optimization专题

【Derivation】Convex Optimization
Separation theorems and supporting hyperplanes(分离定理与支撑超平面) Inner and outer polyhedral approximations.(内部与外部多面体逼近) Let C belongs to Rn be a closed convex set.and suppose that x1,...xk a
![[论文笔记]Circle Loss: A Unified Perspective of Pair Similarity Optimization](/front/images/it_default.gif)
[论文笔记]Circle Loss: A Unified Perspective of Pair Similarity Optimization
引言 为了理解CoSENT的loss,今天来读一下Circle Loss: A Unified Perspective of Pair Similarity Optimization。 为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。 这篇论文从对深度特征学习的成对相似度优化角度出发,旨在最大化同类之间的相似度 s p s_p s

深入理解DPO(Direct Preference Optimization)算法
目录 1. 什么是DPO?2. Bradley-Terry模型2.1 奖励模型的训练 3. 从PPO到DPO4. DPO的简单实现5. 梯度分析Ref 1. 什么是DPO? 直接偏好优化(Direct Preference Optimization, DPO)是一种不需要强化学习的对齐算法。由于去除了复杂的强化学习算法,DPO 可以通过与有监督微调(SFT)相似的复杂度实现模型对

论文速览【LLM】 —— 【ORLM】Training Large Language Models for Optimization Modeling
标题:ORLM: Training Large Language Models for Optimization Modeling文章链接:ORLM: Training Large Language Models for Optimization Modeling代码:Cardinal-Operations/ORLM发表:2024领域:使用 LLM 解决运筹优化问题 摘要:得益于大型语言模型

Introduction to linear optimization 第二章全部课后题答案
费了好长时间,终于把这本经典理论教材第二章的课后题做完了。大部分都是证明题,很多都是比较有难度的。 不少题我参考了网上找到的一些资料的思路,但是有一些题目我觉得这些网上找到的答案也不太好,自己修正完善了下,少部分题目自己独立完成。 我把答案放在一个 Jupyter book 上,见链接:第二章答案

蛇优化算法(Snake Optimization, SO)优化RBF神经网络的扩散速度实现多数入多输出数据预测,可以更改数据集(MATLAB代码)
一、蛇优化算法优化RBF神经网络的扩散速度原理介绍 RBF神经网络的扩散速度通常与它的径向基函数的宽度参数(σ)有关,这个参数控制了函数的径向作用范围。在高斯核函数中,当σ值较大时,函数的扩散速度较快,即它的影响范围更广,对输入数据的局部变化不太敏感;而σ值较小时,函数的扩散速度较慢,影响范围较小,对输入数据的局部变化更加敏感 。 RBF神经网络通过使用高斯函数作为隐含层激活函数,实现了从低维

