recognition专题

人脸识别开源项目之-face_recognition
特性 从图片里找到人脸 定位图片中的所有人脸: import face_recognitionimage = face_recognition.load_image_file("your_file.jpg")face_locations = face_recognition.face_locations(image) 识别人脸关键点 识别人脸关键点,包括眼睛、鼻子、嘴和下巴。

Attribute Recognition简记1-Video-Based Pedestrian Attribute Recognition
创新点 1.行人属性库 2.行人属性识别的RNN框架及其池化策略 总结 先看看行人属性识别RNN结构: backbone是ResNet50,输出是每一帧的空间特征。这组特征被送到两个分支,分别是空间池化和时间建模。最后两种特征拼接。然后分类(FC)。 LSTM关注帧间变化。受cvpr《Recurrent Convolutional Network for Video-Based Person

Face Recognition简记1-A Performance Comparison of Loss Functions for Deep Face Recognition
创新点 1.各种loss的比较 总结 很久没见到这么专业的比较了,好高兴。 好像印证了一句话,没有免费的午餐。。。。 ArcFace 和 Angular Margin Softmax是性能比较突出的

【读点论文】Scene Text Detection and Recognition: The Deep Learning Era
Scene Text Detection and Recognition: The Deep Learning Era Abstract 随着深度学习的兴起和发展,计算机视觉发生了巨大的变革和重塑。场景文本检测与识别作为计算机视觉领域的一个重要研究领域,不可避免地受到了这波革命的影响,从而进入了深度学习时代。近年来,该社区在思维方式、方法论和性能方面取得了长足的进步。本综述旨在总结和分析深度学

水下目标检测(低光照目标检测)方法-发表在Patter Recognition,代码已开源
这里写自定义目录标题 前言动机贡献Overview一些实验结果数据集主要实验结果实验结果展示 总结 前言 Hi,各位读者,好久不见!现在我已经从北大博士毕业,成为一名小青椒啦!工作还是需要宣传的。今天想分享我在水下目标检测的工作:《A gated cross-domain collaborative network for underwater object detection》

步态识别论文Dynamic Aggregated Network for Gait Recognition(1)
摘要:步态识别在视频监控、犯罪现场侦查、社会安全等领域有着广泛的应用前景。然而,在实际场景中,步态识别往往受到多种外部因素的影响,如携带条件、穿着外套、视角多样等。近年来,各种基于深度学习的步态识别方法取得了可喜的成果,但它们倾向于使用固定权重的卷积网络提取显著特征之一,没有很好地考虑关键区域中步态特征之间的关系,忽略了完整运动模式的聚合。 在本文中,我们提出了一个新的观点,即实际的步态特征包括

Deep Face Recognition论文翻译
Deep Face Recognition论文翻译 作者: Omkar M. Parkhi ····································· Visual Geometry Group omkar@robots.ox.ac.uk Andrea Vedaldi ······································ Department of

I3D视频分类论文梗概及代码解读Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
论文https://arxiv.org/pdf/1705.07750.pdf,from DeepMind ,CVPR2017 代码https://github.com/LossNAN/I3D-Tensorflow 2017年视频分类最好的网络,同时提供了VGG的预训练模型,网络端到端,简单易懂,便于部署及工程化。只是跑一下基本有个Tensorflow,单显卡就能训练和测试,效果还好,一绝。本文

MobiFace: A Lightweight Deep Learning Face Recognition on Mobile Devices
1.网络情况介绍, 与mobilenet 相似 2.准确率对比

17.2.20 Sparsifying Neural Network Connections for Face Recognition 小感
首先作为自己的第一篇博客,不为别的。在大致读了 > 《Sparsifying Neural Network Connections for Face Recognition》 本文主要是提出了一种稀疏神经元连接的方法。主要是根据神经元之间的相关性正负和大小,只保留对模型影响较大的神经元间的连接,将影响不大的舍去。 本文并不是第一个考虑到减少神经元连接的方法。GoogLeNet在ImageNe

3DCNN参数解析:2013-PAMI-3DCNN for Human Action Recognition
3DCNN参数解析:2013-PAMI-3DCNN for Human Action Recognition 参数分析 Input:7 @ 60 × \times × 40, 7帧,图片大小60 × \times × 40 hardwired: H1 产生5通道信息,分别是gray, gradient-x, gradient-y, optflow-x, optflow-y

Image Recognition and Object Detection
原文地址:https://www.learnopencv.com/image-recognition-and-object-detection-part1/ In this part, we will briefly explain image recognition using traditional computer vision techniques. I refer to techniq

