本文主要是介绍如何快速高效的训练ResNet,各种奇技淫巧(五):超参数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:David Page
编译:ronghuaiyang
导读
这个系列介绍了如何在CIFAR10上高效的训练ResNet,这是第五篇,给大家讲解超参数的相关内容。
我们开发了一些超参数调优启发式算法。
关于超参数调优以及如何避免它
人们普遍认为神经网络的超参数选择是困难的。如果有人赞同这一观点,就会出现两种不同的行动方针。第一种方法(大致上是我们目前的方法)是忽略这个问题,抱着最好的希望,或许偶尔调整一下学习率策略。在一些较大的云提供商中流行的另一种方法是为每个新的实验设置启动全参数扫描。
现在是解决这个问题的时候了,我们要问一下忽略超参数的代价是什么。我们是否错过了优化的机会,或者更糟,得出了无效的结论?或者,是否夸大了超参数调优的重要性和难度?
在今天的文章中,我们将从实验和理论上成功地识别超参数空间中一些几乎平坦的方向。这大大简化了搜索问题。沿着这些方向进行优化只会有一点帮助,但如果做得不好的话,损失也是很小的。在接下来的文章中,我们将讨论,在有利的环境下,整个体系结构家族共享相似的最优参数值。
我们的结论是,超参数搜索并不总是困难的,有时可以完全跳过。关于权值衰减的研究,大部分是在Thomas Read 实习期间完成的。需要对Thomas道个歉,花了这么长时间来写这篇文章。
让我们开始吧。为了激励大家,我们将从一些实验结果开始,来支持我们的观点,即超参数空间中存在几乎是平坦的方向。我们在超参数空间中绘制了上一篇文章中的最终网络在CIFAR10的测试精度的二维图。
在每种情况下,x轴上的学习率指的是前一篇文章的策略中最大的学习率。第二个超参数(batch size、momentum或weight decay)在每个图的y轴上变化。其他超参数固定为:batch size=512,momentum=0.9,weight decay=5e-4。为了保持动态范围,测试精度提高到91%。每个数据点是三次运行的平均值。
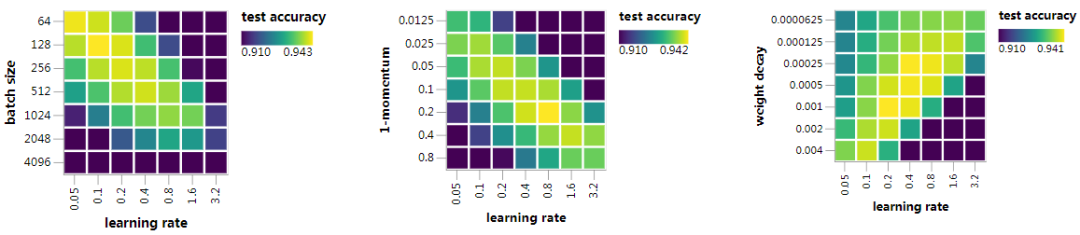
每个图都有一个最大测试精度岭,指向45°轴,在对数参数空间中跨度很大。最大的学习速率我们用λ表示,batch size用N表示,momentum用 ρ表示,weight decay用α表示。画出来的图提供了明显的证据,说明λ/N,λ/(1−ρ)或λα方向上几乎是平坦保持不变的。
我们讨论了让λ/N固定,使用不同的神经网络,在本系列的第二篇中就是这样。这就是所谓的“线性缩放规则”,在其他地方已经讨论过很多次了。我们以前没有绘制超参数空间上的测试精度图,现在为了完整起见,我们这样做了,并强调了这个启发式在这里的应用。我们之前讨论了为什么在曲率效应不占主导地位的当前情况下会出现这样的规则。
我们很快会对另外两个平坦方向提供类似的解释。这些论证很简单,并且让人有信心在实践中应用这些启发式。在此之前,让我们看看这些平面方向的知识如何简化超参数搜索。
假设我们忘记了超参数设置,我们使用当前网络在24个epochs内达到94%的测试精度。我们确定了网络的选择,将batch size设置为512,并假设学习率策略在前5个周期内线性增长,其余时间线性衰减。我们希望复原的超参数目标是最大学习速率λ,Nesterov动量ρ,和weight decay α。我们假设我们对这些超参数的合理值一无所知,随便选了一组参数λ= 0.001,ρ= 0.5,α= 0.01,测试的准确率为30.6%,24个epochs。
