temporal专题

KDD 2024 时空数据(Spatio-temporal) ADS论文总结
2024 KDD( ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 知识发现和数据挖掘会议)在2024年8月25日-29日在西班牙巴塞罗那举行。 本文总结了KDD2024有关时空数据(Spatial-temporal) 的相关论文,如有疏漏,欢迎大家补充。 时空数据Topic:时空(交通)预测, 生成,拥堵预测,定价预

Apache-Flink深度解析-Temporal-Table-JOIN
在《JOIN LATERAL》中提到了Temporal Table JOIN,本篇就向大家详细介绍什么是Temporal Table JOIN。在ANSI-SQL 2011 中提出了Temporal 的概念,Oracle,SQLServer,DB2等大的数据库厂商也先后实现了这个标准。Temporal Table记录了历史上任何时间点所有的数据改动,Temporal Table的工作流程如下:

Learning Temporal Regularity in Video Sequences——视频序列的时间规则性学习
Learning Temporal Regularity in Video Sequences CVPR2016 无监督视频异常事件检测早期工作 摘要 由于对“有意义”的定义不明确以及场景混乱,因此在较长的视频序列中感知有意义的活动是一个具有挑战性的问题。我们通过在非常有限的监督下使用多种来源学习常规运动模式的生成模型(称为规律性)来解决此问题。体来说,我们提出了两种基于自动编码器的方法,以

GNN-第三方库:PyTorch Geometric Temporal【PyG的一个时间图神经网络扩展库】
PyTorch Geometric Temporal 是PyTorch Geometric(PyG)的一个时间图神经网络扩展库。它建立在开源深度学习和图形处理库之上。 GitHub源码:benedekrozemberczki/pytorch_geometric_temporal PyTorch Geometric Temporal由最先进的深度学习和参数学习方法组成,用于处理时空信号。 Py

hibernate @Temporal
最近在研究hibernate标注,但是用到@Temporal标注时,我一开始认为使用该标注后,该属性的值会被自动赋值。不需要在插入数据时,给该属性赋值,通过反复研究最后发现不是这样。 @Temporal标签的作用很简单: (1) 如果在某类中有Date类型的属性, 数据库中存储可能是’yyyy-MM-dd hh:MM:ss’要在查询时获得年月日,在该属性上标注@Temporal(Tem
Hibernate @temporal的使用说明
关于hibernate标注,用到@Temporal标注时,我一开始认为使用该标注后,该属性的值会被自动赋值。不需要在插入数据时,给该属性赋值,通过反复研究最后发现不是这样。 @Temporal标签的作用很简单: (1) 如果在某类中有Date类型的属性,数据库中存储可能是'yyyy-MM-dd hh:MM:ss'要在查询时获得年月日,在该属性上标注@Tempor

