multimodal专题

How to leverage pre-trained multimodal model?
However, embodied experience is limited inreal world and robot. How to leverage pre-trained multimodal model? https://come-robot.github.io/
![[CLIP-VIT-L + Qwen] 多模态大模型源码阅读 - MultiModal篇](https://i-blog.csdnimg.cn/direct/5cd8f3334ae74386b28c9736370a95f2.jpeg#pic_center)
[CLIP-VIT-L + Qwen] 多模态大模型源码阅读 - MultiModal篇
[CLIP-VIT-L + Qwen] 多模态大模型源码阅读 - MultiModal篇 前情提要源码阅读导包逐行讲解 dataclass部分整体含义逐行解读 模型微调整体含义逐行解读 MultiModal类整体含义逐行解读 参考repo:WatchTower-Liu/VLM-learning; url: VLLM-BASE 前情提要 有关多模态大模型架构中的语言模型部分

多模态学习Multimodal Learning:人工智能中的多模态原理与技术介绍初步了解
多模态学习(Multimodal Learning)是机器学习中的一个前沿领域,旨在综合处理和理解来自不同模态的数据。模态可以包括文本、图像、音频、视频等。随着数据多样性和复杂性增加,多模态学习在自然语言处理、计算机视觉、语音识别等领域中的应用变得愈加重要。本文将详细探讨多模态学习的原理、关键技术、挑战及其实际应用。 一、多模态学习的基本概念 什么是多模态学习? 多模态学习指的是通过同时
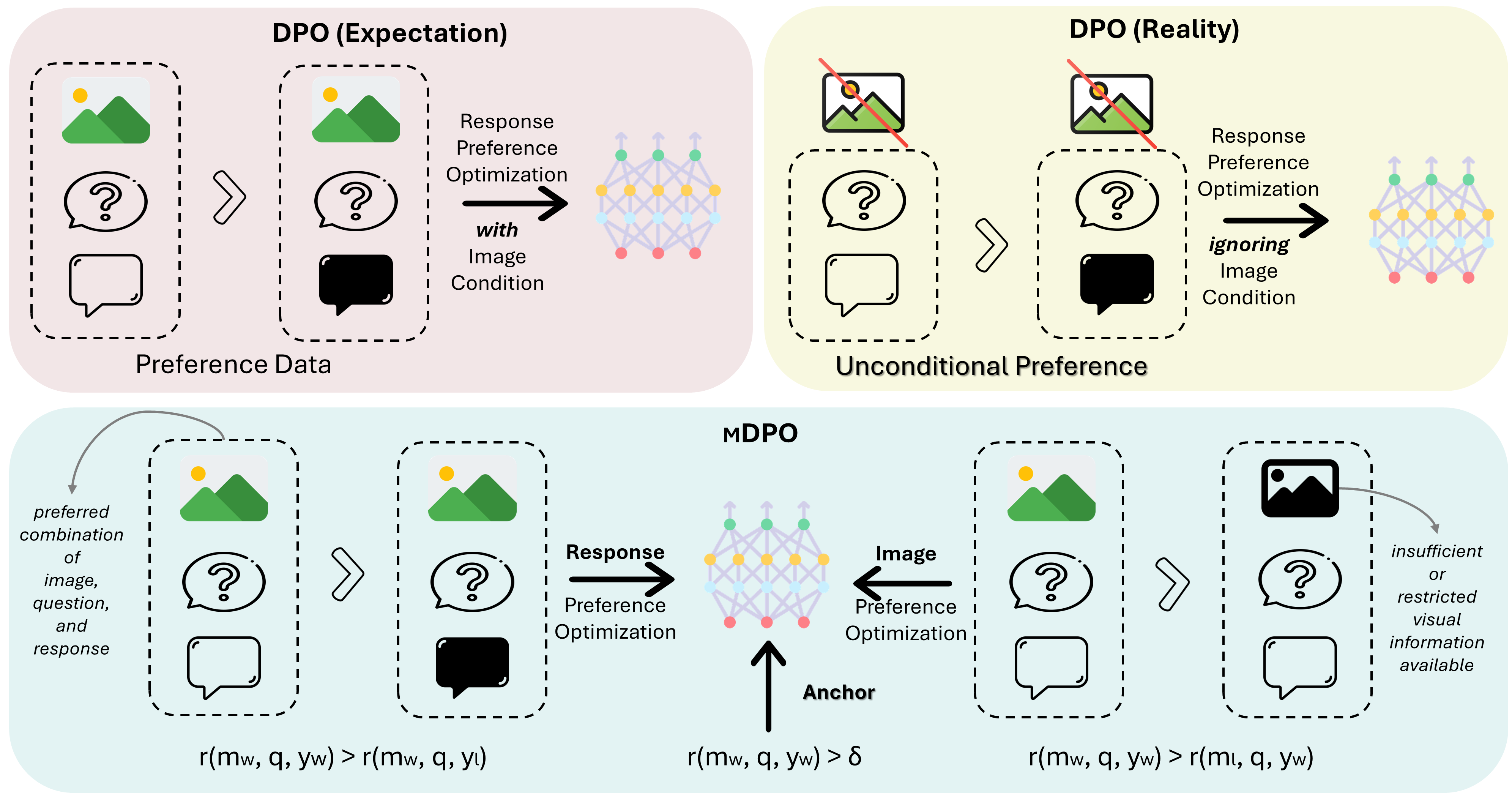
