batch专题
简单的spring batch学习
前言 公司批量任务是数据库执行的,想修改成java执行批量任务,所以简单了解了下springbatch批量任务框架,此处是其学习笔记,具体学习视频地址为bilibili springbatch,以下为其学习笔记内容以及源码信息 一、课程目标 课程目标 系统了解Spring Batch批处理 项目中能熟练使用Spring Batch批处理 课程内容 前置知识 Java基础

选取训练神经网络时的Batch size ,BatchNorm
BatchNorm 优点:对于隐藏层的每一层输入,因为经过激活函数的处理,可能会趋向于大的正值和负值,容易出现梯度下降和梯度消失。所以强行拉回到服从均值为0,方差为1的标准正态分布,避免过拟合 缺点:正是因为这种强行改变分布的手段,使得隐层输入和原始数据分布差异太大,如果数据量不大时,容易欠拟合。可能不用更好一些 https://www.zhihu.com/search?type=conte

《Efficient Batch Processing for Multiple Keyword Queries on Graph Data》——论文笔记
ABSTRACT 目前的关键词查询只关注单个查询。对于查询系统来说,短时间内会接受大批量的关键词查询,往往不同查询包含相同的关键词。 因此本文研究图数据多关键词查询的批处理。为多查询和单个查询找到最优查询计划都是非常复杂的。我们首先提出两个启发式的方法使关键词的重叠最大并优先处理规模小的关键词。然后设计了一个同时考虑了数据统计信息和搜索语义的基于cardinality的成本估计模型。 1.

如何处理批次效应(batch effect)
1、如何处理批次效应(batch effect) https://www.plob.org/article/14410.html 2、基于多数据集分析ANLN在宫颈癌所起到的功能 https://www.omicsclass.com/article/769

神经网络训练不起来怎么办(五)| Batch Normalization
Ⅰ,领域背景 训练困境:当 input feature 在不同 dimension 上差距很大的时候,会产生一个非常崎岖的 error surface(误差平面)。这种崎岖多变的误差平面容易导致训练陷入以下的几个困境。 收敛困难:在崎岖的误差表面上,梯度下降等优化算法很容易陷入局部最小值或者鞍点,并且很难继续优化。这会导致模型无法收敛到全局最优解,训练过程变得非常困难。训练速度变慢:由于优化算
基于Python的机器学习系列(20):Mini-Batch K均值聚类
简介 K均值聚类(K-Means Clustering)是一种经典的无监督学习算法,但在处理大规模数据集时,计算成本较高。为了解决这一问题,Mini-Batch K均值聚类应运而生。Mini-Batch K均值聚类通过使用数据的子集(mini-batch)来更新簇中心,从而减少了计算量,加快了处理速度。 Mini-Batch K均值算法 Mini-Batch

CV-CNN-2015:GoogleNet-V2【首次提出Batch Norm方法:每次先对input数据进行归一化,再送入下层神经网络输入层(解决了协方差偏移问题)】【小的卷积核代替掉大的卷积核】
GoogLeNet凭借其优秀的表现,得到了很多研究人员的学习和使用,因此GoogLeNet团队又对其进行了进一步地发掘改进,产生了升级版本的GoogLeNet。 GoogLeNet设计的初衷就是要又准又快,而如果只是单纯的堆叠网络虽然可以提高准确率,但是会导致计算效率有明显的下降,所以如何在不增加过多计算量的同时提高网络的表达能力就成为了一个问题。 Inception V2版本的解决方案就是修