内涵:半监督学习之Temporal Ensembling For Semi-supervised Learning
一、 引言 这篇文章是ICLR2017的一篇文章,是半监督学习领域的一篇经典文章,以这篇文章作为进入半监督学习的一个切入点。 在这篇文章中,作者的将其工作描述为self-ensembling,而具体来讲有两点:1. Π model 2. temporal ensembling。 We describe two ways to implement self-ensembling, Π-
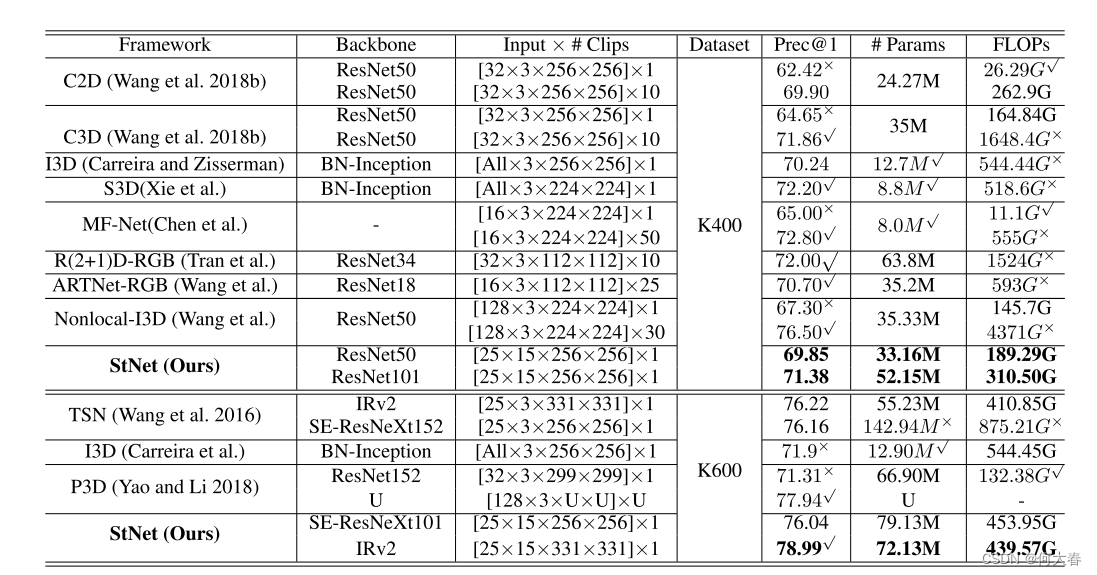
StNet: Local and Global Spatial-Temporal Modeling for Action Recognition 论文阅读
StNet: Local and Global Spatial-Temporal Modeling for Action Recognition 论文阅读 Abstract1 Introduction2 Related Work3 Proposed Approach4 Experiments5 Conclusion 文章信息: 原文链接:https://ojs.aaai.org
SAP HANA Temporal Table (历史表)
引自《SAP HANA 实战》 刘刚 舒戈 著 2.4.2.3 除了行、列存储的数据库表外,HANA还提供了 Temporal Table(简称历史表或临时表)。它和普通表的区别是所有历史表中的数据更新都不会对原始的数据记录进行真正的更新。 Temporal Table 的特点: 插入新数据记录,系统会插入新的数据更新就数据记录系统会插入更新后
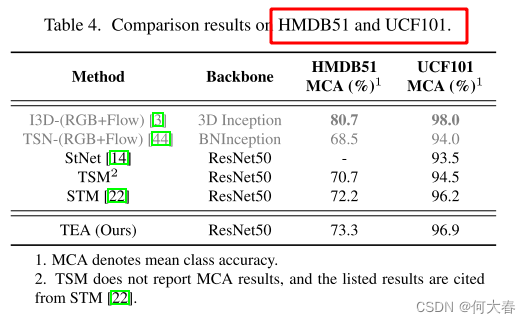
TEA: Temporal Excitation and Aggregation for Action Recognition 论文阅读
TEA: Temporal Excitation and Aggregation for Action Recognition 论文阅读 Abstract1. Introduction2. Related Works3. Our Method3.1. Motion Excitation (ME) Module3.1.1 Discussion with SENet 3.2. MultipleT
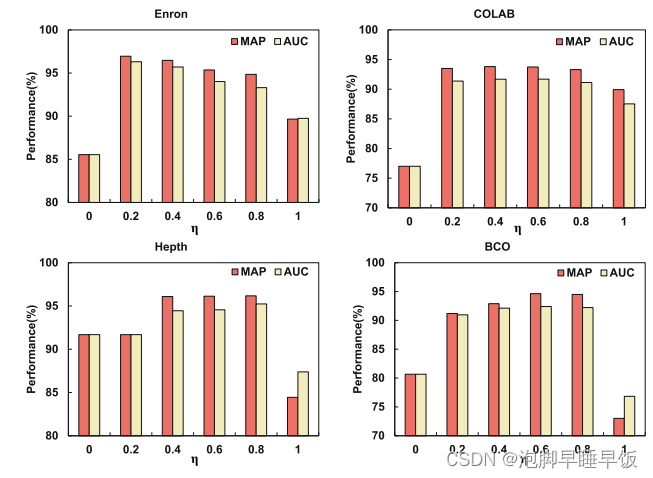
论文《Deep graph tensor learning for temporal link prediction》阅读
论文《Deep graph tensor learning for temporal link prediction》阅读 论文概况IntroductionRelated work动态图表示学习图张量表示 Preliminary张量生成建模 深度图张量学习模型A.基于图紧凑的空间表示B.时间模式表示C.时空特征聚合D.损失函数 实验消融实验 总结 论文概况 本文是2024年Inf
![[深度学习论文笔记]Temporal Localization of Fine-Grained Actions in Videos by Domain Transfer from Web Images](https://img-blog.csdnimg.cn/20190103195855504.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTAxNTg2NTk=,size_16,color_FFFFFF,t_70)
[深度学习论文笔记]Temporal Localization of Fine-Grained Actions in Videos by Domain Transfer from Web Images
[ACM MM 15] Temporal Localization of Fine-Grained Actions in Videos by Domain Transfer from Web Images Chen Sun, Sanketh Shettyy, Rahul Sukthankary and Ram Nevatia from USC & Google paper link Moti

