本文主要是介绍TEA: Temporal Excitation and Aggregation for Action Recognition 论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
TEA: Temporal Excitation and Aggregation for Action Recognition 论文阅读
- Abstract
- 1. Introduction
- 2. Related Works
- 3. Our Method
- 3.1. Motion Excitation (ME) Module
- 3.1.1 Discussion with SENet
- 3.2. MultipleTemporal Aggregation(MTA) Module
- 3.3. Integration with ResNet Block
- 4. Experiments
- 5. Conclusion
文章信息:

原文链接:https://arxiv.org/abs/2004.01398
源码:https://github.com/Phoenix1327/tea-action-recognition
发表于:CVPR 2020
Abstract
时间建模对于视频中的动作识别至关重要。它通常考虑了短期运动和长期聚合。在本文中,我们提出了一个称为时间激励与聚合(TEA)块,包括一个运动激励(ME)模块和一个多重时间聚合(MTA)模块,专门设计用于捕获短期和长期时间演变。特别是,对于短期运动建模,ME模块从时空特征中计算特征级的时间差异。然后利用这些差异来激发特征的运动敏感通道。先前工作中的长期时间聚合通常是通过堆叠大量的局部时间卷积来实现的。每个卷积一次处理一个局部时间窗口。相反,MTA模块提出将局部卷积变形为一组子卷积,形成一个分层残差架构。在不引入额外参数的情况下,特征将通过一系列子卷积进行处理,每个帧都可以与邻域完成多次时间聚合。因此,时间维度的最终等效感受野相应地被扩大,能够对远距离帧的长期时间关系进行建模。TEA块的两个组件在时间建模中是互补的。最后,我们的方法在几个动作识别基准测试中以低FLOPs取得了令人印象深刻的结果,例如Kinetics,Something-Something,HMDB51和UCF101,这证实了它的有效性和效率。
1. Introduction
动作识别是视频任务中的一个基础问题。在智能监控、自动驾驶、个性化推荐和娱乐等视频应用中,它变得越来越重要。虽然视觉外观(及其上下文)对于动作识别很重要,但建模时间结构也很重要。时间建模通常以不同的尺度呈现(或被认为呈现):
