本文主要是介绍如何快速高效的训练ResNet,各种奇技淫巧(四):网络结构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:Ayoosh Kathuria
编译:ronghuaiyang
导读
这个系列介绍了如何在CIFAR10上高效的训练ResNet,到第4篇文章为止,我们使用单个V100的GPU,可以在79s内训练得到94%的准确率。里面有各种各样的trick和相关的解释,非常好。
我们寻找更有效的网络架构,并找到一个9层网络,训练时间为79秒。
我们尝试了一些不同的网络,发现我们一直在努力工作。
到目前为止,我们一直在训练一个固定的网络架构,从CIFAR10上最快的单GPU DAWNBench开始。通过一些简单的修改,我们将达到测试精度94%的时间从341s降低到了154s。今天我们将研究替代的体系结构。
让我们回顾一下我们目前的网络:

粉色残差模块包含一个恒等跳跃连接,保留输入的空间分辨率和通道尺寸:

浅绿色下采样块将空间分辨率降低两倍,输出通道数量增加一倍:
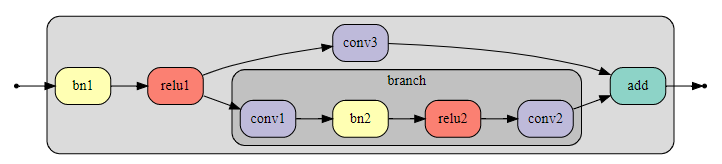
使用残差块的动机是为了在网络中创建跳跃连接来简化优化的过程。我们希望较短的路径代表较浅的子网络,相对容易训练,而较长的路径增加容量和计算深度。研究网络中的最短路径是如何隔离训练的,并在添加较长的分支之前采取措施改进这一点,似乎是合理的。
去掉长分支后,得到以下骨干网络,除初始分支外,所有卷积的步长为2:

在接下来的实验中,我们将使用之前的学习率策略的加速版本进行20个epochs的训练,因为网络较小,因此收敛速度更快。主要的代码都可以在这里找到:https://github.com/davidcpage/cifar10-fast/blob/master/ents.ipynb。
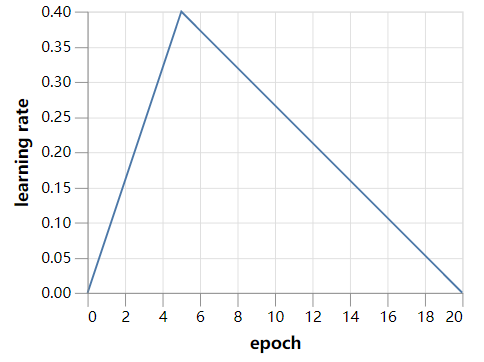
训练20个epochs的最短路径网络,在36秒内的测试精度仅为55.9%。去除重复的batch-norm-ReLU组,将训练时间减少到32秒,但测试精度基本保持不变。
这种主干网的一个严重缺点是,下采样卷积有1×1个核,步长为2,因此它们并没有扩大感受野,而是简单地丢弃了信息。如果我们用3×3个卷积来代替这些,情况会有很大的改善,20个epochs后的测试精度在36秒内达到85.6%。
我们可以进一步改进下采样阶段,使用3×3的卷积,stride为1,然后是池化层,而不是使用strided卷积。我们选择窗口大小为2×2的最大池化,43秒后最终测试准确率为89.7%。使用平均池可以得到类似的结果,但是需要稍微长一点的时间。

