本文主要是介绍AI之MLM:《MM-LLMs: Recent Advances in MultiModal Large Language Models多模态大语言模型的最新进展》翻译与解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AI之MLM:《MM-LLMs: Recent Advances in MultiModal Large Language Models多模态大语言模型的最新进展》翻译与解读
目录
《MM-LLMs: Recent Advances in MultiModal Large Language Models》翻译与解读
Abstract摘要
Figure 1: The timeline of MM-LLMs
1、Lntroduction引言
痛点:传统的MM模型,从头开始训练时会产生大量的计算成本
合理方法:采用基于现成的预训练的单模态基础模型的MM-LLMs=利用LLM作为认知动力+其它模态的基础模型提供的高质量的表示+多模态连接+协同推理
实战流程:多模态预训练(PT) + MM指令调优(IT)=优化对齐【模态间对齐+与人类意图对齐】
MM-LLM的发展历程:代表性GPT-4/Gemini,多模态内容理解和文本生成(Flamingo/BLIP-2/Kosmos-1/LLaVA/MiniGPT- 4/MultiModal-GPT/VideoChat/Video-LLaMA/IDEFICS/Fuyu-8B/Qwen-Audio)→特定模态的生成(引入图像生成的Kosmos-2/MiniGPT-5、引入语音生成的SpeechGPT)→AGI(模仿类似人类的任意模态转换,Visual-ChatGP/ViperGPT/MM- REACT/HuggingGPT/AudioGPT)→端到端的MM-LLM(NExT-GPT/CoDi-2)
本文的贡献:
模型架构5组件:模态编码器、输入投影器、LLM骨干、输出投影器和模态生成器
训练流程2阶段:MMPT→MMIT
SOTA总结及其发展趋势:26种最先进的MM-LLM,
MM-LLM在主流基准上的表现及其训练配方:
MM-LLM的未来潜力方向
2、Model Architecture模型架构,五个组件
Figure 2: The general model architecture of MM-LLMs and the implementation choices for each component.
2.1、Modality Encoder模态编码器
模态编码器公式
Visual Modality视觉模态:四种可选编码器,NFNet-F6、ViT、CLIP ViT、Eva-CLIP ViT
Audio Modality音频模态:C-Former、HuBERT、BEATs、whisper
3D Point Cloud Modality—3D点云模态:ULIP-2
ImageBind(统一的编码器):涵盖六种模态,包括图像、视频、文本、音频、热图等
2.2、Input Projector输入投影器:
简单实现(交替使用线性投影器和多层感知器)→复杂实现(比如Cross-attention、Q-Former、P-Former)
2.3、LLM Backbone骨干
MM-LLM可以继承LLMs的一些显著的特性:零样本泛化、少样本ICL、思维链(Chain-of-Thought, CoT)、指令遵循
PEFT(可调参数仅占比0.1%):前缀调优、适配器、LoRA
MM-LLM中常用的LLM:Flan-T5、ChatGLM 、UL2、Qwen、Chinchilla、OPT、PaLM、LLaMA、LLaMA-2和Vicuna
2.4、Output Projector输出投影器
2.5、Modality Generator模态生成器
3、Training Pipeline训练流程
3.1、MMPT预训练
3.2、MMIT指令调优
4、SOTA MM-LLMs
Flamingo、BLIP-2、LLaVA、MiniGPT-4、mPLUG-Owl、X-LLM、VideoChat、InstructBLIP、PandaGPT、PaLI-x
Video-LLaMA、Video-ChatGPT、Shikra、DLP、BuboGPT 、ChatSpot、Qwen-VL、NExT-GPT、MiniGPT-5
LLaVA-1.5、MiniGPT-v2、CogVLM、DRESS、X-InstructBLIP、CoDi-2、VILA
Trends in Existing MM-LLMs现有MM-LLM的趋势
Table 1: The summary of 26 mainstream MM-LLMs. I→O: Input to Output Modalities, I: Image, V: Video, A: Audio, 3D: Point Cloud, and T: Text. In Modality Encoder, “-L” represents Large, “-G” represents Giant, “/14” indicates a patch size of 14, and “@224” signifies an image resolution of 224 × 224. #.PT and #.IT represent the scale of the dataset during MM PT and MM IT, respectively. † includes in-house data that is not publicly accessible.
5、Benckmarks and Performance基准与性能
Training Recipes Firstly训练配方
6、Future Directions未来发展方向
More Powerful Models更强大的模型
More Challenging Benchmarks更具挑战性的基准
Mobile/Lightweight Deployment移动/轻量级的部署
Embodied Intelligence具身智能
Continual IT持续
7、Conclusion结论
Limitations限制
《MM-LLMs: Recent Advances in MultiModal Large Language Models》翻译与解读
| 地址 | 论文地址:https://arxiv.org/abs/2401.13601 GitHub地址:https://mm-llms.github.io/ |
| 时间 | 2024年1月25日 |
| 作者 | Duzhen Zhang, Yahan Yu, Chenxing Li, Jiahua Dong, Dan Su, Chenhui Chu, Dong Yu 腾讯人工智能实验室、京都大学等 |
| 总结 | 这篇论文系统性总结了目前多模态大语言模型(MM-LLMs)的研究进展。 论文主要介绍和分析了以下几个方面: >> 概述了MM-LLMs的设计形式,将模型架构分为5个部分:模态编码器、输入投影器、语言模型骨干、输出投影器和模态生成器。阐述了每一部分的实现选择。 >> 描述了MM-LLMs的训练流程,主要包括多模态预训练和多模态指令调整两个阶段。 >> 总结分析了26种主流的MM-LLMs模型,从模型架构、训练数据集规模等多个维度进行了对比。 >> 综合回顾了主要MM-LLMs在18个广泛使用的视觉语言评测集上的表现,并总结提炼出提升模型效果的重要训练方法。 >> 探讨了MM-LLMs未来发展的5大方向:构建更强大的模型、设计更具挑战性的评估集、移动端/轻量级部署、具备实体性的智能和持续性指令调整。 综上,该论文系统梳理了MM-LLMs的框架、模型、评估指标和未来研究方向,对其现状和发展趋势进行了全面而深入的总结,为相关领域的研究与进一步发展奠定了基础。 |
Abstract摘要
| In the past year, MultiModal Large Language Models (MM-LLMs) have undergone substan-tial advancements, augmenting off-the-shelf LLMs to support MM inputs or outputs via cost-effective training strategies. The resulting models not only preserve the inherent reasoning and decision-making capabilities of LLMs but also empower a diverse range of MM tasks. In this paper, we provide a comprehensive survey aimed at facilitating further research of MM-LLMs. Specifically, we first outline general design formulations for model architecture and training pipeline. Subsequently, we provide brief introductions of 26 existing MM-LLMs, each characterized by its specific formulations. Additionally, we review the performance of MM-LLMs on mainstream benchmarks and summarize key training recipes to enhance the potency of MM-LLMs. Lastly, we explore promising directions for MM-LLMs while con-currently maintaining a real-time tracking web-site1 for the latest developments in the field. We hope that this survey contributes to the ongoing advancement of the MM-LLMs domain. | 在过去的一年中,多模态大型语言模型(MM-LLM)取得了实质性的进展,通过成本有效的训练策略增强了现成的LLMs,以支持通过多模态输入或输出。所得到的模型不仅保留了LLM固有的推理和决策能力,而且还赋予了多样化的多模态任务以能力。本文对MM-LLM进行了全面的综述,旨在为MM-LLM的进一步研究提供参考。具体来说,我们首先概述了模型体系结构和训练流程的一般设计公式。随后,我们简要介绍了现有的26种MM-LLM,每种MM-LLM都有其特定的配方。此外,我们回顾了MM-LLM在主流基准上的表现,并总结了提高MM-LLM效能的关键训练方法。最后,我们探讨了MM-LLM的发展方向,同时维护了一个实时跟踪网站1,以了解该领域的最新发展。我们希望这项调查有助于MM-LLMs领域的持续发展。 |
GitHub地址:https://mm-llms.github.io/
Figure 1: The timeline of MM-LLMs

1、Lntroduction引言
痛点:传统的MM模型,从头开始训练时会产生大量的计算成本
合理方法:采用基于现成的预训练的单模态基础模型的MM-LLMs=利用LLM作为认知动力+其它模态的基础模型提供的高质量的表示+多模态连接+协同推理
实战流程:多模态预训练(PT) + MM指令调优(IT)=优化对齐【模态间对齐+与人类意图对齐】
| MultiModal (MM) pre-training research has wit-nessed significant advancements in recent years, consistently pushing the performance boundaries across a spectrum of downstream tasks (Li et al., 2020; Akbari et al., 2021; Fang et al., 2021; Yan et al., 2021; Li et al., 2021; Radford et al., 2021; Li et al., 2022; Zellers et al., 2022; Zeng et al., 2022b; Yang et al., 2022; Wang et al., 2022a,b). How-ever, as the scale of models and datasets continues to expand, traditional MM models incur substan-tial computational costs, particularly when trained from scratch. Recognizing that MM research op-erates at the intersection of various modalities, a logical approach is to capitalize on readily avail-able pre-trained unimodal foundation models, with a special emphasis on powerful Large Language Models (LLMs) (OpenAI, 2022). This strategy aims to mitigate computational expenses and en-hance the efficacy of MM pre-training, leading to the emergence of a novel field: MM-LLMs. MM-LLMs harness LLMs as the cognitive pow-erhouse to empower various MM tasks. LLMs contribute desirable properties like robust language generation, zero-shot transfer capabilities, and In-Context Learning (ICL). Concurrently, foun-dation models in other modalities provide high-quality representations. Considering foundation models from different modalities are individually pre-trained, the core challenge facing MM-LLMs is how to effectively connect the LLM with models in other modalities to enable collaborative infer-ence. The predominant focus within this field has been on refining alignment between modalities and aligning with human intent via a MM Pre-Training (PT) + MM Instruction-Tuning (IT) pipeline. | 近年来,多模态(MM)预训练研究取得了重大进展,不断推动下游任务的性能界限(Li et al., 2020;Akbari et al., 2021;Fang等人,2021;Yan等,2021;Li et al., 2021;Radford et al., 2021;Li et al., 2022;Zellers et al., 2022;Zeng等,2022b;Yang et al., 2022;Wang et al., 2022a,b)。然而,随着模型和数据集的规模不断扩大,传统的MM模型会产生大量的计算成本,特别是在从头开始训练时。认识到MM研究在各种模式的交叉点上运作,一个合理的方法是利用现成的预训练的单模态基础模型,特别强调强大的大型语言模型(LLMs)(OpenAI,2022)。该策略旨在减少计算费用并提高多模态预训练的效率,,从而引发了一个新兴领域:MM-LLMs。 MM-LLM利用LLM作为认知动力,为各种MM任务赋能。LLM提供了理想的特性,如强大的语言生成,零迁移能力和上下文学习(ICL)。与此同时,其他模态的基础模型提供了高质量的表示。考虑到不同模态的基础模型是单独预训练的,如何有效地将LLM与其他模式的模型连接起来,实现协同推理是MM-LLM面临的核心挑战。该领域的主要焦点是通过多模态预训练(PT) + MM指令调优(IT)流程来优化模态之间的对齐并与人类意图对齐。 |