1)在相邻帧之间的短程运动和
2)在大尺度上的长程时间聚合。
有许多工作考虑了其中的一个或两个方面,特别是在当前深度CNN时代。然而,它们仍然存在一些差距,问题远未解决,即如何有效高效地建模具有显著变化和复杂性的时间结构仍然不清楚。
对于短程运动编码,大多数现有方法首先提取手工制作的光流,然后将其馈送到基于2D CNN的两流框架中进行动作识别。这样的两流架构分别处理RGB图像和光流。光流的计算耗时且存储需求量大。特别是,空间和时间特征的学习是隔离的,并且融合仅在后期层进行。为了解决这些问题,我们提出了一个运动激发(ME)模块。我们的模块不采用像素级光流作为额外的输入模态,并将时间流的训练与空间流的训练分开,而是可以将运动建模整合到整个时空特征学习方法中。具体来说,首先在相邻帧之间计算特征级的运动表示。然后利用这些运动特征产生调制权重。最后,可以使用这些权重来激发帧原始特征中的运动敏感信息。通过这种方式,网络被迫发现和增强捕获不同信息的信息化时间特征。
对于长程时间聚合,现有方法要么
1)采用2D CNN骨干提取逐帧特征,然后利用简单的时间最大/平均池化来获得整个视频表示。这样简单的汇总策略会导致时间信息的丢失/混淆;
或者2)采用局部3D/(2+1)D卷积操作处理局部时间窗口。长程时间关系是通过在深度网络中重复堆叠局部卷积来间接建模的。然而,重复大量的局部操作会导致优化困难,因为信息需要在远距离帧之间的长路径上传播。
为了解决这个问题,我们引入了多重时间聚合(MTA)模块。MTA模块也采用(2+1)D卷积,但一组子卷积取代了MTA中的1D时间卷积。子卷积形成一个分层结构,相邻子集之间有残余连接。当时空特征通过模块时,特征与相邻帧进行了多次信息交换,等效的时间接受域因此增加了多次,以建模长程时间动态。
提出的ME模块和MTA模块被插入到标准的ResNet块中,以构建Temporal Excitation and Aggregation (TEA)块,并通过堆叠多个块来构建整个网络。获得的模型效率高:得益于轻量级配置,TEA网络的FLOPs控制在较低水平(仅比2D ResNet多1.06倍)。所提出的模型也是有效的:TEA的两个组成部分是互补的,在赋予网络短程和长程时间建模能力方面相互合作。总之,我们方法的主要贡献有三个方面:
- 运动激励(ME)模块,将短程运动建模与整个时空特征学习方法相结合。
- 多重时序聚合(MTA)模块,有效地扩大了长程时间建模的时间感受野。
- 两个提出的模块都简单轻量,并且可以轻松集成到标准ResNet块中,以合作进行有效和高效的时间建模。