Introduction to linear optimization 第 2 章课后题答案 11-15
线性规划导论 Introduction to linear optimization (Dimitris Bertsimas and John N. Tsitsiklis, Athena Scientific, 1997), 这本书的课后题答案我整理成了一个 Jupyter book,发布在网址: https://robinchen121.github.io/manual-introductio
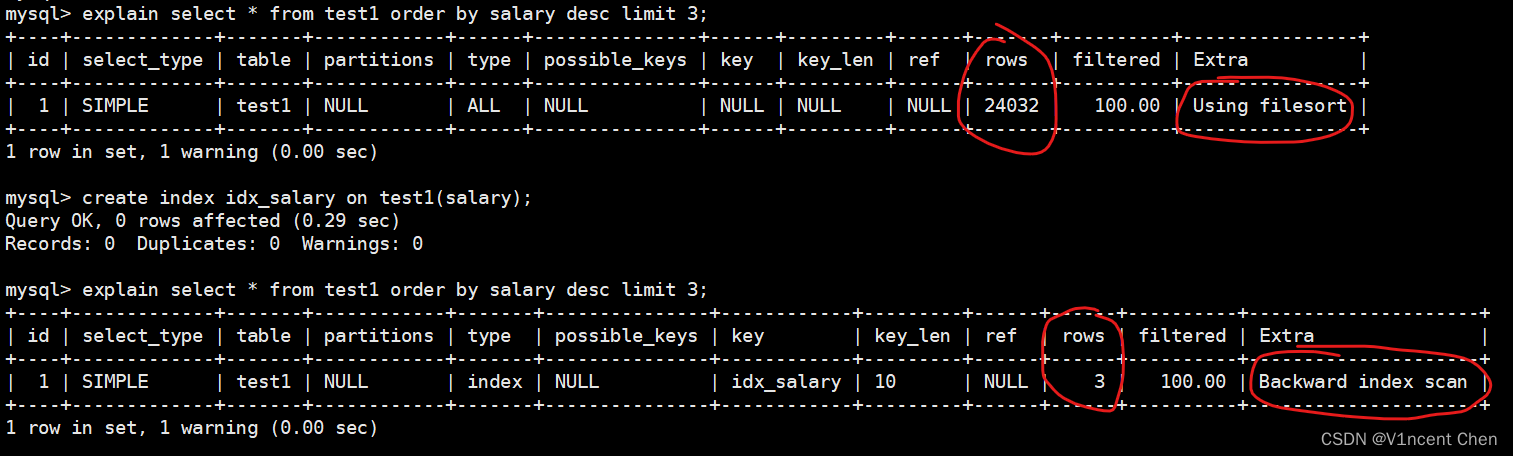
MySQL limit子句用法及优化(Limit Clause Optimization)
在MySQL中,如果只想获取select查询结果的一部分,可以使用limit子句来限制返回记录的数量,limit在获取到满足条件的数据量时即会立刻终止SQL的执行。相比于返回所有数据然后丢弃一部分,执行效率会更高。 文章目录 一、limit子句用法示例1.1 基本用法1.2 limit和order by1.2.1 排序瓶颈优化 二、limit分页优化2.1 延迟关联2.2 转换为位置查询2