MDPO:Conditional Preference Optimization for Multimodal Large Language Models
MDPO: Conditional Preference Optimization for Multimodal Large Language Models 相关链接:arxiv 关键字:多模态、大型语言模型、偏好优化、条件偏好优化、幻觉减少 摘要 直接偏好优化(DPO)已被证明是大型语言模型(LLM)对齐的有效方法。近期的研究尝试将DPO应用于多模态场景,但发现难以实现一致的改进。通

风格迁移学习笔记(1):Multimodal Transfer: A Hierarchical Deep Convolutional Neural Network for Fast
以下将分为3个部分介绍: 效果解決的問題How to solve it? 1.效果: 先来看一下效果
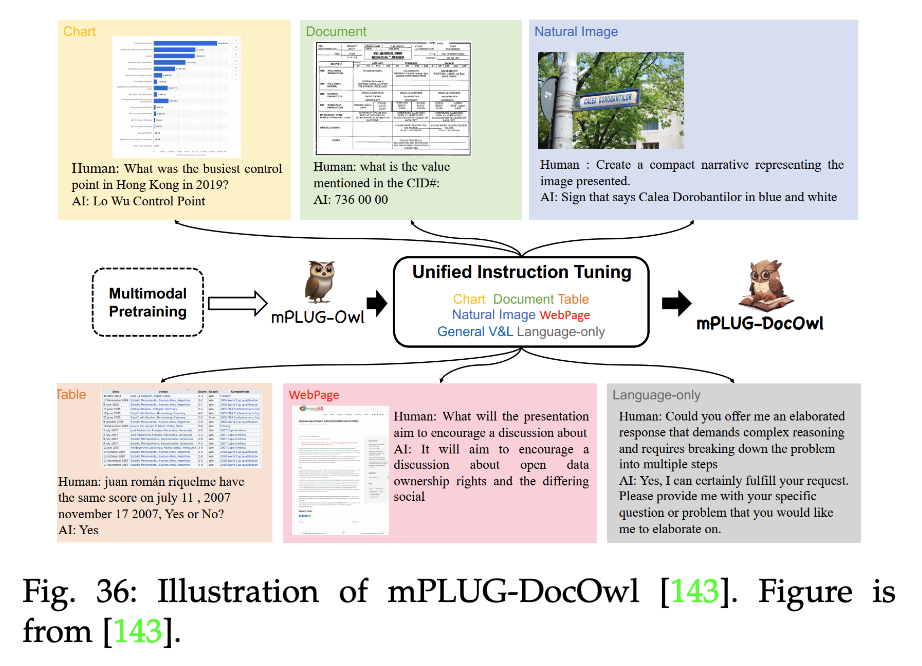
【LLM多模态】综述Visual Instruction Tuning towards General-Purpose Multimodal Model
note 文章目录 note论文1. 论文试图解决什么问题2. 这是否是一个新的问题3. 这篇文章要验证一个什么科学假设4. 有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?5. 论文中提到的解决方案之关键是什么?6. 论文中的实验是如何设计的?7. 用于定量评估的数据集是什么?代码有没有开源?8. 论文中的实验及结果有没有很好地支持需要验证的科学假设?9. 这篇论文到底有

【提示学习论文】PMF:Efficient Multimodal Fusion via Interactive Prompting论文原理
