本文主要是介绍ResNet论文解读—Residual Learning Deep for lmage Recognition(2016),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ResNet论文解读—Residual Learning Deep for lmage Recognition(2016)
研究背景
图像识别中的深度残差学习网络(MSRA:微软亚洲研究院)
认识数据集:ImageNet的大规模图像识别挑战赛
LSVRC-2015:ImageNet Large Scale Visual Recoanition Challenge(15年的相关比赛)
ILSVRC:大规模图像识别挑战赛
ImageNet Large Scale Visual RecognitionChallenge是李飞飞等人于2010年创办的图像识别挑战赛,自2010起连续举办8年,极大地推动计算机视觉发展。
比赛项目涵盖:图像分类(Classification)、目标定位(Object localization)、目标检测(Object detection)、视频目标检测(Object detection from video)、场景分类(Scene classification)、场景解析(Scenearsing)
竞赛中脱颖而出大量经典模型:alexnet, vgg,googlenet, resnet, densenet等
相关的研究
与之相关的一篇论文:Highway Network:首个成功训练成百上千层(100及900层)的卷积神经网络
思路:借鉴LSTM,引入门控单元,将传统前向传播增加一条计算路径。
研究的成果
霸榜各大比赛仅采用ResNet结构,无额外的技巧夺得五个冠军,且与第二名拉开差距ImageNet分类、定位、检测、COCO检测、分割。
研究的意义
- 简洁高效的ResNet受到工业界宠爱,自提出以来已经成为工业界最受欢迎的卷积神经网络结构
- 近代卷积神经网络发展史的又一里程碑,突破千层网络,跳层连接成为标配
论文解读
摘要
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers—8× deeper than VGG nets [40] but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers. The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions1 , where we also won the 1stplaces on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.
摘要的核心总结:
- 提出问题:深度卷积网络难训练
- 本文方法:残差学习框架可以让深层网络更容易训练
- 本文优点:ResNet易优化,并随着层数增加精度也能提升
