训练专题

MiniGPT-3D, 首个高效的3D点云大语言模型,仅需一张RTX3090显卡,训练一天时间,已开源
项目主页:https://tangyuan96.github.io/minigpt_3d_project_page/ 代码:https://github.com/TangYuan96/MiniGPT-3D 论文:https://arxiv.org/pdf/2405.01413 MiniGPT-3D在多个任务上取得了SoTA,被ACM MM2024接收,只拥有47.8M的可训练参数,在一张RTX

Spark MLlib模型训练—聚类算法 PIC(Power Iteration Clustering)
Spark MLlib模型训练—聚类算法 PIC(Power Iteration Clustering) Power Iteration Clustering (PIC) 是一种基于图的聚类算法,用于在大规模数据集上进行高效的社区检测。PIC 算法的核心思想是通过迭代图的幂运算来发现数据中的潜在簇。该算法适用于处理大规模图数据,特别是在社交网络分析、推荐系统和生物信息学等领域具有广泛应用。Spa

SigLIP——采用sigmoid损失的图文预训练方式
SigLIP——采用sigmoid损失的图文预训练方式 FesianXu 20240825 at Wechat Search Team 前言 CLIP中的infoNCE损失是一种对比性损失,在SigLIP这个工作中,作者提出采用非对比性的sigmoid损失,能够更高效地进行图文预训练,本文进行介绍。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注
Detectorn2预训练模型复现:数据准备、训练命令、日志分析与输出目录
Detectorn2预训练模型复现:数据准备、训练命令、日志分析与输出目录 在深度学习项目中,目标检测是一项重要的任务。本文将详细介绍如何使用Detectron2进行目标检测模型的复现训练,涵盖训练数据准备、训练命令、训练日志分析、训练指标以及训练输出目录的各个文件及其作用。特别地,我们将演示在训练过程中出现中断后,如何使用 resume 功能继续训练,并将我们复现的模型与Model Zoo中的

多云架构下大模型训练的存储稳定性探索
一、多云架构与大模型训练的融合 (一)多云架构的优势与挑战 多云架构为大模型训练带来了诸多优势。首先,资源灵活性显著提高,不同的云平台可以提供不同类型的计算资源和存储服务,满足大模型训练在不同阶段的需求。例如,某些云平台可能在 GPU 计算资源上具有优势,而另一些则在存储成本或性能上表现出色,企业可以根据实际情况进行选择和组合。其次,扩展性得以增强,当大模型的规模不断扩大时,单一云平

神经网络训练不起来怎么办(零)| General Guidance
摘要:模型性能不理想时,如何判断 Model Bias, Optimization, Overfitting 等问题,并以此着手优化模型。在这个分析过程中,我们可以对Function Set,模型弹性有直观的理解。关键词:模型性能,Model Bias, Optimization, Overfitting。 零,领域背景 如果我们的模型表现较差,那么我们往往需要根据 Training l


【YOLO 系列】基于YOLOV8的智能花卉分类检测系统【python源码+Pyqt5界面+数据集+训练代码】
前言: 花朵作为自然界中的重要组成部分,不仅在生态学上具有重要意义,也在园艺、农业以及艺术领域中占有一席之地。随着图像识别技术的发展,自动化的花朵分类对于植物研究、生物多样性保护以及园艺爱好者来说变得越发重要。为了提高花朵分类的效率和准确性,我们启动了基于YOLO V8的花朵分类智能识别系统项目。该项目利用深度学习技术,通过分析花朵图像,自动识别并分类不同种类的花朵,为用户提供一个高效的花朵识别

深度学习与大模型第3课:线性回归模型的构建与训练
文章目录 使用Python实现线性回归:从基础到scikit-learn1. 环境准备2. 数据准备和可视化3. 使用numpy实现线性回归4. 使用模型进行预测5. 可视化预测结果6. 使用scikit-learn实现线性回归7. 梯度下降法8. 随机梯度下降和小批量梯度下降9. 比较不同的梯度下降方法总结 使用Python实现线性回归:从基础到scikit-learn 线性
使用openpose caffe源码框架训练车辆模型常见错误及解决办法
错误1:what(): Error: mSources.size() != mProbabilities.size() at 51, OPDataLayer, src/caffe/openpose/layers/oPDataLayer.cpp 原因:这是因为在网络模型中数据源sources和probabilities设置的参数个数不一样导致的,一个数据源对应一个概率 解决方法:只需要将网络文

caffe训练openpose相关资源
CPMTransformationParameter参数解析: https://www.jianshu.com/p/063a2159f0f2 genLMDB.py: https://www.jianshu.com/p/1cae32cbd36d OpenPose 参数说明: https://blog.csdn.net/zziahgf/article/details/84668319 openp