强化学习:时序差分法【Temporal Difference Methods】
强化学习笔记 主要基于b站西湖大学赵世钰老师的【强化学习的数学原理】课程,个人觉得赵老师的课件深入浅出,很适合入门. 第一章 强化学习基本概念 第二章 贝尔曼方程 第三章 贝尔曼最优方程 第四章 值迭代和策略迭代 第五章 强化学习实例分析:GridWorld 第六章 蒙特卡洛方法 第七章 Robbins-Monro算法 第八章 多臂老虎机 第九章 强化学习实例分析:CartPole

稳态视觉诱发电位 (SSVEP) 分类学习系列 (4) :Temporal-Spatial Transformer
稳态视觉诱发电位分类学习系列:Temporal-Spatial Transformer 0. 引言1. 主要贡献2. 提出的方法2.1 解码的主要步骤2.2 网络的主要结构 3. 结果和讨论3.1 在两个数据集下的分类效果3.2 与基线模型的比较3.3 消融实验3.4 t-SNE 可视化 4. 总结欢迎来稿 论文地址:https://www.sciencedirect.com/s
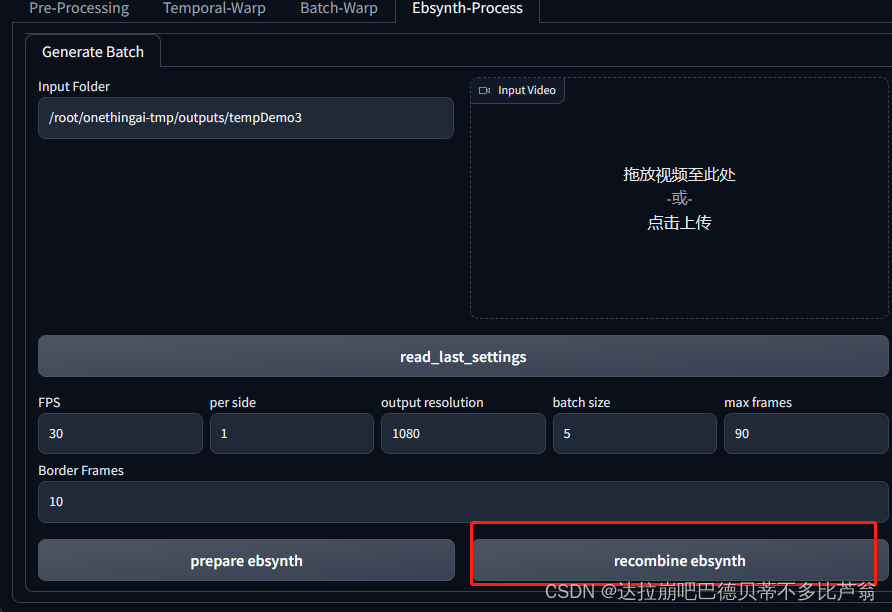
stable diffusion Temporal-kit和EbSynth视频转动画学习笔记
1、打开stable diffsuion webui 点击Temporal-kit 页签,再点击预处理pre-processing,上传视频 在工作目录下得到拆分的关键帧,在input目录里 打开图生图,输入正反描述词,其他配置如下 批量生成图片,找到最满意的那一张,复制那一张的种子号码 设置保存图片不带序列号 点击批量生成,输入Temporal-kit之前拆分开的