为了优化这些超参数,我们将遵循一种“循环坐标下降”的方法,在这种方法中,我们每次只调优一个参数,使用非常粗糙的行搜索(将其加倍或减半,并进行再训练,直到情况变得更糟)。现在,让(λ,ρ,α)空间中的坐标下降不是很好,因为在坐标轴±45°的方向上几乎是平坦的。有个更好的主意,就是在(λα/(1−ρ),ρ,α)空间中做下降,将几乎平坦的方向与坐标轴对齐。这张图片可能会有帮助:

在进行循环之前,我们首先优化了学习率λ,然后是动量ρ(我们对1−ρ而不是ρ进行减半或加倍),然后是权值衰减α。重要的是,当我们优化ρ或α的时候,通过调整适当的λ,我们保持λα/(1−ρ)固定不变。当情况停止改善时,我们就停止了整个过程。
以下是基于总共22次训练运行后的搜索结果。这一过程可以直接自动化,并提高效率。如果有更合理的初始值,我们可以在不到10次运行中完成。表中的第一行显示了初始参数设置和随后的线路优化的结果λ,ρ或α,在后者的两种情况,保持λα/(1−ρ)固定:
| train run | λ | ρ | α | λα/(1−ρ) | test acc |
|---|---|---|---|---|---|
| 0 | 0.001 | 0.5 | .01 | .00002 | 30.6% |
| 10 | 0.256 | 0.5 | .01 | .00512 | 93.0% |
| 13 | 0.128 | 0.75 | .01 | .00512 | 93.2% |
| 17 | 1.024 | 0.75 | .00125 | .00512 | 93.9% |
| 20 | 0.512 | 0.75 | .00125 | .00256 | 94.1% |
| 22 | 0.256 | 0.875 | .00125 | .00256 | 94.2% |
注意,在第一步之后,λα/(1−ρ)已经稳定在其最终值的两倍。优化得到的超参数相当接近我们之前的手动选择(λ=0.4,ρ=0.9,α=0.0005),λα/(1−ρ)λ也接近之前的值0.4×0.0005/(1−0.9)=0.002,使用我们加倍减半计划,最终测试的准确率为94.2%,这是基于单次运行的结果,与我们之前的94.08%相比,没有显著的统计学意义。
有人可能认为,在更高的参数分辨率下进一步优化——并使用多次训练来降低噪音——将比我们的基线训练得到改善。我们没有成功地这样做。超参数空间中的两个方向在这一点上是非常平坦的,而另一个方向也非常接近最优,几乎是平坦的。综上所述,超参数空间存在一个大且易于识别的区域,其性能在统计噪声水平下难以区分。
到目前为止,我们已经提出了超参数空间中存在接近平坦的方向的实验证据,并证明了在调整超参数时了解这些方向的实用价值。但是仍然需要解释平坦的方向从何而来。
对于动量ρ,原因解释起来比较简单。我们这个观点是在SGD普通动量而不是Nesterov动量的情况下提出的,因为方程稍微简单点。类似的逻辑适用于这两种情况。
v←ρv+g
接下来我们使用v来更新权值w:
w←w−λv
λ和ρ学习率和动量参数。
让我们关注在单个时间步长t上计算的梯度gt。首先,通过权重−λt加到wt中,在下一个时间步上,通过权重−ρλt+1加到wt+1上。随着时间的推移,梯度gt对更新的权重的总贡献逐渐增大。
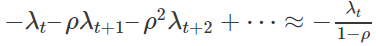
这里,我们假定λt是几乎恒定的,这个贡献是与在时间尺度对几何级数进行求和相关的。
现在假设我们对λ和ρ做一个小变化,保持λ/(1−ρ)固定。这将导致给定梯度gt的总贡献相同,但参数更新的时间尺度略有变化。如果我们可以假设延迟更新只会产生很小的影响(对于足够小的学习率来说也是如此),那么这两种情况下的动态都是相似的。
曲率效应在当前的训练机制中处于次主导地位,因为学习率受到其他效应的限制,正如前面所解释的那样。因此改变ρ同时保持λ/(1−ρ)固定,只是对训练有非常微弱的影响。