PyTorch数据加载:自定义数据集【Dataset:处理每个原始样本】【DataLoader:每次生成batch_size个样本】【collate_fn:重新设置一个Batch中所有样本的加载格式】
一、自定义Dataset Dataset是一个包装类: 用来将数据包装为Dataset类,然后传入DataLoader中,我们再使用DataLoader这个类来更加快捷的对数据进行操作。可以通过继承Dataset来将数据集的源文件、规模和其他非必要的功能打包,从而供DataLoader使用。 1、“文本分类”任务下使用自定义Dataset class.txt:所有类别 finance
GPU有限,如何提高batch size
那么从: https://github.com/mathildor/DeepLab-v3/blob/master/g3doc/faq.md deeplabv3+也是谷歌团队,tensorflow就是他们的产品。可以看到提高batch size 的方法。 batchsize不仅对于batch normalization至关重要,而且梯度下降也需要一定的batchsize,比如batchsize
tf.train.batch 和 tf.train.batch_join的区别
先看两个函数的官方文档说明 tf.train.batch官方文档地址: https://www.tensorflow.org/api_docs/python/tf/train/batch tf.train.batch_join官方文档地址: https://www.tensorflow.org/api_docs/python/tf/train/batch_join tf.train.ba
OutOfRangeError PaddingFIFOQueue '_1_get_batch/batch/padding_fifo_queue 解决方案
最近使用Faster-RCNN训练模型时,遇到了如标题所示的问题,最终得到解决,现在记录解决方式如下: 一般这种问题都不是代码的问题,请先检查训练数据: 1. 训练数据中图像文件和标注文件数量是否相同 2. 训练数据中是否有损坏的图片(数量多的话可以用PIL写个简单的加载方法去判断) 3. 标注文件中标注的长宽与实际长宽是否相同(我的问题在这里得到了解决,下面列出检测的代码): from

IDEA创建MAVEN项目卡在Generating project in Batch mode以及解决 No archetype found in remote catalog警告问题
解决步骤 1.本地仓库要有archetype-catalog-3.1.2.jar 的jar包 注意:本地仓库jar包的获取可以通过修改settings.xml文件中的mirror从阿里云中加载 网上教程很多 就不赘述了。但是如果修改了setting.xml文件,记得在本地仓库下载完成后将其修改还原。 2.要有archetype-catalog.xml 文件 这个文件的下载,因为被墙的原因下载
关于Mybatis的Batch模式性能测试及结论
近日在公司项目中,使用到spring+mybatis的架构,特对mybatis的batch模式做了相关研究,得出以下结论: 1.Mybatis内置的ExecutorType有3种,默认的是simple,该模式下它为每个语句的执行创建一个新的预处理语句,单条提交sql;而batch模式重复使用已经预处理的语句, 并且批量执行所有更新语句,显然batch性能将更优; 2.但batch模

tf.train.batch和tf.train.shuffle_batch的理解
capacity是队列的长度 min_after_dequeue是出队后,队列至少剩下min_after_dequeue个数据 假设现在有个test.tfrecord文件,里面按从小到大顺序存放整数0~100 1. tf.train.batch是按顺序读取数据,队列中的数据始终是一个有序的队列, 比如队列的capacity=20,开始队列内容为0,1,..,19=>读取10条记录后,队列剩下10,

如何快速高效的训练ResNet,各种奇技淫巧(二):Mini-batch
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 作者:Ayoosh Kathuria 编译:ronghuaiyang 导读 这个系列介绍了如何在CIFAR10上高效的训练ResNet,到第4篇文章为止,我们使用单个V100的GPU,可以在79s内训练得到94%的准确率。里面有各种各样的trick和相关的解释,非常好。 我们研究了mini-batch对训练的影响,并使用更大
Scaling SGD Batch Size to 32K for ImageNet Training
为了充分利用GPU计算,加快训练速度,通常采取的方法是增大batch size.然而增大batch size的同时,又要保证精度不下降,目前的state of the art 方法是等比例与batch size增加学习率,并采Sqrt Scaling Rule,Linear Scaling Rule,Warmup Schem等策略来更新学来率. 在训练过程中,通过控制学习率,便可以在训练的时候采

