本文主要是介绍ncnn之resnet图像分类网络模型部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、ONNX模型导出
- 二、模型转换ONNX2NCNN
- 2.1 net.param文件
- 2.2 net.bin文件
- 三、ncnn模型推理
- 四、编译与运行
一、ONNX模型导出
将 PyTorch 模型导出为 ONNX 格式,代码如下:
import torch
import torchvision.models as models
import torch.onnx as onnx# 加载预训练的ResNet-18模型
# 这里使用了ResNet-18的预训练权重,但不再使用 `pretrained=True` 参数
# # resnet = models.resnet18(pretrained=True)
# 而是采用了新的 'weights' 参数来指定预训练的权重集
# 'ResNet18_Weights.IMAGENET1K_V1' 对应于在ImageNet数据集上训练的权重
resnet = models.resnet18(weights='ResNet18_Weights.IMAGENET1K_V1')# 将模型设置为评估模式, 模型中的Dropout层和BatchNorm层将被禁用或固定
resnet.eval()# 创建一个形状为 (1, 3, 224, 224) 的随机输入张量,模拟单张图片输入模型
dummy_input = torch.randn(1, 3, 224, 224)# 使用torch.onnx.export函数导出模型为ONNX格式
# 第一个参数是要导出的模型(resnet)
# 第二个参数是示例输入张量(dummy_input),用于定义模型的输入大小和形状
# 第三个参数是导出的ONNX模型文件的保存路径
onnx_file_path = "../model_param/resnet18.onnx"
onnx.export(resnet, dummy_input, onnx_file_path)print("ResNet-18模型已成功导出为ONNX格式:", onnx_file_path)导出 ONNX 的过程相对简单。提供一个示例输入,然后通过执行一次模型的前向传播,将模型的计算图结构保存下来。执行这段代码后,resnet18.onnx 文件就会被保存到 model_param/ 目录下。大致步骤如下:
-
加载预训练的ResNet-18模型
-
**模型设置为评估模式:**resnet.eval() 将模型切换到
评估模式,确保模型在推理阶段(即模型预测阶段)不会对内部状态进行更新,比如 BatchNorm 层和 Dropout 层。 -
创建示例输入张量:dummy_input = torch.randn(1, 3, 224, 224)生成一个随机输入张量,代表一张3通道的224x224像素的图像
-
**导出为ONNX格式:**使用
torch.onnx.export函数将 PyTorch 模型转换并保存为 ONNX 格式。
使用pretrained的警告:
UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.warnings.warn(
UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=ResNet18_Weights.IMAGENET1K_V1`. You can also use `weights=ResNet18_Weights.DEFAULT` to get the most up-to-date weights.warnings.warn(msg)
在0.13版本后,开始使用weights参数,要解决关于 Torchvision 中pretrained参数弃用的警告,可以将代码中的 pretrained=True参数替换为 weights 参数:weights=ResNet18_Weights.IMAGENET1K_V1或者weights=ResNet18_Weights.DEFAULT。
二、模型转换ONNX2NCNN
NCNN 提供了一个模型转换工具,可以将 ONNX 格式的模型转换为 NCNN 支持的格式。所有模型转换的源代码都在 ncnn/tools 目录下,在编译后,这些工具的可执行文件会生成在 build/tools/ 目录下。
使用 onnx2ncnn 工具来转换模型,具体命令如下:
bin/onnx2ncnn model_param/resnet18.onnx model_param/resnet18.param model_param/resnet18.bin
这条命令将 resnet18.onnx 模型转换为 resnet18.param 和 resnet18.bin 两个文件:
- resnet18.param:记录的是
计算图的结构,即模型的参数信息。 - resnet18.bin:存放的是模型的所有具体参数。
通过这一步,模型就从 ONNX 格式成功转换为了 NCNN 可以使用的格式,接下来可以在 NCNN 上进行推理任务。

2.1 net.param文件
resnet18.param中部分参数如下:
7767517
58 66
Input input.1 0 1 input.1
Convolution /conv1/Conv 1 1 input.1 /conv1/Conv_output_0 0=64 1=7 11=7 2=1 12=1 3=2 13=2 4=3 14=3 15=3 16=3 5=1 6=9408
ReLU /relu/Relu 1 1 /conv1/Conv_output_0 /relu/Relu_output_0
Pooling /maxpool/MaxPool 1 1 /relu/Relu_output_0 /maxpool/MaxPool_output_0 0=0 1=3 11=3 2=2 12=2 3=1 13=1 14=1 15=1 5=1
Split splitncnn_0 1 2 /maxpool/MaxPool_output_0 /maxpool/MaxPool_output_0_splitncnn_0 /maxpool/MaxPool_output_0_splitncnn_1
Convolution /layer1/layer1.0/conv1/Conv 1 1 /maxpool/MaxPool_output_0_splitncnn_1 /layer1/layer1.0/conv1/Conv_output_0 0=64 1=3 11=3 2=1 12=1 3=1 13=1 4=1 14=1 15=1 16=1 5=1 6=36864
ReLU /layer1/layer1.0/relu/Relu 1 1 /layer1/layer1.0/conv1/Conv_output_0 /layer1/layer1.0/relu/Relu_output_0
.......
