本文主要是介绍如何快速高效的训练ResNet,各种奇技淫巧(二):Mini-batch,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:Ayoosh Kathuria
编译:ronghuaiyang
导读
这个系列介绍了如何在CIFAR10上高效的训练ResNet,到第4篇文章为止,我们使用单个V100的GPU,可以在79s内训练得到94%的准确率。里面有各种各样的trick和相关的解释,非常好。
我们研究了mini-batch对训练的影响,并使用更大的minibatch来减少训练时间到256秒。
这里,我们研究了minibatch的大小,并了解到我们在训练的时候会出现遗忘的问题。
上次结束时,我们继承了在DAWNBench上CIFAR10最快的单GPU方案,18层ResNet和学习率策略。训练到94%的测试精度需要341秒,通过对网络和数据加载的一些小的调整,我们将时间降低到297秒。
到目前为止,我们的训练使用的batch大小为128。较大的batch应该计算更高效,所以让我们看看如果将批大小增加到512会发生什么。如果我们要和前面的设置接近,我们需要确保适当地调整学习率和其他超参数。
使用minibatch的SGD类似于一次只训练一个样本,区别在于,参数在每个minibatch的最后才更新。可以认为,只要对minibatch的梯度是求和而不是平均,在低学习率的限制下,这种延迟是一种高阶效应,而且批处理不会对第一阶有任何的改变。在每个batch之后,我们还做了权值衰减,这种衰减会随着batch size的增加而增加,以弥补减少的batch数量带来的效果。如果在minibatch上对梯度求平均,那么应该调整学习率,以消除这种效应以及权值衰减带来的影响,因为我们的权值衰减的更新时包含了学习率的因子。
因此,不再赘述,让我们使用batch size为512进行训练。训练在256秒内完成,只需对学习率稍加调整—提高10%—我们就能够匹配batch size 128,并且3/5的运行中的训练可以达到94%的测试精度。在batch size为512的训练过程中,由于batch norm的影响,预计会出现更嘈杂的验证结果,在后面的文章中会详细介绍这一点。如果稍加注意,可能还会用更大的batch,但目前我们只使用512。
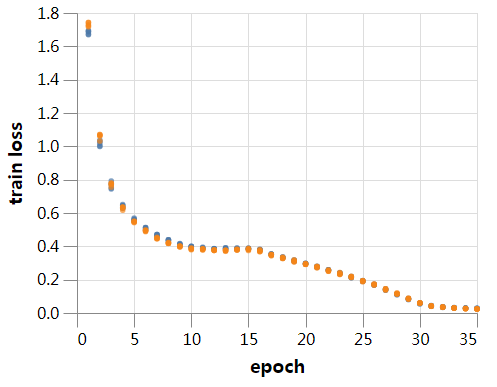
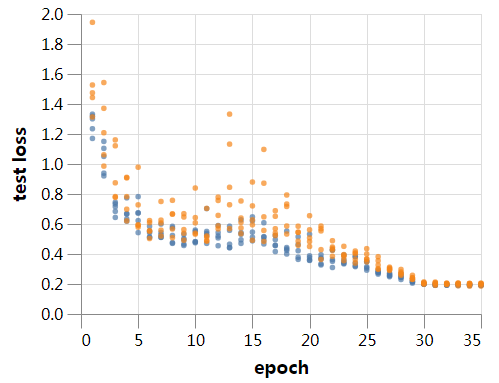
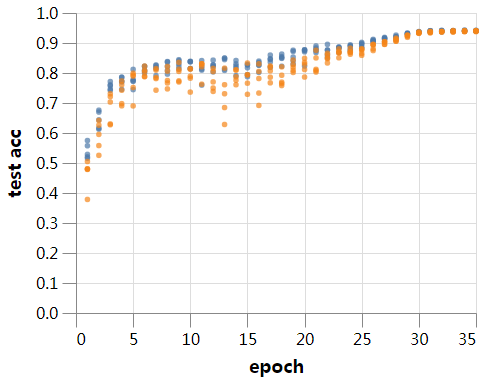
现在速度是很好,但是这个结果让我很惊讶。
我们关于不同mini-batch的大小的训练的等价性的讨论,至少在两个方面是幼稚的。首先,我们认为将更新延迟到一个minibatch最后有一个更高阶的效果,并且在小学习率的限制下应该没有问题。目前根本不清楚这一限制是否适用。确实,当前的快速的训练速度在很大程度上来自于大学习率的使用。在凸优化的上下文中(或者仅仅是对二次曲线的梯度下降),通过在二阶效果开始与一阶效果发生平衡的点上设置学习率来达到最大的训练速度,而且增加一阶的步伐任何好处都被曲率效应抵消了。假设我们在这种情况下,来自minibatch的延迟更新应该与相应的学习率增加产生相同的曲率惩罚,并且训练应该变得不稳定。简而言之,如果忽略了高阶效应,你的训练速度就不够快。