MM-LLM的发展历程:代表性GPT-4/Gemini,多模态内容理解和文本生成(Flamingo/BLIP-2/Kosmos-1/LLaVA/MiniGPT- 4/MultiModal-GPT/VideoChat/Video-LLaMA/IDEFICS/Fuyu-8B/Qwen-Audio)→特定模态的生成(引入图像生成的Kosmos-2/MiniGPT-5、引入语音生成的SpeechGPT)→AGI(模仿类似人类的任意模态转换,Visual-ChatGP/ViperGPT/MM- REACT/HuggingGPT/AudioGPT)→端到端的MM-LLM(NExT-GPT/CoDi-2)
| With the debut of GPT-4(Vision) (OpenAI, 2023) and Gemini (Team et al., 2023), show-casing impressive MM understanding and gen-eration capabilities, a research fervor on MM-LLMs has been sparked. Initial research pri-marily focuses on MM content comprehension and text generation like (Open)Flamingo (Alayrac et al., 2022; Awadalla et al., 2023), BLIP-2 (Li et al., 2023c), Kosmos-1 (Huang et al., 2023c), LLaVA/LLaVA-1.5 (Liu et al., 2023e,d), MiniGPT- 4 (Zhu et al., 2023a), MultiModal-GPT (Gong et al., 2023), VideoChat (Li et al., 2023d), Video-LLaMA (Zhang et al., 2023e), IDEFICS (IDEFICS, 2023), Fuyu-8B (Bavishi et al., 2023), and Qwen-Audio (Chu et al., 2023b). In pursuit of MM-LLMs capable of both MM input and output (Aiello et al., 2023), some studies additionally explore the gen-eration of specific modalities, such as Kosmos- 2 (Peng et al., 2023) and MiniGPT-5 (Zheng et al., 2023b) introducing image generation, and SpeechGPT (Zhang et al., 2023a) introducing speech generation. Recent research endeavors have focused on mimicking human-like any-to-any modality conversion, shedding light on the path to artificial general intelligence. Some efforts aim to amalgamate LLMs with external tools to reach an approaching ‘any-to-any’ MM comprehen-sion and generation, such as Visual-ChatGPT (Wu et al., 2023a), ViperGPT (Surís et al., 2023), MM-REACT (Yang et al., 2023), HuggingGPT (Shen et al., 2023), and AudioGPT (Huang et al., 2023b). Conversely, to mitigate propagated errors in the cas-cade system, initiatives like NExT-GPT (Wu et al., 2023d) and CoDi-2 (Tang et al., 2023b) have devel-oped end-to-end MM-LLMs of arbitrary modalities. The timeline of MM-LLMs is depicted in Figure 1. | 随着GPT-4(Vision) (OpenAI, 2023年)和Gemini (Team et al., 2023年)的首次亮相,展示了令人印象深刻的多模态理解和生成能力,引发了对MM-LLM的研究热情。 >> 最初的研究主要集中在多模态内容理解和文本生成,如(Open)Flamingo (Alayrac et al., 2022;Awadalla等人,2023)、BLIP-2 (Li等人,2023c)、Kosmos-1 (Huang等人,2023c)、LLaVA/LLaVA-1.5 (Liu等人,2023e,d)、MiniGPT- 4 (Zhu等人,2023a)、MultiModal-GPT (Gong等人,2023)、VideoChat (Li等人,2023d)、Video-LLaMA (Zhang等人,2023e)、IDEFICS (IDEFICS, 2023)、Fuyu-8B (Bavishi等人,2023)、Qwen-Audio (Chu等,2023b)。 >> 为了追求能够同时实现多模态输入和输出的MM-LLM (Aiello等,2023),一些研究还探索了特定模态的生成,例如引入图像生成的Kosmos-2 (Peng等,2023)和MiniGPT-5 (Zheng等,2023b),以及引入语音生成的SpeechGPT (Zhang等,2023a)。 >> 最近的研究努力集中在模仿类似人类的任意模态转换,为通用人工智能的道路提供了光明。一些努力旨在将LLM与外部工具合并,以达到接近“任意到任意”的多模态理解和生成,例如Visual-ChatGPT (Wu等人,2023a)、ViperGPT (Surís等人,2023)、MM- REACT(Yang等人,2023)、HuggingGPT (Shen等人,2023)和AudioGPT (Huang等人,2023b)。 >> 相反,为了减轻级联系统中的传播误差,像NExT-GPT(Wu等人,2023d)和CoDi-2 (Tang等人,2023b)这样的计划已经开发了任意模式的端到端MM-LLM。MM-LLM的时间轴如图1所示。 |
本文的贡献:
模型架构5组件:模态编码器、输入投影器、LLM骨干、输出投影器和模态生成器
训练流程2阶段:MMPT→MMIT
SOTA总结及其发展趋势:26种最先进的MM-LLM,
MM-LLM在主流基准上的表现及其训练配方:
MM-LLM的未来潜力方向
| In this paper, we present a comprehensive survey aimed at facilitating further research of MM-LLMs. To provide readers with a holistic understanding of MM-LLMs, we initially delineate general design formulations from model architecture (Section 2) and training pipeline (Section 3). We break down the general model architecture into five compo-nents: Modality Encoder (Section 2.1), Input Pro-jector (Section 2.2), LLM Backbone (Section 2.3), Output Projector (Section 2.4), and Modality Gen-erator (Section 2.5). The training pipeline eluci-dates how to enhance a pre-trained text-only LLM to support MM input or output, primarily consist-ing of two stages: MM PT (Section 3.1) and MM IT (Section 3.2). In this section, we also provide a summary of mainstream datasets for MM PT and MM IT. Next, we engage in discussions of 26 State-of-the-Art (SOTA) MM-LLMs, each characterized by specific formulations, and summarize their de-velopment trends in Section 4. In Section 5, we comprehensively review the performance of major MM-LLMs on mainstream benchmarks and dis-till key training recipes to enhance the efficacy of MM-LLMs. In Section 6, we offer promising direc-tions for MM-LLMs research. Moreover, we have established a website (https://mm-LLMs.github.io) to track the latest progress of MM-LLMs and fa-cilitate crowd-sourcing updates. Finally, we sum-marize the entire paper in Section 7 and discuss related surveys on MM-LLMs in Appendix A. We aspire for our survey to aid researchers in gaining a deeper understanding of this field and to inspire the design of more effective MM-LLMs. | 本文对MM-LLM进行了全面的综述,旨在促进MM-LLM的进一步研究。为了让读者全面了解MM-LLM,我们首先从模型架构(第2节)和训练流程(第3节)描述一般设计公式开始概述。我们将一般模型架构分解为五个组件:模态编码器(第2.1节)、输入投影器(第2.2节)、LLM骨干(第2.3节)、输出投影器(第2.4节)和模态生成器(第2.5节)。训练流程阐述了如何将预训练的仅文本LLM改进为支持多模态输入或输出,主要包括两个阶段:MM PT(第3.1节)和MM IT(第3.2节)。在本节中,我们还提供了MM PT和MM IT的主流数据集的摘要。 接下来,我们讨论了26种最先进的(SOTA) MM-LLM,每种MM-LLM都具有特定的公式或配方特征,并在第4节中总结了它们的发展趋势。 在第5节中,我们全面回顾了主要MM-LLM在主流基准上的表现,并提炼出关键的训练配方,以提高MM-LLM的有效性。 在第6节中,我们提出了MM-LLM研究的有希望的方向。此外,我们建立了一个网站(https://mm-LLMs.github.io),以跟踪MM-LLM的最新进展,以追踪MM-LLMs的最新进展并促进众包更新。 最后,在第7节中,我们总结整篇论文并在附录A中讨论有关MM-LLMs的相关调查。我们希望我们的调查能帮助研究人员更深入地了解这一领域,激发设计更有效的MM-LLMs的灵感。 |
2、Model Architecture模型架构,五个组件
| In this section, we provide a detailed overview of the five components comprising the general model architecture, along with the implementation choices for each component, as illustrated in Fig-ure 2. MM-LLMs that emphasize MM understand-ing only include the first three components. During training, Modality Encoder, LLM Backbone, and Modality Generator are generally maintained in a frozen state. The primary optimization emphasis is on Input and Output Projectors. Given that Pro-jectors are lightweight components, the proportion of trainable parameters in MM-LLMs is notably small compared to the total parameter count (typi-cally around 2%). The overall parameter count is contingent on the scale of the core LLM utilized in the MM-LLMs. As a result, MM-LLMs can be efficiently trained to empower various MM tasks. | 在本节中,我们详细介绍了构成通用模型架构的五个组件,以及每个组件的实现选择,如图2所示。强调仅包含前三个组件的强调多模态理解的MM-LLMs。 在训练期间,模态编码器、LLM主干和模态生成器通常保持在冻结状态。主要的优化重点是输入和输出投影器。 鉴于投影器是轻量级组件,与总参数数量相比,MM-LLMs中可训练参数的比例明显较小(通常约为2%)。总体参数计数取决于MM-LLMs中使用的核心LLM的规模。因此,MM-LLMs可以有效地训练以赋予各种多模态任务能力。 |
Figure 2: The general model architecture of MM-LLMs and the implementation choices for each component.
