llms专题

透彻!驯服大型语言模型(LLMs)的五种方法,及具体方法选择思路
引言 随着时间的发展,大型语言模型不再停留在演示阶段而是逐步面向生产系统的应用,随着人们期望的不断增加,目标也发生了巨大的变化。在短短的几个月的时间里,人们对大模型的认识已经从对其zero-shot能力感到惊讶,转变为考虑改进模型质量、提高模型可用性。 「大语言模型(LLMs)其实就是利用高容量的模型架构(例如Transformer)对海量的、多种多样的数据分布进行建模得到,它包含了大量的先验
![[论文笔记]QLoRA: Efficient Finetuning of Quantized LLMs](https://img-blog.csdnimg.cn/img_convert/e75c9a4137c39630cd34c5ebe3fe8196.png)
[论文笔记]QLoRA: Efficient Finetuning of Quantized LLMs
引言 今天带来LoRA的量化版论文笔记——QLoRA: Efficient Finetuning of Quantized LLMs 为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。 我们提出了QLoRA,一种高效的微调方法,它在减少内存使用的同时,能够在单个48GB GPU上对65B参数的模型进行微调,同时保持16位微调任务的完整性能。QLoRA通过一个冻结的4位量化预


开源模型应用落地-LlamaIndex学习之旅-LLMs-集成vLLM(二)
一、前言 在这个充满创新与挑战的时代,人工智能正以前所未有的速度改变着我们的学习和生活方式。LlamaIndex 作为一款先进的人工智能技术,它以其卓越的性能和创新的功能,为学习者带来前所未有的机遇。我们将带你逐步探索 LlamaIndex 的强大功能,从快速整合海量知识资源,到智能生成个性化的学习路径;从精准分析复杂的文本内容,到与用户进行深度互动交流。通过丰富的实例展示和详细的操作指

如何使用未标注数据对LLMs进行微调
Abstract 本研究专注于利用和选择大量的未标注开放数据来对预训练语言模型进行预微调。目标是尽量减少后续微调中对成本高昂的特定领域数据的需求,同时达到期望的性能水平。尽管许多数据选择算法是为小规模应用设计的,这使得它们不适用于作者的场景,但一些新兴方法确实适用于语言数据规模。然而,它们通常优先选择与目标分布对齐的数据。当从零开始训练模型时,这种策略可能很有效,但当模型已经在一个不同的分布

大模型LLMs很火,作为新生小白应该怎么入门 LLMs?是否有推荐的入门教程推荐?
很明显,这是一个偏学术方向的指南要求,所以我会把整个LLM应用的从数学到编程语言,从框架到常用模型的学习方法,给你捋一个通透。也可能是不爱学习的劝退文。 通常要达到熟练的进行LLM相关的学术研究与开发,至少你要准备 数学、编码、常用模型的知识,还有LLM相关的知识的准备。 TL;DR 要求总结: 数学知识:线性代数、高数、概率开发语言:Python, C/C++开发框架:Numpy/Pyt

Large Language Models(LLMs) Concepts
1、Introduction to Large Language Models(LLM) 1.1、Definition of LLMs Large: Training data and resources.Language: Human-like text.Models: Learn complex patterns using text data. The LLM is conside
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.08.10-2024.08.15
文章目录~ 1.W-RAG: Weakly Supervised Dense Retrieval in RAG for Open-domain Question Answering2.Dynamic Adaptive Optimization for Effective Sentiment Analysis Fine-Tuning on Large Language Models3.Fact

构建生产环境中的大型语言模型(LLMs)——LLM架构与现状
理解Transformer Transformer架构在各种应用中展示了其多才多艺的特性。最初的网络被提出作为一个用于翻译任务的编码器-解码器架构。Transformer架构的下一次演进是引入了仅编码器模型,如BERT,随后是仅解码器网络,即GPT模型的首次迭代。 这些区别不仅体现在网络设计上,还包括学习目标。这些不同的学习目标在塑造模型的行为和结果方面起着至关重要的作用。理解这些差异对于选择

【大模型LLMs】文本分块Chunking调研LangChain实战
【大模型LLMs】文本分块Chunking调研&LangChain实战 Chunking策略类型1. 基于规则的文本分块2. 基于语义Embedding分块3. 基于端到端模型的分块4. 基于大模型的分块 Chunking工具使用(LangChain)1. 固定大小分块(字符&token)2. 语义分块 总结目前主流的文本分块chunking方法,给出LangChain实现各类
Awesome-LLMs-for-Video-Understanding - 基于大型语言模型的视频理解研究
Awesome-LLMs-for-Video-Understanding 是 基于大型语言模型的视频理解研究 github : https://github.com/yunlong10/Awesome-LLMs-for-Video-Understandingpaper:Video Understanding with Large Language Models: A Survey https:/