动量就讲到这里。接下来我们想解释为什么当我们改变权值衰减α以及学习率λ,保持λα固定的时候,训练变化缓慢。
w可以进行缩放而不改变损失函数。这对于我们网络中的所有卷积权值都是成立的,因为每个卷积层后面都直接跟着一个batch norm,从而抵消了权值尺度缩放的影响。最后的分类器或后面的一些batch norm层并不是这样,但是对这些层进行尺度缩放会产生足够温和的效果,从而使结论在实践中继续保持良好的效果。
设w为一组参数,w尺度缩放时损失不变。我们考虑纯的不带动量的SGD,但使用权值衰减,参数更新分为权值衰减步骤:
w←(1–λα)w
和梯度下降步骤:
w←w−λg
(细心的读者会注意到,权值衰减步骤只是w的尺度缩放,因此从损失函数的角度来看是一个无用的操作。稍后将详细介绍。)
假设我们决定自由选择w的尺度来进行缩放后的w的训练。假设我们决定使用3w。我们计算的梯度g变小了3倍(因为参数的固定变化对新尺度下的w影响较小)。另一方面,为了像以前一样更新w,我们希望更新步伐比以前大3倍。这对权值衰减步骤没什么问题,因为随着w的缩放,权值衰减也缩放了,但我们需要调整λ,放大9倍,以弥补变小的梯度和缩放后的更新步伐,接着,我们需要减小α9倍,以弥补权值衰减步骤中λ的变化。总之,为了让参数尺度对称,如果我们把权值w通过缩放因子r进行缩放,就会有一个损失和训练动态的精确对称,学习率通过r2缩放,而权值衰减通过r-2缩放,从而保持λα固定。
这对我们有什么帮助呢?实际上我们快做完了。我们已经看到,改变λ和α,并使λα固定,相当于改变初始化权重的尺度。这种初始化的变化不会改变损失,如果我们幸运的话,随着时间的推移,对训练的影响应该会逐渐减小。让我们更详细地理解它。
假设我们在某个大尺度上初始化权重。接下来会发生什么?就梯度更新步骤而言,权重的大尺度相当于很小的学习率。重量衰减的步骤像正常一样进行,并逐渐缩小权重。当权值达到足够小的尺度时,梯度更新开始变得重要,并平衡了权值衰减的收缩效应。如果权重开始时过小,则会发生相反的动态,梯度更新会主导权重衰减项的重要性,直到权重比例恢复平衡。
对于这个观点来说,梯度更新(平均而言)会导致权重尺度的增加,这一点很重要,因为否则的话,就没有什么可以阻止权值衰减了,将权重缩小到零,并使动态失去稳定。事实上,由于我们假设损失对权值的尺度缩放是不变的,所以梯度g在平行于w的方向上没有分量,而g正交于w。利用毕达哥拉斯定理,梯度的更新使w的范数增大。在SGD +动量的情况下,论证的方法不同,但结果是一样的。关于这一点的更多信息,将在下一篇文章中讨论。
所有这些的结论如下。在batch norm存在下,权值衰减对有效步长起着“稳定的控制机制”的作用。如果梯度更新过小,权值衰减会缩小权值并增大梯度步长,直到恢复平衡。当梯度更新过大时,则会发生相反的情况。
选择初始权值尺度和学习率λ,并不能很好的长期控制这种动态平衡。在过了开始的一个时期之后,梯度更新的步伐的尺度由权值衰减率决定,而权值衰减率是λα唯一确定的函数。如果我们改变λ和α,持有λα固定,学习率动态对于大多数的训练是没有影响的,这几乎产生了参数空间在对应方向是几乎平坦的。
在第6部分中,我们将继续研究权值,并了解为什么超参数设置在架构之间能够很好地转换。

—END—
英文原文:https://myrtle.ai/how-to-train-your-resnet-5-hyperparameters/

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!![]()
这篇关于如何快速高效的训练ResNet,各种奇技淫巧(五):超参数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