- 本文成果:ResNet比VGG深8倍,但是计算复杂度更低,在ILSVRC-2015获得3.57%的top-error
- 本文其它工作:CIFAR-10上训练1000层的ResNet
- 本文其它成果:在coco目标检测任务中提升28%的精度,并基于ResNet夺得ILSVRC的检测、定位COCO的检测和分割四大任务的冠军
论文的结构
- Introduction
- RelatedWork
- DeepResidual Learning
- 3.1 Residual Learning
- 3.2 Identity Mapping by Shortcuts
- 3.3 NetworkArchitectures
- 3.4lmplementation
- Experiment
- 4.1 ImageNetClassification
- 4.2CIFAR-10andAnalysis
- 4.3.Object Detection on PASCAL and MSCoCo
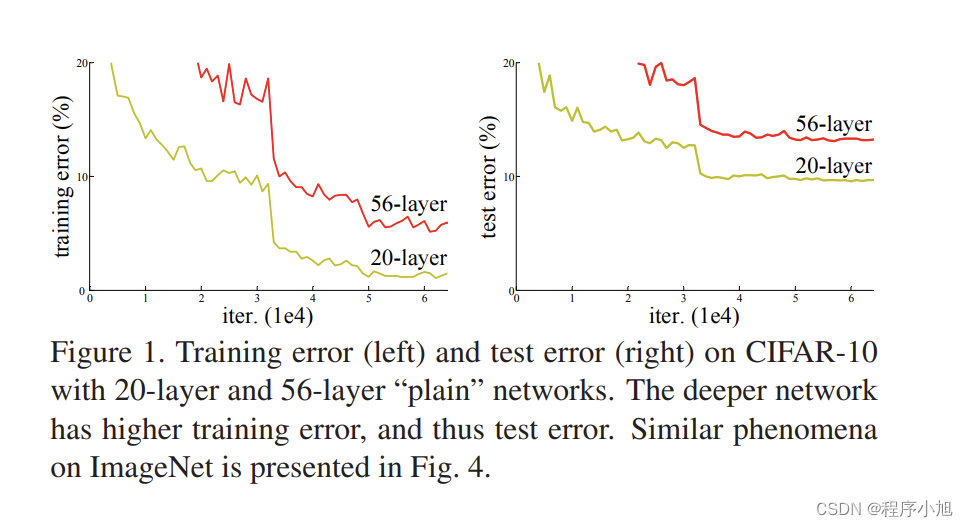
图1.CIFAR-10上对比浅层网络和深层网络的精度(plainnetwork)

核心的图示:残差学习模块的图示:
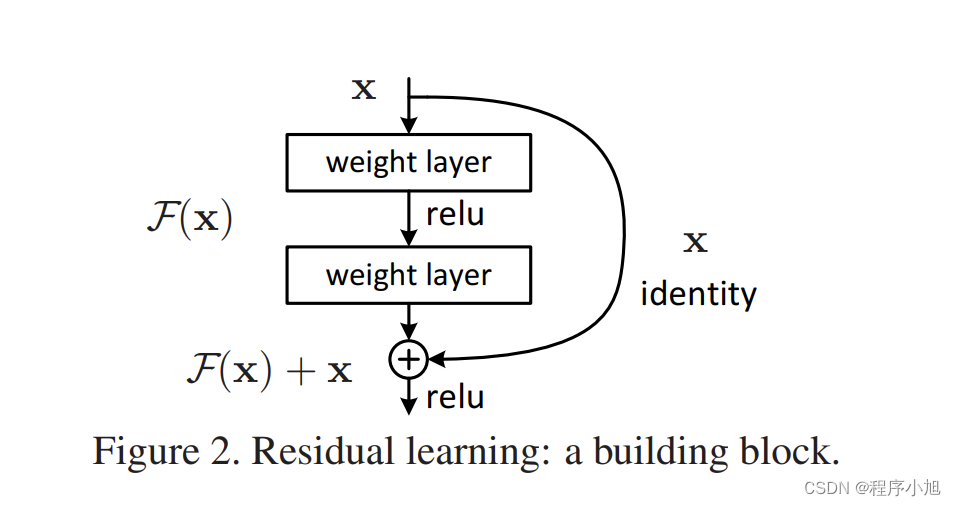
其他部分的图表在论文的解读部分在进一步的进行介绍。
残差结构
残差结构(residual learning)
首先残差学习:是指让网络层拟合H(x)-x,而非H(×)
注:整个buildingblock仍l日拟合H(x),Block_out =H(×)
而对于残差学习来说:Residual learning:Block out=H (x)=F (x)+x
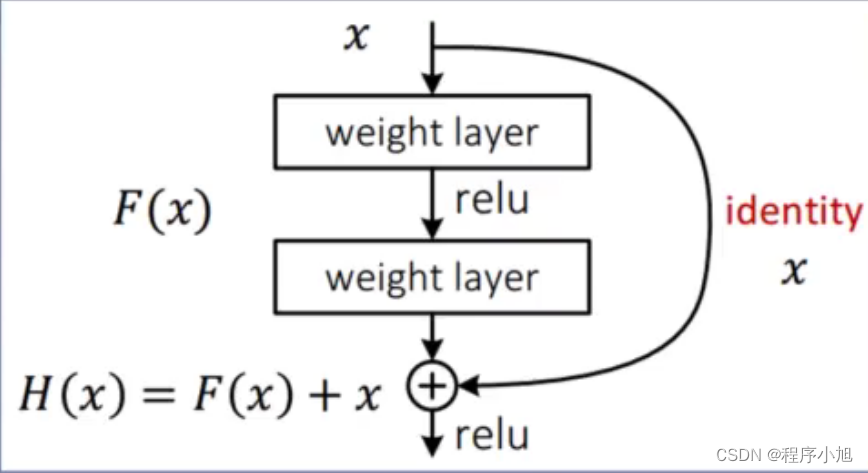
根据上面的图像提出问题:
- 为什么拟合的是F(x)
提供buildingblock更容易学到恒等映射(identity mapping)的可能
- 为什么拟合F(x)就使得buildingblock容易学到恒等映射?
当网络层的输出为0时会得到,H(x)=x的恒等映射让深层网络不至于比浅层网络差,解决了网络退化的问题(图表反映的问题)。
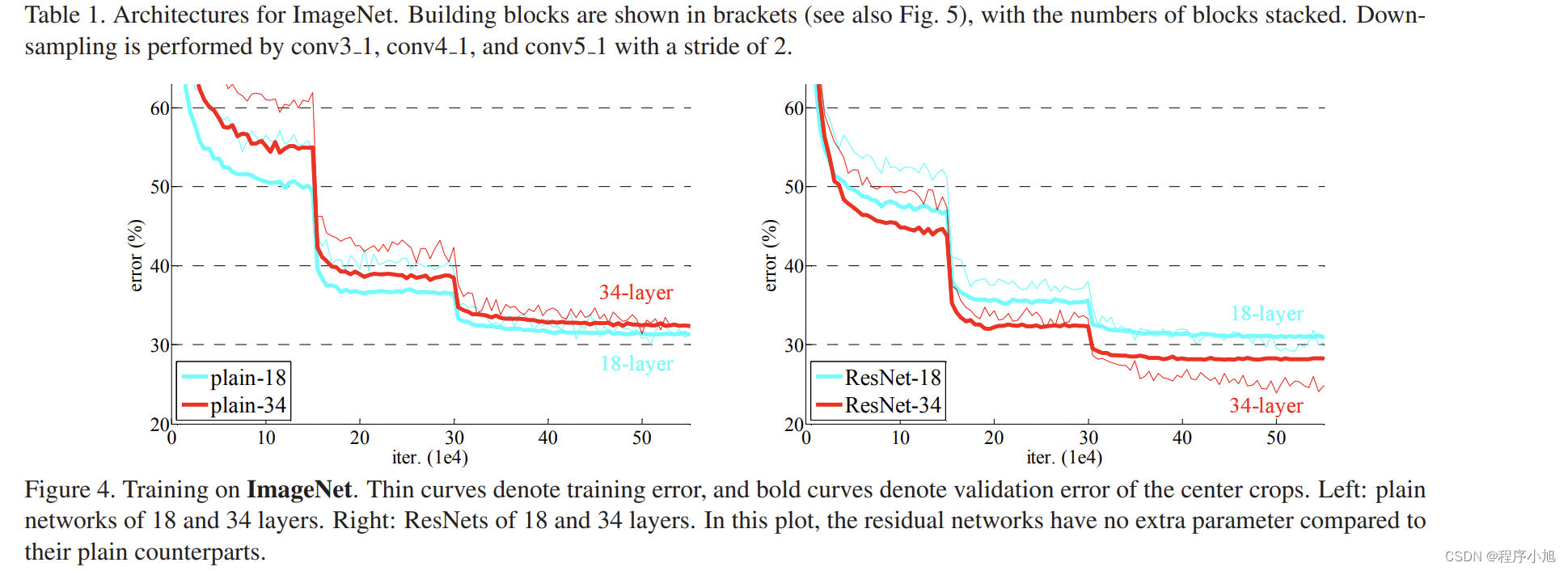
网络退化(degradation problem)
越深的网络拟合能力越强,因此越深的网络训练误差应该越低,但实际相反。
原因:并非过拟合,而是网络优化困难
在论文的原文中也给出了解答:
Unexpectedly,such degradation is not caused by overfitting, and adding more layers to a suitably deep model leads to higher training error, as reported in [10, 41] and thoroughly verified by our experiments. Fig. 1 shows a typical example.