@Temporal的使用
最近在研究hibernate标注,但是用到@Temporal标注时,我一开始认为使用该标注后,该属性的值会被自动赋值。不需要在插入数据时,给该属性赋值,通过反复研究最后发现不是这样。 @Temporal标签的作用很简单: (1) 如果在某类中有Date类型的属性,数据库中存储可能是'yyyy-MM-dd hh:MM:ss'要在查询时获得年月日,在该属性上标注@Temporal(Temporal
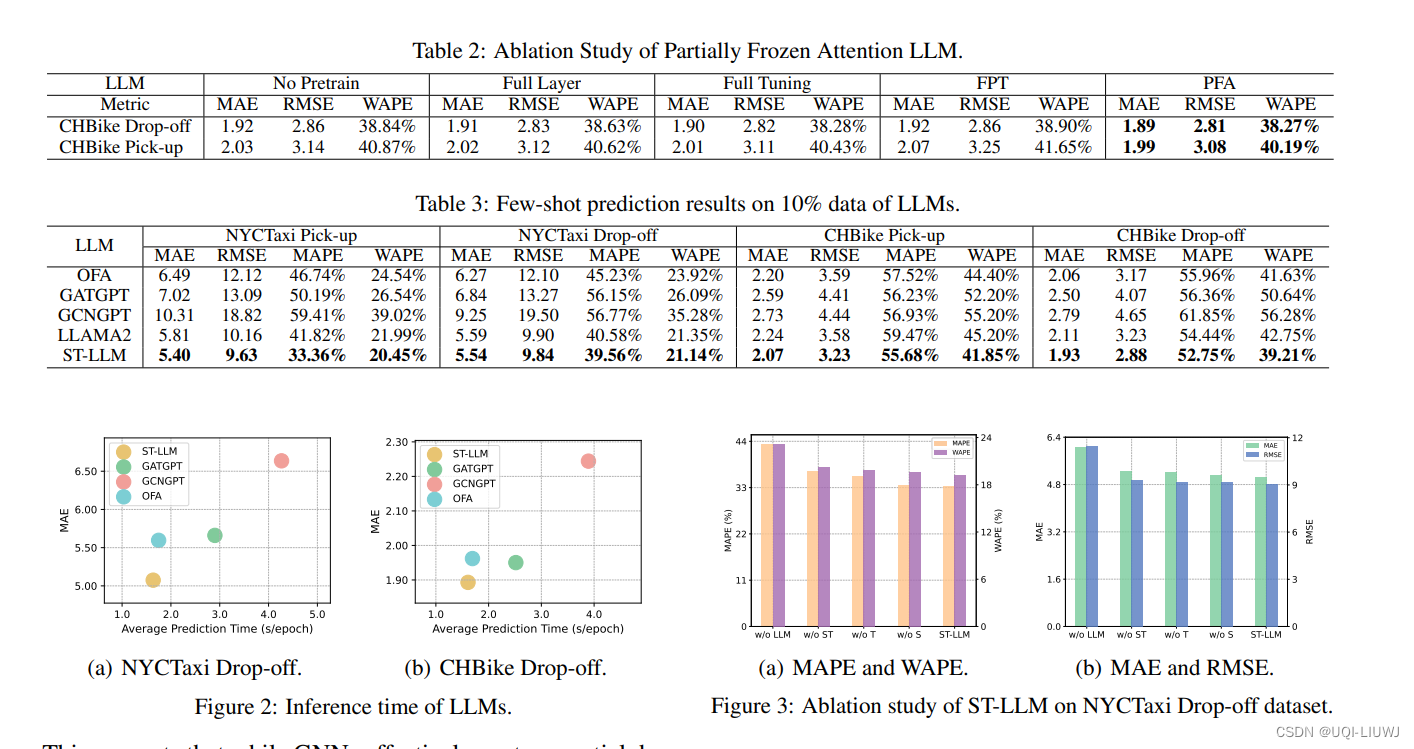
论文笔记:Spatial-Temporal Large Language Model for Traffic Prediction
arxiv 2024 时空+大模型 1 方法 2 结果
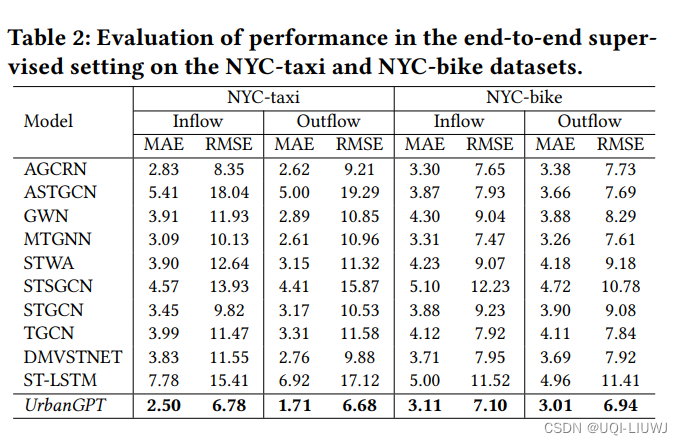
论文笔记:UrbanGPT: Spatio-Temporal Large Language Models
1 intro 时空预测的目标是预测并洞察城市环境随时间和空间不断变化的动态。其目的是预见城市生活多个方面的未来模式、趋势和事件,包括交通、人口流动和犯罪率。虽然已有许多努力致力于开发神经网络技术,以准确预测时空数据,但重要的是要注意,许多这些方法严重依赖于拥有足够的标记数据来生成精确的时空表示。 不幸的是,数据稀缺问题在实际的城市感知场景中普遍存在。在某些情况下,从下游场景收集任何标记数据变