深度学习训练——batch_size参数设置过大反而训练更耗时的原因分析
💪 专业从事且热爱图像处理,图像处理专栏更新如下👇: 📝《图像去噪》 📝《超分辨率重建》 📝《语义分割》 📝《风格迁移》 📝《目标检测》 📝《暗光增强》 📝《模型优化》 📝《模型实战部署》 在深度学习训练过程中,batch_size 对训练时间的影响并不是线性的,有时增大 batch_size 反而会导致训练时间变长。 目录 一、例子1.1 较大batch_s
caffe中BatchNorm层和Scale层实现批量归一化(batch-normalization)注意事项
caffe中实现批量归一化(batch-normalization)需要借助两个层:BatchNorm 和 Scale BatchNorm实现的是归一化 Scale实现的是平移和缩放 在实现的时候要注意的是由于Scale需要实现平移功能,所以要把bias_term项设为true 另外,实现BatchNorm的时候需要注意一下参数use_global_stats,在训练的时候设为false,
2019.04.09日记,springboot多源数据库合并,新知识点=spring batch,以及一次git的代码找回
spring boot 上可以配置多源数据库,因此我们可以在application.properties上这么配置 #数据库aspring.datasource.type=com.alibaba.druid.pool.DruidDataSourcespring.datasource.driverClassName=com.mysql.jdbc.Driverspring.datasource