Pooling /avgpool/GlobalAveragePool 1 1 /layer4/layer4.1/relu_1/Relu_output_0 /avgpool/GlobalAveragePool_output_0 0=1 4=1
Flatten /Flatten 1 1 /avgpool/GlobalAveragePool_output_0 /Flatten_output_0
InnerProduct /fc/Gemm 1 1 /Flatten_output_0 191 0=1000 1=1 2=512000
param:
[magic]
[layer count] [blob count]
[layer type] [layer name] [input count] [output count] [input blobs] [output blobs] [layer specific params]
首先第一行是一个magic数字,用于标识文件的格式。对于ncnn格式,7767517用于确认文件的正确性和格式。 magic数字是特定的数值或字符序列,用于文件的开头,帮助程序识别文件类型。
第二行是两个数组58 66分别表示Layer(算子)和Blob的个数,即模型中层(Layer)和数据块(Blob)的数量。
-
58: 表示模型中的总层数。层是模型的基本组成单位,例如卷积层、池化层等。
-
66: 表示模型中数据块的总数。数据块通常包括模型参数(如权重)和中间计算结果。
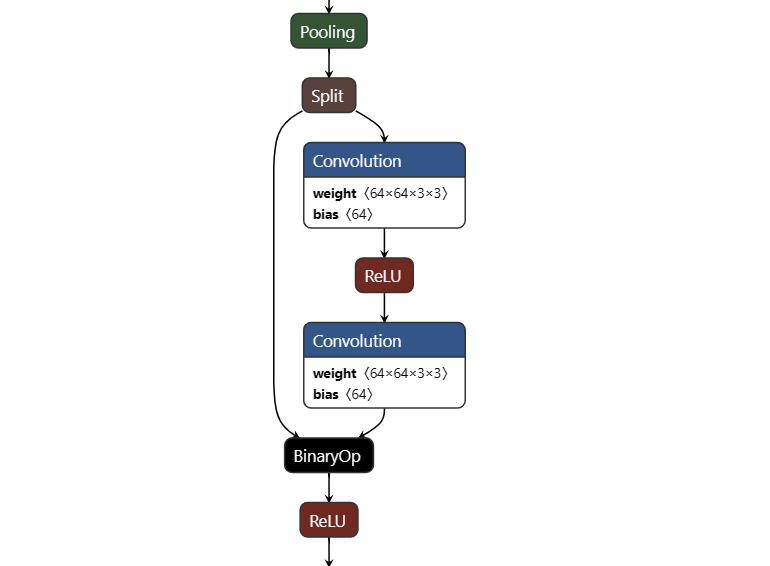
使用netron打开resnet18.param可以看到resnet18的结构,如上图所示,其中像Convolution,ReLU,Pooling,Split,BinaryOp都是一个算子也就是layer。**blob在网络中主要用于存储中间数据、输入数据和输出数据。**以Split算子为例,它有1个输入2个输出,则一共有3个blob。而Convolution和Relu等算子它输入输出都是1个blob。
每个算子(layer)可能会涉及多个blob,因为算子可以有多个输入和输出,而每个blob都代表一个数据存储单元。在查看模型文件时,通常blob的数量会比layer的数量多,因为网络中会有许多中间计算结果需要存储。
Layer和Blob的区别
- Layer(层):
- 定义: 模型中的每一层代表
一个操作或计算单元。例如,卷积层、池化层、激活层等。 - 作用:
每一层执行特定的计算任务,将输入数据转换为输出数据。层定义了模型的结构和计算流程。
- 定义: 模型中的每一层代表
- Blob(数据块):
- 定义: Blob是模型中
存储数据的单位。包括模型的权重、偏置以及中间计算结果等。 - 作用: Blob用于存储和传递数据。模型的每一层可能有输入Blob和输出Blob,数据在这些Blob之间流动。
- 定义: Blob是模型中
接下来分析剩下的每一行的格式时,可以看到这些行都遵循类似的结构,它们描述了模型中的各个层或操作及其参数。通常格式如下:
[layer type] [layer name] [input count] [output count] [input blobs] [output blobs] [layer specific params]
- 层类型 (Layer Type): 层的操作类型,例如 Convolution、Softmax 等。