Efficient Multimodal Fusion via Interactive Prompting(CVPR2023) 基于交互式提示的高效多模态融合方法减少针对下游任务微调模型的计算成本提出模块化多模态融合架构,促进不同模态之间的相互交互将普通提示分为三种类型,仅在单模态transformer深层添加提示向量,显著减少训练内存的使用 1 Introduction 提示微调方法采用顺
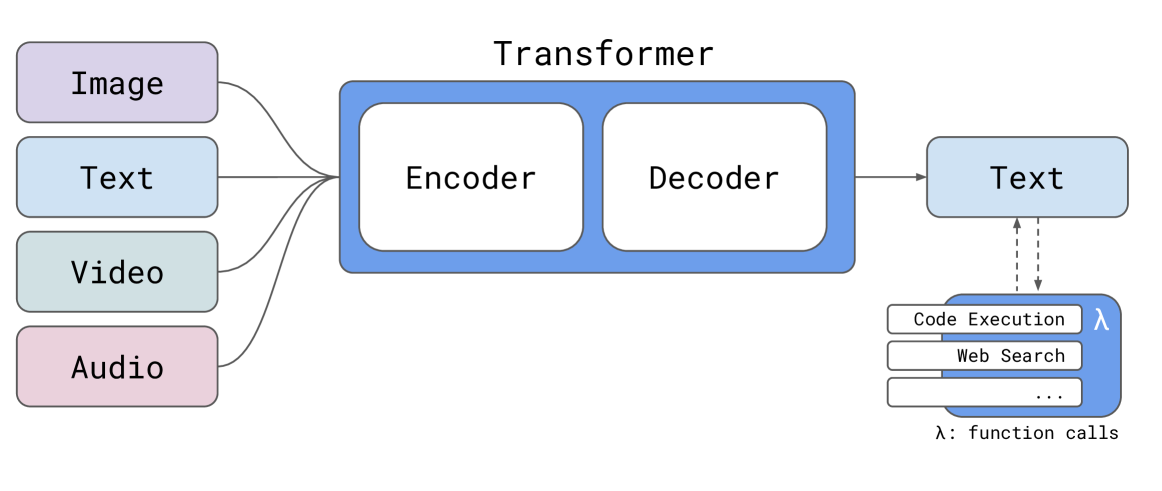
Reka Core, Flash, and Edge: A Series of Powerful Multimodal Language Models
Reka Core, Flash, and Edge: A Series of Powerful Multimodal Language Models 相关链接:arxiv 关键字:Multimodal Language Models、Reka Core、Reka Flash、Reka Edge、State-of-the-Art 摘要 我们介绍了 Reka Core、Flash 和 E
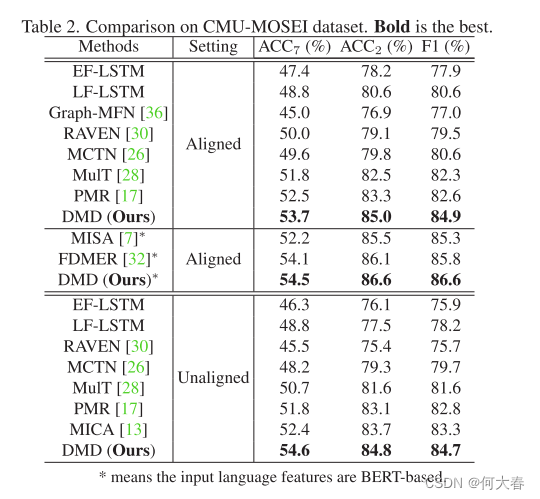
Decoupled Multimodal Distilling for Emotion Recognition 论文阅读
Decoupled Multimodal Distilling for Emotion Recognition 论文阅读 Abstract1. Introduction2. Related Works2.1. Multimodal emotion recognition2.2. Knowledge distillation3. The Proposed Method3.1. Multimod

一文读懂「MLLM,Multimodal Large Language Model」多模态大语言模型