【大模型LLMs】RAG实战:基于LlamaIndex快速构建RAG链路(Qwen2-7B-Instruct+BGE Embedding)
【大模型LLMs】RAG实战:基于LlamaIndex快速构建RAG链路(Qwen2-7B-Instruct+BGE Embedding) 1. 环境准备2. 数据准备3. RAG框架构建3.1 数据读取 + 数据切块3.2 构建向量索引3.3 检索增强3.4 main函数 参考 基于LlamaIndex框架,以Qwen2-7B-Instruct作为大模型底座,bge-base-

大语言模型(LLMs)能够进行推理和规划吗?
大语言模型(LLMs),基本上是经过强化训练的 n-gram 模型,它们在网络规模的语言语料库(实际上,可以说是我们文明的知识库)上进行了训练,展现出了一种超乎预期的语言行为,引发了我们的广泛关注。从训练和操作的角度来看,LLMs 可以被认为是一种巨大的、非真实的记忆库,相当于为我们所有人提供了一个外部的系统 1(见图 1)。然而,它们表面上的多功能性让许多研究者好奇,这些模型是否也能在通常需要系
AI 大模型企业应用实战(10)-LLMs和Chat Models
1 模型 来看两种不同类型的模型--LLM 和聊天模型。然后,它将介绍如何使用提示模板来格式化这些模型的输入,以及如何使用输出解析器来处理输出。 LangChain 中的语言模型有两种类型: 1.1 Chat Models 聊天模型通常由 LLM 支持,但专门针对会话进行了调整。提供者 API 使用与纯文本补全模型不同的接口。它们的输入不是单个字符串,而是聊天信息列表,输出则是一条人工智能

AI推介-大语言模型LLMs论文速览(arXiv方向):2024.06.05-2024.06.10
文章目录~ 1.Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation2.Reasoning in Token Economies: Budget-Aware Evaluation of LLM Reasoning Strategies3.Low-Rank Quantization-Aware Tra
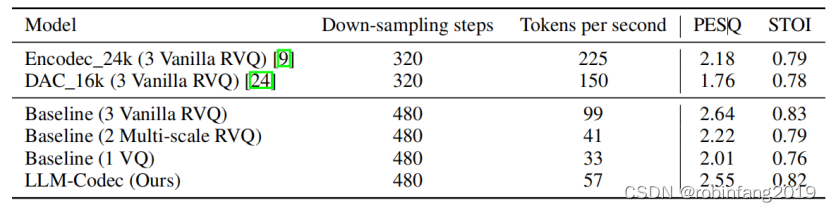
UniAudio 1.5:大型语言模型(LLMs)驱动的音频编解码器
大型语言模型(LLMs)在文本理解和生成方面展示了卓越的能力,但它们不能直接应用于跨模态任务,除非进行微调。本文提出了一种跨模态上下文学习方法,使未进行进一步训练的LLMs能够在少量示例的情况下,无需任何参数更新就能完成多种音频任务。核心思想是通过将音频模态压缩到训练有素的LLMs的令牌空间中,减少文本和音频之间的模态异质性。这样,音频表示可以被视为一种新的语言,LLMs可以通过几个

Redis作者长文总结LLMs, 能够取代99%的程序员
引言 这篇文章并不是对大型语言模型(LLMs)的全面回顾。很明显,2023年对人工智能而言是特别的一年,但再次强调这一点似乎毫无意义。相反,这篇文章旨在作为一个程序员个人的见证。自从ChatGPT问世,以及后来使用本地运行的LLMs,我广泛使用了这项新技术。目的是加速编写代码的能力,但这并非唯一目的。还有一个意图是不在编程的不值得花费精力的方面浪费精神能量。无数小时花在寻找关于特殊、智力上不感兴