该论点的第二个问题是,它应用于单个训练步骤,但实际上,训练是一个长期运行的过程,至少要持续O(1/学习率)个步骤,以便O对参数进行O(1)的修改。因此,小batch训练和大batch训练之间的二阶差异可能会随着时间的推移而累积,并导致训练轨迹的显著差异。我们将在稍后的文章中重新讨论这一点,那时我们已经对长时间动态训练有了更多的了解,但是现在我们只关注第一个。
那么,我们如何能够同时处于训练的速度极限,并且能够在不受曲率影响的情况下增加batch size呢?答案可能是,其他因素限制了可达到的学习率,而我们并不处于曲率效应占主导地位的状态。我们会说,这是另一种叫做“灾难性遗忘”的现象,它限制了小batch size时候的学习率,而不是损失的曲率。
首先我们应该解释一下我们的意思。通常,这个术语适用于这样一种情况:一个模型被训练在一个任务上,然后另一个或多个任务上训练在。学习较晚的任务会导致较早任务的性能下降,有时这种影响是灾难性的。在我们的例子中,所讨论的任务是同一训练集的不同部分,当学习率足够高时,遗忘可以在一个epoch内发生。学习率越大,在单个训练周期中移动的参数就越多,在某种程度上,这一定会损害模型从整个数据集中吸收信息的能力。较早的batch将被有效地遗忘。
我们已经看到了我们主张的第一个证据:batch size的增加不会立即导致训练的不稳定性,如果曲率是问题所在,就应该是这样,但是如果问题是遗忘,则会立即导致训练的不稳定,而健遗忘在很大程度上应该不受batch size大小的影响。
接下来,我们做了一个实验来从遗忘中分离曲率的影响,曲率主要取决于学习率,而遗忘,共同取决于学习速度和数据集的大小。当我们使用不同大小的训练集的子集进行训练时,我们将最终的训练和测试损失绘制在batch size为128的位置。我们使用原始的学习率策略,根据1/8到16之间的一系列因素重新调整。
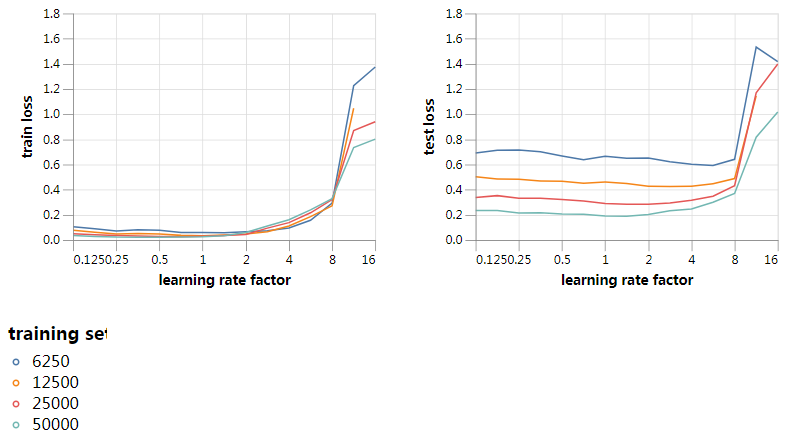
我们可以在图中看到很多有趣的东西。首先,在不依赖于训练集大小的情况下,以相似的学习率(大约是原始学习速率的8倍),训练和测试损失都会突然变得不稳定。这是一个强烈的迹象,曲率效应在这一点变得很重要。反之,在很大范围内,在原学习率周围(图中学习率因子=1)训练和测试损失是稳定的。
最优的学习率因子(通过测试集损失来测量)对于完整的训练数据集来说接近于1,因为这是手工优化的,所以这是预期的。对于较小的数据集,最优学习率因子更高,对于最小的数据集(6250),最优学习率因子接近于曲率影响训练不稳定的点。这与我们上面的假设是一致的:对于一个足够小的数据集,遗忘不再是一个问题,学习率应该被推到接近曲率允许的极限。对于较大的数据集,由于遗忘效应,学习率可以相比最佳点显著降低。
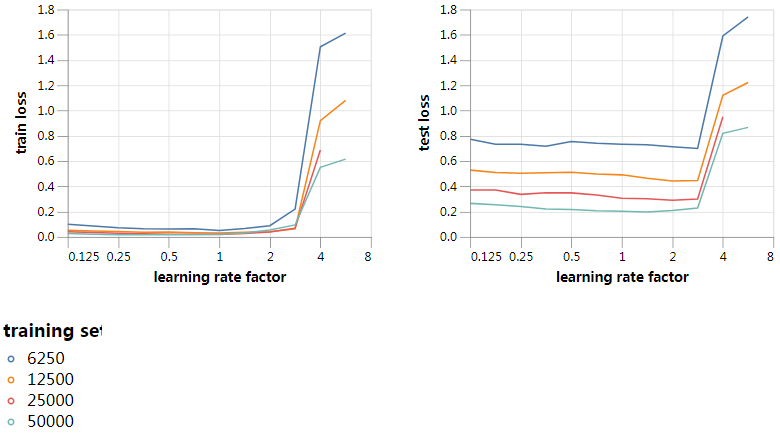
绘制batch size为512的结果也很有趣。由于在这个batch size上比原来大了4倍,我们可能会期望8倍的学习率,但我们会发现自己更接近曲率不稳定性,它应该设置在大约2倍而不是8倍。由于遗忘速度不受batch size的影响,曲率效应尚未在最优值上占主导地位,因此我们还期望学习率因子和损失的最优值与batch size为128时的最优值相似。结果正如我们所希望的:
