large专题

论文翻译:arxiv-2024 Benchmark Data Contamination of Large Language Models: A Survey
Benchmark Data Contamination of Large Language Models: A Survey https://arxiv.org/abs/2406.04244 大规模语言模型的基准数据污染:一项综述 文章目录 大规模语言模型的基准数据污染:一项综述摘要1 引言 摘要 大规模语言模型(LLMs),如GPT-4、Claude-3和Gemini的快

高精度打表-Factoring Large Numbers
求斐波那契数,不打表的话会超时,打表的话普通的高精度开不出来那么大的数组,不如一个int存8位,特殊处理一下,具体看代码 #include<stdio.h>#include<string.h>#define MAX_SIZE 5005#define LEN 150#define to 100000000/*一个int存8位*/int num[MAX_SIZE][LEN];void
![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)
[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval
引言 今天带来北京智源研究院(BAAI)团队带来的一篇关于如何微调LLM变成密集检索器的论文笔记——Making Large Language Models A Better Foundation For Dense Retrieval。 为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。 密集检索需要学习具有区分性的文本嵌入,以表示查询和文档之间的语义关系。考虑到大语言模

教育LLM—大型教育语言模型: 调查,原文阅读:Large Language Models for Education: A Survey
Large Language Models for Education: A Survey 大型教育语言模型: 调查 paper: https://arxiv.org/abs/2405.13001 文章目录~ 原文阅读Abstract1 Introduction2 Characteristics of LLM in Education2.1.Characteristics of LLM

Large Language Models(LLMs) Concepts
1、Introduction to Large Language Models(LLM) 1.1、Definition of LLMs Large: Training data and resources.Language: Human-like text.Models: Learn complex patterns using text data. The LLM is conside

2024年Linux内核社区关于large folio和mthp的关键进展
1. 概述 在 Linux 内核中,一个 folio 可以只包含 1 个 page,也可以包含多个 page。当一个 folio 包含多个 page 的时候,我们称它为一个 large folio,在中文社区,我们一般称呼其为大页。采用 large folio 可潜在带来诸多好处,比如: 1. TLB miss 减小,比如许多硬件都支持 PMD 映射,可以直接把 2MB 做成一个 lar

论文笔记:LONG-FORM FACTUALITY IN LARGE LANGUAGE MODELS
Abstract 当前存在问题,大模型在生成关于开放主题的事实寻求问题的时候经常存在事实性错误。 LongFact 创建了LongFact用于对各种主题的长形式事实性问题进行基准测试。LongFact是一个prompt集包含38个领域的数千条提示词,使用GPT-4生成。 Search-Augmented Factuality Evaluator(SAFE) SAFE利用大模型将一个相应拆

论文速览【LLM】 —— 【ORLM】Training Large Language Models for Optimization Modeling
标题:ORLM: Training Large Language Models for Optimization Modeling文章链接:ORLM: Training Large Language Models for Optimization Modeling代码:Cardinal-Operations/ORLM发表:2024领域:使用 LLM 解决运筹优化问题 摘要:得益于大型语言模型

【ElasticSearch】(五)“Result window is too large 深度分页”的利弊权衡
如题,在使用elastic search的dsl查询过程中,遇到了如下问题: {"error": {"root_cause": [{"type": "query_phase_execution_exception","reason": "Result window is too large, from + size must be less than or equal to: [200]

论文辅助笔记:Large Language Models are Zero-Shot Next LocationPredictors
论文理论部分:论文笔记:lunLarge Language Models are Zero-Shot Next LocationPredictors-CSDN博客 2 Data 2.1 Dataset类 2.2 下载文件 2.3 get_dataset 2.4 get_trajectories trajectory_split暂时略去 # save the tes

Large-Scale Relation Learning for Question Answering over Knowledge Bases with Pre-trained Langu论文笔记
文章目录 一. 简介1.知识库问答(KBQA)介绍2.知识库问答(KBQA)的主要挑战3.以往方案4.本文方法 二. 方法问题定义:BERT for KBQA关系学习(Relation Learning)的辅助任务 三. 实验1. 数据集2. Baselines3. Metrics4.Main Results 一. 简介 1.知识库问答(KBQA)介绍 知识库问答(KBQA