【论文阅读】Activity Recognition using Cell Phone Accelerometers
Activity Recognition using Cell Phone Accelerometers 引用: Kwapisz J R, Weiss G M, Moore S A. Activity recognition using cell phone accelerometers[J]. ACM SigKDD Explorations Newsletter, 2011, 12(2): 7
Face Recognition Loss Evolution
问题: 人脸识别的框架一般是这样的(图来自center loss): 这个框架的有一个问题在于,用原始softmax学习到的特征,仅仅是separable的,而不够discriminative。在最后的分类层上,不同输出节点对应的权重可以看做类中心,用softmax分类的过程可以看成使样本尽量靠近本类中心,并远离其他类中心的过程。这个过程本身是希望类间距离尽量大、类内距离尽量小的,但是并
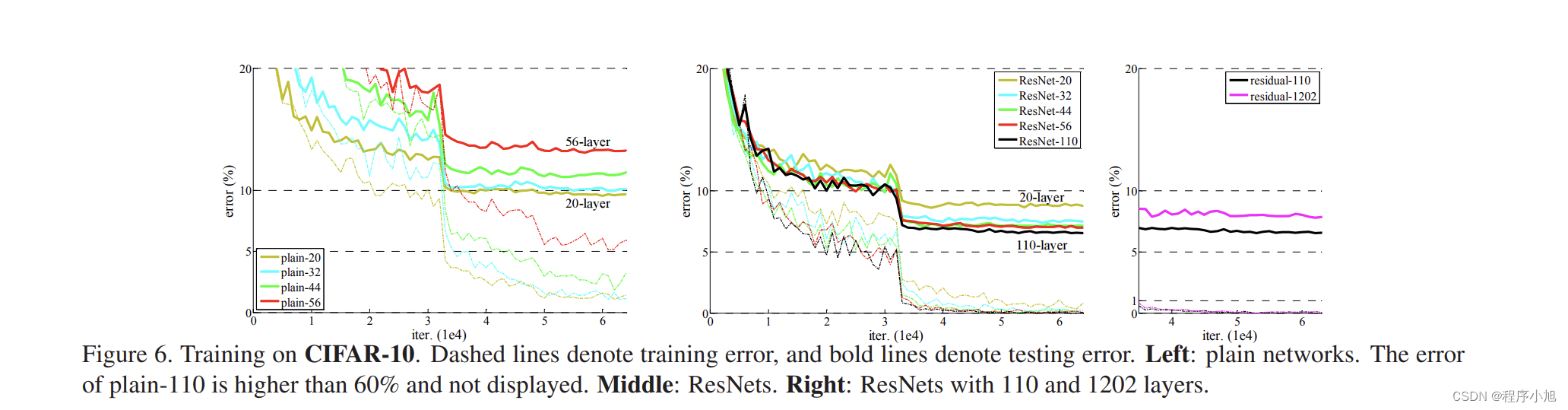
ResNet论文解读—Residual Learning Deep for lmage Recognition(2016)
ResNet论文解读—Residual Learning Deep for lmage Recognition(2016) 研究背景 图像识别中的深度残差学习网络(MSRA:微软亚洲研究院) 认识数据集:ImageNet的大规模图像识别挑战赛 LSVRC-2015:ImageNet Large Scale Visual Recoanition Challenge(15年的相关比赛)

hdu4331 Image Recognition 就暴力啊。。啊。。
题意: 给一个1和0组成的正方形矩阵,求 四条边都由1构成的正方形的个数。 方法: 先统计矩阵中每一点,向四个方向,最多有多少个连续的1,这里用dp做也 与此同时,顺便求下 能向右下和 左上 两个方向 形成的最大的正方形的边长 (就是里面的d1[][] d2[][]) 为什么朝这俩方向呢,这样方便统计最长的连续的1啊,四个方向一起好像不行啊 然后枚举边长,就没了 #i