2. Related Works
随着深度学习方法在基于图像的识别任务上取得了巨大成功,一些研究人员开始探索将深度网络应用于视频动作识别任务。其中,Karpathy等人提出了将单个2D CNN模型应用于视频的每一帧,并探索了几种融合时间信息的策略。然而,该方法未考虑帧间的运动变化,并且最终性能不如手工特征的算法。Donahue等人使用LSTM模型对2D CNN特征进行聚合以建模时间关系。在这种方法中,每帧的特征提取是独立的,而且只考虑了高级别的2D CNN特征用于学习时间关系。
现有的方法通常采用两种方法来提高时间建模能力。第一种是基于Simonyan和Zisserman提出的两流架构。该架构包含一个空间2D CNN,从帧中学习静态特征,以及一个用光流形式建模运动信息的时间2D CNN。两个流的训练是分开的,并且对视频的最终预测是在两个流上进行平均。许多后续工作已经扩展了这样的框架。[9, 8]探索了不同的中间级别组合策略来融合两个流的特征。TSN提出了稀疏采样策略来捕获长距离视频剪辑。所有这些方法都需要额外的计算和存储成本来处理光流。此外,不同帧之间和两种模态之间的交互受到限制,通常仅发生在后期层。相反,我们提出的方法放弃了光流提取,并通过计算时间差异来学习近似的特征级别运动表示。运动编码可以与时空特征的学习相结合,并用于发现和增强其对运动敏感的成分。
最近的作品STM [22]也尝试对特征级别的运动特征进行建模,并将运动建模插入到时空特征学习中。我们的方法与STM的不同之处在于,STM直接将时空特征和运动编码加在一起。相比之下,我们的方法利用运动特征对特征进行重新校准,以增强运动模式。
另一种典型的视频动作识别方法是基于3D CNN及其(2+1)D CNN变体 [38, 36, 3, 40, 46]。这一系列工作的首个作品是C3D [38],它对相邻帧进行3D卷积,以统一的方式共同建模空间和时间特征。为了利用预训练的2D CNN,Carreira和Zisserman [3] 提出了I3D,将预训练的2D卷积膨胀到3D卷积中。为了减少3D CNN的大量计算,一些工作提出将3D卷积分解为2D空间卷积和1D时间卷积 [36, 5, 27, 14, 31, 39],或者利用2D CNN和3D CNN的混合 [40, 47, 54]。在这些方法中,长程时间连接理论上可以通过堆叠多个局部时间卷积来建立。然而,在大量的局部卷积操作之后,来自远距离帧的有用特征已经被削弱,不能很好地捕获。为了解决这个问题,T3D [5] 提出采用密集连接结构 [20],并结合了不同的时间窗口 [37]。Nonlocal模块 [45] 和stnet [14] 应用了自注意机制来建模长程时间关系。这些尝试都伴随着额外的参数或耗时的操作。与这些工作不同,我们提出的多重时间聚合模块简单高效,不需要引入额外的运算符。