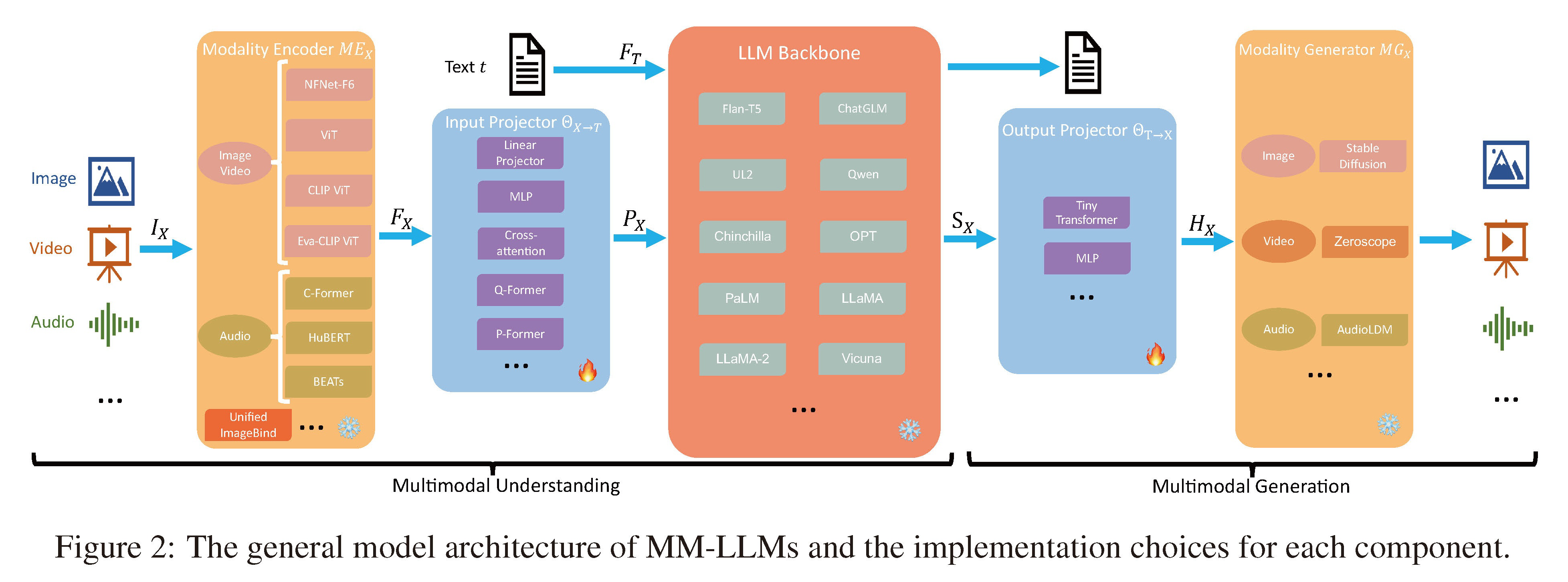
2.1、Modality Encoder模态编码器
模态编码器公式
| The Modality Encoder (ME) is tasked with encod-ing inputs from diverse modalities IX to obtain corresponding features FX , formulated as follows: Various pre-trained encoder options MEX exist for handling different modalities, where X can be image, video, audio, 3D, or etc. Next, we will offer a concise introduction organized by modality. | 模态编码器(ME)负责对来自多种模态的输入IX进行编码,以获得相应的特征FX,公式如下: 存在处理不同模态的各种预训练编码器MEX,其中X可以是图像、视频、音频、3D等。接下来,我们将按模态组织的方式提供简要介绍。 |
Visual Modality视觉模态:四种可选编码器,NFNet-F6、ViT、CLIP ViT、Eva-CLIP ViT
| Visual Modality For images, there are gener-ally four optional encoders: NFNet-F6 (Brock et al., 2021), ViT (Dosovitskiy et al., 2020), CLIP ViT (Radford et al., 2021), and Eva-CLIP ViT (Fang et al., 2023). NFNet-F6 is a normalizer-free ResNet (He et al., 2016), showcasing an adap-tive gradient clipping technique that allows training on extensively augmented datasets while achieving SOTA levels of image recognition. ViT applies the Transformer (Vaswani et al., 2017) to images by first dividing the image into patches. It then undergoes linear projection to flatten the patches, followed by encoding via multiple Transformer blocks. CLIP ViT builds connections between text and images, comprising a ViT and a text encoder. Utilizing a vast amount of text-image pairs, it opti-mizes ViT by contrastive learning, treating paired text and images as positive samples and others as negative ones. Its Eva version stabilizes the train-ing and optimization process of the massive CLIP, offering new directions in expanding and accelerat-ing the expensive training of MM base models. For videos, they can be uniformly sampled to 5 frames, undergoing the same pre-processing as images. | 对于图像,通常有四种可选编码器:NFNet-F6 (Brock等人,2021)、ViT (Dosovitskiy等人,2020)、CLIP ViT (Radford等人,2021)和Eva-CLIP ViT (Fang等人,2023)。 >> NFNet-F6是一种无归一化器的ResNet (He et al., 2016),展示了一种自适应梯度裁剪技术,允许在广泛增强的数据集上进行训练,同时实现SOTA级别的图像识别。 >> ViT将Transformer (Vaswani et al., 2017)应用于图像,首先将图像划分为小patch。然后进行线性投影使patch展平,然后通过多个Transformer块进行编码。 >> CLIP ViT在文本和图像之间建立连接,包括一个ViT和一个文本编码器。它利用大量的文本-图像对,通过对比学习来优化ViT,将配对的文本和图像视为正样本,其他为负样本。 >> 它的Eva版本稳定了大规模CLIP的训练和优化过程,为扩展和加速昂贵的多模态基础模型训练提供了新的方向。对于视频,可以均匀采样到5帧,并经过与图像相同的预处理。 |
Audio Modality音频模态:C-Former、HuBERT、BEATs、whisper
| Audio Modality is typically encoded by C-Former (Chen et al., 2023b), HuBERT (Hsu et al., 2021), BEATs (Chen et al., 2023f), and Whis-per (Radford et al., 2023). C-Former employs the CIF alignment mechanism (Dong and Xu, 2020; Zhang et al., 2022a) for sequence transduction and a Transformer to extract audio features. HuBERT is a self-supervised speech representation learning framework based on BERT (Kenton and Toutanova, 2019), achieved by the masked prediction of dis-crete hidden units. BEATs is an iterative audio pre-training framework designed to learn Bidirectional Encoder representations from Audio Transformers. | 音频模态通常由C-Former (Chen等人,2023b)、HuBERT (Hsu等人,2021)、BEATs (Chen等人,2023f)和whisper (Radford等人,2023)编码。 >> C-Former采用CIF对齐机制(Dong and Xu, 2020;Zhang等人,2022a)进行序列转换,并使用Transformer提取音频特征。 >> HuBERT是一个基于BERT的自监督语音表示学习框架(Kenton and Toutanova, 2019),通过对离散隐藏单元的掩模预测实现。 >> BEATs是一个迭代音频预训练框架,旨在从音频Transformer学习双向编码器表示。 |
3D Point Cloud Modality—3D点云模态:ULIP-2
| 3D Point Cloud Modality is typically encoded by ULIP-2 (Salesforce, 2022; Xu et al., 2023a,b) with a PointBERT (Yu et al., 2022) backbone. | 3D点云模态通常由ULIP-2编码(Salesforce, 2022;Xu et al., 2023a,b)采用PointBERT (Yu et al., 2022)骨干网。 |
ImageBind(统一的编码器):涵盖六种模态,包括图像、视频、文本、音频、热图等
| Moreover, to handle numerous heterogeneous modal encoders, some MM-LLMs, particularly any-to-any ones, use ImageBind (Girdhar et al., 2023), a unified encoder covering six modalities, including image, video, text, audio, heat map, etc. | 此外,为了处理众多异构模态编码器,一些MM-LLM,特别是任意对任意的MM-LLM,使用ImageBind (Girdhar等人,2023),这是一种统一的编码器,涵盖六种模态,包括图像、视频、文本、音频、热图等。 |
2.2、Input Projector输入投影器:
| The Input Projector ΘX→T is tasked with align-ing the encoded features of other modalities FX with the text feature space T . The aligned fea-tures as prompts PX are then fed into the LLM Backbone alongside the textual features FT . Given X-text dataset {IX , t}, the goal is to minimize the X-conditioned text generation loss Ltxt-gen: | 输入投影器ΘX→T的任务是将其他模态的编码特征FX与文本特征空间T对齐。对齐后的特征作为提示PX然后与文本特征FT一起输入LLM主干,给定X-text数据集{IX,t},目标是最小化X条件的文本生成损失Ltxt-gen: |
简单实现(交替使用线性投影器和多层感知器)→复杂实现(比如Cross-attention、Q-Former、P-Former)
| The Input Projector can be achieved directly by a Linear Projector or Multi-Layer Perceptron (MLP), i.e., several linear projectors interleaved with non-linear activation functions. There are also more complex implementations like Cross-attention, Q-Former (Li et al., 2023c), or P-Former (Jian et al., 2023). Cross-attention uses a set of trainable vectors as queries and the encoded features FX as keys to compress the feature se-quence to a fixed length. The compressed represen-tation is then fed directly into the LLM (Bai et al., 2023b) or further used for X-text cross-attention fusion (Alayrac et al., 2022). Q-Former extracts relevant features from FX , and the selected fea-tures are then used as prompts PX . Meanwhile, P-Former generates ‘reference prompts’, imposing an alignment constraint on the prompts produced by Q-Former. However, both Q- and P-Former require a separate PT process for initialization. | 输入投影器可以直接通过线性投影器或多层感知器(MLP)来实现,即交替使用几个线性投影器和非线性激活函数。 还有更复杂的实现,如交叉注意Cross-attention、Q-Former (Li et al., 2023c)或P-Former (Jian et al., 2023)。 >> Cross-attention使用一组可训练向量作为查询,并使用编码特征FX作为键将特征序列压缩到固定长度。然后将压缩后的表示直接输入LLM (Bai等人,2023b)或进一步用于X-text交叉注意融合(Alayrac等人,2022)。 >> Q-Former从FX中提取相关特征,然后将选中的特征作为提示PX。 >> 同时,P-Former生成“参考提示”,对Q-Former生成的提示施加对齐约束。然而,Q-和P-Former都需要单独的PT进程进行初始化。 |
2.3、LLM Backbone骨干
MM-LLM可以继承LLMs的一些显著的特性:零样本泛化、少样本ICL、思维链(Chain-of-Thought, CoT)、指令遵循
