本文主要是介绍MDPO:Conditional Preference Optimization for Multimodal Large Language Models,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MDPO: Conditional Preference Optimization for Multimodal Large Language Models
相关链接:arxiv
关键字:多模态、大型语言模型、偏好优化、条件偏好优化、幻觉减少
摘要
直接偏好优化(DPO)已被证明是大型语言模型(LLM)对齐的有效方法。近期的研究尝试将DPO应用于多模态场景,但发现难以实现一致的改进。通过比较实验,我们确定了多模态偏好优化中的无条件偏好问题,即模型在优化过程中忽略了图像条件。为了解决这个问题,我们提出了MDPO,这是一个多模态DPO目标,它通过同时优化图像偏好来防止过度优先考虑仅基于语言的偏好。此外,我们引入了一个奖励锚点,强制奖励对于选定的响应为正,从而避免了它们的似然度降低——这是相对偏好优化的一个内在问题。在不同大小的两个多模态LLM和三个广泛使用的基准测试上的实验表明,MDPO有效地解决了多模态偏好优化中的无条件偏好问题,并显著提高了模型性能,特别是在减少幻觉方面。
核心方法
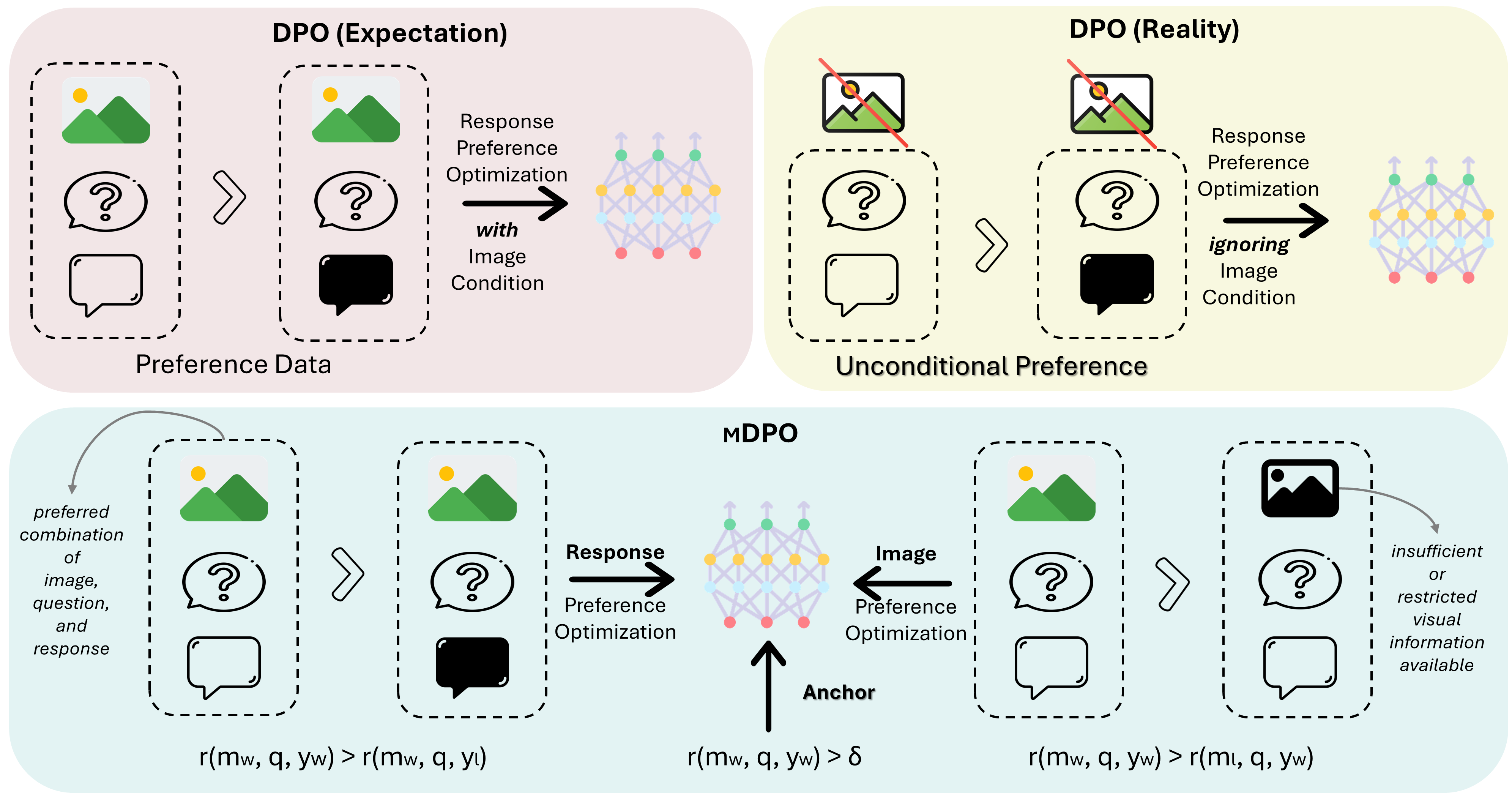
MDPO(多模态直接偏好优化)提出了一种针对多模态场景的改进的偏好优化方法。核心方法包括以下几个关键点:
-
条件偏好优化:通过引入新的偏好对来强调图像与响应之间的关系,解决模型在偏好数据中忽略视觉信息的问题。
-
奖励锚点:通过正则化奖励为正,保持选定响应的似然度,避免在相对偏好优化中选定响应的似然度降低。
-
多模态偏好数据:MDPO在优化过程中同时考虑视觉和语言特征,以确保模型能够基于图像和问题文本的条件学习响应偏好。
-
实验验证:通过在不同规模的多模态LLM上进行实验,验证MDPO在减少幻觉和提高模型性能方面的有效性。
-
性能提升:MDPO通过条件偏好优化和奖励锚点,显著提高了模型对图像的理解能力,并减少了模型响应中的语言偏差。
实验说明