3. Our Method
所提方法的框架如图1所示。输入视频长度可变,使用TSN提出的稀疏时间采样策略进行采样 [44]。首先,将视频均匀分成T个段。然后,从每个段中随机选择一帧,形成具有T帧的输入序列。对于时空建模,我们的模型基于2D CNN ResNet [15],通过堆叠多个Temporal Excitation and Aggregation (TEA)模块构建而成。TEA模块包含一个运动激发 (ME) 模块用于激发运动模式,以及一个多重时间聚合 (MTA) 模块用于建立长程时间关系。在模型末端,遵循之前的方法 [44, 27],采用简单的时间平均池化来对所有帧的预测进行平均。
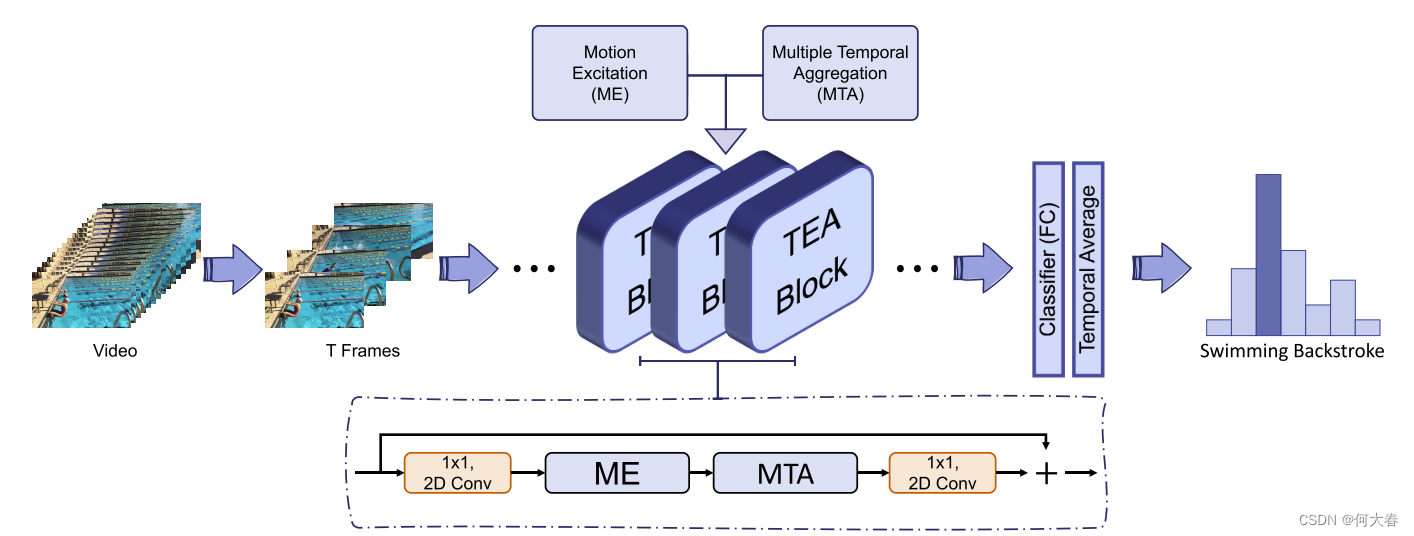
图1. 提出的用于动作识别的方法框架。采用稀疏采样策略[44]从视频中抽样T帧。使用2D ResNet [15]作为骨干网络,并将ME和MTA模块插入到每个ResNet块中以形成TEA块。简单的时间池化用于对整个视频的动作预测进行平均。
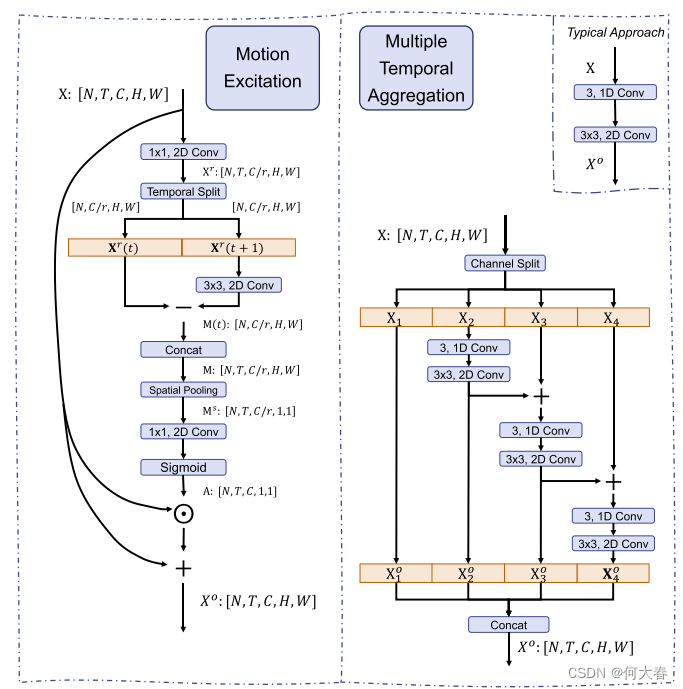
图2.运动激发(ME)模块(左侧面板)和多时间聚合(MTA)模块(右侧面板)的实现。
3.1. Motion Excitation (ME) Module
动作度量了连续两帧之间的内容位移,主要反映了实际的动作。许多先前的工作利用运动表示进行动作识别 [44, 3]。然而,大多数方法只考虑像素级的光流形式的运动模式,并将运动的学习与时空特征的学习分开。与此不同的是,在提出的运动激发(ME)模块中,运动建模从原始的像素级扩展到了较大范围的特征级别,使得运动建模和时空特征学习融合到了一个统一的框架中。
ME模块的架构如图2的左侧所示。输入时空特征X的形状为[N, T, C, H, W],其中N是批量大小。T和C分别表示时间维度和特征通道。H和W对应于空间形状。提出的ME模块的直觉是,在所有特征通道中,不同的通道会捕获不同的信息。一部分通道倾向于建模与背景场景相关的静态信息;其他通道主要关注描述时间差异的动态运动模式。对于动作识别,让模型发现并增强这些对运动敏感的通道是有益的。
首先采用一个1×1的二维卷积层对输入特征X进行通道数的降维,以提高效率。
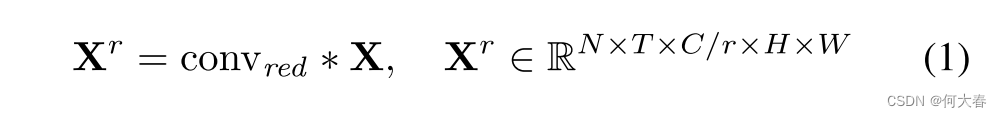