小知识点快速总结:Batch Normalization Layer(BN层)的作用
本系列文章只做简要总结,不详细说明原理和公式。 目录 1. 参考文章2. 主要作用3. 具体分析3.1 正则化,降低过拟合3.2 提高模型收敛速度,加速训练3.3 减少梯度爆炸或者梯度消失的情况 4. 补充4.1 BN层做的是标准化不是归一化4.2 BN层的公式4.3 BN层为什么要引入gamma和beta参数 1. 参考文章 [1] Sergey Ioffe, “Batch
【tensorrt】——batch推理对比
关键词:tensorrt, int8, float16,batch推理 该测试结果有问题,正确的测试请移步:【tensorrt】——trtexec动态batch支持与batch推理耗时评测 int8量化,这篇文章中nvidia tensorrt的int8推理在batch大的时候有推理速度的提升,这里实测一下。 采用float16精度的ddrnet23模型,tensorrt的python
【tensorrt】——PluginV2Layer must be V2Ext or V2IOExt or V2DynamicExt when there is no implicit batch d
tensorrt 1. tensorrt插件 用c++为tensorrt写了插件,继承自IPluginV2用pybind11进行python注册 namespace torch2trt {PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {py::class_<InterpolatePlugin>(m, "InterpolatePlugin")
tensorflow中 tf.train.slice_input_producer() 函数和 tf.train.batch() 函数
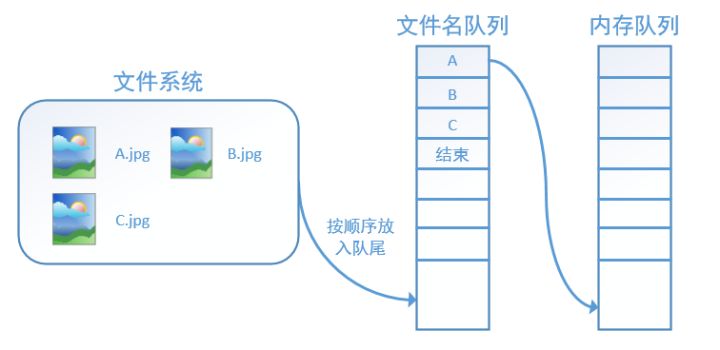
原创:https://blog.csdn.net/dcrmg/article/details/79776876 别人总结的转载方便自己以后看 tensorflow数据读取机制 tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算。 具体来说就是使用一个线程源源不断的将硬盘中的图片数据读入到一个内存队列中,另一个线程负责
什么是 Batch Normalization 批标准化和全连接层
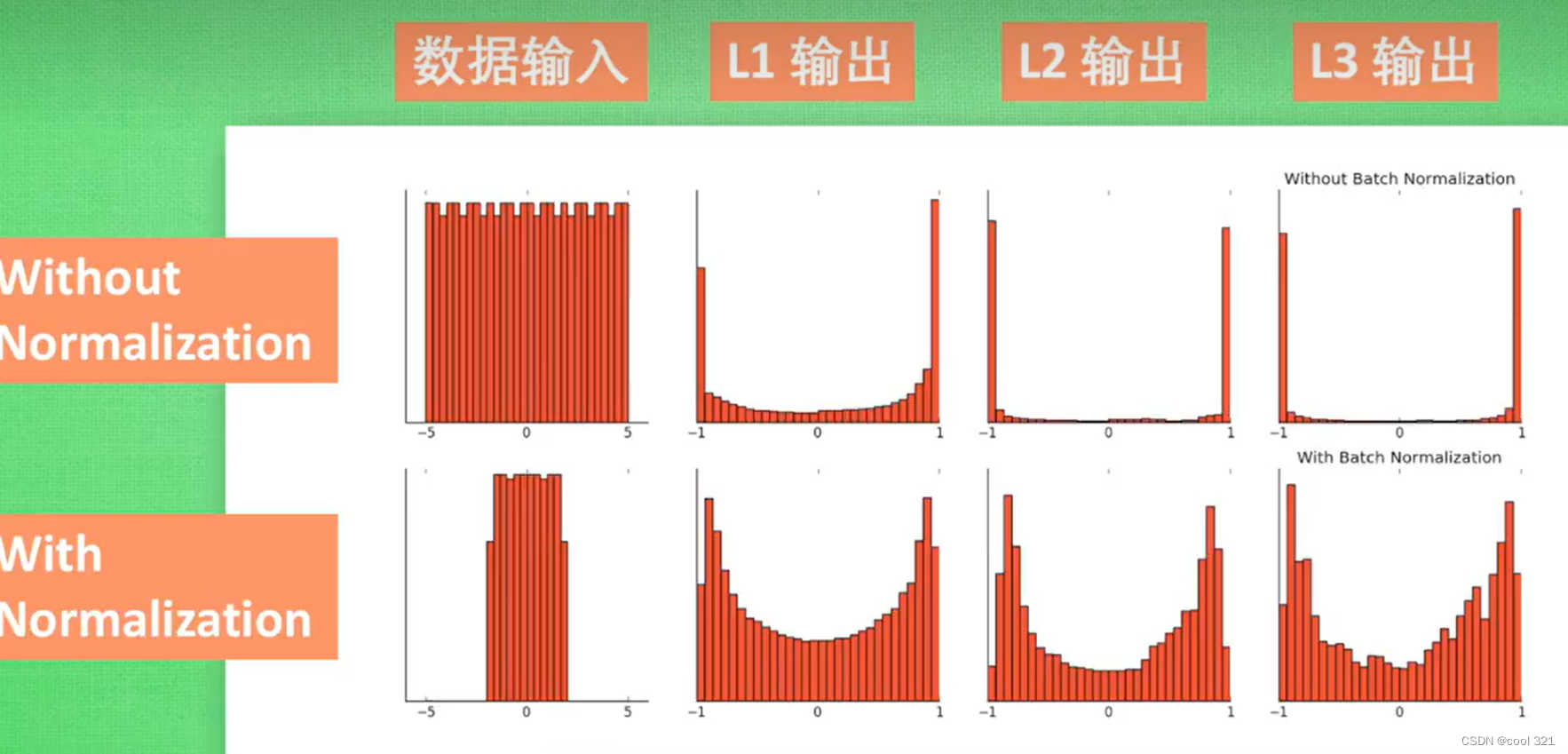
Batch Normalization 神经元在经过激活函数之后会处于饱和状态,无论后续怎么变化都不会再起作用。 每一层都会进行batch normalization的处理! without normalization 会导致数据分布再饱和区 全连接层: 全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。如果说卷积
转 如何理解TensorFlow中的batch和minibatch
如何理解TensorFlow中的batch和minibatch 深度学习的优化算法,说白了就是梯度下降。每次的参数更新有两种方式。 第一种,遍历全部数据集算一次损失函数,然后算函数对各个参数的梯度,更新梯度。这种方法每更新一次参数都要把数据集里的所有样本都看一遍,计算量开销大,计算速度慢,不支持在线学习,这称为Batch gradient descent,批梯度下降。 另一种,每看一个数据就算