论文翻译:Benchmarking Large Language Models in Retrieval-Augmented Generation
https://ojs.aaai.org/index.php/AAAI/article/view/29728 检索增强型生成中的大型语言模型基准测试 文章目录 检索增强型生成中的大型语言模型基准测试摘要1 引言2 相关工作3 检索增强型生成基准RAG所需能力数据构建评估指标 4实验设置噪声鲁棒性结果负面拒绝测试平台结果信息整合测试平台结果反事实鲁棒性测试平台结果 5 结论 摘要

CV-Paper-增量学习-Large Scale Incremental Learning
目录 0 简介1 什么是偏差2 网络3 loss4 偏差矫正层 0 简介 就简单的说明一下好了,首先是使用蒸馏学习,然后再利用验证集来学习一个简单的线性变换 ax + b 来减少偏差。 这里是把验证集也拿过来训练了,虽然只是学习一个简单的线性变换,因为这个线性变换只有两个参数,所以需要的数据量非常少,虽然这个变换很简单,但是非常有效的提高精度。 文章中说的偏差指的是增量学习

论文笔记 A Large Contextual Dataset for Classification,Detection and Counting of Cars with Deep Learning
ECCV 2016的文章,首先建立了一个从上到下照的车辆影像数据集(即鸟瞰视角),并提出ResCeption神经网络进行训练,进一步建立residual learning with Inception-style layers,进行车辆数目的计算。该方法为车辆数目的计算的一种新方式:通过定位和密度估计方法。对于新的场景或新的目标计数也同样适用。 文章主要关注3个任务点:(1)两类的分类问题(2)

【Oracle点滴积累】解决ORA-20000: ORA-12899: value too large for column错误的方法
广告位招租! 知识无价,人有情,无偿分享知识,希望本条信息对你有用! 今天和大家分享ORA-20000: ORA-12899: value too large for column错误的解决方法,本文仅供参考,谢谢! A fatal error occurred during processing of the com.********.servlet.pub.RegisterCustomer

Retrieval-Augmented Generation for Large Language Models A Survey
Retrieval-Augmented Generation for Large Language Models: A Survey 文献综述 文章目录 Retrieval-Augmented Generation for Large Language Models: A Survey 文献综述 Abstract背景介绍 RAG概述原始RAG先进RAG预检索过程后检索过程 模块化RAGMo
OSS报错The difference between the request time and the current time is too large
目录 一、问题描述二、问题原因三、解决方法 一、问题描述 文件上传阿里云 OSS 报错: The difference between the request time and the current time is too large 二、问题原因 请求发起的时间超过 OSS 服务器当前时间 15 分钟,OSS 判定该请求无效,返回报错。 三、解决方法 OSS

阅读笔记——《Large Language Model guided Protocol Fuzzing》
【参考文献】Meng R, Mirchev M, Böhme M, et al. Large language model guided protocol fuzzing[C]//Proceedings of the 31st Annual Network and Distributed System Security Symposium (NDSS). 2024.(CCF A类会议)【注】本

Mistral AI最新力作——Mistral Large媲美GPT-4
Mistral AI自豪地宣布,他们的最新力作——Mistral Large,已经正式面世。这款尖端的文本生成模型不仅在多语言理解上表现出色,更在推理能力上达到了顶级水平。Mistral Large能够处理包括文本理解、转换和代码生成在内的复杂多语言推理任务。 Mistral Large(预训练版本)与其他顶级语言模型(如 GPT-4、Claude 2、Gemini Pro 1.0、GPT