| Taking LLMs (Zhao et al., 2023c; Naveed et al., 2023; Luo et al., 2023) as the core agents, MM-LLMs can inherit some notable properties like zero-shot generalization, few-shot ICL, Chain-of-Thought (CoT), and instruction following. The LLM Backbone processes representations from var-ious modalities, engaging in semantic understand-ing, reasoning, and decision-making regarding the inputs. It produces (1) direct textual outputs t, and (2) signal tokens SX from other modalities (if any). These signal tokens act as instructions to guide the generator on whether to produce MM contents and, if affirmative, specifying the content to produce: where the aligned representations of other modal-ities PX can be considered as soft Prompt-tuning for the LLM Backbone. | 以LLMs(Zhao等人,2023c;Naveed等人,2023;Luo等人,2023)为核心智能体,MM-LLM可以继承一些显著的特性,如零样本泛化、少样本ICL、思维链(Chain-of-Thought, CoT)和指令遵循。 LLM主干处理来自各种模态的表示,参与关于输入的语义理解、推理和决策。它产生 (1)直接文本输出t, (2)来自其他模态(如果有的话)的信号令牌SX。 这些信号令牌作为指示,指导生成器是否生成MM内容,如果是肯定的,指定要生成的内容: 其中其他模态PX的对齐表示可以被认为是LLM主干的软提示调优。 |
PEFT(可调参数仅占比0.1%):前缀调优、适配器、LoRA
| Moreover, some research works have introduced Parameter-Efficient Fine-Tuning (PEFT) methods, such as Prefix-tuning (Li and Liang, 2021), Adapter (Houlsby et al., 2019), and LoRA (Hu et al., 2021). In these cases, the number of additional trainable parameters is excep-tionally minimal, even less than 0.1% of the total LLM parameter count. We provide an introduction to mainstream PEFT methods in Appendix B. | 此外,一些研究工作还引入了参数高效微调(PEFT)方法,如前缀调优(Li and Liang, 2021)、适配器(Houlsby等,2019)和LoRA (Hu等,2021)。在这些情况下,额外可训练参数的数量非常少,甚至不到LLM参数总数的0.1%。我们在附录B中介绍了主流的PEFT方法。 |
MM-LLM中常用的LLM:Flan-T5、ChatGLM 、UL2、Qwen、Chinchilla、OPT、PaLM、LLaMA、LLaMA-2和Vicuna
| The commonly used LLMs in MM-LLMs incude Flan-T5 (Chung et al., 2022), ChatGLM (Zeng et al., 2022a), UL2 (Tay et al., 2022), Qwen (Bai et al., 2023a), Chinchilla (Hoffmann et al., 2022), OPT (Zhang et al., 2022b), PaLM (Chowd-hery et al., 2023), LLaMA (Touvron et al., 2023a), LLaMA-2 (Touvron et al., 2023b), and Vicuna (Chiang et al., 2023). We provide a brief introduction to these models in Appendix C. | MM-LLM中常用的LLM包括Flan-T5 (Chung等人,2022)、ChatGLM (Zeng等人,2022a)、UL2 (Tay等人,2022)、Qwen (Bai等人,2023a)、Chinchilla (Hoffmann等人,2022)、OPT (Zhang等人,2022b)、PaLM (Chowd-hery等人,2023)、LLaMA (Touvron等人,2023a)、LLaMA-2 (Touvron等人,2023b)和Vicuna (Chiang等人,2023)。我们在附录C中简要介绍了这些模型。 |
2.4、Output Projector输出投影器
| The Output Projector ΘT→X maps the signal to-ken representations SX from the LLM Backbone into features HX understandable to the follow-ing Modality Generator MGX . Given the X-text dataset {IX , t}, t is first fed into LLM to generate the corresponding SX , then mapped into HX . To facilitate alignment of the mapped features HX , the goal is to minimize the distance between HX and the conditional text representations of MGX : The optimization only relies on captioning texts, without utilizing any audio or visual resources X, where HX = ΘT→X(SX) and τX is the textual condition encoder in MGX . The Output Projector is implemented by a Tiny Transformer or MLP. | 输出投影器ΘT→X将LLM主干的信号到标记表示SX映射为HX可理解的特征,以随后的模态生成器MGX。给定X-text数据集{IX, t},首先将t输入LLM以生成相应的SX,然后将其映射到HX。 为了便于对齐映射后的特征HX,目标是最小化HX与MGX的条件文本表示之间的距离: 优化仅依赖于字幕文本,不使用任何音频或视觉资源X,其中HX = ΘT→X(SX), τX是MGX中的文本条件编码器。输出投影器是由一个微型Transformer或MLP实现的。 |
2.5、Modality Generator模态生成器
| The Modality Generator MGX is tasked with pro-ducing outputs in distinct modalities. Commonly, existing works use off-the-shelf Latent Diffusion Models (LDMs) (Zhao et al., 2022), i.e., Stable Diffusion (Rombach et al., 2022) for image syn-thesis, Zeroscope (Cerspense, 2023) for video syn-thesis, and AudioLDM-2 (Liu et al., 2023b,c) for audio synthesis. The features HX mapped by the Output Projector serve as conditional inputs in the denoising process to generate MM content. Dur-ing training, the ground truth content is first trans-formed into a latent feature z0 by the pre-trained VAE (Kingma and Welling, 2013). Then, noise ϵ is added to z0 to obtain the noisy latent feature zt. A pre-trained Unet (Ronneberger et al., 2015) ϵX is used to compute the conditional LDM loss LX-gen as follows: | 模态生成器MGX的任务是产生不同模态的输出。通常,现有的工作使用现成的潜在扩散模型(LDMs) (Zhao et al., 2022),即用于图像合成的Stable Diffusion (Rombach et al., 2022),用于视频合成的Zeroscope (Cerspense, 2023),以及用于音频合成的AudioLDM-2 (Liu et al., 2023b,c)。由输出投影器映射的特征HX作为去噪过程中的条件输入,来生成MM内容。 在训练过程中,地面真值内容首先被预训练的VAE转化为潜在特征z0 (Kingma and Welling, 2013)。然后向z0添加噪音ϵ以获得嘈杂的潜在特征zt。使用预训练的Unet (Ronneberger et al., 2015) ϵX计算条件LDM损失LX-gen如下: |
| LX-gen := Eϵ∼N (0,1),t||ϵ − ϵX(zt, t, HX)|| , (5) optimize parameters ΘX→T and ΘT→X by mini-mizing LX-gen. | LX-gen := Eϵ∼N(0,1),t||ϵ − ϵX(zt,t,HX)||,(5)通过最小化LX-gen来优化参数ΘX→T和ΘT→X。 |
3、Training Pipeline训练流程
| MM-LLMs’ training pipeline can be delineated into two principal stages: MM PT and MM IT. | MM-LLM的训练流程可以划分为两个主要阶段:MM PT和MM IT。 |
3.1、MMPT预训练
| During the PT stage, typically leveraging the X-Text datasets, Input and Output Projectors are trained to achieve alignment among various modal-ities by optimizing predefined objectives (PEFT is sometimes applied to the LLM Backbone). For MM understanding models, optimization focuses solely on Equation (2), while for MM generation models, optimization involves Equations (2), (4), and (5). In the latter case, Equation (2) also in-cludes the ground-truth signal token sequence. The X-Text datasets encompass Image-Text, Video-Text, and Audio-Text, with Image-Text having two types: Image-Text pairs (i.e., <img1><txt1>) and interleaved Image-Text corpus (i.e., <txt1><img1><txt2><txt3><img2><txt4>). The detailed statistics for these X-Text datasets are presented in Table 3 of Appendix F. | 在PT阶段,通常利用X-Text数据集,训练输入和输出投影器通过优化预定义的目标来实现各种模式之间的对齐(PEFT有时应用于LLM主干)。对于MM理解模型,优化仅关注式(2),而对于MM生成模型,优化涉及式(2)、式(4)、式(5)。在后一种情况下,式(2)还包括真值信号令牌序列。 X-Text数据集包括图像-文本、视频-文本和音频-文本,其中图像-文本有两种类型:图像-文本对(即<img1><txt1>)和交错图像-文本语料库(即<txt1><img1><txt2><txt3><img2><txt4>)。这些X-Text数据集的详细统计数据见附录F的表3。 |
3.2、MMIT指令调优