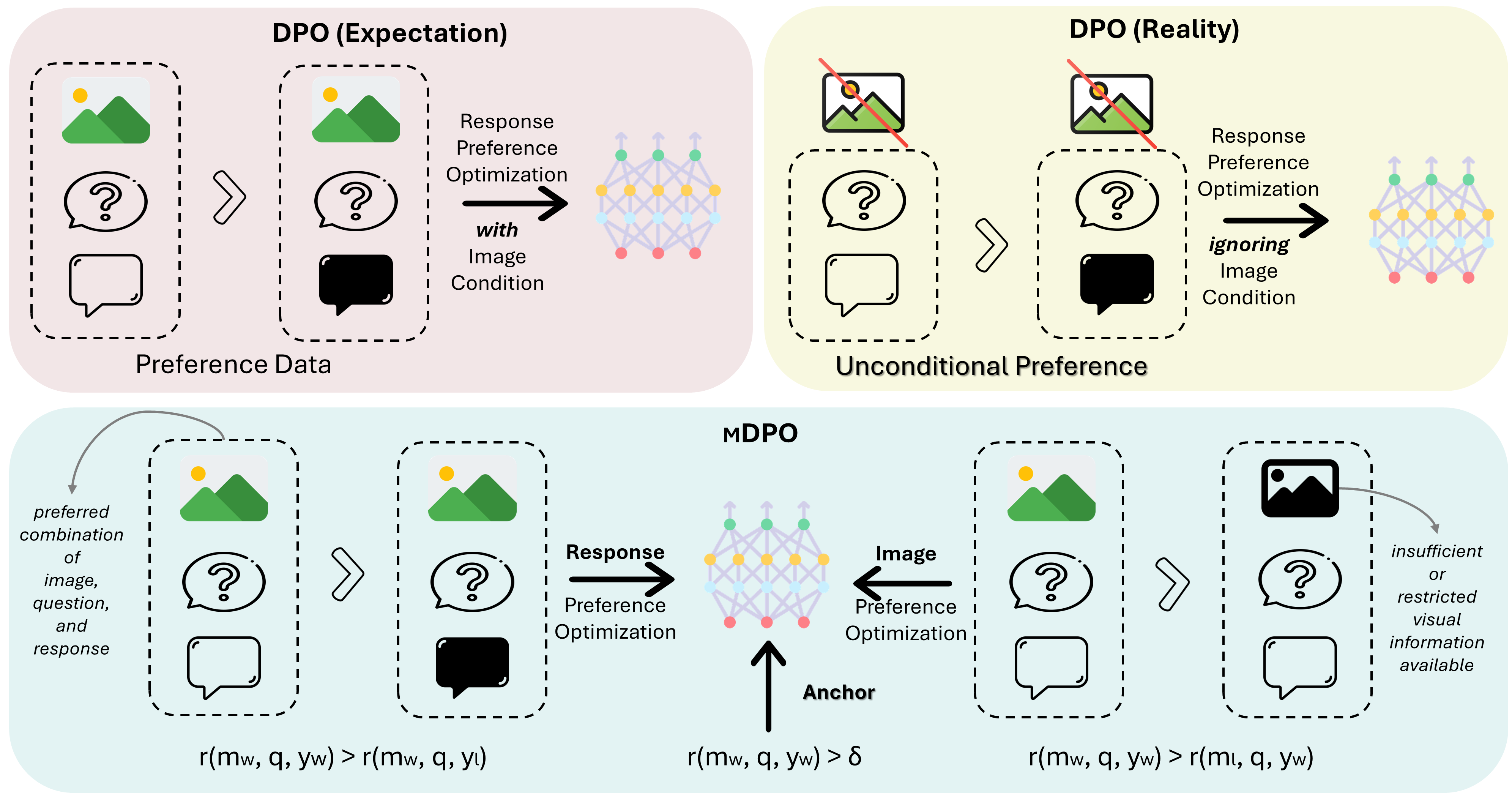
MDPO:Conditional Preference Optimization for Multimodal Large Language Models
MDPO: Conditional Preference Optimization for Multimodal Large Language Models 相关链接:arxiv 关键字:多模态、大型语言模型、偏好优化、条件偏好优化、幻觉减少 摘要 直接偏好优化(DPO)已被证明是大型语言模型(LLM)对齐的有效方法。近期的研究尝试将DPO应用于多模态场景,但发现难以实现一致的改进。通
How to maintenance Operating System and Hardware Optimization
1.What Limits MySQL's Performance? CPU saturationI/O saturation 2.How to Select CPUs for MySQL? two goals for your server: Low latency(fast response time)High throughput 3.How to balancing Memory

