到最终的RDD。 调度器向各节点分配任务采用延时调度机制并根据数据存储位置(数据本地性)来确定。如果一个任务需要处理的某个分区刚好存储在相应节点的内存中,则该任务会分配给
Spark03:RDD编程接口
公众号:数据挖掘与机器学习笔记 Spark中提供了通用接口来抽象每个RDD,包括: 分区信息:数据集的最小分片依赖关系:指向其父RDD函数:基于父RDD的计算方法划分策略和数据位置的元数据 1.RDD分区 RDD的分区是一个逻辑概念,变换前后的新旧分区在物理上可能是同一块内存或存储,这种优化防止函数式不变性导致的内存需求无限扩张。在RDD操作中可以使用Partitions方法获取RDD
spark之键值对RDD
1、键值对RDD生成方式 1.1、通过map函数来生成 通过map函数将x映射为(x,1) #在本地进行操作textFile = sc.textFile("file:///home/jsy/spark_test/test.txt")wordCount = textFile.flatMap(lambda line: line.split(" ")).map(lambda x:(x,1))

Spark技术内幕:究竟什么是RDD
RDD是Spark最基本,也是最根本的数据抽象。http://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf 是关于RDD的论文。如果觉得英文阅读太费时间,可以看这篇译文:http://shiyanjun.cn/archives/744.html 本文也是基于这篇论文和源码,分析RDD的实现。 第一个问题,RDD是什么?Resili
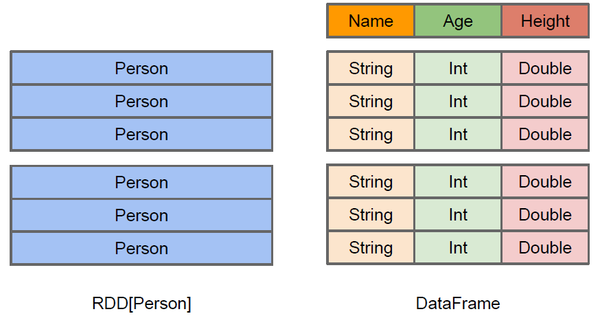
Spark RDD、DataFrame、DataSet区别和联系
左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。DataFrame多了数据的结构信息,即schema。RDD是分布式的Java对象的集合。DataFrame是分布式的Row对象的集合。Data
如何理解spark中RDD和DataFrame的结构?
RDD中可以存储任何的单机类型的数据,但是,直接使用RDD在字段需求明显时,存在算子难以复用的缺点。 例如,现在RDD存的数据是一个Person类型的数据,现在要求所有每个年龄段(10年一个年龄段)的人中最高的身高与最大的体重。 使用RDD接口,因为RDD不了解其中存储的数据的具体结构,数据的结构对它而言是黑盒,于是这就需要用户自己去写一个很特化的聚合的函数来完成这样的功能。 而有了Dat
Spark RDD Actions操作之reduce()
textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b) The arguments to reduce() are Scala function literals (closures)。 reduce将RDD中元素两两传递给输入函数? 同时产生一个新的值,新产生的值与RDD中下一个
Spark学习笔记 --- RDD的创建
Spark所有的操作都围绕弹性分布式数据集(RDD)进行,这是一个有容错机制并可以被并行操作的元素集合, 具有只读、分区、容错、高效、无需物化、可以缓存、RDD依赖等特征。 目前有两种类型的基础RDD: 并行集合(Parallelized Collections):接收一个已经存在的Scala集合,然后进行各种并行计算。 Hadoop数据集(Hadoop Datasets
Spark学习笔记 --- spark RDD加载文件
对于Spark RDD加载的文件,可以分为几类: 首先加载本地文件,加载方式: val localFileRDD = sc.textFile("file://usr/wordcount.txt") 其次加载hdfs文件,加载方式: val textHDFSFile = sc.textFile("/user/README.md") 或者:
Spark学习笔记整理 --- 2018-06-22【RDD的设计与运行原理】
Spark的核心是建立在统一的抽象RDD之上,使得Spark的各个组件可以无缝进行集成,在同一个应用程序中完成大数据计算任务。RDD的设计理念源自AMP实验室发表的论文《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》。 1.RDD设计背景 在实际应
理解Spark-RDD共享变量 --- Shared Variables
通常,当在远程集群节点上执行传递给Spark操作(例如map或reduce)的函数时,它将在函数中使用的所有变量的单独副本上工作。 这些变量将复制到每台计算机,并且远程计算机上的变量的更新不会传播回驱动程序。 支持跨任务的通用,读写共享变量效率低下。 但是,Spark确实为两种常见的使用模式提供了两种有限类型的共享变量:广播变量和累加器。 1.广播变量-Broadcast Vari
理解Spark-RDD持久化