一. 什么是多模态? 模态是事物的一种表现形式,多模态通常包含两个或者两个以上的模态形式,是从多个视角出发对事物进行描述。生活中常见多 模态表示,例如传感器的数据不仅仅包含文字、图像,还可以包括与之匹配的温度、深度信息等。使用多模态数据能够使得事物呈现更加立体、全面,多模态研究成为当前研究重要方面,在情感分析、机器翻译、自然语言处理 和生物医药前沿方向取得重大突破。 1.1 背景 T

Woodpecker: Hallucination Correction for Multimodal Large Language Models----啄木鸟:多模态大语言模型的幻觉校正
Abstract 幻觉是笼罩在快速发展的多模态大语言模型(MLLM)上的一个大阴影,指的是生成的文本与图像内容不一致的现象。为了减轻幻觉,现有的研究主要采用指令调整的方式,需要用特定的数据重新训练模型。在本文中,我们开辟了一条不同的道路,引入了一种名为 Woodpecker 的免训练方法。就像啄木鸟治愈树木一样,它从生成的文本中挑选并纠正幻觉。具体来说,啄木鸟由五个阶段组成:关键概念提取、问题制
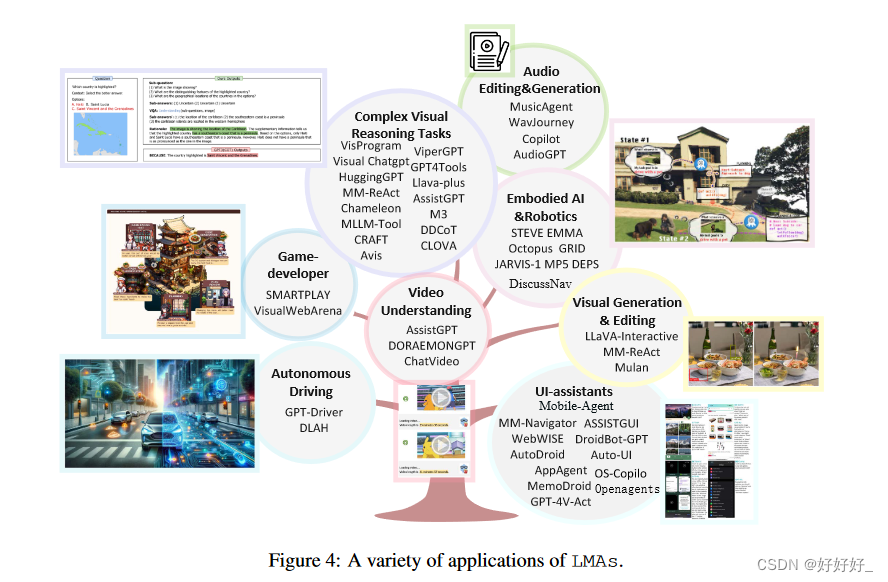
Large Multimodal Agents: A Survey(大型多模态代理:综述)
目录 1. Introduction2. LMAS的核心组件3. LMAS的四种类型4. 多代理协作5. 评估6. 应用 大型语言模型(LLM)在支持基于文本的人工智能代理方面取得了卓越的性能,赋予它们类似于人类的决策和推理能力。与此同时,出现了一种新兴的研究趋势,重点是将这些由LLMs支持的人工智能代理扩展到多模式领域。此扩展使人工智能代理能够解释和响应不同的多模式用户查询,从而处

MM1: Methods, Analysis Insights from Multimodal LLM Pre-training