- 层名称 (Layer Name): 该层的唯一名称。
- 输入数量 (Input Count): 该层需要的输入 blob 数量。
- 输出数量 (Output Count): 该层产生的输出 blob 数量。
- 输入 blob (Input Blobs): 该层输入 blob 的名字列表,名称之间用空格分隔。
- 输出 blob (Output Blobs): 该层输出 blob 的名字列表,名称之间用空格分隔。
- 层特定参数 (Layer Specific Params): 该层的参数信息,以
key=value的形式列出,参数之间用空格分隔。
层参数 (Layer Param)格式如下:
0=1 1=2.5 -23303=2,2.0,3.0
key=value 的形式
在每一层的行中,键索引应该是唯一的。如果使用了默认值,则可以省略键值对,可以在 operation-param-weight-table中查找已有的参数键索引的含义,如下图所示。
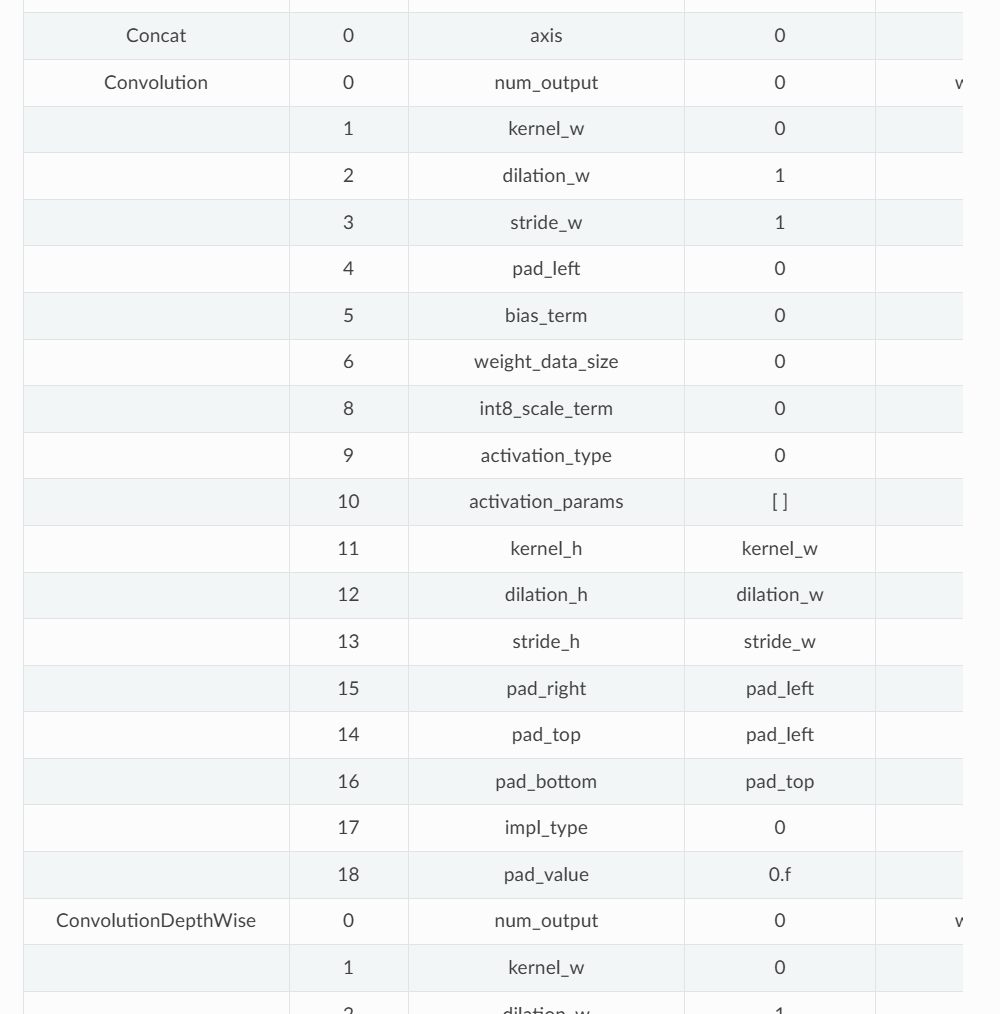
Convolution conv1 1 1 input.1 conv1_weight 0=64 1=7 2=1 3=2 4=3 5=64 6=3 7=448 8=1 9=1 10=0
-
Convolution: 操作类型,表示这是一个卷积层。 -
conv1: 该层的名称。 -
1: 输入个数。 -
1: 输出个数。 -
input.1 conv1_weight: 输入的张量名称,input.1是输入数据,conv1_weight是卷积核权重。 -
0=64: 输出通道数64。 -
1=7: 卷积核大小7x7。…
以上这些对ncnn的使用者来说,主要需要关注的是整个模型的输入输出。对于当前这个网络来说,整个网络的输入blob名字是input.1,输出blob是191,这些信息在写推理代码的时候会用到。
2.2 net.bin文件
+---------+---------+---------+---------+---------+---------+| weight1 | weight2 | weight3 | weight4 | ....... | weightN |+---------+---------+---------+---------+---------+---------+^ ^ ^ ^0x0 0x80 0x140 0x1C0
模型二进制文件是所有==权重数据(Weight Data)==的串联,每个权重缓冲区按 32 位对齐。
权重缓冲区 (Weight Buffer)格式如下所示:
[flag] (optional) [raw data] [padding] (optional)
- flag :无符号整数,小端序,表示权重存储类型,0 => float32,0x01306B47 => float16,否则 => 量化 int8,如果层实现强制明确存储类型,则可以省略。
- Raw Data原始数据:原始权重数据,小端数据,float32 数据或 float16 数据或量化表和索引,具体取决于存储类型标志
- padding:32 位对齐的填充空间,如果已经对齐,则可以省略
net.param文件包含网络的层信息和参数,而 net.bin文件则包含权重数据。
参考文档:https://ncnn.readthedocs.io/en/latest/developer-guide/param-and-model-file-structure.html#layer-param