因为网络难以优化而存在网络的退化问题,32层的网络的训练效果,并没有18层网络的训练效果更好。
之后提出的一个问题是:如何让32层的网络,可以达到18层网络的训练效果呢?
即图中的连接都为恒等映射,相当于直线时两者之间就可以等价。从而也就自然的引出了之前的残差结构与residual learning==shortcut connection的概念。
残差结构的运算过程
F ( x ) = W 2 ⋅ ReLu ( W 1 ⋅ x ) H ( x ) = F ( x ) + x = W 2 ⋅ ReLu ( W 1 ⋅ x ) + x \begin{array}{l} F(x)=W_{2} \cdot \operatorname{ReLu}\left(W_{1} \cdot \mathrm{x}\right) \\ \mathrm{H}(x)=F(x)+x=W_{2} \cdot \operatorname{ReLu}\left(W_{1} \cdot \mathrm{x}\right)+x \end{array} F(x)=W2⋅ReLu(W1⋅x)H(x)=F(x)+x=W2⋅ReLu(W1⋅x)+x
若F(x)为0,则H(x)=x,网络实现恒等映射 在X相加的过程中要满足的时维度相同的概念。(逐元素相加)
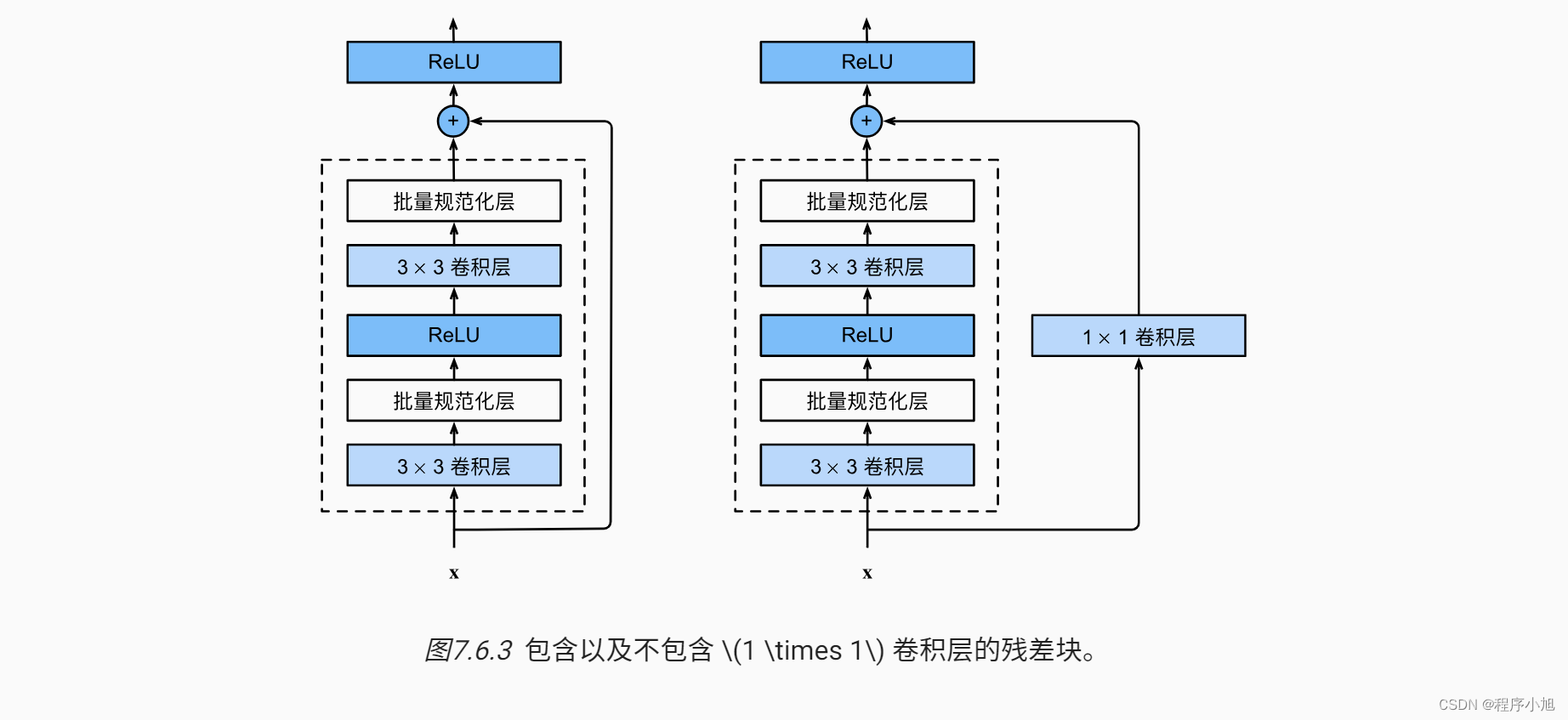
shortcut connection 特指的是残差学习的连接方式,论文中也提出了几种连接的策略
Identity与F(x)结合形式探讨:
- A-全零填充:维度增加的部分采用零来填充
- B-网络层映射:当维度发生变化时,通过网络层映射(例如:1*1卷积)特征图至相同维度
- C-所有Short cut均通过网络层映射(例如:1*1卷积)
通常使用的是策略二:在动手学深度学习的实验中使用的是策略三:
残差结构优势
说明残差结构为什么能训练上千层的网络?