分类器之前的最后一个池化层是全局平均池化层和最大池化层的连接,它们继承自原始网络。我们将其替换为更标准的全局最大池化层,并将最终卷积的输出维数加倍,以补偿分类器输入维数的减少,最终的测试精度在47s内达到90.7%。注意,此阶段的平均池化性能明显低于最大池化。
在PyTorch(0.4)中,默认从区间[0,1]中随机均匀地选择初始batch norm尺度。接近于零的初始化通道可能会被浪费,因此我们用常量1的初始化来替换它。这导致了一个更大的信号通过网络和补偿,我们对最终的分类器引入了一个常数,用来整体相乘。对这个额外超参数的粗略手工优化表明0.125是一个合理的值。(较低的数值使得预测不那么确定,而且似乎有利于优化。)随着这些变化,20个epochs的训练在47秒内达到91.1%的测试精度。
以下是我们迄今为止所采取的步骤:
| Network | Test acc | Train time |
|---|---|---|
| Original backbone | 55.9% | 36s |
| 去掉重复的BN-ReLU | 56.0% | 32s |
| 使用3×3卷积 | 85.6% | 36s |
| 使用Max pool下采样 | 89.7% | 43s |
| 全局最大池化 | 90.7% | 47s |
| 更好的BN尺度初始化 | 91.1% | 47s |
骨干网现在似乎处于合理的状态,我们的回报正在递减。是时候添加一些层了。网络只有5层深(4个卷积,一个全连接),所以我们不清楚是否需要残差分支,或者主干上的额外层是否能使我们达到94%的目标。
一种看起来不太可能的方法就是给5层网络增加宽度。如果我们将通道尺寸加倍,训练60个周期,我们可以达到93.5%的测试精度,但训练需要全部321秒。
在扩展网络深度时,我们面临着过多的选择,比如不同的残差分支类型、深度和宽度,以及新的超参数,比如初始规模和残差分支的偏差。为了取得进展,我们将搜索空间限制在可管理的范围内,并且不调优任何新的超参数。
具体来说,我们考虑两类网络。第一个是可选地在每个最大池化层之后添加一个卷积层(使用batch-norm-ReLU)。第二类构造方法是在相同的最大池化层之后,选择性地添加一个由两个具有跳跃连接的串行3×3卷积组成的残差块。
我们在最后一个卷积块之后和全局最大池化之前插入一个额外的2×2 max pooling层,这样就有3个位置可以添加新的layer。在每种情况下,包含或不包含新层的选择都是独立做出的,导致每个类中有7个新网络。我们还考虑了这两个类的混合,但这些并没有导致进一步的改进,所以我们不在这里描述它们。
下面是第一类网络的一个例子,我们在第二个最大池层之后添加了一个额外的卷积:

下面是第二类网络的一个例子,我们在第1层和第3层之后添加了残差分支:

现在是时候进行一些蛮力架构搜索了!我们对15个网络中的每个网络(改进的主干+每个类中的7个变种)进行20个epochs的训练,同时也做了22个epochs的训练,以了解更长时间的训练与使用更深层次的体系结构相比的好处。如果我们每个实验运行一次,这相当于整整30分钟的计算。遗憾的是,每个最终测试精度的标准差都在0.15%左右,为了能够得出准确的结论,我们将每个实验运行10次,导致每个数据点的标准差在0.05%左右。即便如此,从20个epochs到22个epochs,架构之间的改进率的变化可能主要是噪音。
结果如下,点表示20个epochs的次数和精度,而直线是延伸到相应的22个epochs的结果:
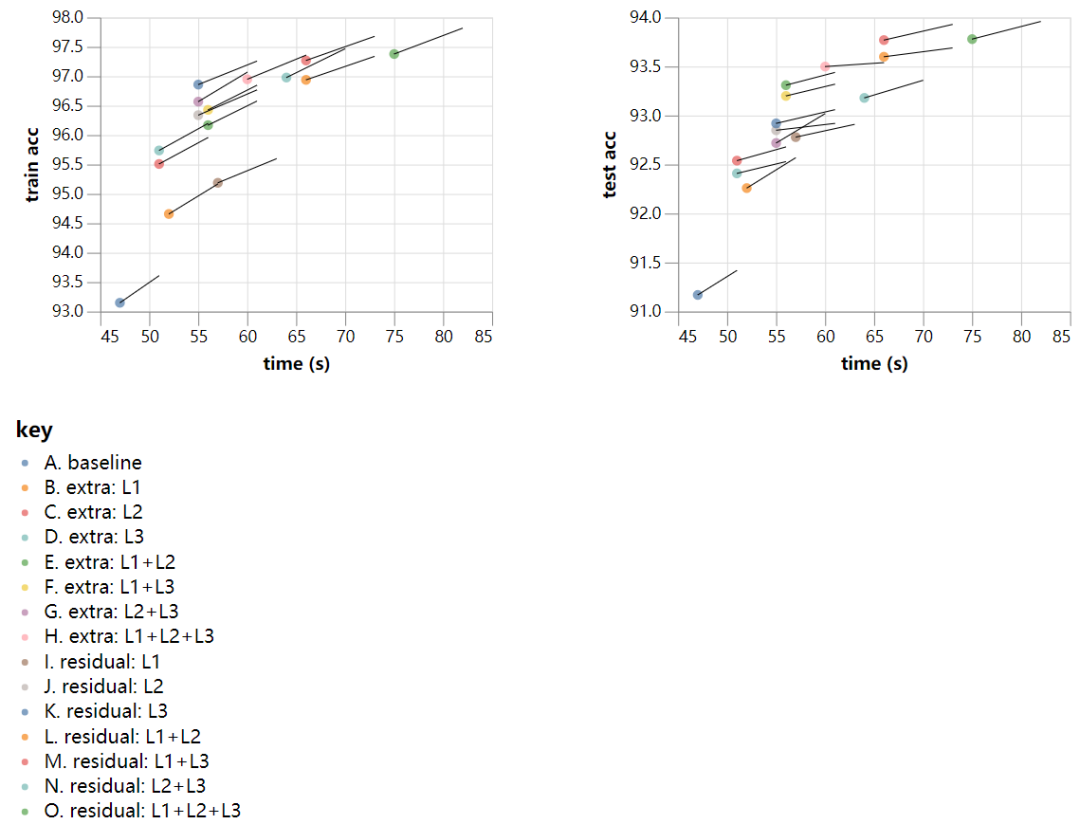
与使用更深层次的体系结构实现的改进相比,较长时间的训练带来的改进速度似乎比较慢。在测试的架构中,可能最有希望的是残差:L1+L3,我们在上面碰巧选择了它来说明。该网络运行20个epoch,在66秒内达到93.8%的测试精度。如果我们将训练时间延长到24个周期,10次跑中有7次达到94%,平均准确率为94.08%,训练时间为79秒!
今天就到这里吧。我们发现了一个9层深度残差网络,在79秒内训练准确率达到94%,训练时间几乎减少了一半。剩下的一个问题是,我们真的需要残差分支来达到94%的测试精度吗?答案显然是否定的。例如,单分支网络Extra:L1+L2+L3在180秒内达到95%的准确率,其中包括60个epoch训练和额外的正则化(12×12 cutout),更宽的版本更高。但至少目前最快的网络达到94%是残差网络(考虑到本系列文章的标题,这是幸运的)。
在今天结束之前,我想简要地回顾一下这项工作的动机。有一种合理的观点认为,在CIFAR10上训练一个模型到94%的测试准确度是毫无意义的,因为最先进的水平是98%以上。(还有一种不太合理的观点认为,ImageNet是唯一真实的数据集,其他任何东西都是浪费时间,但我不会讨论这个问题,只是说,从CIFAR10中学到的一些经验教训也应该可以转移到这个数据集上。)
我们使用一个9层网络,在24个epochs可以达到94%的准确率这个事实,增加我的一些观点的可信度,我们的目标阈值太低。另一方面,人类在CIFAR10上的表现估计约为94%(基于一个人对400幅图像进行分类!)因此,这个问题还没有研究的很清楚。
最先进的精度是一个病态的目标,因为在这个问题上投入更大的模型、更多的超参数调优、更多的数据扩充或更长的训练时间通常会导致精度的提高,使结果之间的公平比较成为一项微妙的任务。在训练或架构设计方面的创新可能会引入额外的超参数维度,而对这些维度进行调优可能会对训练的其他方面进行更好的隐式优化,而这些方面与正在研究的扩展无关。消融研究通常被认为是最佳实践,但如果基础模型具有更低的显式超参数空间来优化,则无法解决这一问题。这种情况的结果是,最先进的模型看起来就像一个由孤立的结果组成的动物展览,这些结果很难比较,容易复制,也很难建立。
鉴于这些问题,我们提出,任何能使实验作品内部和之间的比较变得更容易的东西都是一件好事。我们认为,为资源有限的训练制定有竞争力的基准是减轻其中一些困难的一种方法。
资源限制的引入鼓励工作之间进行更公平的比较,从而减少了对训练工作进行调整的必要性。额外的模型复杂性,允许隐式参数的高维优化,通常会受到资源约束基准的惩罚。明确控制相关参数的方法往往会胜出。
资源限制基准允许最先进前沿研究,而不是局限于一个点上,允许在一个合适的制度下对目标进行研究,可以更清楚的认识到不同的组件的作用,也许可以通过一系列转换变得更加复杂,并获得成功的架构。
一个简单的技术可以被证明是针对较低的阈值,而不需要包含所有的技巧,以提高一个无约束的问题,获得最好的表现。较短的训练时间和较低的模型复杂度应该使较低的资源基准测试更容易研究,并且比它们的无约束同类测试能更好地优化。更好的优化基线反过来使接受或拒绝提议的变更变得更容易。
近年来,根据推理时间或模型大小,最先进模型的发布曲线呈现出积极的趋势。这些都是优化的重要实际目标,它们解决了上面的一些问题,但我们相信,随着训练时间的增加,正则化会带来更多的好处。另一方面,优化训练时间不考虑推理时间并不是最优的,这就是为什么我们的训练时间结果总是包括每个epoch评估测试集的时间,我们避免那些增加测试时间,减小训练时间的技术。
在第5部分中,我们从加速训练中休息一下,并开发了一些超参数调优的启发式方法。

—END—
英文原文:https://myrtle.ai/how-to-train-your-resnet-4-architecture/

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!![]()
这篇关于如何快速高效的训练ResNet,各种奇技淫巧(四):网络结构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




