preference专题

深入理解DPO(Direct Preference Optimization)算法
目录 1. 什么是DPO?2. Bradley-Terry模型2.1 奖励模型的训练 3. 从PPO到DPO4. DPO的简单实现5. 梯度分析Ref 1. 什么是DPO? 直接偏好优化(Direct Preference Optimization, DPO)是一种不需要强化学习的对齐算法。由于去除了复杂的强化学习算法,DPO 可以通过与有监督微调(SFT)相似的复杂度实现模型对

Unable to create the selected preference page解决方法
解决: 将path路径中的%JAVA_HOME%\bin 移动到最前面即可. 问题: Unable to create the selected preferencepage. com.avaya.exvantage.ui.interfaces.eclipse.plugin 解决办法: 方式一: 系统级别path高于用户级别pathjdk路径一定在系统path比较保险 方式二:

创建采购订单,选择供应商后报错:未获权限,您需要拥有对客户记录类型Vendor Prepayment Preference 的更高权限才能访问此页面
创建采购订单,选择供应商后报错:未获权限,您需要拥有对客户记录类型Vendor Prepayment Preference 的更高权限才能访问此页面 今天培训客户创建供应商和采购订单,创建供应商没有问题,但是在创建采购订单时,选择这个供应商报错。未获权限:您需要拥有对客户记录类型Vendor Prepayment Preference 的更高权限才能访问此页面。具体错误见图: 初步分析是我之前