机器学习之时序差分学习(Temporal Different Learning)
时序差分学习(Temporal Difference Learning)是一种强化学习算法,常用于解决序列决策问题。它结合了动态规划和蒙特卡洛方法的优点,在未来奖励和当前估计之间进行自举式更新。 该算法的核心思想是通过不断地估计状态值或动作值的更新来学习。具体来说,它通过比较当前状态的估计值和下一个状态(或下一步动作)的估计值加上未来奖励的总和,来调整当前状态的估计值。这种调整是通过一个称为TD
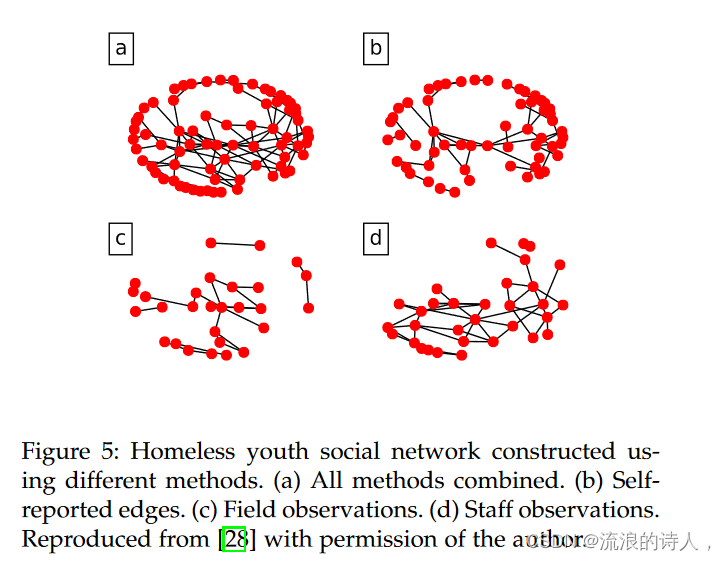
Influence maximization on temporal networks: a review
Abstract 影响力最大化(IM)是网络科学中的一个重要主题,其中选择一个小的种子集来最大化网络影响力的传播。最近,这个问题引起了网络结构随时间变化的时间网络的关注。这种动态变化的网络上的 IM 是本次评论的主题。我们首先将方法分为两个主要范式:单播种和多播种。在单次播种中,节点在扩散过程开始时激活,大多数方法要么有效地估计影响力扩散并使用贪婪算法选择节点,要么使用节点排名启发式。

