本文主要是介绍《Affective Region Recognition and FusionNetwork for Target-Level Multimodal SentimentClassificati》阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

原论文地址:https://ieeexplore.ieee.org/abstract/document/10014688/
代码地址:https://github.com/LiLi-Jia/ARFN(作者暂未上传代码)
摘要
目标级/方面级的多模态情感分类任务已经获得更多的关注。现有的方法主要依赖于将整个图像和文本结合起来,忽略了图像中的隐藏情感区域的作用。基于这个问题作者提出了ARFN模型,该模型更关注视觉和文本在向量空间中的对齐。
引言
作者首先认为文本和视觉信息是相互补充和强化的。文本内容简短,非正式,信息丰富,这种现象有可能导致目标的情绪主要由图像决定。作者在此处举了下述的例子:

作者认为如果不看图像,只看文字表达,我们会认为两条信息都是中立的情感,只有结合图片才能进行正确分类。(对于图(a)我只看文字也能看出这条新闻表达了正面的情感)。
其次作者发现,现有的大多数研究要么简单的将不同模式中提取出的特征连接起来,要么在一个粗糙的水平上学习图像,文本和目标之间的关系。作者认为这样做并不合理,因为人类的情感主要是由图像中某个区域引起的,除此之外图像的其余部分并为发挥很多作用(类似注意力机制)。如下图所示:

图(c)我们之所以一眼就能看出表达了积极的情感,主要与图中那个中年人的笑容有关,至于背景中的房屋等次要信息,对我们的判断影响很小。
作者基于此提出了ARFN模型。
提出的方法
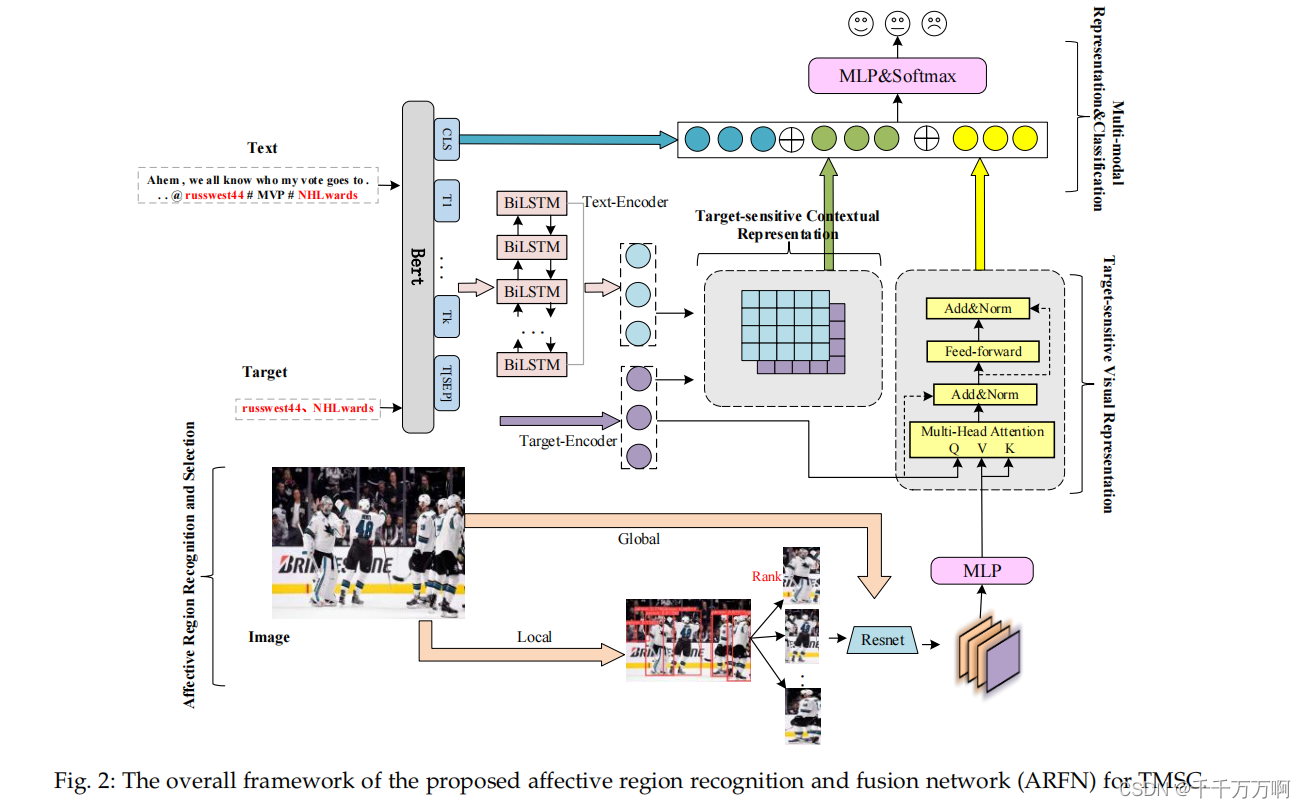
模型结构如上图所示。
总体流程:
1.使用Yolov5模型来检测图像中的对象。随后使用在Sentiment_LDL, Emotion和EmotionRoI上预训练过的ResNet-152来对检测到的对象进行编码。随后计算每个对象的ARs_score值,并根据该值对其进行排序,公式表达如下:
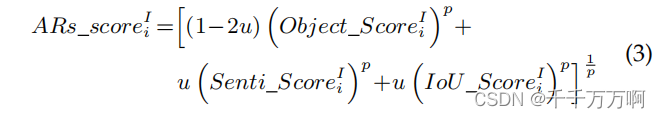
Object_Score和IoU_Score是在使用Yolov5时获得的。Senti_Score是作者提出的一个可以量化情感区域特征重要性的值,其计算公式如下:
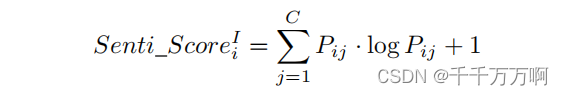
P为ResNet+SoftMax网络最后一层的输出,即预测概率。
2. 从排序完成的对象列表中取出最重要的J个对象,将其和整张图片输入到ResNet-152中进行特征提取(此处将从整张图片中提取出的特征叫做全局特征,将从J个对象中提取的特征叫做局部特征)。随后将全局特征和局部特征拼接起来后输入到MLP中进行维度的调整,输出记为RV。(此处作者并没有说清楚是如何进行结合的,因为全局特征只有一个,而局部特征有J个,我猜测此处是将全局特征与每一个局部特征进行相加。)
3.将Target输入到Bert中获得Target的word embedding,记为RT。(此处作者提到,一个Target可能会有多个单词组成,此处作者将其长度设置为K。但就按照我对该任务的理解以及文中的例子来看,多数的Target只是单独的一个单词。所以此处大部分情况下是只对单独的一个单词进行编码。)随后使用RT获得Q,使用RV生成K和V输入到多头注意力+MLP的网络结构中获得结果,最后通过stack运算进行降维,获得输出RTSV。(stack此处解释的并不清楚,结合图以及作者此处的文字表达推断此处应该是一个类似sumpooling的操作。)
4.将文本输入到Bert中进行编码。将[CLS]标记位的输出记为RText,将模型输出的word embedding部分输入到BiLSTM中获得文本特征RS。将RS与RT进行与第三步同样的处理后获得RTCR。
5.最后将RTSV,RTCR和Rtext进行拼接后输入到MLP中获得最终的分类结果。
实验数据集
Twitter-15:https://github.com/jefferyYu/TomBERT/tree/master/absa_data/twitter2015
Twitter-17:https://github.com/jefferyYu/TomBERT/tree/master/absa_data/twitter
readme中会告诉你如何下载并处理图片。
实验结果与分析
1.通过对比实验证明了模型的有效性。
2.通过消融实验证明了模型中每个模块都是有作用的。
3.进一步的分析。(1)通过可视化说明了作者使用的ARs_score值确实能够检测出图中最重要的对象,例子如下图所示:

(2)对 ARs_score计算公式中的u以及选取的对象数量J进行了分析。发现当u=0.3,J=3时模型获得最好的效果。可视化的图如下所示:
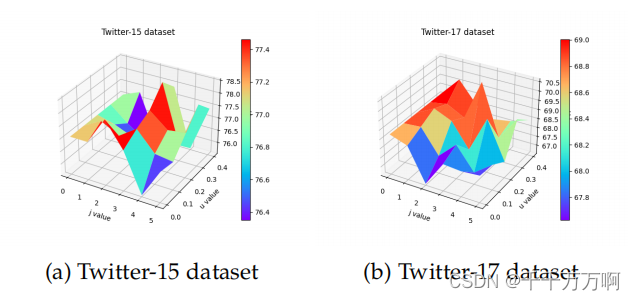
(这种类型的图我多次看到了,好像在进行超参数分析时经常用到,后续自己也要学习下如何画出类似的图。)
(3)验证不同的图像情绪分类预训练模型的选取对最终结果的影响(我认为此处是为了验证第一步中使用Sentiment_LDL, Emotion和EmotionRoI对ResNet-153进行预训练对结果是否有影响)。
总结
整篇文章作者并未开源代码,所以部分模型的细节智能靠文章来进行猜测,因此如果有那些地方理解错误,大家请指出来。
这篇关于《Affective Region Recognition and FusionNetwork for Target-Level Multimodal SentimentClassificati》阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