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training 相关链接:arxiv 关键字:多模态学习、大型语言模型、预训练、视觉语言连接、混合专家模型 摘要 本文讨论了构建高性能的多模态大型语言模型(MLLMs)。特别地,我们研究了各种架构组件和数据选择的重要性。通过对图像编码器、视觉语言连接器以及各种预训练数据
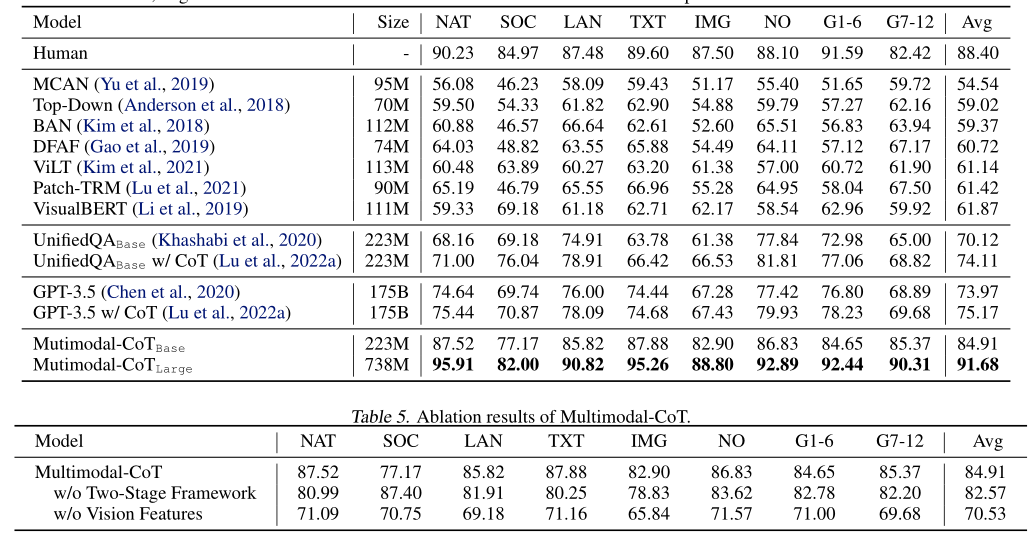
论文阅读之Multimodal Chain-of-Thought Reasoning in Language Models
文章目录 简介摘要引言多模态思维链推理的挑战多模态CoT框架多模态CoT模型架构细节编码模块融合模块解码模块 实验结果总结 简介 本文主要对2023一篇论文《Multimodal Chain-of-Thought Reasoning in Language Models》主要内容进行介绍。 摘要 大型语言模型(LLM)通过利用思想链(CoT)提示生成中间推理链作为推断答案的基
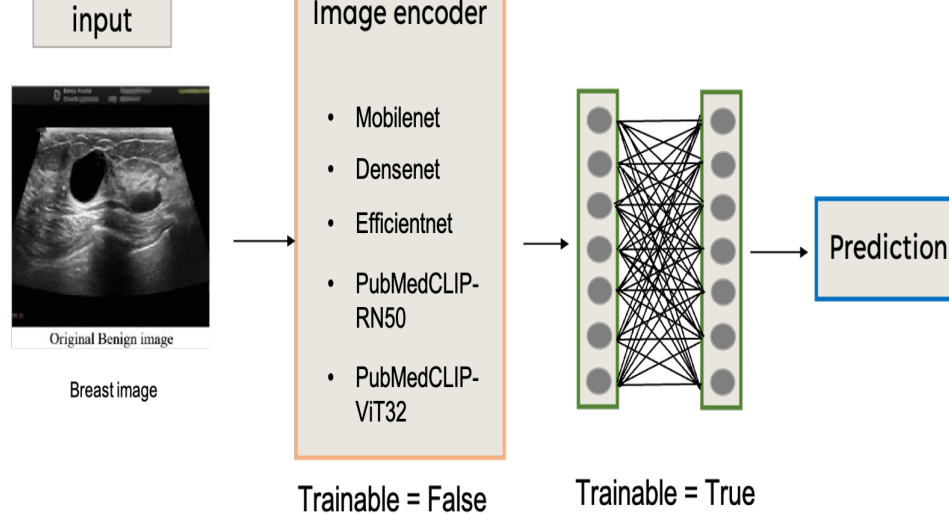
A Multimodal Transfer Learning Approach for Medical Image Classification
是否可训练可用🔥和❄表示,这样更美观 辅助信息 作者未提供代码
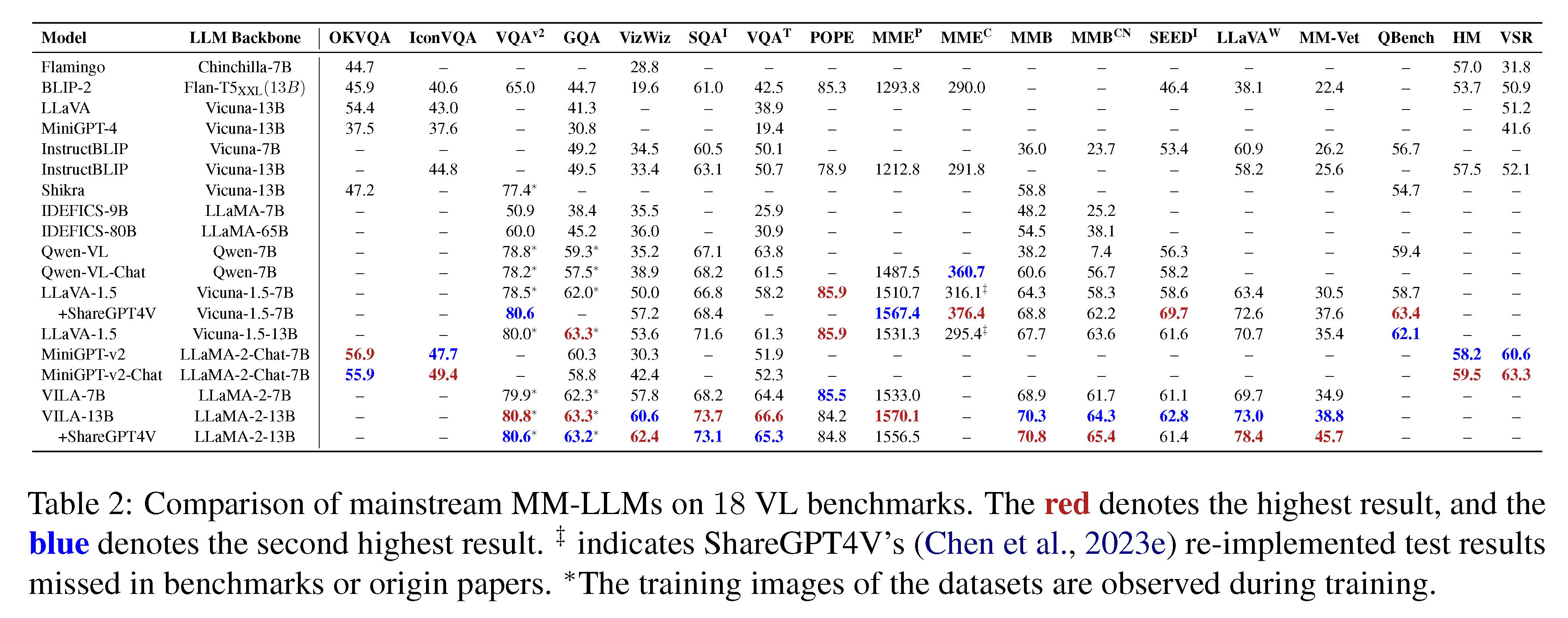
AI之MLM:《MM-LLMs: Recent Advances in MultiModal Large Language Models多模态大语言模型的最新进展》翻译与解读
AI之MLM:《MM-LLMs: Recent Advances in MultiModal Large Language Models多模态大语言模型的最新进展》翻译与解读 目录 《MM-LLMs: Recent Advances in MultiModal Large Language Models》翻译与解读 Abstract摘要 Figure 1: The timeli