Llama 3.1大模型的预训练和后训练范式解析
Meta的Llama大型语言模型每次出新版本,都会是一大事件。前段时间他们不仅发布了3.1的一个超大型的405亿参数模型,还对之前的8亿和70亿参数的模型做了升级,让它们在MMLU测试中的表现更好了。 不同模型在MMLU基准测试中的表现 他们还出了一个92页的技术报告《Llama 3 Herd of Models》(https://arxiv.org/abs/2407.21783),里
[置顶] 2014训练计划进阶版
动态规划: 区间dp,树状dp,数位dphdu3555, sgu258, sgu390 队列优化: zoj3399 最小表示法的状态压缩DP: spoj2159 专题链接:http://acm.hust.edu.cn/vjudge/contest/view.action?cid=38881#overview 专题链接: http://acm.hust.edu.cn/vjudg
![[置顶] 2014训练计划](https://img-blog.csdn.net/20140306201539640)
[置顶] 2014训练计划
每个专题结束后会有5小时的专题赛~ 1、hustOJ目前支持谷歌、火狐浏览器等部分浏览器。 2、欢迎吐槽~ 3、推荐该阶段用书(以下具体算法实现多数可在此书中找到详解):算法竞赛入门经典之训练指南(刘汝佳) 4、题解报告:专题中的题目多是经典题目,百度搜索即有详细解答~ 5、专题相关知识点红字标出,建议先百度红字部分,有助于专题学习~ 6、专题时间会在"ACM 今天你AC了吗?"(12
2015多校联合训练第三场Work(hdu5326)
题意: a是b的上司,b是c的上司,则a是c的上司,问构成一个树种,有多人是 k个人的上司 思路: 先找出root,然后dfs一下就行 #include <bits/stdc++.h>#define LL long longusing namespace std;const int MAXN = 1e6;int f[105];int n, k;int mp[101][101];
2015年多校联合训练第三场RGCDQ(hdu5317)
题意: f(i)代表i数中有的素数的种数,给出区间[l,r],求区间内max(gcd(f(i))), 由于i最大是1e6,2*3*5*7*11*13*17>1e6,故最多不超过7种素数, 先打表打出1e6内的素数种数表,然后用sum[i][j]代表1-i个数中,还有j个素数的个数,最后用sum[r][j] - sum[l-1][j]求出区间内含有j个素数的数的个数,暴力找出1,2,3,4,5
2015多校联合训练第一场Tricks Device(hdu5294)
题意:给一个无向图,给起点s,终点t,求最少拆掉几条边使得s到不了t,最多拆几条边使得s能到t 思路: 先跑一边最短路,记录最短路中最短的边数,总边数-最短边数就是第二个答案 第一个答案就是在最短路里面求最小割,也就是求最大流,然后根据最短路在建个新图,权为1,跑一边网络流 模板题,以后就用这套模板了 #include <iostream>#include <cstdio>#incl

2015多校联合训练第一场Assignment(hdu5289)三种解法
题目大意:给出一个数列,问其中存在多少连续子序列,子序列的最大值-最小值< k 这题有三种解法: 1:单调队列,时间复杂度O(n) 2:RMQ+二分,时间复杂度O(nlogn) 3:RMQ+贪心,时间复杂度O(nlogn) 一:RMQ+二分 RMQ维护最大值,最小值,枚举左端点i,二分找出最远的符合的右端点j,答案就是ans += j - i+1;(手推一下就知道) 比如1 2 3
2015年多校联合训练第一场OO’s Sequence(hdu5288)
题意:给定一个长度为n的序列,规定f(l,r)是对于l,r范围内的某个数字a[i],都不能找到一个对应的j使得a[i]%a[j]=0,那么l,r内有多少个i,f(l,r)就是几。问所有f(l,r)的总和是多少。 公式中给出的区间,也就是所有存在的区间。 思路:直接枚举每一个数字,对于这个数字,如果这个数字是合法的i,那么向左能扩展的最大长度是多少,向右能扩展的最大长度是多少,那么i为合法的情况

使用 VisionTransformer(VIT) FineTune 训练驾驶员行为状态识别模型
一、VisionTransformer(VIT) 介绍 大模型已经成为人工智能领域的热门话题。在这股热潮中,大模型的核心结构 Transformer 也再次脱颖而出证明了其强大的能力和广泛的应用前景。Transformer 自 2017年由Google提出以来,便在NLP领域掀起了一场革命。相较于传统的循环神经网络(RNN)和长短时记忆网络(LSTM), Transformer 凭借自注意力机制


