resnet专题

Resnet图像识别入门——残差结构
桃树、杏树、梨树,你不让我,我不让你,都开满了花赶趟儿。红的像火,粉的像霞,白的像雪。花里带着甜味儿;闭了眼,树上仿佛已经满是桃儿、杏儿、梨儿。花下成千成百的蜜蜂嗡嗡地闹着,大小的蝴蝶飞来飞去。野花遍地是:杂样儿,有名字的,没名字的,散在草丛里,像眼睛,像星星,还眨呀眨的。 朱自清在写《春》的时候,或许也没有完全认清春天的所有花,以至于写出了“有名字的,没名字的,散在草丛中”这样的句子。

【ShuQiHere】从残差思想到 ResNet:深度学习的突破性创新
【ShuQiHere】引言 在深度学习的迅速发展中,卷积神经网络(CNN)凭借其在计算机视觉领域的出色表现,已经成为一种主流的神经网络架构。然而,随着网络层数的增加,研究人员逐渐发现了一个关键问题:梯度消失 😖 和 梯度爆炸 💥,这使得训练非常深的网络变得极其困难。为了解决这一问题,残差思想 💡 被提出,并在 2015 年由 Kaiming He 等人正式引入 ResNet 中。这一创新不

【python 走进pytotch】pytorch实现用Resnet提取特征
无意中发现了一个巨牛的人工智能教程,忍不住分享一下给大家。教程不仅是零基础,通俗易懂, 而且非常风趣幽默,像看小说一样!觉得太牛了,所以分享给大家。点这里可以跳转到教程。人工智能教程 准备一张图片,pytorch可以方便地实现用预训练的网络提取特征。 下面我们用pytorch提取图片采用预训练网络resnet50,提取图片特征。 # -*- coding: utf-8 -*-import os
【深度学习 卷积】利用ResNet-50模型实现高效GPU图片预测
本文介绍了如何使用训练好的ResNet-50模型进行图片预测。通过详细阐述模型原理、训练过程及预测步骤,帮助读者掌握基于深度学习的图片识别技术。 一、引言 近年来,深度学习技术在计算机视觉领域取得了显著成果,特别是卷积神经网络(CNN)在图像识别、分类等方面表现出色。ResNet-50作为一种经典的CNN模型,以其强大的特征提取能力和较高的预测准确率,在众多领域得到了广泛应用。本文将介绍如何使
深度学习-TensorFlow2:TensorFlow2 创建CNN神经网络模型【ResNet模型】
自定义ResNet神经网络-Tensorflow【cifar100分类数据集】 import osos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 放在 import tensorflow as tf 之前才有效import tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras

深度学习-Pytorch:Pytorch 创建CNN神经网络模型【ResNet模型】
一、自定义ResNet神经网络-Pytorch【cifar10图片分类数据集】 import torchfrom torch.utils.data import DataLoaderfrom torchvision import datasetsfrom torchvision import transformsfrom torch import nn, optimfrom torch