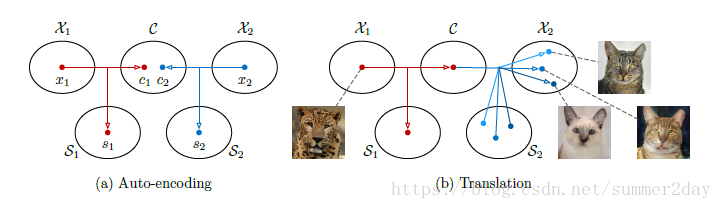
论文Multimodal Unsupervised Image-to-Image Translation
简介: 无监督图像迁移网络是计算机视觉领域的一个技术难题,即给定一张源域图像,如何在没有其他图像样本的情况下,学习相应目标域图像的条件分布。当处理多维条件分布时,现有的方法是在过度简化的假设条件下,通过绘制源域图像和确定的、一对一的目标图像来进行建模。 然而,上述方法无法用来生成给定源域图像的多种多样的目标图像。因此,本文提出了一种多维无监督图像迁移网络框架。 本文中假定代表图像可以被分解成
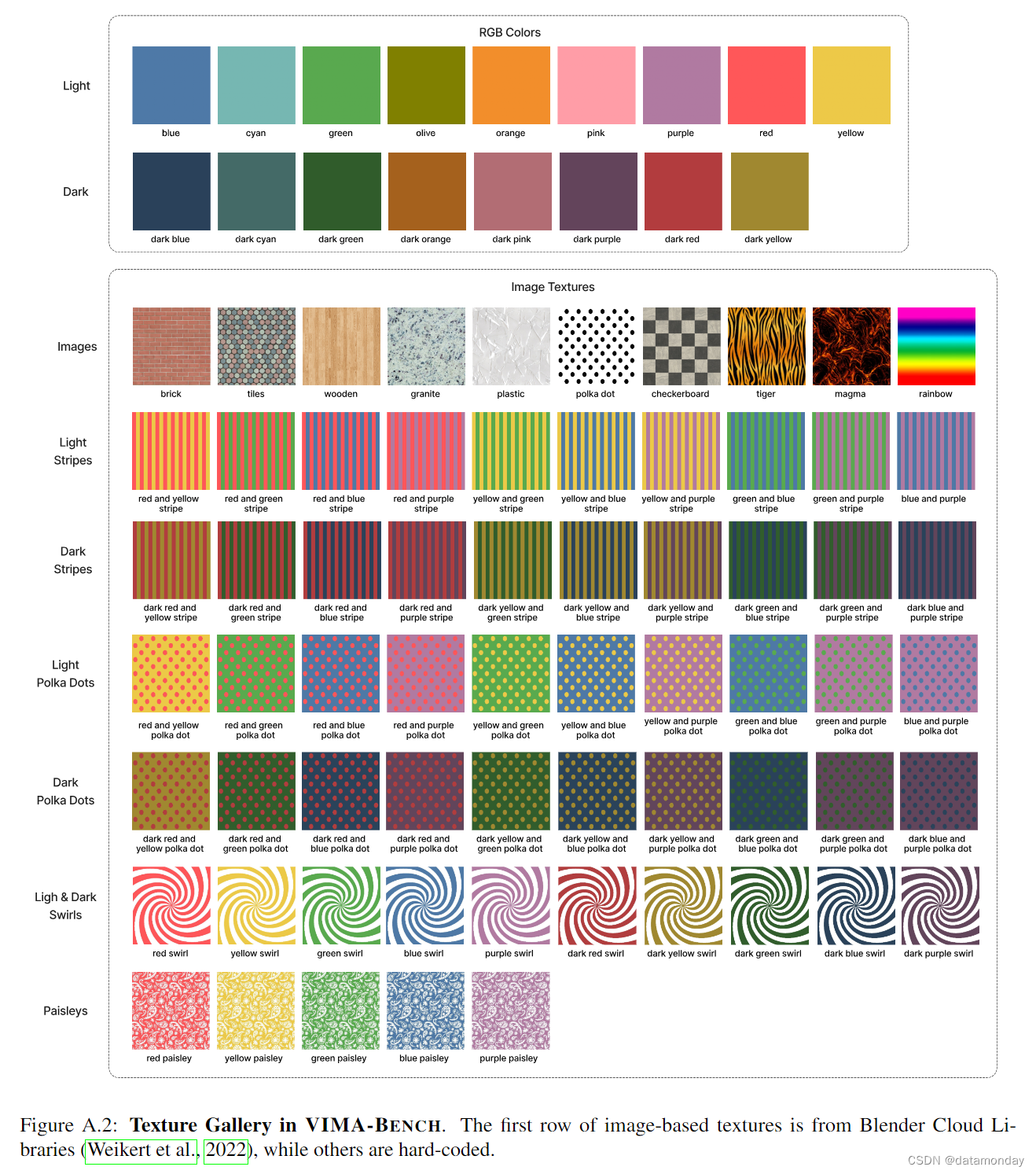
【EAI 016】VIMA: General Robot Manipulation with Multimodal Prompts
论文标题:VIMA: General Robot Manipulation with Multimodal Prompts 论文作者:Yunfan Jiang, Agrim Gupta, Zichen Zhang, Guanzhi Wang, Yongqiang Dou, Yanjun Chen, Li Fei-Fei, Anima Anandkumar, Yuke Zhu, Linxi Fan

Multimodal Segmentation of Medical Images with Heavily Missing Data
F是mapping function 吐槽 图3太简单了吧。作者未提供代码

论文阅读 《Multimodal Remote Sensing Image Registration Based on Image Transfer and Local Features》