Shortcut mapping有利于梯度传播(H(x)=F(x)+x)
∂ H ∂ x = ∂ F ∂ x + ∂ x ∂ x = ∂ F ∂ x + 1 \frac{\partial H}{\partial x}=\frac{\partial F}{\partial x}+\frac{\partial x}{\partial x}=\frac{\partial F}{\partial x}+1 ∂x∂H=∂x∂F+∂x∂x=∂x∂F+1
恒等映射使得梯度畅通无阻的从后向前传播这使得ResNet结构可拓展到上干层(1202层)
适合梯度的反向传播
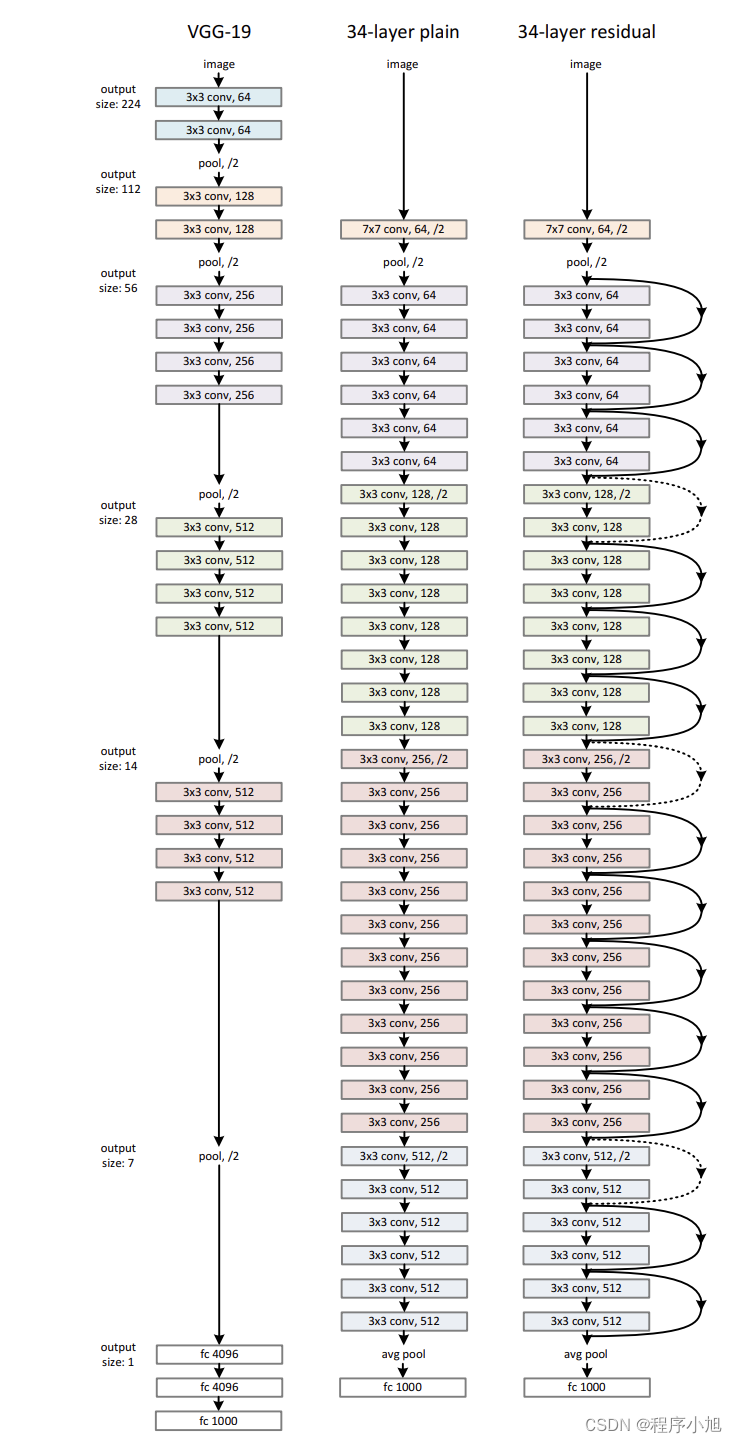
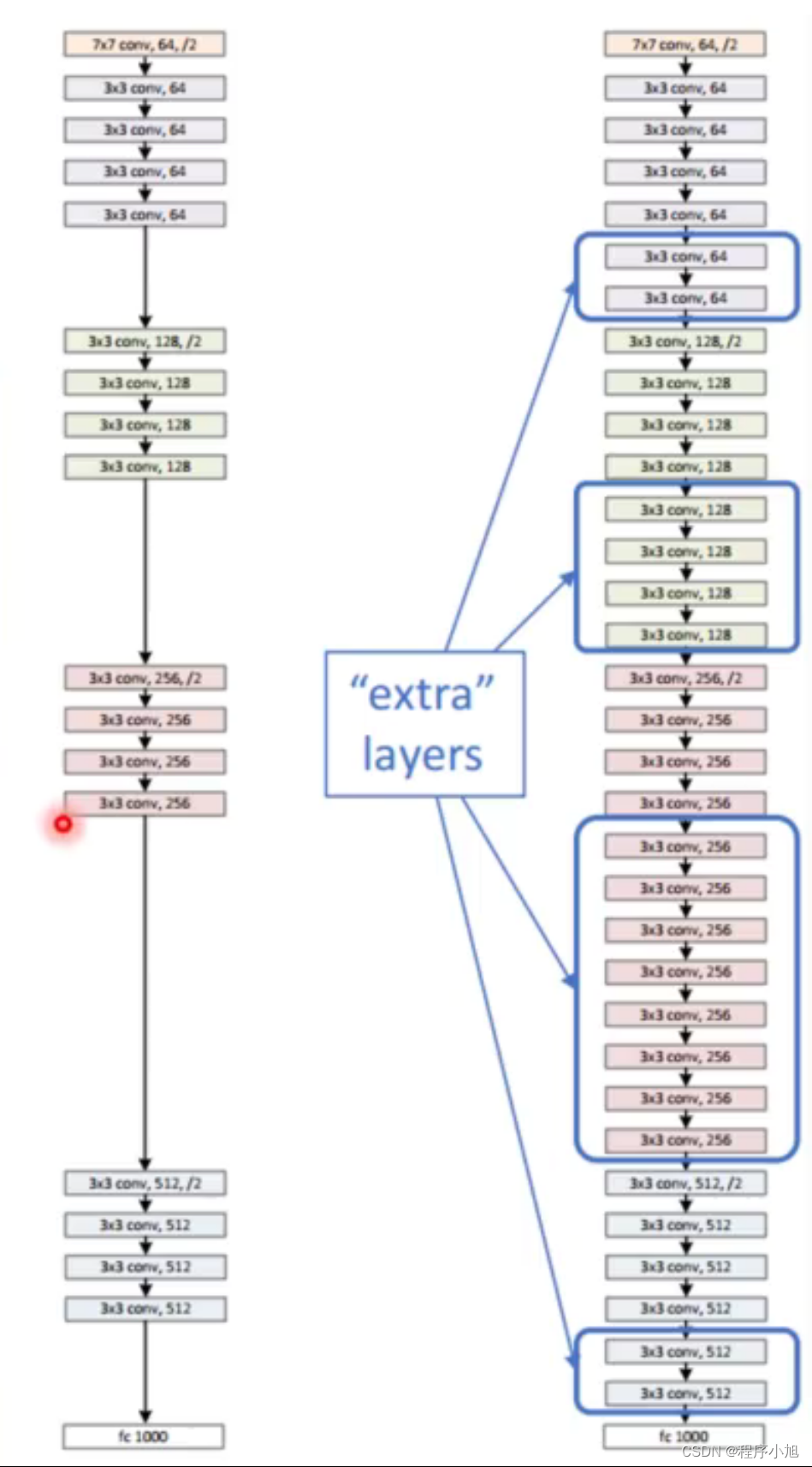