| MM IT is a methodology that entails the fine-tuning of pre-trained MM-LLMs using a set of instruction-formatted datasets (Wei et al., 2021). Through this tuning process, MM-LLMs can generalize to un-seen tasks by adhering to new instructions, thereby enhancing zero-shot performance. This straightfor-ward yet impactful concept has catalyzed the suc-cess of subsequent endeavors in the field of NLP, exemplified by works such as InstructGPT (Ouyang et al., 2022), OPT-IML (Iyer et al., 2022), and In-structBLIP (Dai et al., 2023). MM IT comprises Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF), aiming to align with human in-tents or preferences and enhance the interaction capabilities of MM-LLMs. SFT converts part of the PT stage data into an instruction-aware format. Using visual Question-Answer (QA) as an example, various templates may be employed like (1) <Im-age>{Question} A short answer to the question is; (2) <Image>Examine the image and respond to the following question with a brief answer: {Ques-tion}. Answer:; and so on. Next, it fine-tunes the pre-trained MM-LLMs using the same optimiza-tion objectives. The SFT dataset can be structured as either single-turn QA or multi-turn dialogues. | MM IT是一种方法,需要使用一组指令格式的数据集对预训练的MM-LLM进行微调(Wei et al., 2021)。通过这个调优过程,MM-LLM可以通过遵守新的指令来推广到未见过的任务,从而提高零样本性能。这种直接而有影响力的概念催化了NLP领域后续努力的成功,例如InstructGPT (Ouyang等人,2022)、OPT-IML (Iyer等人,2022)和in - structlip (Dai等人,2023)。 MM IT包括监督微调(SFT)和从人类反馈中强化学习(RLHF),旨在与人类的意图或偏好保持一致,并增强MM-LLM的交互能力。SFT将部分PT阶段数据转换为指令感知格式。以视觉问答(QA)为例,可以使用各种模板,如(1)< image -age>{Question}问题的简短答案是;(2) <图片>检查图片,用一个简短的答案回答以下问题:{问题}。答:;等等......。接下来,它使用相同的优化目标对预训练的MM-LLM进行微调。SFT数据集可以构建为单回合QA或多回合对话。 |
| After SFT, RLHF involves further fine-tuning of the model, relying on feedback regarding the MM-LLMs’ responses (e.g., Natural Language Feedback (NLF) labeled manually or automati-cally) (Sun et al., 2023). This process employs a reinforcement learning algorithm to effectively integrate the non-differentiable NLF. The model is trained to generate corresponding responses con-ditioned on the NLF (Chen et al., 2023h; Akyürek et al., 2023). The statistics for SFT and RLHF datasets are presented in Table 4 of Appendix F. The datasets used by existing MM-LLMs in the MM PT and MM IT stages are diverse, but they are all subsets of the datasets in Tables 3 and 4. | 在SFT之后,RLHF涉及模型的进一步微调,依赖于MM-LLM响应的反馈(例如,手动或自动标记的自然语言反馈(NLF)) (Sun et al., 2023)。该过程采用强化学习算法对不可微NLF进行有效积分。该模型经过训练,在NLF条件下产生相应的响应(Chen et al., 2023h;aky<s:1> rek等人,2023)。SFT和RLHF数据集的统计结果见附录F的表4。 现有MM-LLM在MM PT和MM IT阶段使用的数据集各不相同,但它们都是表3和表4中数据集的子集。 |
4、SOTA MM-LLMs
| Based on the previously defined design formula-tions, we conduct a comprehensive comparison of the architectures and training dataset scales for 26 SOTA MM-LLMs, as illustrated in Table 1. Subse-quently, we will provide a concise introduction to the core contributions of these models and summa-rize their developmental trends. | 基于之前定义的设计公式,我们对26个SOTA MM-LLM的架构和训练数据集规模进行了全面比较,如表1所示。随后,我们将简要介绍这些模型的核心贡献,并总结它们的发展趋势。 |
Flamingo、BLIP-2、LLaVA、MiniGPT-4、mPLUG-Owl、X-LLM、VideoChat、InstructBLIP、PandaGPT、PaLI-x
| (1) Flamingo (Alayrac et al., 2022) represents a series of Visual Language (VL) Models designed for processing interleaved visual data and text, gen-erating free-form text as the output. (2) BLIP-2 (Li et al., 2023c) introduces a more resource-efficient framework, comprising the lightweight Q-Former to bridge modality gaps and the utilization of frozen LLMs. Leveraging LLMs, BLIP-2 can be guided for zero-shot image-to-text generation using nat-ural language prompts. (3) LLaVA (Liu et al.,2023e) pioneers the transfer of IT techniques to the MM domain. Addressing data scarcity, LLaVA introduces a novel open-source MM instruction-following dataset created using ChatGPT/GPT-4, alongside the MM instruction-following bench-mark, LLaVA-Bench. (4) MiniGPT-4 (Zhu et al., 2023a) proposes a streamlined approach where training only one linear layer aligns the pre-trained vision encoder with the LLM. This efficient method enables the replication of the exhibited capabili-ties of GPT-4. (5) mPLUG-Owl (Ye et al., 2023) presents a novel modularized training framework for MM-LLMs, incorporating the visual context. To assess different models’ performance in MM tasks, the framework includes an instructional eval-uation dataset called OwlEval. (6) X-LLM (Chen et al., 2023b) is expanded to various modalities, in-cluding audio, and demonstrates strong scalability. Leveraging the language transferability of the Q-Former, X-LLM is successfully applied in the con-text of Sino-Tibetan Chinese. (7) VideoChat (Li et al., 2023d) pioneers an efficient chat-centric MM-LLM for video understanding dialogue, set-ting standards for future research in this domain and offering protocols for both academia and in-dustry. (8) InstructBLIP (Dai et al., 2023) is trained based on the pre-trained BLIP-2 model, updating only the Q-Former during MM IT. By introducing instruction-aware visual feature extrac-tion and corresponding instructions, the model en-ables the extraction of flexible and diverse features.、 (9) PandaGPT (Su et al., 2023) is a pioneering general-purpose model with the capability to com-prehend and act upon instructions across 6 differ-ent modalities: text, image/video, audio, thermal, depth, and inertial measurement units. (10) PaLI-X (Chen et al., 2023g) is trained using mixed VL objectives and unimodal objectives, including pre-fix completion and masked-token completion. This approach proves effective for both downstream task results and achieving the Pareto frontier in the fine-tuning setting. | (1) Flamingo (Alayrac et al., 2022)代表了一系列视觉语言(VL)模型,用于处理交错的视觉数据和文本,生成自由格式的文本作为输出。 (2) BLIP-2 (Li et al., 2023c)引入了一个资源效率更高的框架,包括轻型Q-Former,以弥合模态差距,并利用冻结的LLMs。利用LLM, BLIP-2可以使用自然语言提示进行零样本图像到文本的生成。 (3) LLaVA (Liu et al.,2023e)率先将IT技术引入到MM领域。为了解决数据短缺问题,LLaVA引入了一个使用ChatGPT/GPT-4创建的新的开源MM指令遵循数据集,以及MM指令遵循基准,LLaVA- bench。 (4) MiniGPT-4 (Zhu等人,2023a)提出了一种简化的方法,其中只训练一个线性层将预训练的视觉编码器与LLM对齐。这种有效的方法能够复制GPT-4所展示的功能。 (5) mPLUG-Owl (Ye et al., 2023)提出了一种新的MM-LLM模块化训练框架,并结合了视觉上下文。为了评估不同模型在MM任务中的表现,该框架包括一个称为OwlEval的指导性评估数据集。 (6) X-LLM (Chen et al., 2023b)扩展到各种模态,包括音频,并显示出很强的可扩展性。利用Q-Former的语言可迁移性,X-LLM成功地应用于汉藏汉语语境。 (7) VideoChat (Li et al., 2023)开创了一种高效的以聊天为中心的MM-LLM,用于视频理解对话,为该领域的未来研究设定了标准,并为学术界和工业界提供了协议。 (8) InstructBLIP(Dai et al., 2023)基于预训练的BLIP-2模型进行训练,在MM IT期间仅更新Q-Former。该模型通过引入指令感知的视觉特征提取和相应的指令,实现了灵活多样的特征提取。 (9) PandaGPT(Su et al., 2023)是一种开创性的通用模型,能够理解和执行6种不同模态的指令:文本、图像/视频、音频、热图、深度和惯性测量单元。 (10) PaLI-X(Chen et al., 2023g)使用混合VL目标和单模态目标进行训练,包括前缀补全和掩码补全。事实证明,这种方法对下游任务结果和在微调设置下实现Pareto边界都是有效的。 |