论文解读 Combating Adversarial Misspellings with Robust Word Recognition
1. 简介 论文链接 https://www.aclweb.org/anthology/P19-1561.pdf 这篇文章发表在ACL19,目的是为了解决错误拼写的对抗(adversarial misspellings)问题。尽管现在的deep learning和Transformer已经非常先进,但是当他们面对错误拼写时仍然十分的脆弱(brittle),一个单词的字母写错就可以愚弄(fool
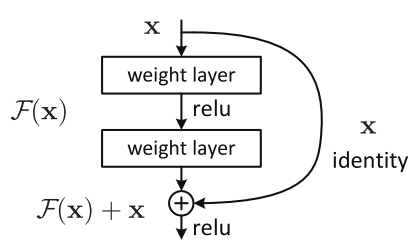
CNN初探(四)------Deep Residual Learning for Image Recognition
Degradation problem 是否通过简单地叠加网络的层数来提高准确率?为了得到答案,首先要解决vanishing/exploding gradients问题,这会极大地妨碍收敛。通过normalized initialization([1,2,3,4])和intermediate normalization layers[5]解决。 当深度网络能够收敛时,精度开始饱和,然后开始快速
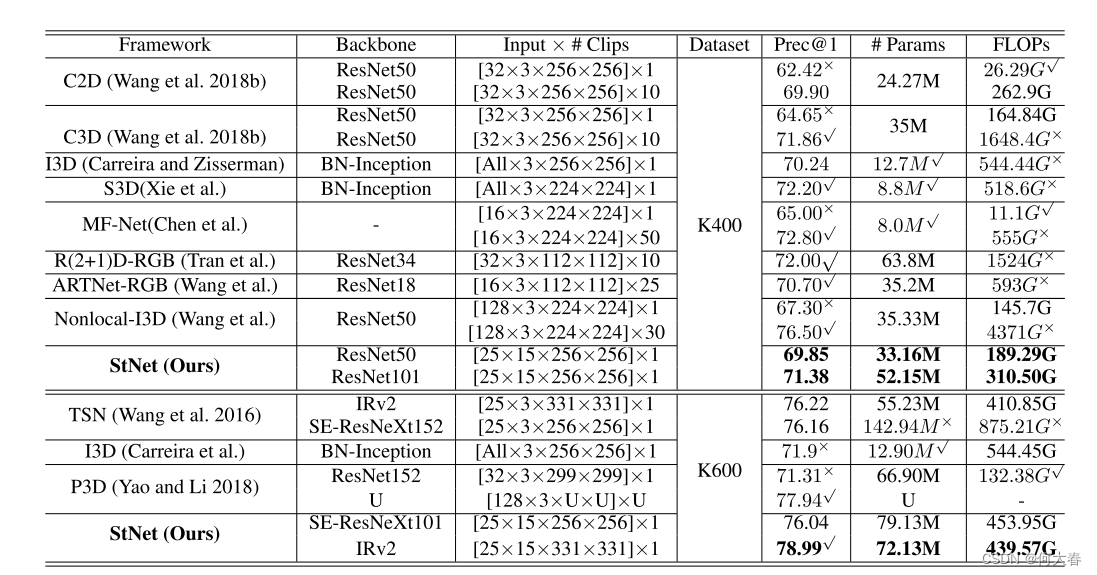
StNet: Local and Global Spatial-Temporal Modeling for Action Recognition 论文阅读
StNet: Local and Global Spatial-Temporal Modeling for Action Recognition 论文阅读 Abstract1 Introduction2 Related Work3 Proposed Approach4 Experiments5 Conclusion 文章信息: 原文链接:https://ojs.aaai.org