Spatio-Temporal Pivotal Graph Neural Networks for Traffie Flow Forecasting
摘要:交通流量预测是一个经典的时空数据挖掘问题,具有许多实际应用。,最近,针对该问题提出了各种基于图神经网络(GNN)的方法,并取得了令人印象深刻的预测性能。然而,我们认为大多数现有方法忽视了某些节点(称为关键节点)的重要性,这些节点自然地与多个其他节点表现出广泛的联系。由于与其他节点相比,关键节点具有复杂的时空依赖性,因此对关键节点进行预测提出了挑战。在本文中,我们提出了一种基于 GNN 的
Flow Prediction in Spatio-Temporal Networks Based on Multitask Deep Learning
这是一篇郑宇团队2019年发表在 **IEEE Transactions on Knowledge and Data Engineering** 杂志上的一篇论文。 从题目来看文章提出的模型是一个多任务模型,在阅读文论之后发现是为了解决两个问题: ①流量预测;(同论文 [上一篇博文介绍的论文一样](https://blog.csdn.net/The_lastest/article/detai

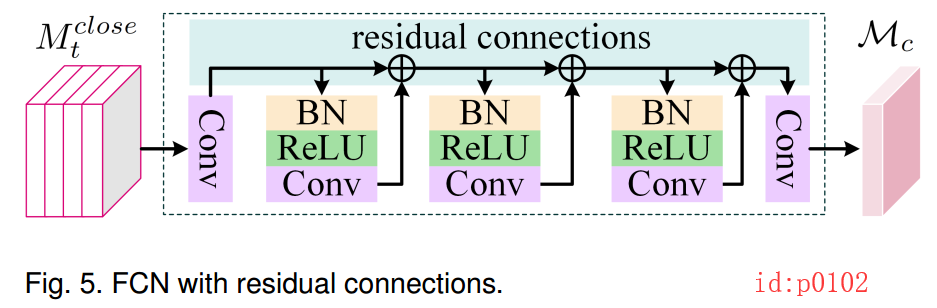
Deep Spatio-Temporal Residual Networks for Citywide Crowd Flows Prediction
本博文是对郑宇老师团队所提出的STResNet网络的一个略微扩充说明。本人自己在看完这篇论文的时候,感觉就一个字‘懵’。你说不懂吧,好像又明白点,你说懂吧又感觉有好多细节还是不清楚。好在该论文开放了源代码。经过对源代码的一番剖析,总算是弄懂之前不明白的一些细节。不过该源码是基于Keras实现的,由于本人之前一直使用Tensorflow,所以又对其利用tf进行了重构,代码整体上看起也来更加简洁,

机器学习小白阅读笔记:深度学习时序预测模型 Temporal Fusion Transformers
机器学习笔记:深度学习时序预测模型 Temporal Fusion Transformers 前言 由于接触的时序预测问题基本都来自于数字化转型期的企业,我经常发现,在解决实际时序预测问题的时候,大部分时候还是用树模型结合特征工程的思路,关键点往往都在数据和特征工程上,如果想要使用深度学习,有时候客户的数据量不满足,有时候客户的生产环境不允许。 我自己在一些时序预测问题,比如销量预测问题的比

Uniformer: Unified Transformer for Efficient Spatial-Temporal Representation Learning
Unified Transformer for Efficient Spatial-Temporal Representation Learning 1. Motivation2. Method2.1 MHRA:2.2 DPE2.3 FFN 1. Motivation 高维视频具有大量的局部冗余和复杂的全局依赖关系,而该研究主要是由3D卷积神经网络和视觉Transformer驱
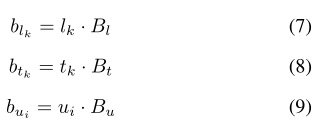
2020-ASRM: A Semantic and Attention Spatio-temporal Recurrent Model for Next Location Prediction
[1] Zhang X, Li B, Song C, et al. SASRM: A Semantic and Attention Spatio-temporal Recurrent Model for Next Location Prediction[C]//2020 International Joint Conference on Neural Networks (IJCNN). IEEE