实验使用了两个不同大小的多模态LLM(Bunny-v1.0-3B和LLaVA-v1.5-7B),并在三个广泛使用的基准测试(MMHalBench、Object HalBench和AMBER)上进行了评估。实验结果表明MDPO在多模态场景中的表现优于标准DPO,特别是在减少幻觉方面。
以下是实验结果的Markdown表格展示:
| 基准测试 | 指标 | Bunny-v1.0-3B (DPO) | Bunny-v1.0-3B (MDPO) | LLaVA-v1.5-7B (DPO) | LLaVA-v1.5-7B (MDPO) |
|---|---|---|---|---|---|
| MMHalBench | 分数 | 2.28 | 2.96 | 2.14 | 2.39 |
| 幻觉率 | 0.56 | 0.42 | 0.65 | 0.54 | |
| Object HalBench | CHAIRs | 44.3 | 27.0 | 49.0 | 35.7 |
| CHAIRi | 7.6 | 4.6 | 13.0 | 9.8 | |
| AMBER | 分数 | 74.1 | 67.4 | 55.1 | 52.4 |
| 覆盖率 | 58.9 | 37.7 | 34.5 | 24.5 | |
| 幻觉率 | 4.8 | 2.4 | 2.3 | 2.4 |
实验结果数据来源于论文中的实验部分,展示了MDPO在不同基准测试上的性能提升。数据要求反映了模型在减少幻觉和提高响应质量方面的表现。
结论
MDPO是一种针对多模态场景的偏好优化方法,它通过条件偏好优化和奖励锚点,有效地提高了多模态LLM的性能,并显著减少了幻觉。实验结果表明,MDPO在不同模型规模和数据规模上均能实现性能提升,证明了其在多模态偏好优化中的有效性和潜力。
整个论文的梳理保持了连贯性,并采用了技术性语言来描述方法和结果。对于深度学习的专业术语,如“大型语言模型(LLM)”和“直接偏好优化(DPO)”,保留了原文中的英文表述。
这篇关于MDPO:Conditional Preference Optimization for Multimodal Large Language Models的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)