其中, X r \mathbf{X}^r Xr 表示通道减少后的特征。 ∗ * ∗ 表示卷积操作。 r = 16 r=16 r=16 是减少比率。
在时间步 t t t处,特征级别的运动表示被近似地视为两个相邻帧 X r ( t ) \mathbf{X}^r(t) Xr(t)和 X r ( t + 1 ) \mathbf{X}^r(t+1) Xr(t+1)之间的差异。而不是直接减去原始特征,我们提出首先对特征进行逐通道的转换,然后利用转换后的特征计算运动。形式上,
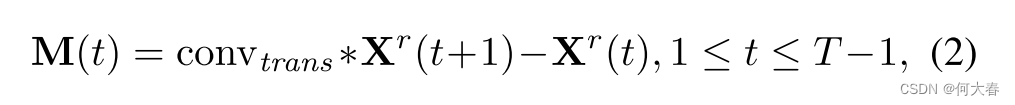
其中, M ( t ) ∈ R N × C / r × H × W \mathbf{M}(t)\in\mathcal{R}^{N\times C/r\times H\times W} M(t)∈RN×C/r×H×W 表示时间 t t t的运动特征。 conv t r a n s \text{conv}_{trans} convtrans 是一个3×3的二维逐通道卷积层,用于对每个通道执行转换。
我们将时间步结束时的运动特征表示为零,即 M ( T ) = 0 \mathbf{M}(T)=0 M(T)=0,并通过连接所有运动特征 [ M ( 1 ) , … , M ( T ) ] [\mathbf{M}(1),\ldots,\mathbf{M}(T)] [M(1),…,M(T)]构建最终的运动矩阵 M \mathbf{M} M。然后,我们使用全局平均池化层来总结空间信息,因为我们的目标是激发对运动敏感的通道,而详细的空间布局并不重要。
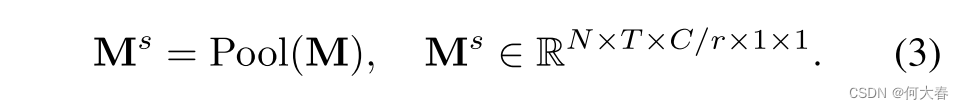
另外,我们使用一个 1 × 1 1\times1 1×1的二维卷积层conv e x p _{exp} exp来扩展运动特征的通道维度至原始通道维度 C C C,然后通过使用sigmoid函数可以得到运动注意力权重 A \mathbf{A} A。
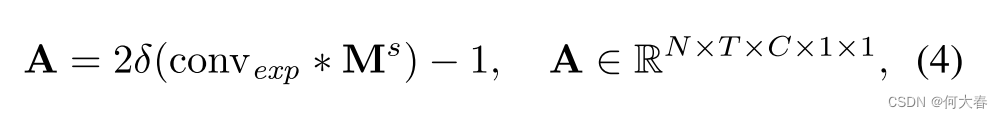
其中, δ \delta δ 表示 sigmoid 函数。
最后,该模块的目标是激发运动敏感的通道;因此,一种简单的方法是在输入特征 X X X和注意力权重 A \mathbf{A} A之间进行逐通道乘法。然而,这种方法会抑制静态背景场景信息,而这对于动作识别也是有益的。为了解决这个问题,在提出的基于运动的激发模块中,我们提出采用残差连接来增强运动信息,同时保留场景信息。