1.Spark中最重要的功能之一是跨操作在内存中持久化(或缓存)数据集。当数据持久保存在RDD时,每个节点都会存储它在内存中计算的任何分区, 并在该数据集(或从中派生的数据集)的其他操作中重用它们。这使得特性函数的Action更快(通常超过10倍)。缓存是迭代算法和快速交互式使用的关键工具。 2.可以使用persist()或cache()方法标记要保留的RDD。 第一次在动作中计算它,它
理解Spark-RDD的Shuffle操作
1.Spark中的某些操作会触发称为shuffle的事件。 随机广播是Spark的重新分发数据的机制,因此它可以跨分区进行不同的分组。 这通常涉及跨执行程序和机器复制数据,使得Shuffle成为复杂且昂贵的操作。 2.为了理解在shuffle期间发生的事情,我们可以考虑reduceByKey操作的示例。 reduceByKey操作生成一个新的RDD, 其中单个键的所有值都组合成一个元组 -

理解Spark的RDD算子
什么是Spark的算子呢?说简单一些就是Spark内部封装了一些处理RDD数据的函数方法。 其中算子又分为两部分: Transformation 与 Actions Transformation(转换):Transformation属于延迟计算,当一个RDD转换成另一个RDD时并没有立即进行转换,仅仅是记住了数据集的逻辑操作 Action(执行):触发Spark作业的运行,真
理解Spark中RDD(Resilient Distributed DataSet)
1。Spark围绕弹性分布式数据集(RDD)的概念展开,RDD是一个可以并行操作的容错的容错集合。 创建RDD有两种方法:并行化驱动程序中的现有集合,或引用外部存储系统中的数据集,例如共享文件系统,HDFS,HBase或提供Hadoop InputFormat的任何数据源。 val sc = spark.sparkContext // 已有内部数据源val data = Array(1, 2,
RDD论文翻译 --弹性分布式数据集:一种基于内存的集群计算的容错性抽象方法
原文出处:http://www.eecs.berkeley.edu/Pubs/TechRpts/2011/EECS-2011-82.pdf 译文原处:http://blog.csdn.net/cj7749910/article/details/51115063 摘要 我们提出的弹性分布式数据集(RDDs),是一个让程序员在大型集群上以容错的方式执行基于
Spark算子:RDD行动Action操作(3)–aggregate、fold、lookup
aggregate def aggregate[U](zeroValue: U)(seqOp: (U, T) ⇒ U, combOp: (U, U) ⇒ U)(implicit arg0: ClassTag[U]): U aggregate用户聚合RDD中的元素,先使用seqOp将RDD中每个分区中的T类型元素聚合成U类型,再使用combOp将之前每个分区聚合后的U类型聚合成U类型,特别注意se
Spark算子:RDD键值转换操作(4)–cogroup/join
cogroup 函数原型:最多可以组合4个RDD,可以通过partitioner和numsPartitions设置 def cogroup[W1, W2, W3](other1: RDD[(K, W1)], other2: RDD[(K, W2)], other3: RDD[(K, W3)], partitioner: Partitioner) :RDD[(K, (Iterable[V],
Spark算子:RDD键值转换操作(3)–groupByKey、reduceByKey、reduceByKeyLocally
groupByKey def groupByKey(): RDD[(K, Iterable[V])] def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])] def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] 该函数用于将RDD[K,V]中每个K对应
Spark算子:RDD键值转换操作(1)–partitionBy、mapValues、flatMapValues
partitionBy def partitionBy(partitioner: Partitioner): RDD[(K, V)] 该函数根据partitioner函数生成新的ShuffleRDD,将原RDD重新分区。 scala> var rdd1 = sc.makeRDD(Array((1,"A"),(2,"B"),(3,"C"),(4,"D")),2)rd
Spark算子:RDD基本转换操作(6)–zip、zipPartitions
zip def zip[U](other: RDD[U])(implicit arg0: ClassTag[U]): RDD[(T, U)] zip函数用于将两个RDD组合成Key/Value形式的RDD,这里默认两个RDD的partition数量以及元素数量都相同,否则会抛出异常。 scala> var rdd1 = sc.makeRDD(1 to 10,2)