使用YOLOv10训练自定义数据集之二(数据集准备)
0x00 前言 经过上一篇环境部署的介绍【传送门】,我们已经得到了一个基本可用的YOLOv10的运行环境,还需要我们再准备一些数据,用于模型训练。 0x01 准备数据集 1. 图像标注工具 数据集是训练模型基础素材。 对于小白来说,一般推荐从一些开放网站中下载直接使用,官方推荐了一个名为Roboflow的数据集网站。Roboflow是一个免费开源数据集管理平台,它不仅提供免费的数据集,还
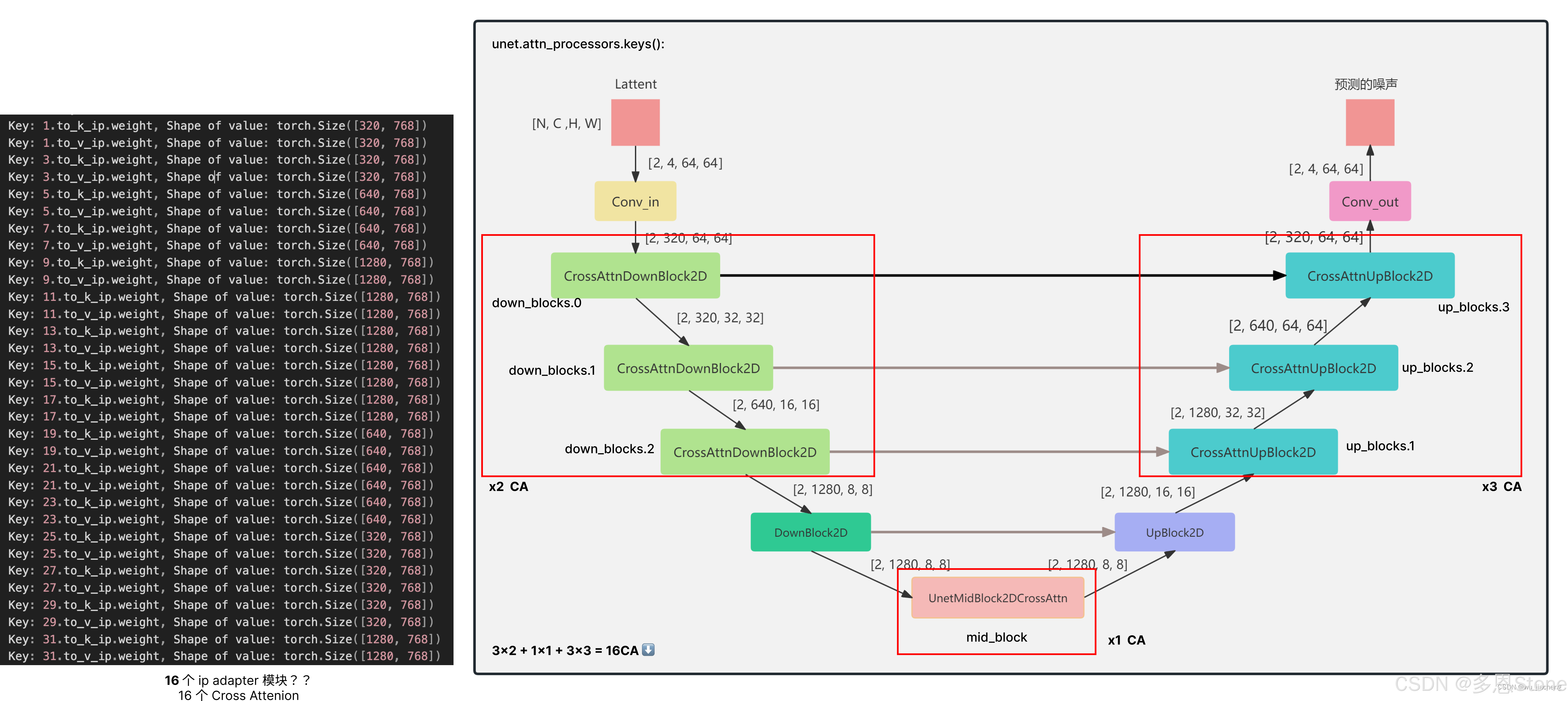
【扩散模型(十)】IP-Adapter 源码详解 4 - 训练细节、具体训了哪些层?
系列文章目录 【扩散模型(一)】中介绍了 Stable Diffusion 可以被理解为重建分支(reconstruction branch)和条件分支(condition branch)【扩散模型(二)】IP-Adapter 从条件分支的视角,快速理解相关的可控生成研究【扩散模型(三)】IP-Adapter 源码详解1-训练输入 介绍了训练代码中的 image prompt 的输入部分,即 i

基于百度AIStudio飞桨paddleRS-develop版道路模型开发训练
基于百度AIStudio飞桨paddleRS-develop版道路模型开发训练 参考地址:https://aistudio.baidu.com/projectdetail/8271882 基于python35+paddle120+env环境 预测可视化结果: (一)安装环境: 先上传本地下载的源代码PaddleRS-develop.zip 解压PaddleRS-develop.zip到目录

分布式训练同步梯度出现形状不一致的解决方案
1、问题描述 为了加快大模型的训练速度,采用了分布式训练策略,基于MultiWorkerServerStrategy模式,集群之间采用Ring—Reduce的通信机制,不同节点在同步梯度会借助collective_ops.all_gather方法将梯度进行汇聚收集,汇聚过程出现了: allreduce_1/CollectiveGather_1 Inconsitent out

选取训练神经网络时的Batch size ,BatchNorm
BatchNorm 优点:对于隐藏层的每一层输入,因为经过激活函数的处理,可能会趋向于大的正值和负值,容易出现梯度下降和梯度消失。所以强行拉回到服从均值为0,方差为1的标准正态分布,避免过拟合 缺点:正是因为这种强行改变分布的手段,使得隐层输入和原始数据分布差异太大,如果数据量不大时,容易欠拟合。可能不用更好一些 https://www.zhihu.com/search?type=conte