CAST: Cross-Attention in Space and Time for Video Action Recognition
标题:CAST: 时空交叉注意力网络用于视频动作识别 原文链接:2311.18825v1 (arxiv.org)https://arxiv.org/pdf/2311.18825v1 源码链接:GitHub - KHU-VLL/CASThttps://github.com/KHU-VLL/CAST 发表:NeurIPS-2023(CCF A、顶会) 摘要 在视频中识别人类动作需要空间
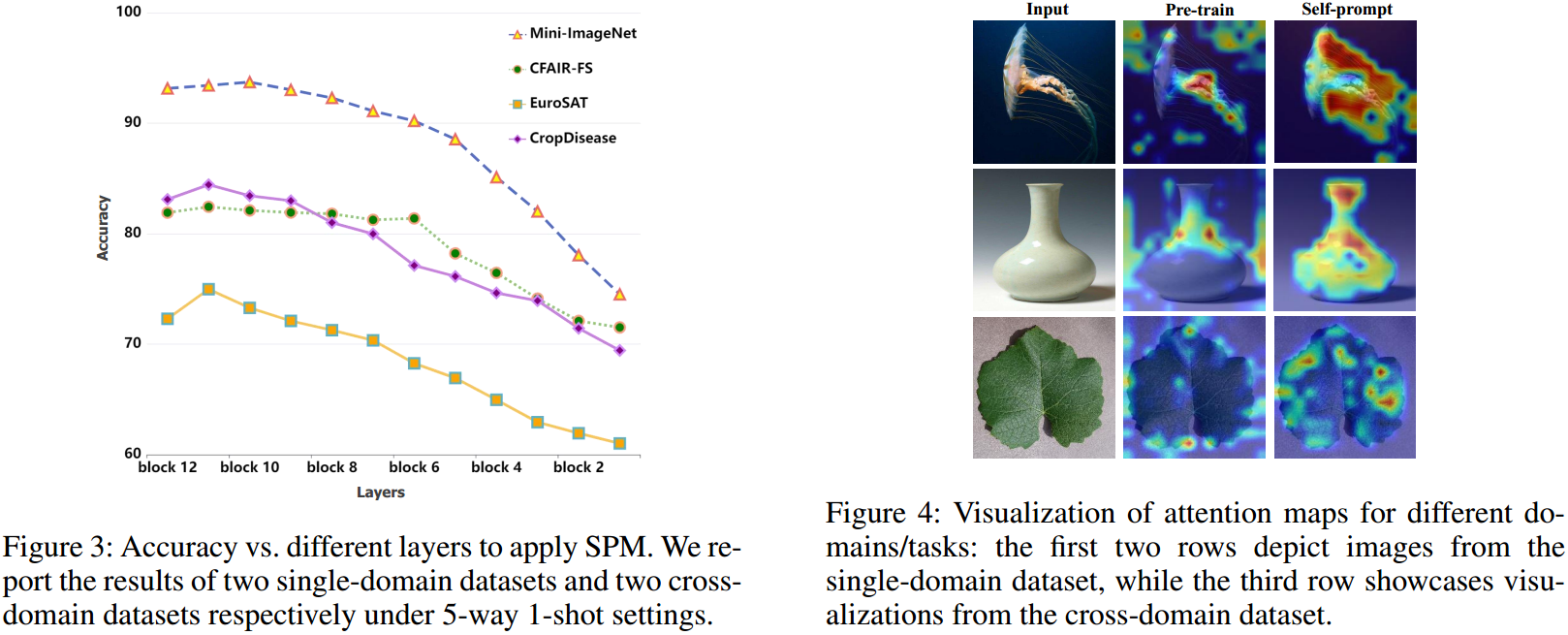
论文解读:Self-Prompt Mechanism for Few-Shot Image Recognition
文章汇总 存在的问题 由于提示文本和图像特征之间固有的模态差异,常规的提示方法的性能受到限制。 动机 让视觉信息自己给自己提示 解决办法 SPM涉及到图像编码器跨空间和通道维度产生的固有语义特征的系统选择,从而产生自提示信息。随后,在将这种自提示信息反向传播到神经网络的更深层后,它有效地引导网络学习和适应新样本。 流程解读 作者的想法很简单,常规的方法都是用文本来指导Image E
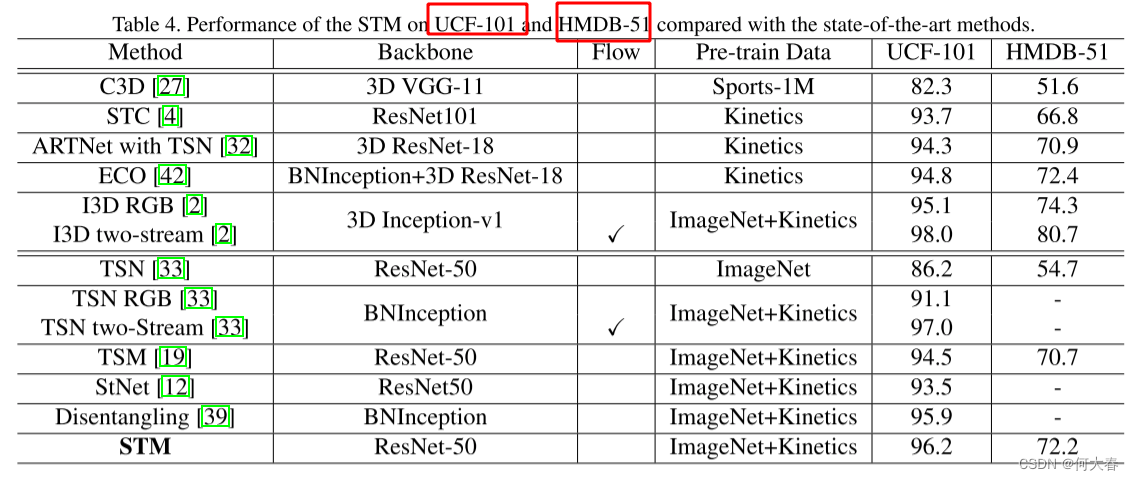
STM: SpatioTemporal and Motion Encoding for Action Recognition 论文阅读
STM: SpatioTemporal and Motion Encoding for Action Recognition 论文阅读 Abstract1. Introduction2. Related Works3. Approach3.1. Channel-wise SpatioTemporal Module3.2. Channel-wise Motion Module3.3. STM