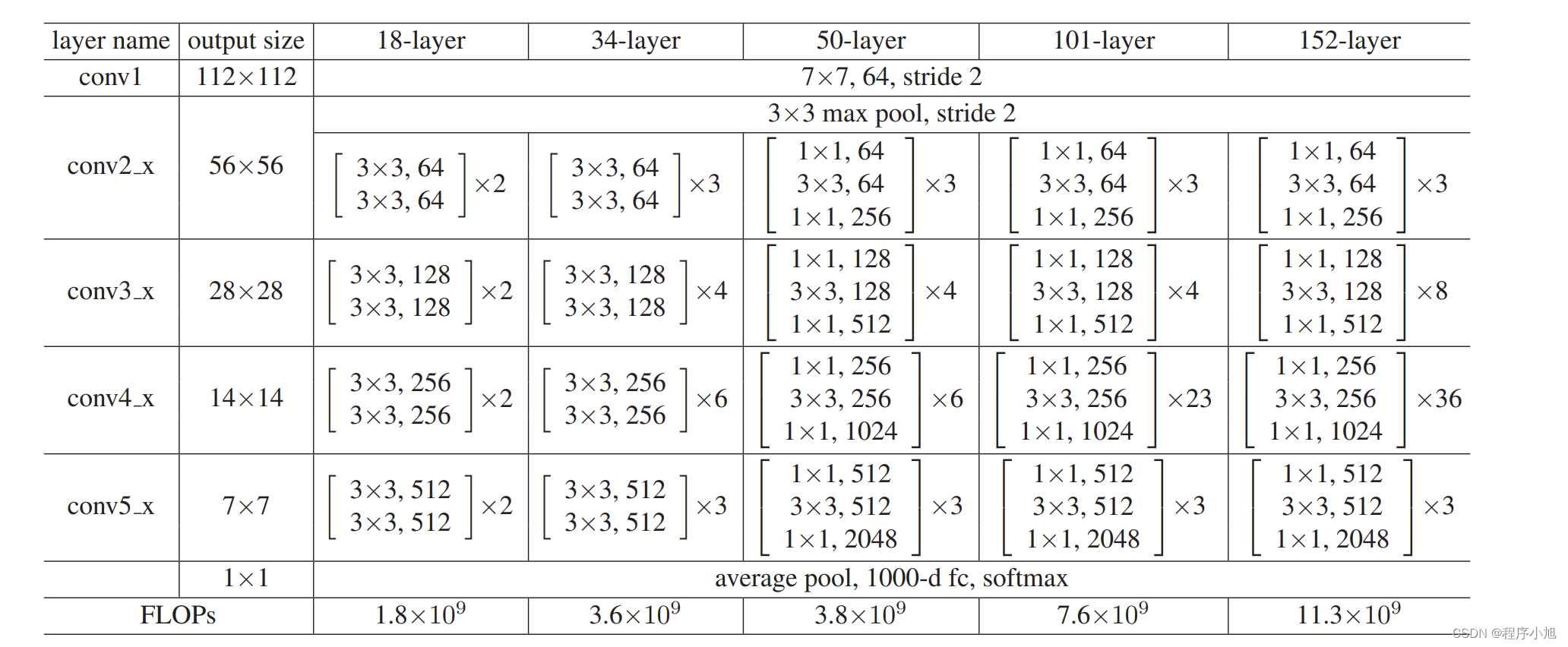
ResNet网络结构
我们对于resnet18来说,第一个网络层的步骤与之前分析的Googlenet相同,输入是224x224 x3的输入,经过7x7的卷积核,得到112x112的一个输出
F o = ⌊ F in − k + 2 p s ⌋ + 1 F_{o}=\left\lfloor\frac{F_{\text {in }}-k+2 p}{s}\right\rfloor+1 Fo=⌊sFin −k+2p⌋+1
首先进行7x7的步长为2的卷积运算(padding=3做减半运算)
=(224-7+6)/2 +1=112
第二次池化的padding=1做减半运算