如何高效使用大型语言模型 LLMs 初学者版本 简单易上手
第一条也是最重要的一条规则是 永远不要要求LLM提供你无法自己验证的信息, 或让它完成你无法验证其正确性的任务。 唯一例外的情况是那些无关紧要的任务, 例如,让大型语言模型提供公寓装修灵感之类的是可以的 。 首先请看两个范例 不佳示范:“使用文献综述最佳实践,总结过去十年乳腺癌的研究成果。” (这是一个不够好的请求,因为我们无法直接检查它是否正确地总结了文献。) 较好的示范:“给我
LLMs:《A Decoder-Only Foundation Model For Time-Series Forecasting》的翻译与解读
LLMs:《A Decoder-Only Foundation Model For Time-Series Forecasting》的翻译与解读 导读:本文提出了一种名为TimesFM的时序基础模型,用于零样本学习模式下的时序预测任务。 背景痛点:近年来,深度学习模型在有充足训练数据的情况下已成为时序预测的主流方法,但这些方法通常需要独立在每个数据集上训练。同时,自然语言处理领域的大规模预训练
QLoRA:高效的LLMs微调方法,48G内存可调65B 模型
文章:https://arxiv.org/pdf/2305.14314.pdf代码:https://github.com/artidoro/qlora 概括 QLORA是一种有效的微调方法,它减少了内存使用,足以在单个48GB GPU上微调65B参数模型,同时保留完整的16位微调任务性能。QLORA通过冻结的4位量化预训练语言模型将梯度反向传播到低秩适配器(Low Rank Adapter
机器学习之Transformer模型和大型语言模型(LLMs)
Transformer模型和大型语言模型(LLMs)是现代自然语言处理(NLP)和人工智能(AI)领域的前沿技术。这些模型革新了机器理解和生成人类语言的方式,使得从聊天机器人和自动翻译到复杂的内容生成和情感分析的应用成为可能。 Transformer模型 概述 Transformer模型是现代自然语言处理(NLP)和深度学习领域的核心技术之一。它由Vaswani等人在2017年提出的论文《A

大型语言模型(LLMs)的后门攻击和防御技术
大型语言模型(LLMs)通过训练在大量文本语料库上,展示了在多种自然语言处理(NLP)应用中取得最先进性能的能力。与基础语言模型相比,LLMs在少样本学习和零样本学习场景中取得了显著的性能提升,这得益于模型规模的扩大。随着模型参数的增加和高质量训练数据的获取,LLMs更能识别语言中的固有模式和语义信息。 尽管部署语言模型有潜在的好处,但它们因易受对抗性攻击、越狱攻击和后门攻击的脆
LLMs,即大型语言模型
LLMs,即大型语言模型,是一类基于深度学习的人工智能模型,它们通过海量的数据和大量的计算资源进行训练,可以理解和生成自然语言。LLMs的核心架构是Transformer,其关键在于自注意力机制,使得模型能够同时对输入的所有位置进行“关注”,从而更好地捕捉长距离的语义依赖关系。 LLMs在众多领域都有广泛的应用,如自然语言理解(NLU),语言生成,以及语音识别和合成等。例如,

AI视频教程下载:用LangChain开发 ChatGPT和 LLMs 应用
在这个快速变化的人工智能时代,我们为您带来了一场关于语言模型和生成式人工智能的革命性课程。这不仅仅是一个课程,而是一次探险,一次深入人工智能核心的奇妙之旅。 在这里,您将开启一段激动人心的旅程,探索语言模型的奥秘和生成式人工智能的无限可能。从基础的**引言**开始,我们将带您领略人工智能的宏伟蓝图,然后深入到**语言模型简介**,让您对这一领域有一个全面的认识。 随着旅程的深入,您将学习到**
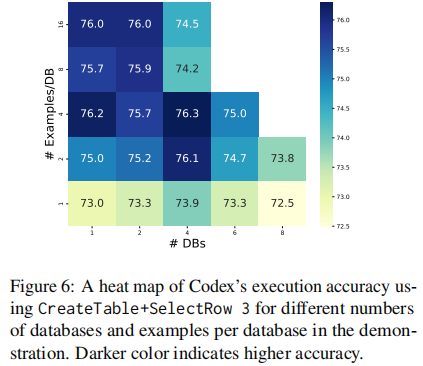
【Text2SQL 论文】How to prompt LLMs for Text2SQL
论文:How to Prompt LLMs for Text-to-SQL: A Study in Zero-shot, Single-domain, and Cross-domain Settings ⭐⭐⭐⭐ arXiv:2305.11853, NeurlPS 2023 Code: GitHub 一、论文速读 本文主要是在三种常见的 Text2SQL ICL settings 评估不

LLMs之Embedding:FlagEmbedding(一款用于微调/评估文本嵌入模型的工具)的简介、安装和使用方法、案例应用之详细攻略
LLMs之Embedding:FlagEmbedding(一款用于微调/评估文本嵌入模型的工具)的简介、安装和使用方法、案例应用之详细攻略 目录 FlagEmbedding的简介 1、该项目采用的原理主要包括: FlagEmbedding的安装和使用方法 1、安装 T1、使用pip T2、从源代码安装 T3、对于开发环境,请以可编辑模式安装: 2、使用方法 (1)、数据准备