Convolutional Neural Networks for Visual Recognition
CS231n简介 CS231n的全称是CS231n: Convolutional Neural Networks for Visual Recognition,即面向视觉识别的卷积神经网络。该课程是斯坦福大学计算机视觉实验室推出的课程。需要注意的是,目前大家说CS231n,大都指的是2016年冬季学期(一月到三月)的最新版本。 课程描述:请允许我们引用课程主页上的官方描述如下。 计算
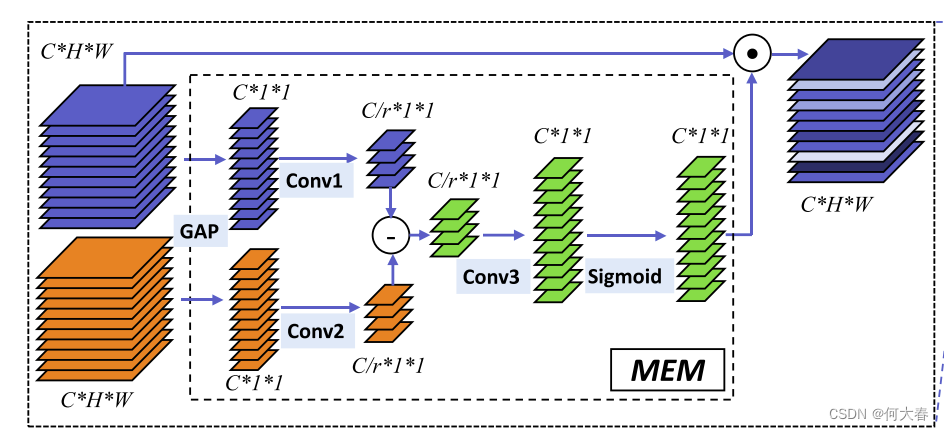
TEINet: Towards an Efficient Architecture for Video Recognition 论文阅读
TEINet: Towards an Efficient Architecture for Video Recognition 论文阅读 Abstract1 Introduction2 Related Work3 Method3.1 Motion Enhanced Module3.2 Temporal Interaction Module3.3 TEINet 4 Experiments5 C
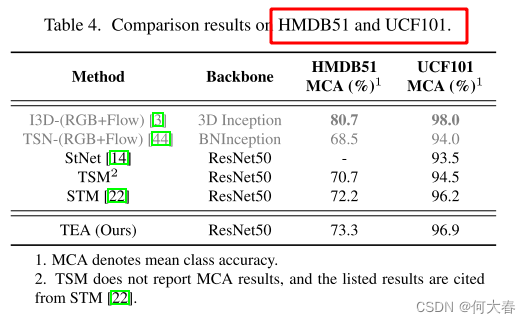
TEA: Temporal Excitation and Aggregation for Action Recognition 论文阅读
TEA: Temporal Excitation and Aggregation for Action Recognition 论文阅读 Abstract1. Introduction2. Related Works3. Our Method3.1. Motion Excitation (ME) Module3.1.1 Discussion with SENet 3.2. MultipleT
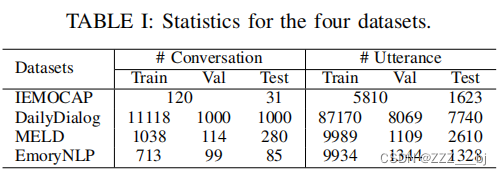
Dynamic Extraction of Subdialogues for Dialogue Emotion Recognition
对话情感识别的子对话动态提取 摘要1. 介绍2 相关工作2.1 对话上下文建模2.2 常识知识 3 方法3.1 问题定义3.2 模型概述3.3 特征提取模块3.4 依赖性建模3.5 交互式子对话提取模块3.6 重要性增强的多头自注意力模块3.7 子对话框主题提取模块3.8. 分类模块 四、实验4.1 数据集4.1 实验细节4.2 基线4.3. 结果与分析 摘要 对话中的情绪识别