Video-LLaMA、Video-ChatGPT、Shikra、DLP、BuboGPT 、ChatSpot、Qwen-VL、NExT-GPT、MiniGPT-5
| (11) Video-LLaMA (Zhang et al., 2023e) introduces a multi-branch cross-modal PT framework, enabling LLMs to simultaneously pro-cess the vision and audio content of a given video while engaging in conversations with humans. This framework aligns vision with language as well as audio with language. (12) Video-ChatGPT (Maaz et al., 2023) is a model specifically designed for video conversations, capable of generating discus-sions about videos by integrating spatiotemporal vision representations. (13) Shikra (Chen et al.,2023d) introduces a simple and unified pre-trained MM-LLM tailored for Referential Dialogue, a task involving discussions about regions and objects in images. This model demonstrates commendable generalization ability, effectively handling unseen settings. (14) DLP (Jian et al., 2023) proposes the P-Former to predict the ideal prompt, trained on a dataset of single-modal sentences. This showcases the feasibility of single-modal training to enhance MM learning. (15) BuboGPT (Zhao et al., 2023d) is a model constructed by learning a shared se-mantic space for a comprehensive understanding of MM content. It explores fine-grained relation-ships among different modalities such as image, text, and audio. (16) ChatSpot (Zhao et al., 2023b) introduces a simple yet potent method for finely adjusting precise referring instructions for MM-LLM, facilitating fine-grained interactions. The incorporation of precise referring instructions, con-sisting of image- and region-level instructions, en-hances the integration of multi-grained VL task descriptions. (17) Qwen-VL (Bai et al., 2023b) is a multi-lingual MM-LLM that supports both En-glish and Chinese. Qwen-VL also allows the input of multiple images during the training phase, im-proving its ability to understand the vision context. (18) NExT-GPT (Wu et al., 2023d) is an end-to-end, general-purpose any-to-any MM-LLM that supports the free input and output of image, video, audio, and text. It employs a lightweight alignment strategy, utilizing LLM-centric alignment in the en-coding phase and instruction-following alignment in the decoding phase. (19) MiniGPT-5 (Zheng et al., 2023b) is an MM-LLM integrated with inver-sion to generative vokens and integration with Sta-ble Diffusion. It excels in performing interleaved VL outputs for MM generation. The inclusion of classifier-free guidance during the training phase enhances the quality of generation. | (11) Video-LLaMA(Zhang et al., 2023e)引入了一个多分支跨模态PT框架,使LLM能够在与人类对话时同时处理给定视频的视觉和音频内容。该框架同时将视觉与语言以及音频与语言进行对齐。 (12) Video-ChatGPT (Maaz et al., 2023)是一个专门为视频对话设计的模型,能够通过整合时空视觉表征来生成关于视频的讨论。 (13) Shikra(Chen et al.,2023)引入了一个简单而统一的预训练MM-LLM,专为指涉对话而定制,涉及对图像中的区域和对象进行讨论的任务。该模型展示了令人瞩目的泛化能力,能够有效处理未见过的设置。 (14) DLP (Jian et al., 2023)提出了P-Former来预测理想提示,在单模态句子数据集上进行训练。这展示了单模态训练以增强MM学习的可行性。 (15) BuboGPT (Zhao et al., 2023d)是通过学习共享语义空间构建的模型,用于全面理解MM内容。它探索不同模态(如图像、文本和音频)之间的细粒度关系。 (16) ChatSpot (Zhao et al., 2023b)引入了一种简单而强大的方法,用于精细调整MM-LLM的精确引用指令,促进细粒度交互。包括图像和区域级别的指令,增强了多粒度VL任务描述的整合。 (17) Qwen-VL (Bai et al., 2023b)是一种支持英语和汉语的多语种MM-LLM。Qwen-VL还允许在训练阶段输入多个图像,提高其理解视觉上下文的能力。 (18) NExT-GPT (Wu et al., 2023d)是一种端到端、通用的任意到任意MM-LLM,支持图像、视频、音频和文本的自由输入和输出。它采用轻量级对齐策略,在编码阶段利用LLM中心的对齐,在解码阶段利用遵循指令的对齐。 (19) MiniGPT-5 (Zheng et al., 2023b)是一个与逆向生成voken和与Stable Diffusion集成的MM-LLM。它擅长于为MM生成执行交错VL输出。在训练阶段引入无分类器的指导可提高生成的质量。 |
LLaVA-1.5、MiniGPT-v2、CogVLM、DRESS、X-InstructBLIP、CoDi-2、VILA
| For introduction regarding the remaining seven MM-LLMs, please refer to Appendix D, which includes (20) LLaVA-1.5 (Liu et al., 2023d), (21) MiniGPT-v2 (Chen et al., 2023c), (22) CogVLM (Wang et al., 2023),(23) DRESS (Chen et al., 2023h), (24) X-InstructBLIP (Panagopoulou et al., 2023), (25) CoDi-2 (Tang et al., 2023a), and (26) VILA (Lin et al., 2023). | 关于其余7种MM-LLM的介绍,请参见附录D,其中包括(20)LLaVA-1.5 (Liu等人,2023d)、(21)MiniGPT-v2 (Chen等人,2023c)、(22)CogVLM (Wang等人,2023)、(23)DRESS (Chen等人,2023h)、(24)X-InstructBLIP(Panagopoulou等人,2023)、(25)CoDi-2 (Tang等人,2023a)和(26)VILA (Lin等人,2023)。 |
Trends in Existing MM-LLMs现有MM-LLM的趋势
| Trends in Existing MM-LLMs: (1) Progressing from a dedicated emphasis on MM understanding to the generation of specific modalities and further evolving into any-to-any modality conversion (e.g., MiniGPT-4 → MiniGPT-5 → NExT-GPT); (2) Ad-vancing from MM PT to SFT and then to RLHF, the training pipeline undergoes continuous refine-ment, striving to better align with human intent and enhance the model’s conversational interac-tion capabilities (e.g., BLIP-2 → InstructBLIP → DRESS); (3) Embracing Diversified Modal Exten-sions (e.g., BLIP-2 → X-LLM and InstructBLIP → X-InstructBLIP); (4) Incorporating a Higher-Quality Training Dataset (e.g., LLaVA → LLaVA- 1.5); (5) Adopting a More Efficient Model Architec-ture, transitioning from complex Q- and P-Former input projector modules in BLIP-2 and DLP to a simpler yet effective linear projector in VILA. | 现有MM-LLM的趋势: (1)从专注于MM理解逐渐发展为特定模态的生成,并进一步演变为任意到任意模态的转换(例如,MiniGPT-4→MiniGPT-5→NExT-GPT); (2)从MM PT到SFT再到RLHF,训练流程不断完善,力求更好地符合人类意图,增强模型的对话交互能力(例如,BLIP-2→InstructBLIP →DRESS); (3)采用多样化的模态扩展(例如,BLIP-2→X-LLM和InstructBLIP→X-InstructBLIP); (4)结合更高质量的训练数据集(例如,LLaVA→LLaVA- 1.5); (5)采用更高效的模型架构,从BLIP-2和DLP中复杂的Q-和P-Former输入投影机模块过渡到VILA中更简单但有效的线性投影机。 |
Table 1: The summary of 26 mainstream MM-LLMs. I→O: Input to Output Modalities, I: Image, V: Video, A: Audio, 3D: Point Cloud, and T: Text. In Modality Encoder, “-L” represents Large, “-G” represents Giant, “/14” indicates a patch size of 14, and “@224” signifies an image resolution of 224 × 224. #.PT and #.IT represent the scale of the dataset during MM PT and MM IT, respectively. † includes in-house data that is not publicly accessible.