CV-CNN-2016:GoogleNet-V4【用ResNet模型的残差连接(Residual Connection)思想改进GoogleNet-V3的结构】
Inception V4研究了Inception模块与残差连接的结合。 ResNet结构大大地加深了网络深度,还极大地提升了训练速度,同时性能也有提升。 Inception V4主要利用残差连接(Residual Connection)来改进V3结构,得到Inception-ResNet-v1,Inception-ResNet-v2,Inception-v4网络。 ResNet的残差结构如下
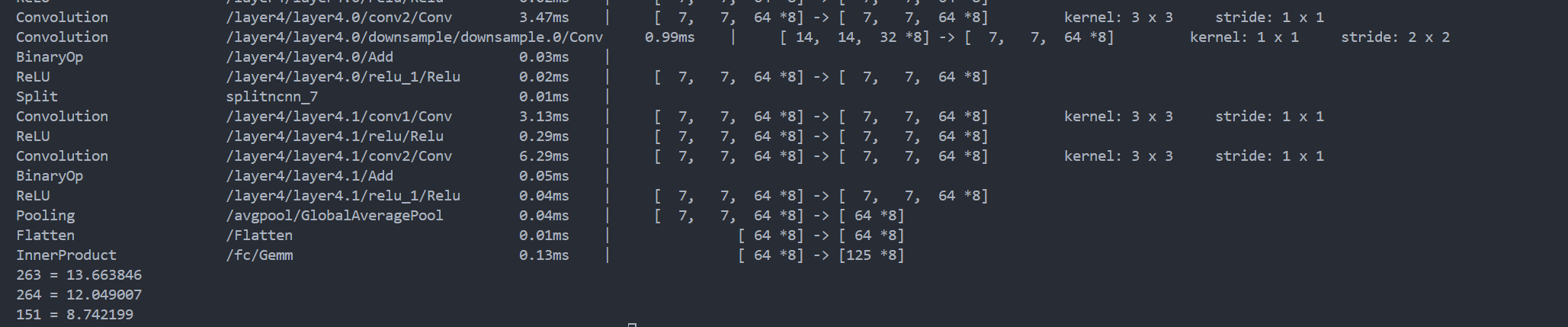
ncnn之resnet图像分类网络模型部署
文章目录 一、ONNX模型导出二、模型转换ONNX2NCNN2.1 net.param文件2.2 net.bin文件 三、ncnn模型推理四、编译与运行 一、ONNX模型导出 将 PyTorch 模型导出为 ONNX 格式,代码如下: import torchimport torchvision.models as modelsimport torch.onnx as o
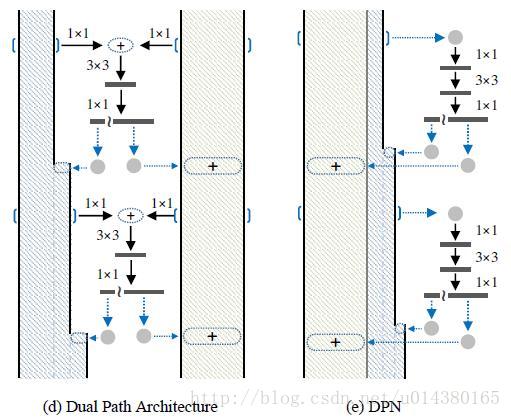
对ResNet和DenseNet的一点比较
在之前的文章中,我曾经详细的分析过DenseNet。随着时间的推移,越来越多的人开始关注DenseNet并且把它应用到实际的项目中(我从百度搜索的统计上得到这个结论 ?)。所以我决定也在应用这方面写一点。 当前卷积网络使用最广泛的两种结构是ResNet和Inception,当然还有各种衍生系列以及它俩的合体Inception-Resnet。从结构特点上,它们都是某个小结构的组合,包括DenseN


秃姐学AI系列之:残差网络 ResNet
目录 残差网络——ResNet 残差块思想 ResNet块细节 ResNet架构 总结 代码实现 残差块 两种 ResNet 块的情况 ResNet 模型 QA 由上图发现,只有当较复杂的函数类包含较小的函数类时,才能确保提高它们的性能。 对于深度神经网络,如果我们能将新添加的层训练成恒等映射(identity function)f(x)=x,新模型和原模型将同样