三、ncnn模型推理
#include "net.h"
#include <algorithm>
#if defined(USE_NCNN_SIMPLEOCV)
#include "simpleocv.h"
#else
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#endif
#include <stdio.h>
#include <vector>// 模型检测函数,输入图像是BGR格式,输出是类别得分的向量
static int detect_resnet18(const cv::Mat& bgr, std::vector<float>& cls_scores)
{ncnn::Net resnet18; // 创建ncnn::Net实例以加载模型// 启用Vulkan计算以使用GPU加速resnet18.opt.use_vulkan_compute = true;// 加载模型的参数和权重if (resnet18.load_param("/home/xiaochao/Infer/NCNN/use_ncnn/resnet18/model_param/resnet18.param"))exit(-1);if (resnet18.load_model("/home/xiaochao/Infer/NCNN/use_ncnn/resnet18/model_param/resnet18.bin"))exit(-1);// opencv读取图片是BGR格式,需要转换为RGB格式,并调整大小为224x224ncnn::Mat in = ncnn::Mat::from_pixels_resize(bgr.data, ncnn::Mat::PIXEL_BGR2RGB, bgr.cols, bgr.rows, 224, 224);// 使用均值和标准差值对图像进行归一化处理// 图像归一标准化,以R通道为例(x/225-0.485)/0.229,化简后可以得到下面的式子// 需要注意的是substract_mean_normalize里的标准差其实是标准差的倒数,这样在算的时候就可以将除法转换为乘法计算// 所以norm_vals里用的是1除const float mean_vals[3] = {0.485f*255.f, 0.456f*255.f, 0.406f*255.f};const float norm_vals[3] = {1/0.229f/255.f, 1/0.224f/255.f, 1/0.225f/255.f};in.substract_mean_normalize(mean_vals, norm_vals);// 创建一个网络提取器,用于输入数据和提取结果ncnn::Extractor ex = resnet18.create_extractor();// 将归一化后的图像数据输入到网络的"input.1" blob中ex.input("input.1", in);ncnn::Mat out;// 提取出推理结果,推理结果存放在191这个blob里 该结果包含类别得分ex.extract("191", out);// 调整输出向量的大小以存储类别得分cls_scores.resize(out.w);for (int j = 0; j < out.w; j++){cls_scores[j] = out[j]; // 将每个得分存储到向量中}return 0;