轨迹规划论文阅读20220109-A Real-Time Motion Planner with Trajectory Optimization for Autonomous Vehicles
0、摘要 提出了一种基于轨迹优化的高效实时自动驾驶运动规划方法。将轨迹空间离散化->利用cost functions 来找到最佳轨迹。 引[CSDN1]: 规划器首先把规划空间离散化 ,并根据一组代价函数搜索最优轨迹,然后对轨迹的path和speed进行迭代优化。文中提出了一种“post-optimization”的方法,可以弥补离散化难以求出最优解的问题(离散越密,越接近最优解),
Code optimization summary
1. Arrange the if/switch statements follow the rules of halfman tree. Minimize the unexpected branch call.
Lecture3——线性最优化(Linear Optimization)
一,本文重点 线性最优化(LP)和标准线性最优化(Standard LP form)的定义如何将LP转换为Standard LP用Python解决LP问题将非线性最优化问题(NLP)转换为LP 二,定义 1,线性最优化 定义 线性最优化问题,或者线性规划(linear programming,缩写:LP)是一个目标函数和所有限制函数(在决策变量中)都是线性的最优化问题。 注意:

Theano学习笔记:“Optimization failure due to: constant_folding”错误
刚安装完Theano,测试了一下,报错如图: 解决方法: 可能是权限不够,加上sudo即可 sudo python test.py
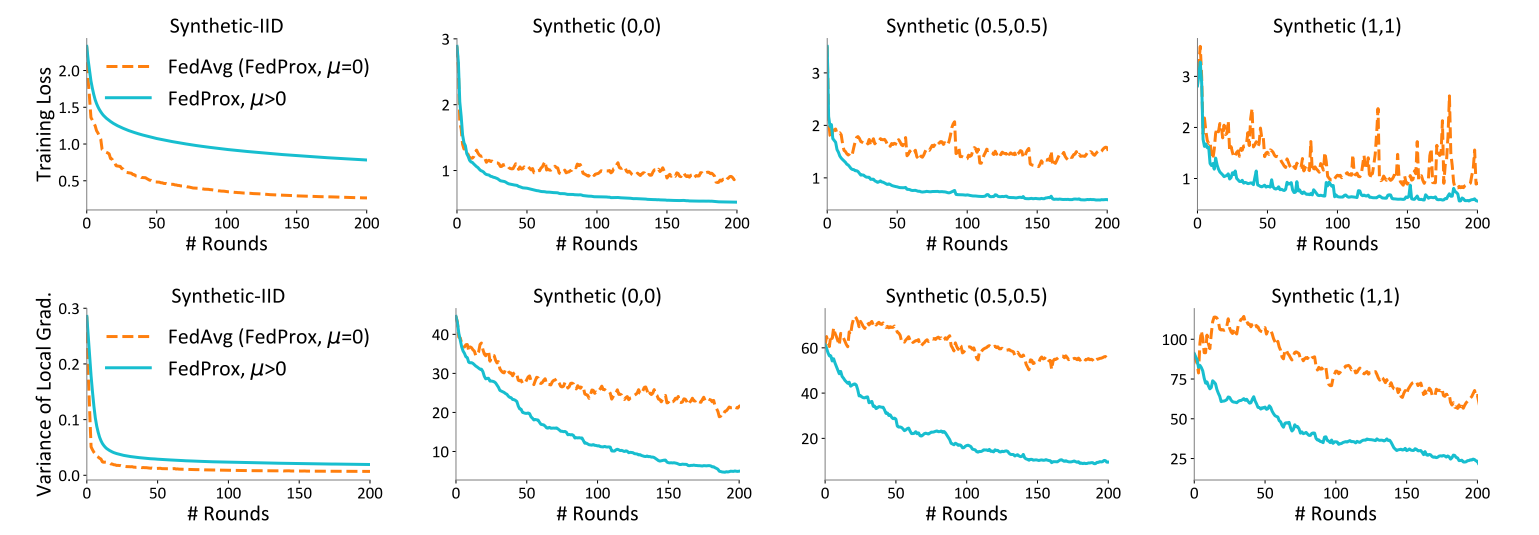
详解FedProx:FedAvg的改进版 Federated optimization in heterogeneous networks
FedProx:2020 FedAvg的改进 论文:《Federated Optimization in Heterogeneous Networks》 引用量:4445 源码地址: 官方实现(tensorflow)https://github.com/litian96/FedProx 几个pytorch实现:https://github.com/ki-ljl/FedProx-PyTorch ,

贪心+树状数组,CF1579E2 - Array Optimization by Deque
一、题目 1、题目描述 2、输入输出 2.1输入 2.2输出 3、原题链接 1579E2 - Array Optimization by Deque 二、解题报告 1、思路分析 很好想也很好证明的贪心 因为添加的顺序是确定的,我们每次只需决策放左边还是放右边 x放左边,那么贡献就是右边比x小的个数 x放右边,那么贡献就是左边比x大的个数

开源SLAM框架学习——OpenVSLAM源码解析:全局优化模块(global optimization module):回环检测、pose-graph优化、global-BA优化
这篇博客主要介绍OpenVSLAM的全局优化模块(global_optimization_module),该模块是单独运行在一个线程中的。它主要执行的工作是:SLAM的回环检测,以及回环成功之后的回环矫正,还包括紧随着回环检测成功之后的pose graph优化和全局的BA优化。 1.全局优化模块入口 说是全局优化模块,其实也就是一个普通的类。对于类,第一步肯定就是实例化构造对象,全局优化模块的