其中, X o \mathbf{X}^o Xo 是提出模块的输出,其中运动模式已经被激发和增强。符号 ⊙ \odot ⊙表示逐通道乘法。
3.1.1 Discussion with SENet
激发方案最初由SENet [19, 18] 提出,用于图像识别任务。我们想要突出我们与SENet的区别。
- SENet设计用于基于图像的任务。当SENet应用于时空特征时,它独立处理视频的每一帧,而不考虑时间信息。
- SENet是一种自门控机制[42],得到的调制权重被用来增强特征X的信息通道。而我们的模块旨在增强特征中的运动敏感成分。
- 无用的通道在SENet中将被完全抑制,但通过引入残差连接,我们的模块可以保留静态背景信息。
3.2. MultipleTemporal Aggregation(MTA) Module
先前的动作识别方法[38, 36]通常采用局部时间卷积来同时处理相邻帧,而长期时间结构只能在具有大量堆叠局部操作的深度网络中建模。这是一种低效的方法,因为来自远处帧的优化信息已经被显著削弱,无法很好地处理。为了解决这个问题,我们提出了多时间聚合(MTA)模块,用于有效的长距离时间建模。MTA模块受到了Res2Net [10]的启发,在其中,时空特征和相应的局部卷积层被分成一组子集。这种方法是高效的,因为它不引入额外的参数和耗时的操作。在模块中,这些子集被构建为分层的残差架构,使得一系列子卷积逐步应用于特征,并相应地扩大了时间维度的等效感受野。
如图2的右上角所示,给定输入特征 X \mathbf{X} X,一个典型的方法是用单个局部时间卷积和另一个空间卷积来处理它。与此不同的是,我们沿着通道维度将特征分成四个片段,因此每个片段的形状变为 [ N , T , C / 4 , H , W ] [N, T, C/4, H, W] [N,T,C/4,H,W]。局部卷积也被分成多个子卷积。最后的三个片段分别用一个通道级时间子卷积层和另一个空间子卷积层进行顺序处理。每个子卷积层的参数量仅为原始参数的1/4。此外,在两个相邻片段之间添加了残差连接,将该模块从并行架构转变为分层级联架构。形式上 1 ^{1} 1
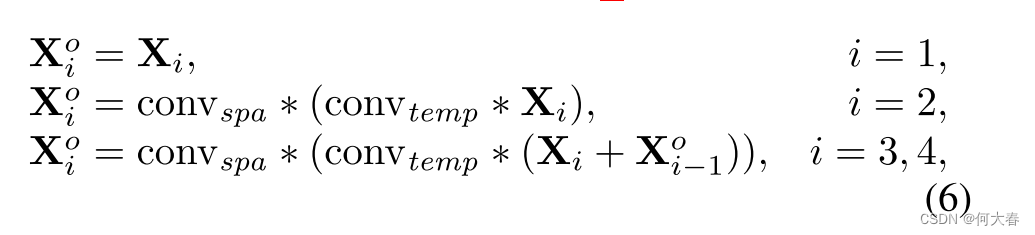
其中, X i o ∈ R N × T × C / 4 × H × W \mathbf{X}_i^o\in\mathbb{R}^{N\times T\times C/4\times H\times W} Xio∈RN×T×C/4×H×W 是第 i i i个片段的输出。conv t e m p _{temp} temp 表示1D通道级时间子卷积,其卷积核大小为3,而conv s p a _{spa} spa 表示 3 × 3 3\times3 3×3的二维空间子卷积。