【论文阅读】MOA,《Mixture-of-Agents Enhances Large Language Model Capabilities》
前面大概了解了Together AI的新研究MoA,比较好奇具体的实现方法,所以再来看一下对应的文章论文。 论文:《Mixture-of-Agents Enhances Large Language Model Capabilities》 论文链接:https://arxiv.org/html/2406.04692v1 这篇文章的标题是《Mixture-of-Agents Enhances
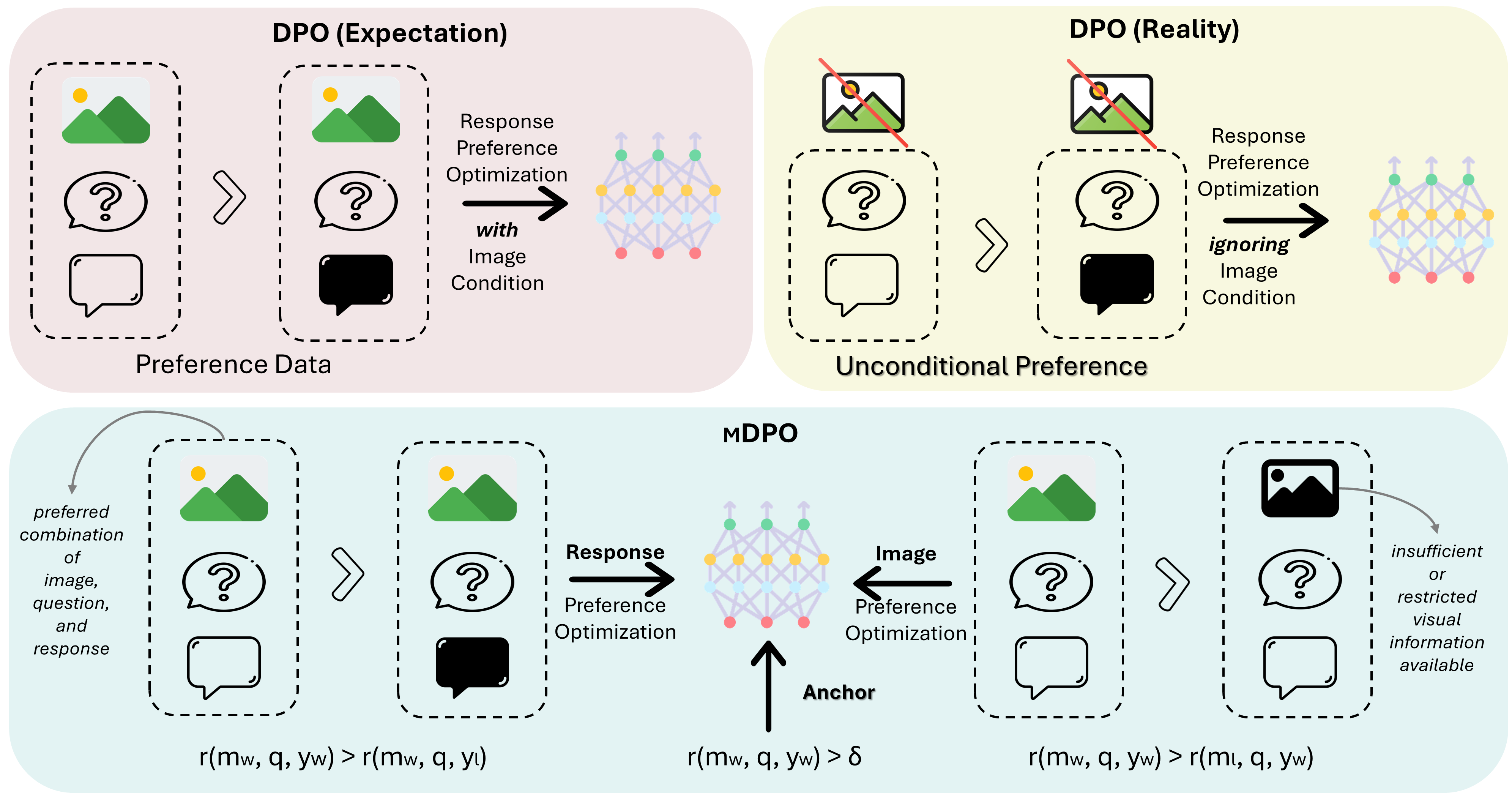
MDPO:Conditional Preference Optimization for Multimodal Large Language Models
MDPO: Conditional Preference Optimization for Multimodal Large Language Models 相关链接:arxiv 关键字:多模态、大型语言模型、偏好优化、条件偏好优化、幻觉减少 摘要 直接偏好优化(DPO)已被证明是大型语言模型(LLM)对齐的有效方法。近期的研究尝试将DPO应用于多模态场景,但发现难以实现一致的改进。通
论文学习_Fuzz4All: Universal Fuzzing with Large Language Models
论文名称发表时间发表期刊期刊等级研究单位Fuzz4All: Universal Fuzzing with Large Language Models2024年arXiv-伊利诺伊大学 0.摘要 研究背景模糊测试再发现各种软件系统中的错误和漏洞方面取得了巨大的成功。以编程或形式语言作为输入的被测系统(SUT),例如编译器、运行时引擎、约束求解器以及具有可访问 API 的软件库尤为重要,因为它们是
![[论文笔记]Are Large Language Models All You Need for Task-Oriented Dialogue?](https://img-blog.csdnimg.cn/img_convert/a9a583c33a94ba4467be7e9b1b88712b.png)