=(112+2-1)/2 +1 =56
- 头部迅速降低分辨率
- 4阶段残差结构堆叠
- 池化+FC层输出
根据论文中restnet的结构,论文中也给出了两种常见的堆叠方式。如下图所示
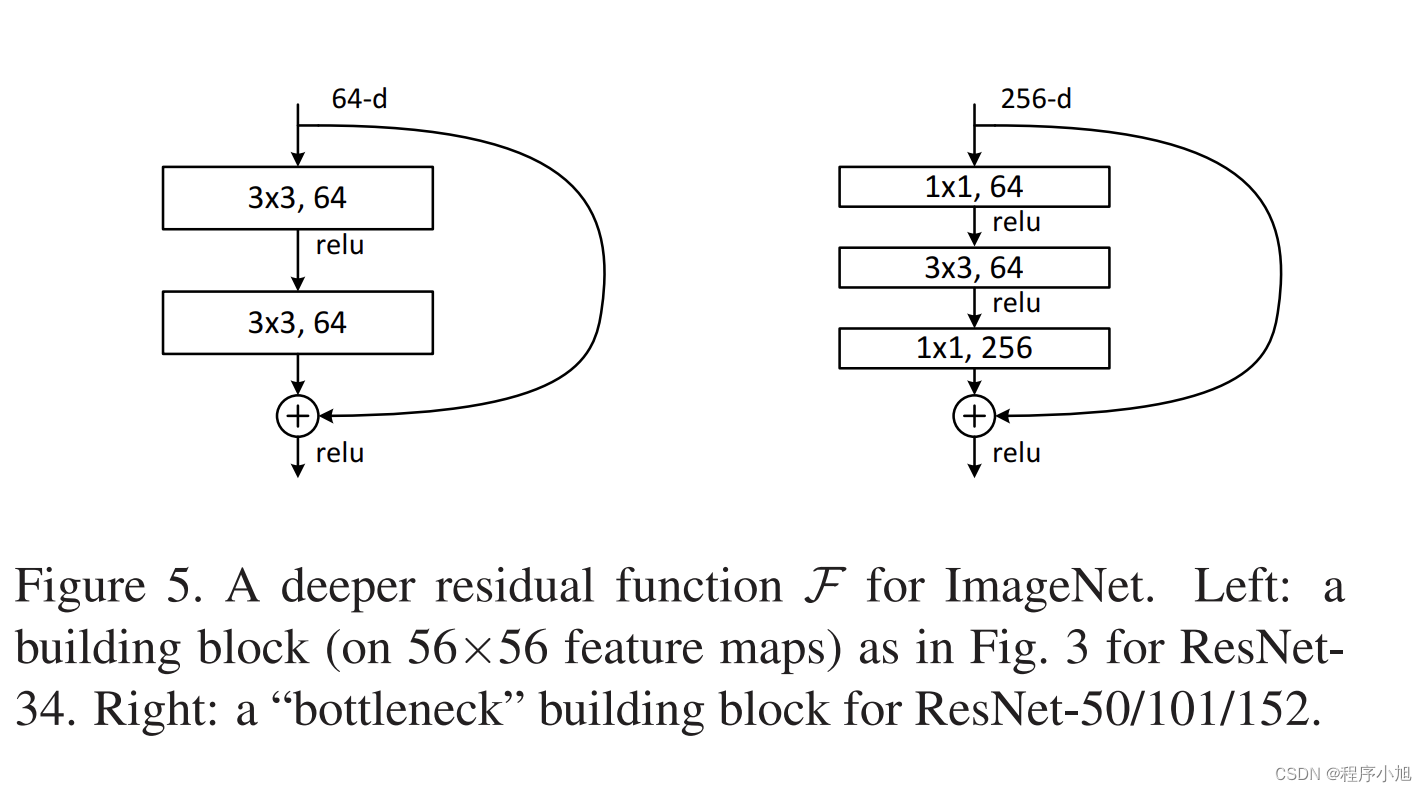
即为restnet18/34与之后的50/101/152的结构
- 第一个1*1下降1/4通道数(降低通道数减少运算)
- 第二个1*1提升4倍通道数(保证逐个元素相加)
预热训练
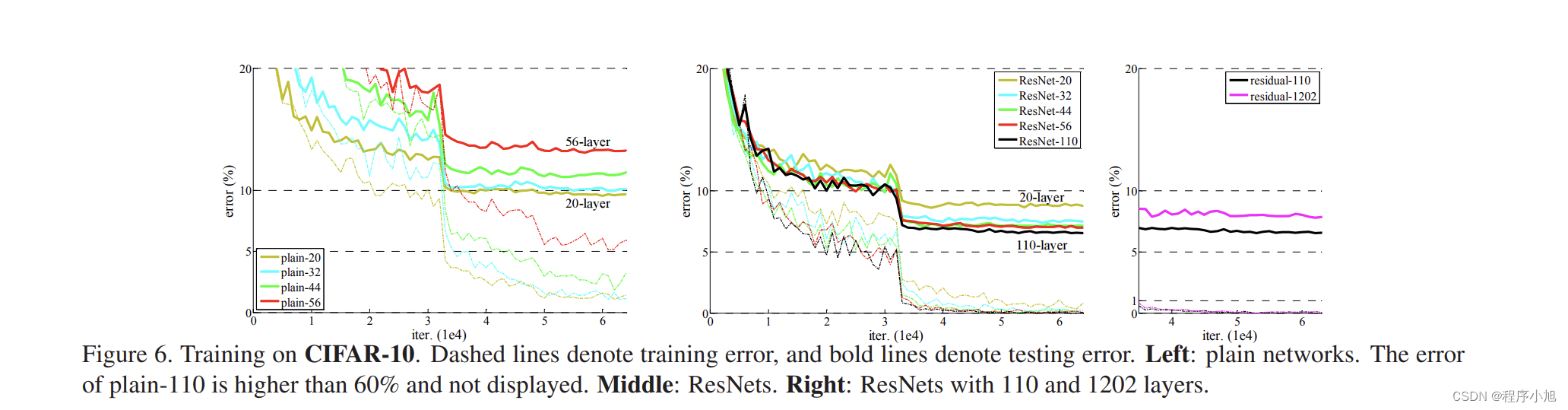
We further explore n = 18 that leads to a 110-layer
ResNet. In this case, we find that the initial learning rate
of 0.1 is slightly too large to start converging 5. So we use 0.01 to warm up the training until the training error is below80% (about 400 iterations), and then go back to 0.1 and continue training. The rest of the learning schedule is as done previously. This 110-layer network converges well (Fig. 6,middle).