MeshFusion Pro : Ultimate Optimization Tool
MeshFusion Pro是Unity的强大优化工具,它使用一种高效的方法来组合对象,以减少绘制调用并提高FPS。 MeshFusion Pro可用于组合静态对象以及LODGroups。您还可以创建动态组合对象,其中每个单独的网格都可以在运行时移动,新的组合网格将自动更新。在保持单个网格自由度的同时,仍然可以获得组合网格的性能提升! MeshFusion Pro还将场景划分为单元,并在其中组
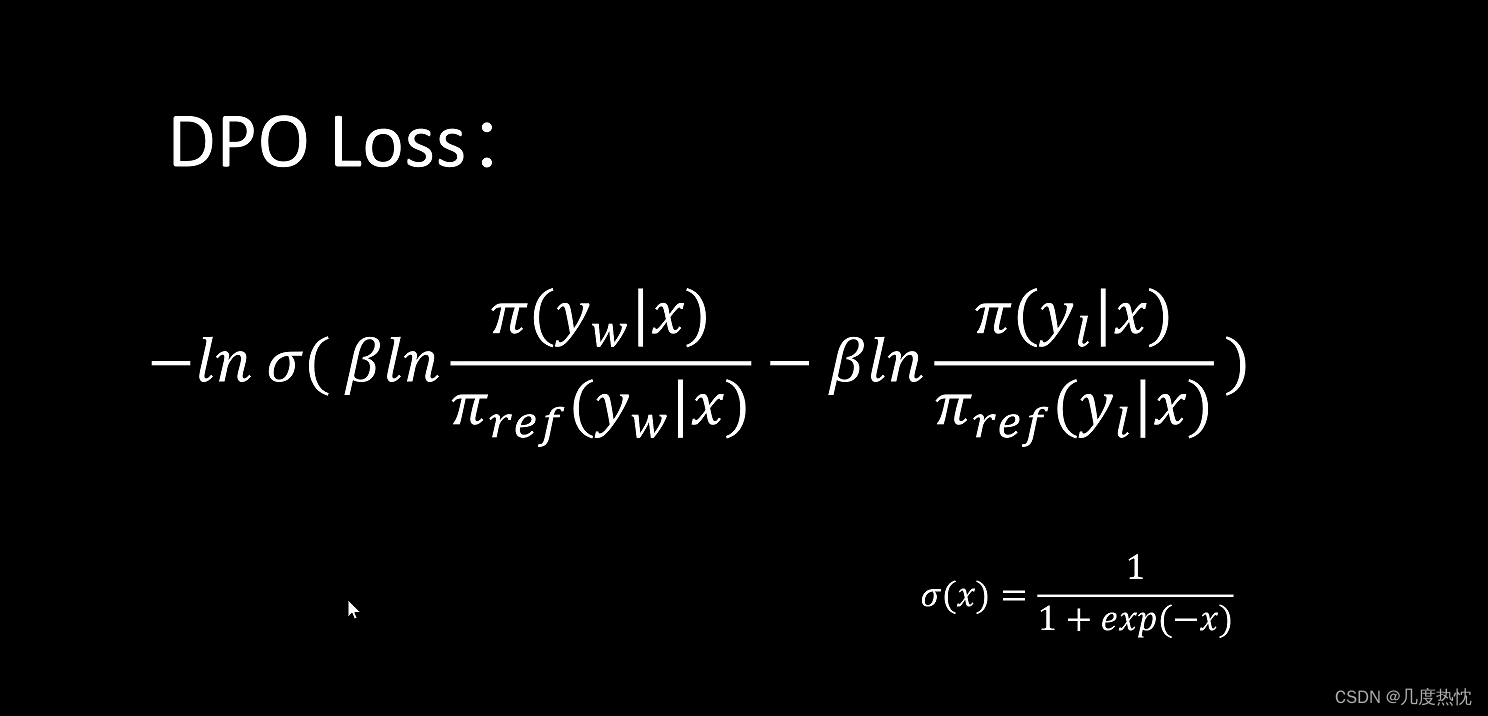
【强化学习】DPO(Direct Preference Optimization)算法学习笔记
【强化学习】DPO(Direct Preference Optimization)算法学习笔记 RLHF与DPO的关系KL散度Bradley-Terry模型DPO算法流程参考文献 RLHF与DPO的关系 DPO(Direct Preference Optimization)和RLHF(Reinforcement Learning from Human Feedback)都是用于训

延迟重平衡优化(Deferred Re-balancing Optimization Schedule)
DRW 论文代码 elif args.train_rule == 'DRW':train_sampler = Noneidx = epoch // 160betas = [0, 0.9999]effective_num = 1.0 - np.power(betas[idx], cls_num_list)print(f"\neffective_num:{effective_num
Geometrically Constrained Trajectory Optimization for Multicopters 论文分析
这篇论文题目为"针对多旋翼飞行器的几何约束轨迹优化方法"(Geometrically Constrained Trajectory Optimization for Multicopters),主要讲了一种高效求解多旋翼无人机在复杂环境下轨迹规划问题的优化框架。 1. 引言 多旋翼无人机要实现自主导航,需要能够在复杂环境中快速规划出安全且动力学可行的轨迹。但现有的轨迹规划方法在求解质量、计算效