该文章是一篇遥感图像融合的文章,但在图片的预处理中,使用风格迁移的方法对图片进行了处理,使得使用经典的SIFT方法进行图像配准拼接时能够找到更多对应特征,从而实现更好地融合效果。 1.Motivation 多模态遥感图像的自动配准是一个具有挑战性的问题,包括其中包括光学、光探测与测距、合成孔径雷达图像等多种图像之间的配准问题。由于成像原理的不同,这些图像在局部区域的灰度值、纹理和景观特征也不同

Next-GPT: Any-to-Any Multimodal LLM
Next-GPT: Any-to-Any Multimodal LLM 最近在调研一些多模态大模型相关的论文,发现Arxiv上出的论文根本看不过来,遂决定开辟一个新坑《一页PPT说清一篇论文》。自己在读论文的过程中会用一页PPT梳理其脉络和重点信息,旨在帮助自己和读者快速了解一篇论文。 论文PPT在GitHub中:https://github.com/FutureForMe/One_Page_

医学影像处理--Unet在Multimodal Brain Tumor Segmentation Challenge 2019上的应用
背景 Multimodal Brain Tumor Segmentation Challenge 2019 http://braintumorsegmentation.org/ 是一个脑部肿瘤分割的比赛,主要是利用病人的核磁共振的图像,预测病人脑部胶质瘤的位置,预测病人的生存期,这两部分会有一个排名,这是属于图像的语义分割的问题。 数据分析 原始的数据需要在这个网站上注册下载,分成两部分,t

EMNLP 2020 VMSMO: Learning to Generate Multimodal Summary for Video-based News Articles