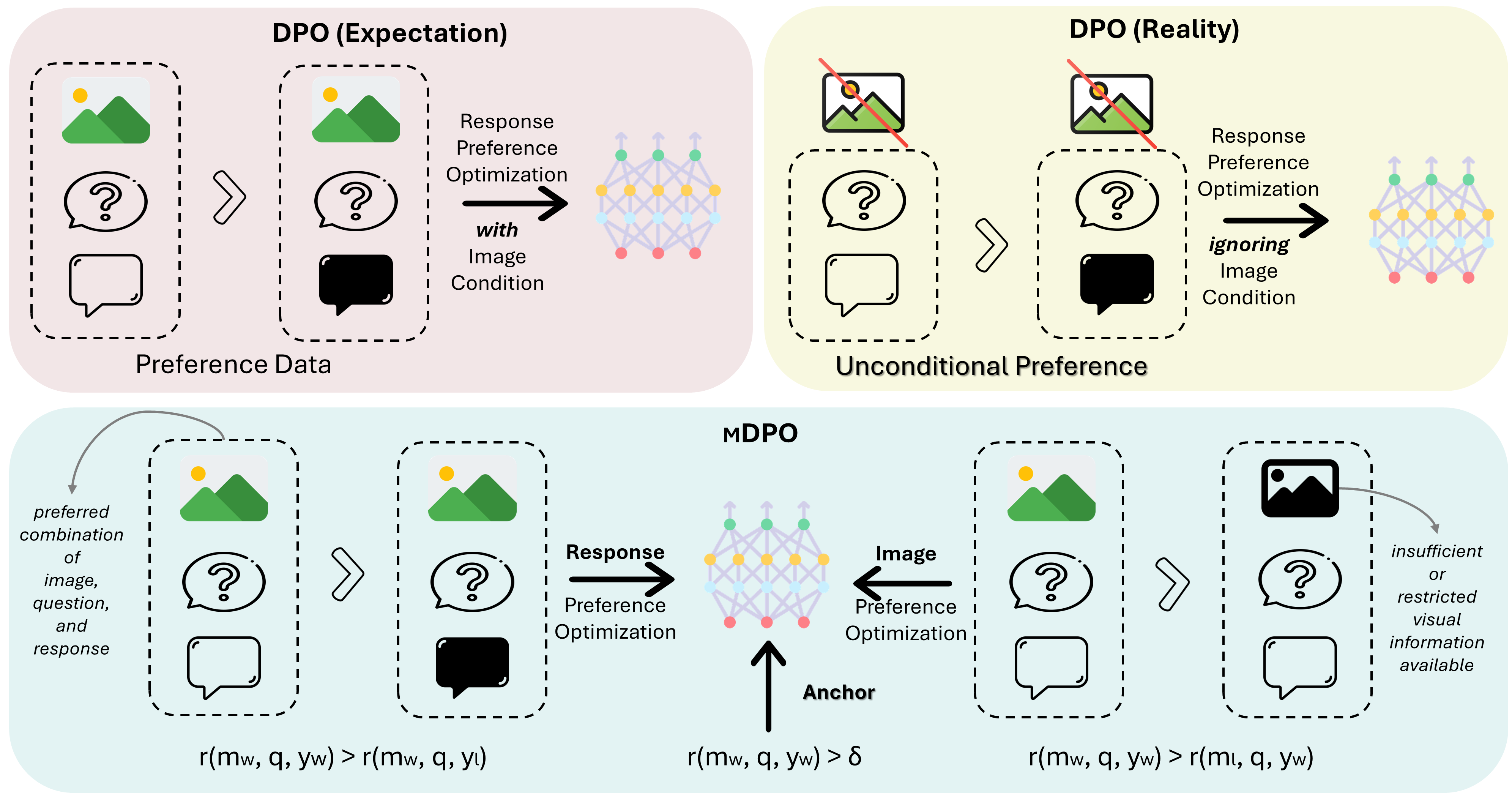
MDPO:Conditional Preference Optimization for Multimodal Large Language Models
MDPO: Conditional Preference Optimization for Multimodal Large Language Models 相关链接:arxiv 关键字:多模态、大型语言模型、偏好优化、条件偏好优化、幻觉减少 摘要 直接偏好优化(DPO)已被证明是大型语言模型(LLM)对齐的有效方法。近期的研究尝试将DPO应用于多模态场景,但发现难以实现一致的改进。通
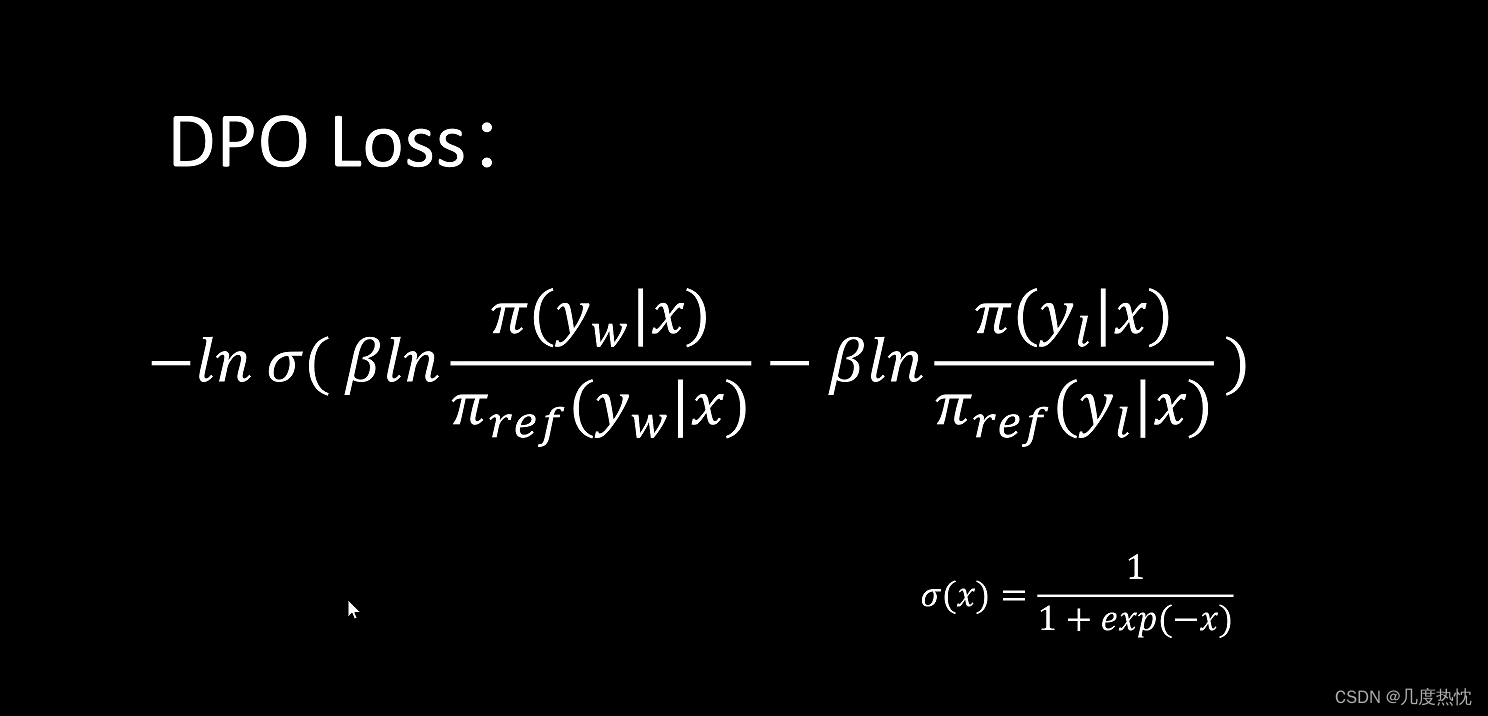
【强化学习】DPO(Direct Preference Optimization)算法学习笔记
【强化学习】DPO(Direct Preference Optimization)算法学习笔记 RLHF与DPO的关系KL散度Bradley-Terry模型DPO算法流程参考文献 RLHF与DPO的关系 DPO(Direct Preference Optimization)和RLHF(Reinforcement Learning from Human Feedback)都是用于训