李沐--动手学深度学习 ResNet
1.理论 2.残差块 import torchfrom torch import nnfrom torch.nn import functional as Ffrom d2l import torch as d2l#ResNet沿用了VGG完整的3*3卷积层设计.残差块的实现如下:#此代码生成两种类型的网络:#一种是当use_1x1conv=F
ResNet 几大变体的github地址
WRN(wide residual network): github地址:https://github.com/szagoruyko/wide-residual-networks ResNeXt: github地址:https://github.com/facebook/fb.resnet.torch MobleNet: github地址: TensorFlow实
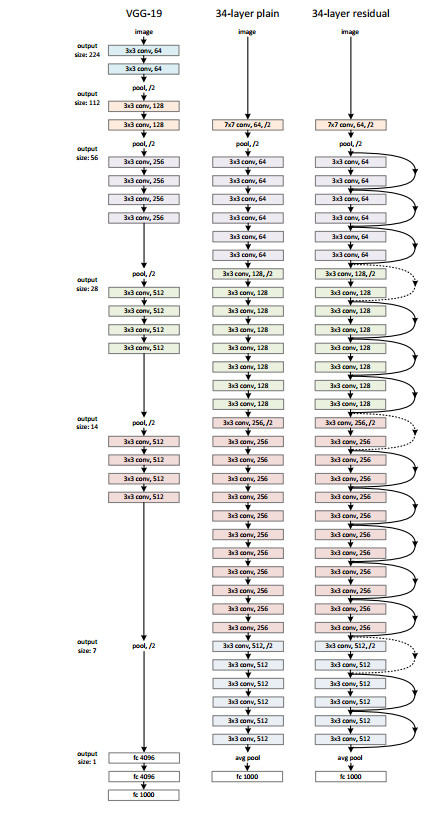
深度残差网络(ResNet)浅析
第一次写博客,欢迎大家来拍砖。 网络层数深了,会面临梯度消失的问题。深度大了为什么会出现梯度消失问题?在于假设网络的输入和输出和网络参数的分布取值大约[-1,1],为什么这样说,想想数据预处理(RGB值0-256抓化为0-1或-1到1),网络参数初始化服从高斯分布,batch normalization(把数据转化为正态分布),sigmoid function的输出范围。BP算法中链式求导的法

穿越时光的经典:从LeNet到ResNet,机器学习中的CNN架构进化史
在机器学习的浩瀚星空中,卷积神经网络(Convolutional Neural Networks, CNNs)无疑是最为耀眼的星辰之一,它们以其卓越的图像处理能力,在计算机视觉领域书写了无数辉煌篇章。从最初的简单架构到如今复杂而高效的模型,经典CNN架构的演变不仅见证了人工智能技术的飞速进步,也深刻影响了我们对图像理解方式的认知。本文将带您踏上一场从LeNet到ResNet的经典CNN架构进化

ResNet网络(三部曲_3)
文章目录 1 网络介绍2 具体应用2.1 网络搭建2.2 网络训练2.3 模型测试2.4 小玩意儿 1 网络介绍 Deep Residual Learning for Image Recognition 论文地址:https://arxiv.org/abs/1512.03385 2 具体应用 使用resnet50,进行猫狗二分类 2.1 网络搭建

ResNet网络学习
简介 Residual Network 简称 ResNet (残差网络) 下面是ResNet的网络结构: ResNet详细介绍 原理 传统方法的问题: 对于一个网络,如果简单地增加深度,就会导致 梯度消失 或 梯度爆炸,我们采取的解决方法是 正则化。随着网络层数进一步增加,又会出现模型退化问题,在训练集上的 准确率出现饱和甚至下降 的现象 ; 因此提出了通过利用内部的残差块实现跳跃连

深度学习----------------------残差网络ResNet
目录 ResNet加更多的层总是改进精度吗?残差块ResNet块细节不同的残差块ResNet块ResNet架构总结 ResNet代码实现残差块输入和输出形状一致增加输出通道数的同时,减半输出的高和宽ResNet模型观察ResNet中不同模块的输入形状是如何变化的训练模型 问题ResNet为什么能训练出1000层的模型?ResNet是这样解决的 问题 ResNet
PyTorch下的5种不同神经网络-ResNet
1.导入模块 导入所需的Python库,包括图像处理、深度学习模型和数据加载 import osimport torchimport torch.nn as nnimport torch.optim as optimfrom torch.utils.data import Dataset, DataLoaderfrom PIL import Imagefrom torchvision impo

如何快速高效的训练ResNet,各种奇技淫巧(八):一大波技巧
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 作者:David Page 编译:ronghuaiyang 导读 这个系列介绍了如何在CIFAR10上高效的训练ResNet,这是第八篇,给大家总结了一大波的技巧,这些技巧同样可以用到提升准确率上。 在本系列的最后一篇文章中,我们绕了一圈,加快了我们的单gpu训练,与多gpu竞争。我们推出了一系列标准和不太标准的技巧,通过增