5、Benckmarks and Performance基准与性能
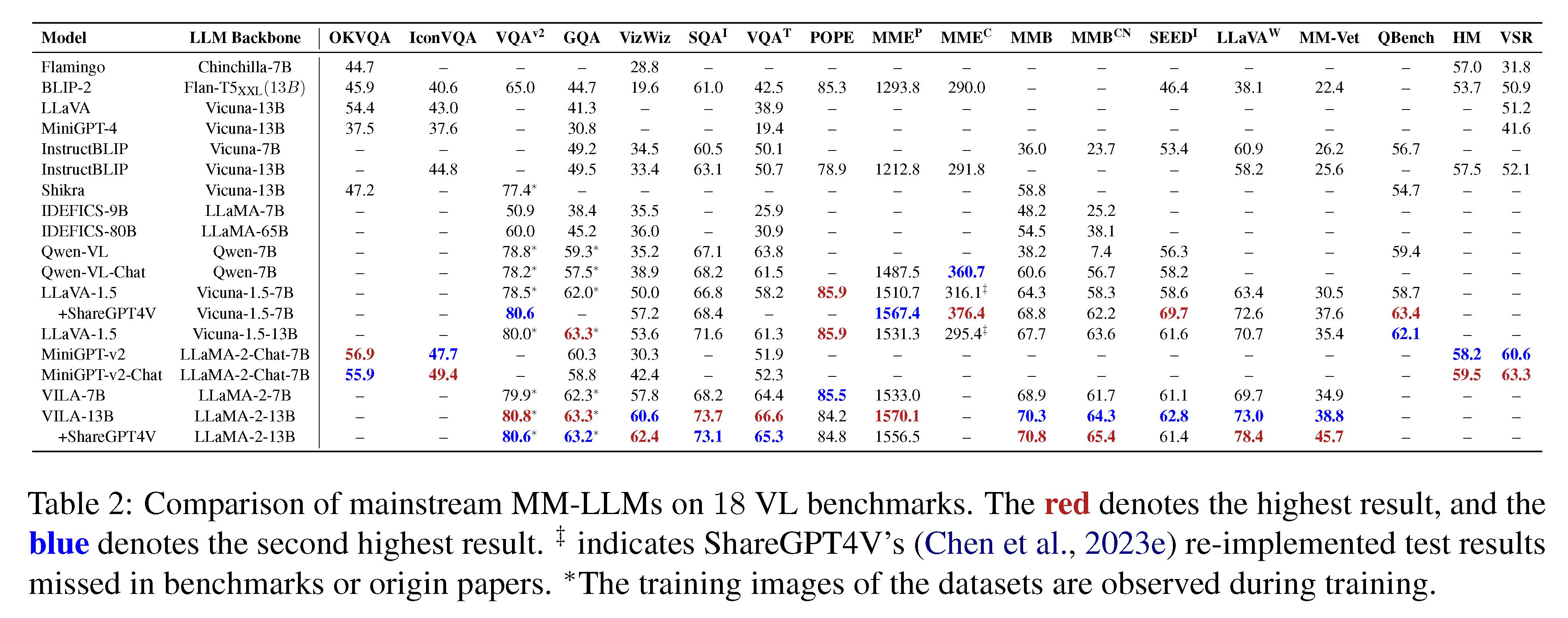
| To offer a comprehensive performance compari-son, we have compiled a table featuring major MM-LLMs across 18 VL benchmarks gathered from various papers (Li et al., 2023c; Chen et al., 2023c,e; Lin et al., 2023), as shown in Table 2. The information of these benchmarks can be found in Appendix E. Next, we will extract essential training recipes that boost the effectiveness of MM-LLMs, drawing insights from SOTA models. | 为了提供全面的性能比较,我们编制了一个表,列出了从各种论文中收集的18个VL基准中的主要MM-LLM (Li et al., 2023c;Chen et al., 2023c,e;Lin et al., 2023),见表2。这些基准的信息可以在附录e中找到。接下来,我们将从SOTA模型中提取出提高MM-LLM有效性的基本训练配方。 |
Training Recipes Firstly训练配方
| Training Recipes Firstly, higher image resolu-tion can incorporate more visual details for the model, benefiting tasks that require fine-grained details. For example, LLaVA-1.5 and VILA em-ploy a resolution of 336 × 336, while Qwen-VL and MiniGPT-v2 utilize 448 × 448. However, higher resolutions lead to longer token sequences, incurring additional training and inference costs. MiniGPT-v2 addresses this by concatenating 4 adja-cent visual tokens in the embedding space to reduce length. Recently, Monkey (Li et al., 2023h) pro-posed a solution to enhance the resolution of input images without retraining a high-resolution visual encoder, utilizing only a low-resolution visual en-coder, supporting resolutions up to 1300 × 800. To enhance the understanding of rich-text images, ta-bles, and document content, DocPedia (Feng et al., 2023) introduced a method to increase the visual encoder resolution to 2560 × 2560, overcoming the limitations of poorly performing low resolu-tions in open-sourced ViT. Secondly, the incorpo-ration of high-quality SFT data can significantly im-prove performance in specific tasks, as evidenced by the addition of ShareGPT4V data to LLaVA-1.5 and VILA-13B, as shown in Table 2. Moreover, VILA reveals several key findings: (1) Performing PEFT on the LLM Backbone promotes deep em-bedding alignment, crucial for ICL; (2) Interleaved Image-Text data proves beneficial, whereas Image-Text pairs alone are sub-optimal; (3) Re-blending text-only instruction data (e.g., Unnatural instruction (Honovich et al., 2022)) with image-text data during SFT not only addresses the degradation of text-only tasks but also enhances VL task accuracy. | 首先,更高的图像分辨率可以为模型包含更多的视觉细节,有利于需要细粒度细节的任务。例如,LLaVA-1.5和VILA的分辨率为336 × 336,而Qwen-VL和MiniGPT-v2的分辨率为448 × 448。然而,更高的分辨率会导致更长的令牌序列,从而产生额外的训练和推理成本。MiniGPT-v2通过在嵌入空间中连接4个相邻的视觉标记来减少长度来解决这个问题。最近,Monkey (Li et al., 2023h)提出了一种无需重新训练高分辨率视觉编码器即可提高输入图像分辨率的解决方案,该方案仅使用低分辨率视觉编码器,支持分辨率高达1300 × 800。为了增强对富文本图像、表和文档内容的理解,DocPedia (Feng et al., 2023)引入了一种将视觉编码器分辨率提高到2560 × 2560的方法,克服了开源ViT中表现不佳的低分辨率限制。其次,纳入高质量的SFT数据可以显著提高特定任务的性能,如将ShareGPT4V数据添加到llva -1.5和VILA-13B中,如表2所示。此外,VILA揭示了几个关键发现:(1)在LLM骨干上进行PEFT可以促进深层嵌层对准,这对ICL至关重要;(2)交错的图像-文本数据被证明是有益的,而单独的图像-文本对是次优的;(3)在SFT过程中,将纯文本指令数据(例如,非自然指令(Honovich et al., 2022))与图像文本数据重新混合,不仅可以解决纯文本任务的退化问题,还可以提高VL任务的准确性。 |
Table 2: Comparison of mainstream MM-LLMs on 18 VL benchmarks. The red denotes the highest result, and the blue denotes the second highest result. ‡ indicates ShareGPT4V’s (Chen et al., 2023e) re-implemented test results missed in benchmarks or origin papers. ∗The training images of the datasets are observed during training.