Offline RL : Beyond Reward: Offline Preference-guided Policy Optimization
ICML 2023 paper code preference based offline RL,基于HIM,不依靠额外学习奖励函数 Intro 本研究聚焦于离线偏好引导的强化学习(Offline Preference-based Reinforcement Learning, PbRL),这是传统强化学习(RL)的一个变体,它不需要在线交互或指定奖励函数。在这个框架下,代理(agent)被提
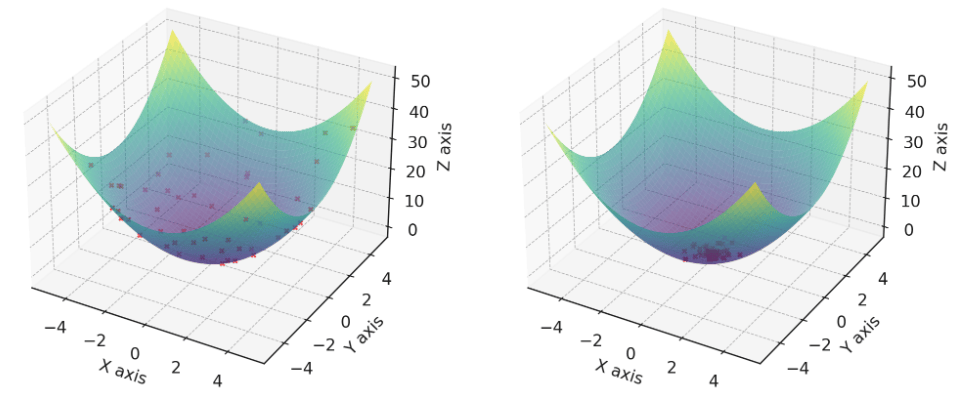
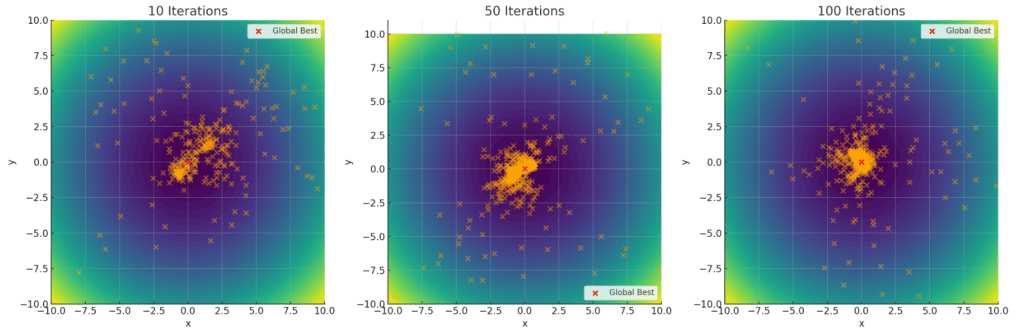
粒子群算法(Particle Swarm Optimization)
注意:本文引用自专业人工智能社区Venus AI 更多AI知识请参考原站 ([www.aideeplearning.cn]) 算法背景 粒子群优化算法(Particle Swarm Optimization,PSO)的灵感来源于鸟群或鱼群的觅食行为。想象一下,你在公园里看到一群鸟,它们在空中飞翔,寻找食物。每只鸟都不知道食物在哪里,但它们会根据周围其他鸟的位置和过去自己找到食物的经验来调整自