在这个模块中,不同的片段具有不同的感受野。例如,第一个输出片段 X 1 o \mathbf{X}_1^o X1o的输出与输入片段 X 1 \mathbf{X}_1 X1相同;因此,其感受野为 1 × 1 × 1 1\times1\times1 1×1×1。通过按序聚合前面片段的信息,最后一个片段 X 4 o \mathbf{X}_4^o X4o的等效感受野已经扩大了三倍。最后,采用简单的串联策略来组合多个输出。
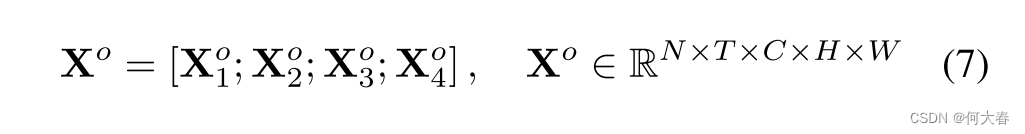
得到的输出特征 X o \mathbf{X}^o Xo涉及捕获不同时间范围的时空表示。它优于典型方法中使用单个局部卷积得到的局部时间表示。
3.3. Integration with ResNet Block
最后,我们描述如何将提出的模块集成到标准的ResNet块[15]中,以构建我们的时间激发和聚合(TEA)块。该方法如图3所示。为了计算效率,运动激发(ME)模块被集成到瓶颈层之后的残差路径中(第一个1×1的卷积层)。多时间聚合(MTA)模块被用来替换残差路径中的原始3×3卷积层。动作识别网络可以通过堆叠TEA块来构建。
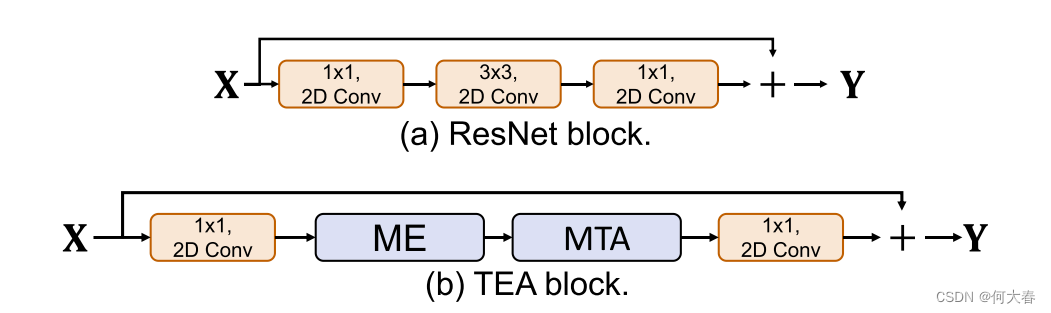
图3.运动激发(ME)模块放置在第一个1×1卷积层之后。多时间聚合(MTA)模块被用来替换3×3卷积层。
4. Experiments
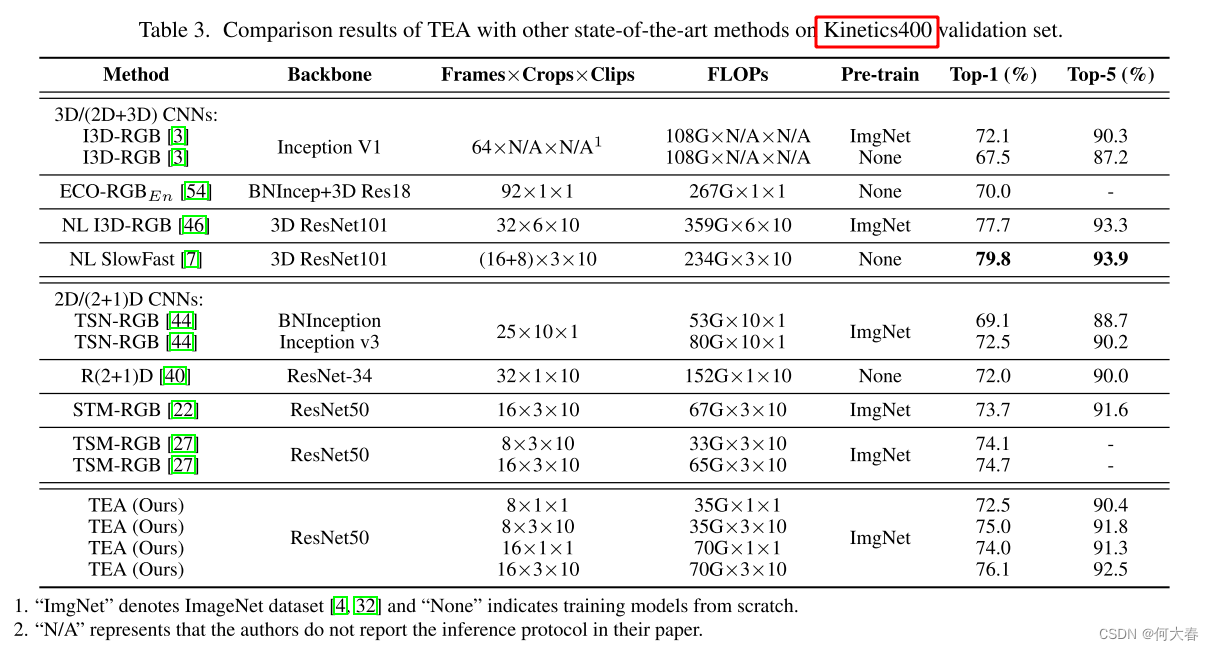
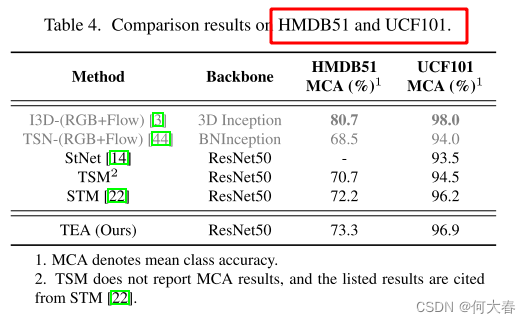
作者做了很多消融实验,感兴趣的可以看看原文,我自己以后有时间在看吧
5. Conclusion
在本文中,我们提出了时间激发和聚合(TEA)块,包括运动激发(ME)模块和多时间聚合(MTA)模块,用于短期和长期时间建模。具体而言,ME模块可以将运动编码插入到时空特征学习方法中,并增强时空特征中的运动模式。在MTA模块中,通过将局部卷积变形为一组子卷积来扩大等效的时间感受野,建立可靠的长期时间关系。这两个提出的模块被集成到标准的ResNet块中,并共同用于有效的时间建模。
这篇关于TEA: Temporal Excitation and Aggregation for Action Recognition 论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