6、Future Directions未来发展方向
| In this section, we explore promising future direc-tions for MM-LLMs across the following aspects: | 在本节中,我们将从以下几个方面探讨MM-LLM的未来发展方向: |
More Powerful Models更强大的模型
| More Powerful Models We can enhance the MM-LLMs’ strength from the following four key avenues: (1) Expanding Modalities: Current MM-LLMs typically support the following modalities: image, video, audio, 3D, and text. However, the real world involves a broader range of modalities. Extending MM-LLMs to accommodate additional modalities (e.g., web pages, heat maps, and fig-ures&tables) will increase the model’s versatility, making it more universally applicable; (2) Diver-sifying LLMs: Incorporating various types and sizes of LLMs provides practitioners with the flexi-bility to select the most appropriate one based on their specific requirements; (3) Improving MM IT Dataset Quality: Current MM IT dataset have ample room for improvement and expansion. Di-versifying the range of instructions can enhance the effectiveness of MM-LLMs in understanding and executing user commands. (4) Strengthen-ing MM Generation Capabilities: Most current MM-LLMs are predominantly oriented towards MM understanding. Although some models have incorporated MM generation capabilities, the qual-ity of generated responses may be constrained by the capacities of the LDMs. Exploring the inte-gration of retrieval-based approaches (Asai et al., 2023) holds significant promise in complementing the generative process, potentially enhancing the overall performance of the model. | 我们可以从以下四个主要途径增强MM-LLM的能力:(1)扩展模式:目前的MM-LLM通常支持以下模式:图像、视频、音频、3D和文本。然而,现实世界涉及更广泛的模式。扩展MM-LLM以适应额外的模式(例如,网页、热图和图表)将增加模型的多功能性,使其更普遍适用;(2)多样化的LLM:纳入不同类型和规模的LLM,为从业者提供了根据具体要求选择最合适的LLM的灵活性;(3)提高MM IT数据集质量:当前MM IT数据集有很大的改进和扩展空间。多样化的指令范围可以提高MM-LLM理解和执行用户命令的有效性。(4)增强MM生成能力:目前大多数MM-LLM主要面向对MM的理解。尽管一些模型包含了生成MM的能力,但是生成的响应的质量可能受到ldm能力的限制。探索基于检索的方法的集成(Asai等人,2023)在补充生成过程方面具有重要的前景,可能会提高模型的整体性能。 |
More Challenging Benchmarks更具挑战性的基准
| More Challenging Benchmarks Existing bench-marks might not adequately challenge the capa-bilities of MM-LLMs, given that many datasets have previously appeared to varying degrees in the PT or IT sets. This implies that the models may have learned these tasks during training. More-over, current benchmarks predominantly concen-trate on the VL sub-field. Thus, it is crucial for the development of MM-LLMs to construct a more challenging, larger-scale benchmark that includes more modalities and uses a unified evaluation stan-dard. Concurrently, benchmarks can be tailored to assess the MM-LLMs’ proficiency in practical ap-plications. For instance, the introduction of GOAT-Bench (Lin et al., 2024) aims to evaluate various MM-LLMs’ capacity to discern and respond to nu-anced aspects of social abuse presented in memes. | 现有的基准测试可能无法充分挑战MM-LLM的能力,因为许多数据集以前在PT或IT集中不同程度地出现过。这意味着模型可能在训练过程中已经学会了这些任务。此外,目前的基准主要集中在VL子油田。因此,构建一个更具挑战性、规模更大、包含更多模式、使用统一评价标准的MM-LLM基准,对于MM-LLM的发展至关重要。同时,可以定制基准来评估MM-LLM在实际应用中的熟练程度。例如,引入GOAT-Bench (Lin et al., 2024)旨在评估各种MM-LLM辨别和应对模因中呈现的社会虐待的细微方面的能力。 |
Mobile/Lightweight Deployment移动/轻量级的部署
| Mobile/Lightweight Deployment To deploy MM-LLMs on resource-constrained platforms and achieve optimal performance meanwhile, such as low-power mobile and IoT devices, lightweight implementations are of paramount importance. A notable advancement in this realm is Mo-bileVLM (Chu et al., 2023a). This approach strate-gically downscales LLaMA, allowing for seam-less off-the-shelf deployment. MobileVLM further introduces a Lightweight Downsample Projector, consisting of fewer than 20 million parameters, con-tributing to improved computational speed. Never-theless, this avenue necessitates additional explo-ration for further advancements in development. | 移动/轻量级部署要在资源受限的平台上部署MM-LLM,同时实现最优性能,如低功耗移动和物联网设备,轻量级实现至关重要。在这个领域的一个显著进步是Mo-bileVLM (Chu et al., 2023a)。这种方法战略性地缩小了LLaMA的规模,允许无缝的现成部署。MobileVLM进一步推出了轻量级下样投影器,由不到2000万个参数组成,有助于提高计算速度。然而,这一途径需要进一步探索,以进一步促进发展。 |
Embodied Intelligence具身智能
| Embodied Intelligence The embodied intelli-gence aims to replicate human-like perception and interaction with the surroundings by effectively understanding the environment, recognizing perti-nent objects, assessing their spatial relationships, and devising a comprehensive task plan (Firoozi et al., 2023). Embodied AI tasks, such as embod-ied planning, embodied visual question answer-ing, and embodied control, equips robots to au-tonomously implement extended plans by leverag-ing real-time observations. Some typical work in this area is PaLM-E (Driess et al., 2023) and Em-bodiedGPT (Mu et al., 2023). PaLM-E introduces a multi-embodiment agent through the training of a MM-LLM. Beyond functioning solely as an em-bodied decision maker, PaLM-E also demonstrates proficiency in handling general VL tasks. Em-bodiedGPT introduces an economically efficient method characterized through a CoT approach, en-hancing the capability of embodied agents to engage with the real world and establishing a closed loop that connects high-level planning with low-level control. While MM-LLM-based Embodied Intelligence has made advancements in integrat-ing with robots, further exploration is needed to enhance the autonomy of robots. | 具身智能旨在通过有效地理解环境、识别相关物体、评估它们的空间关系以及制定综合任务计划来复制类似人类的感知和与周围环境的互动(Firoozi et al., 2023)。嵌入式人工智能任务,如嵌入式规划、嵌入式视觉问答和嵌入式控制,使机器人能够通过利用实时观察自主执行扩展计划。在该领域的一些典型工作是PaLM-E (Driess et al., 2023)和Em-bodiedGPT (Mu et al., 2023)。PaLM-E通过MM-LLM的培训引入了一种多体现代理。除了作为一个实体决策者的功能之外,PaLM-E还展示了处理一般VL任务的熟练程度。实体gpt引入了一种经济高效的方法,以CoT方法为特征,增强了实体代理与现实世界接触的能力,并建立了一个将高层规划与低层控制联系起来的闭环。虽然基于MM-LLM的具身智能在与机器人的集成方面取得了进展,但在增强机器人的自主性方面还需要进一步探索。 |
Continual IT持续
| Continual IT In practical applications, MM-LLMs are expected to adapt to new MM tasks for supporting additional functionalities. Never-theless, current MM-LLMs remain static and are unable to adjust to continuously emerging require-ments. Therefore, an approach is needed to make the model flexible enough to efficiently and con-tinually leverage emerging data, while avoiding the substantial cost of retraining MM-LLMs. This aligns with the principles of continual learning, where models are designed to incrementaly learn new tasks similar to human learning. Continual IT aims to continuously fine-tune MM-LLMs for new MM tasks while maintaining superior perfor-mance on tasks learned during the original MM IT stage. It introduces two primary challenges: (1) catastrophic forgetting, where models forget previ-ous knowledge when learning new tasks (Robins, 1995; McCloskey and Cohen, 1989; Goodfellow et al., 2013; Zhang et al., 2023d,c,b; Zheng et al., 2023a), and (2) negative forward transfer, indicat-ing that the performance of unseen tasks is declined when learning new ones (Zheng et al., 2024; Dong et al., 2023b,a). Recently, He et al. established a benchmark to facilitate the development of contin-ual IT for MM-LLMs. Despite these advancements, there is still a significant opportunity and room for improvement in developing better methods to ad-dress the challenges of catastrophic forgetting and negative forward transfer. | 在实际应用中,MM-LLM被期望适应新的MM任务,以支持额外的功能。然而,目前的MM-LLM仍然是静态的,无法适应不断出现的需求。因此,需要一种方法使模型足够灵活,以有效和持续地利用新出现的数据,同时避免重新培训MM-LLM的大量成本。这与持续学习的原则是一致的,其中模型被设计为与人类学习类似的增量学习新任务。持续IT的目标是不断微调MM-LLM,以适应新的MM任务,同时在原始MM IT阶段学习的任务上保持优越的性能。它引入了两个主要挑战:(1)灾难性遗忘,即模型在学习新任务时忘记了以前的知识(Robins, 1995;McCloskey and Cohen, 1989;Goodfellow et al., 2013;张等,2013年3月,c,b;Zheng et al., 2023a)和(2)负前向迁移,表明学习新任务时未见任务的表现下降(Zheng et al., 2024;董等人,2009,b,a)。最近,He等人建立了一个基准来促进MM-LLM持续IT的开发。尽管取得了这些进步,但在开发更好的方法来解决灾难性遗忘和负正向转移的挑战方面,仍有很大的机会和改进空间。 |
7、Conclusion结论
| In this paper, we have presented a comprehensive survey of MM-LLMs with a focus on recent ad-vancements. Initially, we categorize the model architecture into five components, providing a de-tailed overview of general design formulations and training pipelines. Subsequently, we introduce var-ious SOTA MM-LLMs, each distinguished by its specific formulations. Our survey also sheds light on their capabilities across diverse MM bench-marks and envisions future developments in this rapidly evolving field. We hope this survey can provide insights for researchers, contributing to the ongoing advancements in the MM-LLMs domain. | 在本文中,我们对MM-LLM进行了全面的调查,并重点介绍了最近的进展。最初,我们将模型体系结构分为五个组件,提供一般设计公式和训练流程的详细概述。随后,我们介绍了各种SOTA MM-LLM,每种MM-LLM都有其特定的配方。我们的调查还揭示了他们在不同MM基准上的能力,并展望了这个快速发展领域的未来发展。我们希望这项调查能够为研究者提供一些见解,为MM-LLM领域的持续发展做出贡献。 |
Limitations限制
| In this paper, we embark on a comprehensive explo-ration of the current MM-LLMs landscape, present-ing a synthesis from diverse perspectives enriched by our insights. Acknowledging the dynamic na-ture of this field, it is plausible that certain aspects may have eluded our scrutiny, and recent advances might not be entirely encapsulated. To tackle this inherent challenge, we’ve established a dedicated website for real-time tracking, using crowdsourc-ing to capture the latest advancements. Our goal is for this platform to evolve into a continuous source of contributions propelling ongoing development in the field. Given the constraints of page limits, we are unable to delve into all technical details and have provided concise overviews of the core contri-butions of mainstream MM-LLMs. Looking ahead, we coMM IT to vigilant monitoring and continual enhancement of relevant details on our website, incorporating fresh insights as they emerge. | 在本文中,我们对当前的MM-LLM景观进行了全面的探索,从不同的角度展示了一个综述,丰富了我们的见解。鉴于这一领域的动态性质,某些方面可能已逃脱我们的审查,并且最新的进展可能并未完全包含。为了解决这个固有的挑战,我们建立了一个专门的网站来实时跟踪,使用众包来捕捉最新的进展。我们的目标是让这个平台发展成为一个持续的贡献来源,推动该领域的持续发展。由于页面限制的限制,我们无法深入研究所有的技术细节,并提供了主流MM-LLM核心贡献的简明概述。展望未来,我们承诺对网站的相关细节进行密切监控和持续改进,并在出现新见解时纳入其中。 |
这篇关于AI之MLM:《MM-LLMs: Recent Advances in MultiModal Large Language Models多模态大语言模型的最新进展》翻译与解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