}// 打印得分最高的前k个类别及其对应的索引
static int print_topk(const std::vector<float>& cls_scores, int topk)
{int size = cls_scores.size();std::vector<std::pair<float, int> > vec(size);// 将得分与其对应的索引存储到一个pair向量中for (int i = 0; i < size; i++){ // [score,index]vec[i] = std::make_pair(cls_scores[i], i);}// 对向量进行部分排序,以获取前k个最高得分,按降序排列std::partial_sort(vec.begin(), vec.begin() + topk, vec.end(),std::greater<std::pair<float, int> >());// 打印前k个得分及其对应的类别索引for (int i = 0; i < topk; i++){float score = vec[i].first;int index = vec[i].second;fprintf(stderr, "%d = %f\n", index, score);}return 0;
}int main(int argc, char** argv)
{// 检查是否提供了正确数量的参数if (argc != 2){fprintf(stderr, "Usage: %s [imagepath]\n", argv[0]);return -1;}const char* imagepath = argv[1];// 使用OpenCV读取输入图像cv::Mat m = cv::imread(imagepath, 1);if (m.empty()){fprintf(stderr, "cv::imread %s failed\n", imagepath);return -1;}std::vector<float> cls_scores;// 检测图像中的对象,并获取类别得分detect_resnet18(m, cls_scores);// 打印得分最高的前三个类别print_topk(cls_scores, 3);return 0;
}resnet18网络推理的主要流程步骤如下:
-
图像加载以及图像预处理
使用OpenCV加载推理图像,将BGR(cv::Mat)格式的图像转换为RGB(ncnn::Mat)格式,并调整为模型所需的输入尺寸的大小(224x224像素)。然后对图像进行归一化处理,和模型在训练时候的预处理操作一样,使用指定的均值和标准差对图像的像素值进行标准化。
-
加载ResNet-18模型
使用ncnn库加载ResNet-18模型的参数文件(
.param)和权重文件(.bin)。启用Vulkan计算以利用GPU加速推理过程。 -
进行推理
将预处理后的图像数据输入到ResNet-18模型中,并运行前向传播以获取模型的输出结果。输出结果是一个包含每个类别得分的向量。
-
处理并输出推理结果。