[论文笔记]Are Large Language Models All You Need for Task-Oriented Dialogue?
引言 今天带来论文Are Large Language Models All You Need for Task-Oriented Dialogue?的笔记。 主要评估了LLM在完成多轮对话任务以及同外部数据库进行交互的能力。在明确的信念状态跟踪方面,LLMs的表现不及专门的任务特定模型。然而,如果为它们提供了正确的槽值,它们可以通过生成的回复引导对话顺利结束。 1. 总体介绍 本篇工
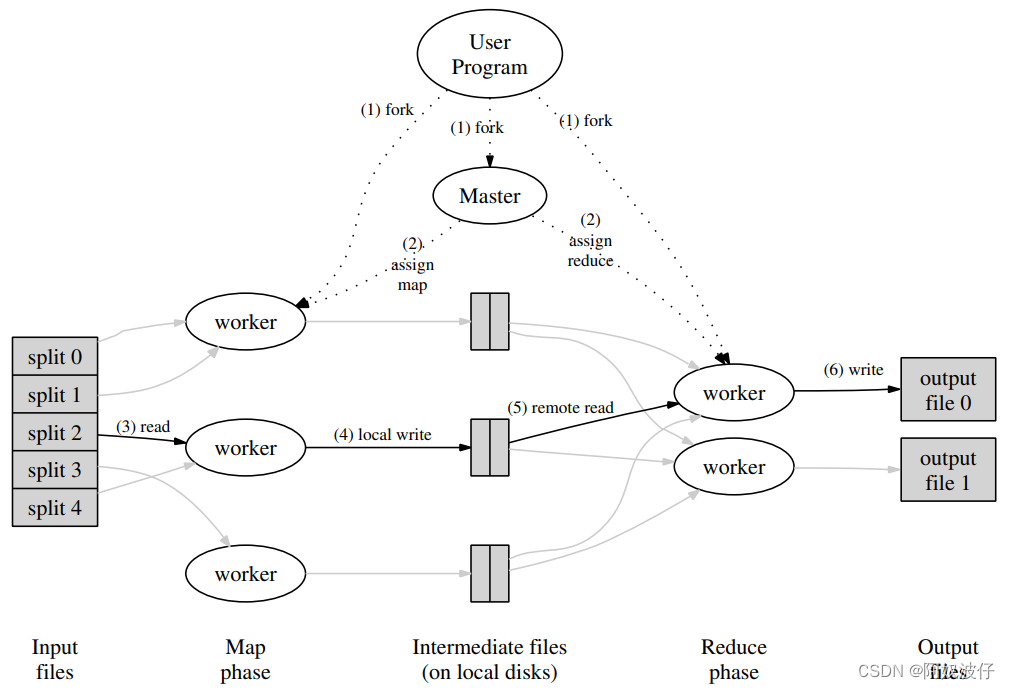
MapReduce Simplified Data Processing on Large Clusters 论文笔记
2003年USENIX,出自谷歌,开启分布式大数据时代的三篇论文之一,作者是 Jeffrey 和 Sanjay,两位谷歌巨头。 Abstract MapReduce 是一种变成模型,用于处理和生成大规模数据。用户指定 map 函数处理每一个 key/value 对来产生中间结果的 key/value 对;reduce 函数合并每一个相同中间 key 的 value。 这种编程风格能自动获得并
上传大文件报错:Request Entity Too Large
背景 如题目所示,网站上传大文件时报了这个错。 解决过程 网上查说在nginx的配置文件中的http{}中加入 client_max_body_size 10m;这个属性默认只有1m,所以按照自己的需求设置,打开nginx配置文件一看:好家伙,已经设置为1000m了。 找来大佬,直接问网站是不是80端口,我说应该是吧,然后他直接改了其中一项东西的client_max_body_size为10

关于Mysql 中 Row size too large (> 8126) 错误的解决和理解
提示:啰嗦一嘴 ,数据库的任何操作和验证前,一定要记得先备份!!!不会有错; 文章目录 问题发现一、问题导致的可能原因1、页大小2、行格式2.1 compact格式2.2 Redundant格式2.3 Dynamic格式2.4 Compressed格式 3、BLOB和TEXT列 二、解决办法1、修改页大小(不推荐)2、修改行格式3、修改数据类型为BLOB和TEXT列4、其他优化方式(