Offline RL : Beyond Reward: Offline Preference-guided Policy Optimization
ICML 2023 paper code preference based offline RL,基于HIM,不依靠额外学习奖励函数 Intro 本研究聚焦于离线偏好引导的强化学习(Offline Preference-based Reinforcement Learning, PbRL),这是传统强化学习(RL)的一个变体,它不需要在线交互或指定奖励函数。在这个框架下,代理(agent)被提
在Preference标签中,为intent标签加参数,实现带参数跳转
转自: https://my.oschina.net/artshell/blog/397132 在为应用开发设置界面中时,一般会使用PreferenceActivity或者PreferenceFragment类来实现.在写xml文件时,可以通过为Preference标签添加intent标签的方法来实现点击跳转,而且可以在intent标签中添加额外的参数.这样就不用再去编码实现跳转了.具体实现参考

督促学习——ViewPager实现滑动的Preference页面且带ActionBar
直接上代码有时间具体分析: 1、MainActivity.java public class MainActivity extends FragmentActivity implementsOnPageChangeListener {private int mActionBarOptions;private ViewPager mViewPager;private View mCustomVi
图形界面介绍Set Preference—Design
这次要介绍的GUI上的按键是Set Preference。这个就是我们平时经常用到的系统设置界面,我们一般要设置一些GUI上面的全局性参数,就是通过这个图形界面来设置。Set Preference的图形界面内容比较多,我们按模块来介绍吧~~ 首先是第一个模块——Design 1,就是最基本的Design名字,Hierarchical,DEF,PDEF的分隔符 2,Write Conforma
图形界面介绍Set Preference—Text
这次要介绍的GUI上的按键是Set Preference中的Text模块。这个模块的作用的改变GUI上的字体大小,大家如果嫌默认的字体太小,看不清的话,可以通过这个设置改变大小。 1)Instance Name:对module来说,显示hinsts的名字 Master Name:对module来说,显示实例化前的cell名字 Instance and Master Name:同时显示hIns
复现Evolutionary Preference Learning via Graph Nested GRU ODE for Session-based Recommendation的GNG-ODE
恒源云中下载FileZilla用于上传数据,新建一个站点后 填写如下信息 在主页面打开jupyterlab 里面有各种操作台 选择终端 然后进入cd /hy-tmp内部 然后cd 所需目录之下 调用作者给出的 python -u scripts/main_ode.py --dataset-dir …/datasets/tmall --gnn GATConv --solver dopri5即可运行

Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference 相关链接:arxiv 关键字:Large Language Models、LLMs、Human Preference、Chatbot Arena、Benchmark Platform 摘要 随着大型语言模型(LLMs)解锁新功能和应用,评估它们
RLAIF(0)—— DPO(Direct Preference Optimization) 原理与代码解读
之前的系列文章:介绍了 RLHF 里用到 Reward Model、PPO 算法。 但是这种传统的 RLHF 算法存在以下问题:流程复杂,需要多个中间模型对超参数很敏感,导致模型训练的结果不稳定。 斯坦福大学提出了 DPO 算法,尝试解决上面的问题,DPO 算法的思想也被后面 RLAIF(AI反馈强化学习)的算法借鉴,这个系列会从 DPO 开始,介绍 SPIN、self-reward model

eclipse 源码设置UTF-8 (eclipse可以为JSP HTML 等各种文件不同编码格式设置) 在windows - preference- general-workspace
eclipse 源码设置UTF-8 (eclipse可以为JSP HTML 等各种文件不同编码格式设置) 在windows - preference- general-workspace https://blog.csdn.net/qq_42183409/article/details/89787431

Android 完美解决自定义preference与ActivityGroup UI更新的问题
之前发过一篇有关于自定义preference 在ActivityGroup 的包容下出现UI不能更新的问题,当时还以为是Android 的一个BUG 现在想想真可笑 。其实是自己对机制的理解不够深刻,看来以后要多看看源码才行。 本篇讲述内容大致为如何自定义preference 开始到与ActivityGroup 互用下UI更新的解决方法。 首先从扩展preference开始: 类文件必须继承自Pr
Android设置界面之Preference
转载自简书:http://www.jianshu.com/p/6d6f84e2f50d Android系统为设置界面的UI提供了一系列的接口,设置界面的部分和Activity是分离的,会有一个PreferenceScreen的对象 是根目录,在其中会包含CheckBoxPreference EditTextPreference ListPreference PreferenceCatego
创建采购订单,选择供应商后报错:未获权限,您需要拥有对客户记录类型Vendor Prepayment Preference 的更高权限才能访问此页面
创建采购订单,选择供应商后报错:未获权限,您需要拥有对客户记录类型Vendor Prepayment Preference 的更高权限才能访问此页面 今天培训客户创建供应商和采购订单,创建供应商没有问题,但是在创建采购订单时,选择这个供应商报错。未获权限:您需要拥有对客户记录类型Vendor Prepayment Preference 的更高权限才能访问此页面。具体错误见图: 初步分析是我之前
android preference
虽然很早就知道preference这个东西,在android中是做设置页面用的,但是一直没有详细了解过,而且现在大家做应用都不用这个了,因为样式太丑,自定义的支持比较少(我是看了一天多才知道的),改造起来巨麻烦。所以大家都自己写设置页面了。 android 的官方文档,guide和developer的文档,必须看看,可能会发现很多百度不出来的内容。 http://developer.
Preference偏好设置使用方法
学习了一下Preference偏好设置的方法,这里记录总结,供学习参考。代码参考了android Settings packages/app/Settings里偏好设置,以及自定义Preference的用法。 在API 11以后,推荐PreferenceFragment的addPreferencesFromResource方法,原来的PrefereneceActivity已经废弃。 pu

【iOS】iOS数据存储,应用沙盒,XML,Preference,NSKeyedArchiver归档,SQLite3
版权声明:本文为博主原创,如需转载请注明出处。 应用沙盒 每个iOS应用都有自己的应用沙盒(应用沙盒就是文件系统目录),与其他文件系统隔离。应用必须待在自己的沙盒里,其他应用不能访问该沙盒 应用沙盒的文件系统目录,如下图所示(假设应用的名称叫Layer) 模拟器应用沙盒的根路径在: (apple是用户名, 6.0是模拟器版本) /Users/apple/Library/Appl

C1-1: Consumer Theory-Primitive Notions, Preference Relations and categories.
Chapter1-Consumer Theory Primitive Notions 4 building blocks in any model of consumer choice consumption set, X : \mathbf{X}: X: SET, all alternatives or complete consumption plans. X ⊆ R + n \m