再来看看归一化处理操作, imagenet图片三通道的均值和标准差分别是mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]。以R通道为例,原始图片的像素值是从0到255,所以像素值归一化即像x/255,减去均值再除以标准差就是==(x/255-0.485)/0.299==,把255乘下去也就是==(x-0.485×255)/255×0.299==。如果把归一化和标准化一起处理的话,等价均值就是0.485×255,等价标准差就是255×0.299。但由于substract_mean_normalize里的标准差实际是标准差的倒数,这样可以把除法转换为乘法来计算加快效率,所以这里norm_vals用的是标准差的倒数。
const float mean_vals[3] = {0.485f*255.f, 0.456f*255.f, 0.406f*255.f};
const float norm_vals[3] = {1/0.229f/255.f, 1/0.224f/255.f, 1/0.225f/255.f};
in.substract_mean_normalize(mean_vals, norm_vals);
类别下载:https://storage.googleapis.com/download.tensorflow.org/data/imagenet_class_index.json
四、编译与运行
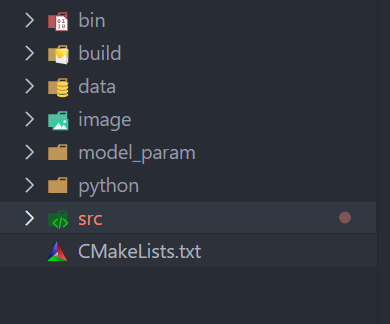
整个工程如上所示,使用CMakeLists.txt来构建整个工程,bin存放可执行程序,比如onnx2ncnn,程序生成的可执行文件。build存放CMakeLists编译后的文件。image存放图片,model_param存储网络结构和参数相关的文件,python存放导出onnx模型的脚步,src存放推理的源文件。
CMakeLists代码如下:
# 指定CMake的最低版本要求为2.8.12
cmake_minimum_required(VERSION 2.8.12)# 定义项目名称为 "NCNN_RESNET18"
project(NCNN_RESNET18)# 设置构建类型为Debug模式,便于调试
set(CMAKE_BUILD_TYPE Debug)# 指定NCNN库的安装路径,并添加到CMake的查找路径中
set(CMAKE_PREFIX_PATH ${CMAKE_PREFIX_PATH} "/home/xiaochao/Infer/NCNN/ncnn/build/install")# 查找并加载NCNN库,要求该库必须存在
find_package(ncnn REQUIRED)# 查找并加载OpenCV库,要求该库必须存在
find_package(OpenCV REQUIRED)# 设置生成的可执行文件的输出目录为项目的bin文件夹
set(CMAKE_RUNTIME_OUTPUT_DIRECTORY ${CMAKE_SOURCE_DIR}/bin)# 添加可执行文件 "resnet18",其源文件为 "src/resnet18.cpp"
add_executable(resnet18 src/resnet18.cpp)# 链接必要的库文件,即ncnn和OpenCV库
target_link_libraries(resnet18 ncnn ${OpenCV_LIBS})运行结果如下:
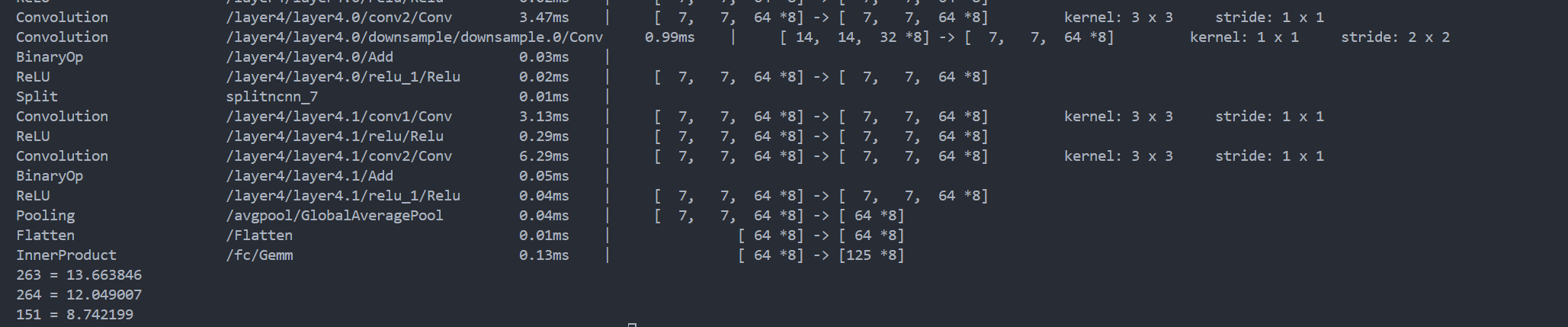
可以看出输出了三个类别263,264,151,可以对imageneg类别中查找分别对应的标签。
这篇关于ncnn之resnet图像分类网络模型部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