免疫优化算法(Immune Optimization Algorithm)
注意:本文引用自专业人工智能社区Venus AI 更多AI知识请参考原站 ([www.aideeplearning.cn]) 算法背景 免疫算法是一种模拟生物免疫系统的智能优化算法。想象一下,当我们的身体遇到病毒或细菌侵袭时,免疫系统会启动,通过识别、记忆、适应和清除来保护我们。就像我们的身体需要应对各种各样的健康挑战一样,免疫算法也被设计来解决复杂的优化问题。 为了更生动地展示这个概念,
蜂群优化算法(bee colony optimization algorithm)
注意:本文引用自专业人工智能社区Venus AI 更多AI知识请参考原站 ([www.aideeplearning.cn]) 算法引言 自然界的启发:BSO算法的灵感来自于蜜蜂在自然界中的觅食行为。在自然界中,蜜蜂需要找到花蜜来生存。当一只蜜蜂找到一片花丛时,它会返回蜂巢,通过特殊的“摆动舞”将花丛的位置信息传递给其他蜜蜂。这些信息包括花丛的方向、距离,甚至花蜜的质量。信息共享:在蜂群优化
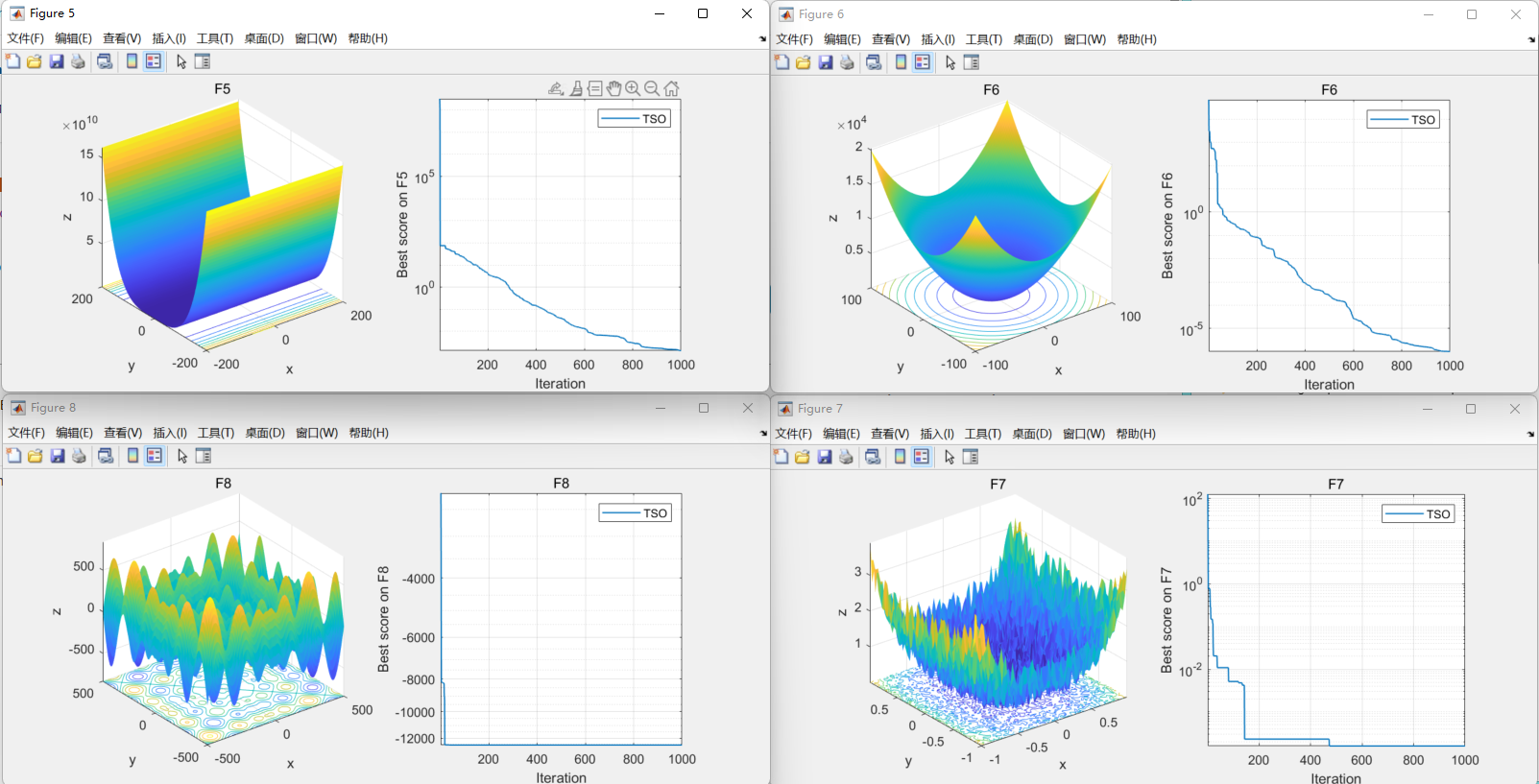
【智能优化算法】金枪鱼群优化(Tuna Swarm Optimization,TSO)
金枪鱼群优化(Tuna Swarm Optimization,TSO)是期刊“Computational Intelligence and Neuroscience”(IF:1.8)的2021年智能优化算法 01.引言 金枪鱼群优化(Tuna Swarm Optimization,TSO)的主要灵感来自于金枪鱼群体的合作觅食行为。模拟金枪鱼群体的两种觅食行为,包括螺旋觅食和抛物线觅食,以开发一