避免一开始较大学习率导致模型的不稳定,因而一开始训练时用较小的学习率训练一个epochs,然后恢复正常学习率
实验结果与分析
实验1:验证residuallearning可解决网络退化问题,可训练更深网络
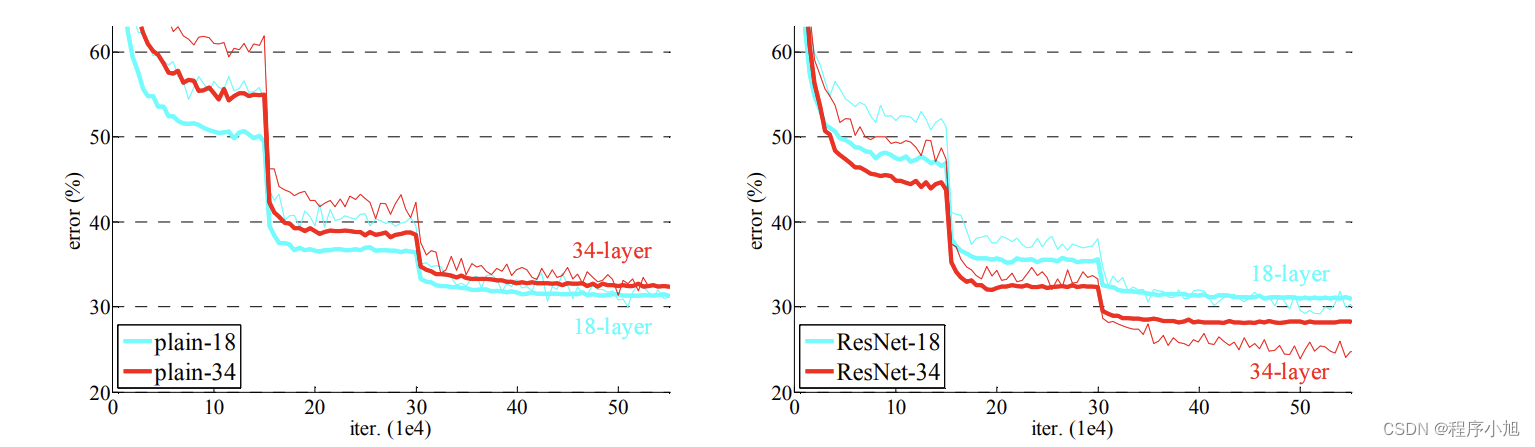
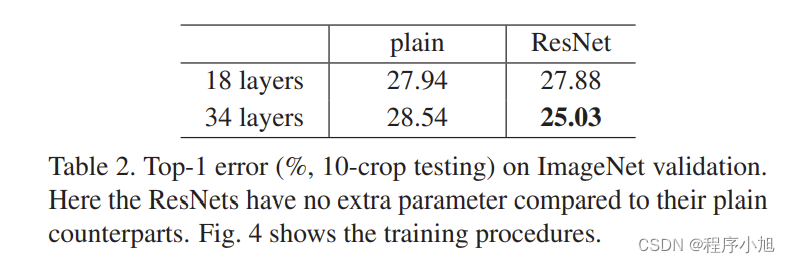
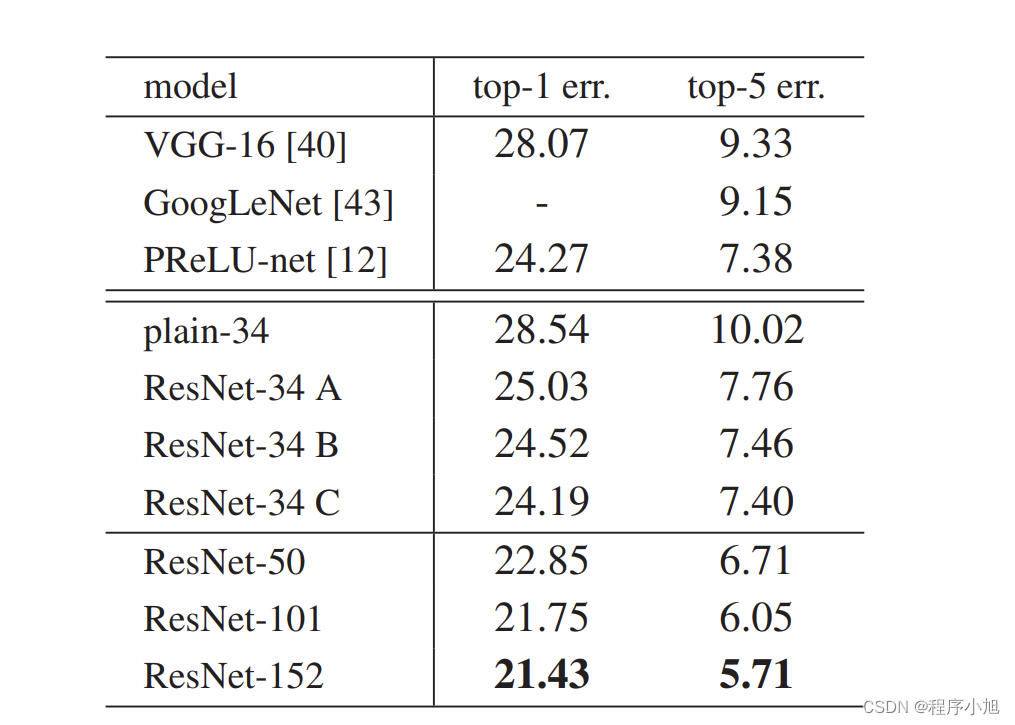
实验2:横纵对比,shortcut策略(ABC)及层数
实验3:成功训练干层神经网络Cifar-10数据集上成功训练1202层卷积网络
总结:以上就是对ResNet论文的解读,在学习完成CV的基础网络后,更应该结合论文的全文或者翻译,在日后进一步的进行学习,相信会有不同的体会。
这篇关于ResNet论文解读—Residual Learning Deep for lmage Recognition(2016)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