如何快速高效的训练ResNet,各种奇技淫巧(六):权值衰减
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 作者:David Page 编译:ronghuaiyang 导读 这个系列介绍了如何在CIFAR10上高效的训练ResNet,这是第六篇,给大家讲解权值衰减的相关内容以及训练中的各种动态。 我们了解到更多的关于权值衰减对训练的影响,并发现了一个与LARS之间意想不到的关系。 其中我们更深入地研究了学习率的动态 读者可能在这
如何快速高效的训练ResNet,各种奇技淫巧(五):超参数
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 作者:David Page 编译:ronghuaiyang 导读 这个系列介绍了如何在CIFAR10上高效的训练ResNet,这是第五篇,给大家讲解超参数的相关内容。 我们开发了一些超参数调优启发式算法。 关于超参数调优以及如何避免它 人们普遍认为神经网络的超参数选择是困难的。如果有人赞同这一观点,就会出现两种不同的行动方针
如何快速高效的训练ResNet,各种奇技淫巧(四):网络结构
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 作者:Ayoosh Kathuria 编译:ronghuaiyang 导读 这个系列介绍了如何在CIFAR10上高效的训练ResNet,到第4篇文章为止,我们使用单个V100的GPU,可以在79s内训练得到94%的准确率。里面有各种各样的trick和相关的解释,非常好。 我们寻找更有效的网络架构,并找到一个9层网络,训练时间
如何快速高效的训练ResNet,各种奇技淫巧(三):正则化
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 作者:David Page 编译:ronghuaiyang 导读 这个系列介绍了如何在CIFAR10上高效的训练ResNet,到第4篇文章为止,我们使用单个V100的GPU,可以在79s内训练得到94%的准确率。里面有各种各样的trick和相关的解释,非常好。 我们发现了一个性能瓶颈,并增加了正则化,从而将训练时间进一步缩
如何快速高效的训练ResNet,各种奇技淫巧(二):Mini-batch
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 作者:Ayoosh Kathuria 编译:ronghuaiyang 导读 这个系列介绍了如何在CIFAR10上高效的训练ResNet,到第4篇文章为止,我们使用单个V100的GPU,可以在79s内训练得到94%的准确率。里面有各种各样的trick和相关的解释,非常好。 我们研究了mini-batch对训练的影响,并使用更大
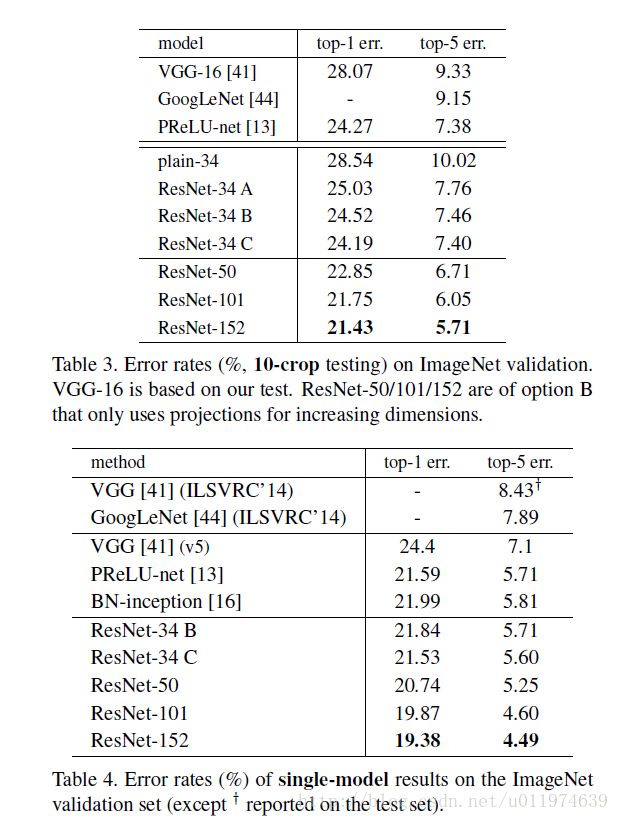
TensorFlow实战:Chapter-6(CNN-4-经典卷积神经网络(ResNet))
ResNet ResNet简介相关内容论文分析 问题引出解决办法实现residual mapping实验实验结果 ResNet在TensorFlow上的实现 ResNet ResNet简介 ResNet(Residual Neural Network)由微软研究院的何凯明大神等4人提出,ResNet通过使用Residual Unit成功训练152层神经网络,在ILSCRC20