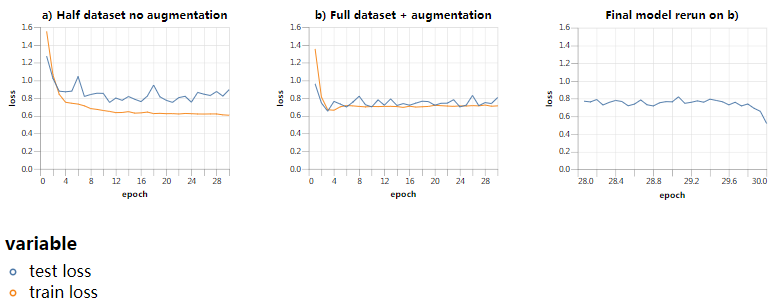
通过下面的实验,我们可以直接观察遗忘的效果。我们将batch size设置为128,并使用一个学习率策略进行训练,该策略在前5个周期内线性增长,然后在接下来的25个周期内以固定的最大速率保持不变,从而使训练和测试损失在给定的学习率下稳定下来。我们比较了两个不同数据集上的训练运行情况:a)没有数据增强的完整训练集的50%,b)使用标准增强的完整数据集。然后,我们冻结运行b)的最终模型,并重新计算刚刚完成的训练在过去几个阶段中的损失。用这种方法重新计算损失的想法是比较最近看到的batch和很久以前看到的batch上模型的损失,以测试模型的记忆能力。
以下是最高学习率4倍高于原始训练设置的结果:
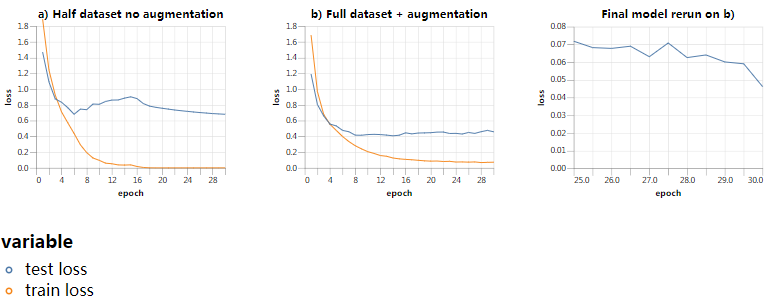
最大学习率比原训练低4倍的结果如下:
从这些结果中,有几件事很明显。集中在前三个图上,我们可以看到,当模型对50%没有增强的数据集或全部有增强的数据集进行训练时,测试损失几乎是相同的,这与较高的学习率相对应。这意味着训练不能从完整的数据集中提取信息,并且50%的未增强数据集已经包含了(几乎)模型在这种情况下能够学习的所有信息。最右边的图显示了为什么会这样。最近看到的训练batch的损失明显低于较老的batch,但是损失在半个训练周期内恢复到未看到的样本试集的水平。这是一个明显的证据,表明该模型正在忘记它在同一训练时期之前所看到的东西,这限制了它在这个学习率下能够吸收的信息量。
第二行显示了低学习率的对比。完整的(增强的)数据集导致了较低的测试损失,并且最近看到的batch在过去许多时期的性能优于随机batch(请注意x轴上两行的最终图的不同比例)。
讨论
上述结果表明,如果想要训练一个高学习率的神经网络,那么有两种方法可以考虑。对于当前模型和数据集,用batch size为128时我们安全地使得遗忘占据主导地位,而我们应该考虑别的方法来减少这种(例如使用(更大的模型与稀疏更新或者自然梯度下降法)效应,或者我们应该增大batch size的大小。在batch size为512时,我们进入了曲率效应占主导地位的状态,重点应该转移到减轻这中影响。
对于较大的数据集,如ImageNet-1K,它包含大约20倍的CIFAR10的训练样本,遗忘的影响可能要严重得多。这就解释了为什么在此数据集中以非常高的学习率提高minibatch的训练速度的尝试失败了,而跨多台机器的batch size为8000的训练或更多的尝试成功了。在非常大的batch size下,曲率效应再次占据主导,因此在ImageNet的大batch size训练和CIFAR10的快速单GPU训练中使用的技术存在大量重叠。
在第3部分中,我们加快了batch norm的速度,添加了一些正则化,并超越了另一个基准。

—END—
英文原文:https://myrtle.ai/how-to-train-your-resnet-2-mini-batches/

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!![]()
这篇关于如何快速高效的训练ResNet,各种奇技淫巧(二):Mini-batch的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