动机 多模态新闻能够显著提高用户对信息性的满意度。目前流行的一种多媒体新闻形式是为用户提供一段生动的视频和一篇相应的新闻文章,这种形式被CNN、BBC等有影响力的新闻媒体以及Twitter、Weibo等社交媒体所采用。自动生成多模态摘要,即选择合适的视频封面帧,生成合适的文章文本摘要,可以帮助编辑节省时间,读者更有效地做出决策。在实际应用中,输入通常是由数百帧组成的视频,且通常需要选择封面图
《Affective Region Recognition and FusionNetwork for Target-Level Multimodal SentimentClassificati》阅读
原论文地址:https://ieeexplore.ieee.org/abstract/document/10014688/ 代码地址:https://github.com/LiLi-Jia/ARFN(作者暂未上传代码) 摘要 目标级/方面级的多模态情感分类任务已经获得更多的关注。现有的方法主要依赖于将整个图像和文本结合起来,忽略了图像中的隐藏情感区域的作用。基于这个问题作者提出了ARFN
Multimodal Segmentation of Medical Images with Heavily Missing Data
F是mapping function 吐槽 图3太简单了吧。作者未提供代码
【论文笔记】Gemini: A Family of Highly Capable Multimodal Models——细看Gemini
Gemini 【一句话总结,对标GPT4,模型还是transformer的docoder部分,提出三个不同版本的Gemini模型,Ultra的最牛逼,Nano的可以用在手机上。】 谷歌提出了一个新系列多模态模型——Gemini家族模型,包括Ultra,Pro,Nano(1.5B Nano-1,3.25BNano-2)三种尺寸(模型由大到小)。在图像、音频、视频和文本理解方面都表现出现,Gemi