本文主要是介绍如何使用未标注数据对LLMs进行微调,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

Abstract
本研究专注于利用和选择大量的未标注开放数据来对预训练语言模型进行预微调。目标是尽量减少后续微调中对成本高昂的特定领域数据的需求,同时达到期望的性能水平。尽管许多数据选择算法是为小规模应用设计的,这使得它们不适用于作者的场景,但一些新兴方法确实适用于语言数据规模。然而,它们通常优先选择与目标分布对齐的数据。当从零开始训练模型时,这种策略可能很有效,但当模型已经在一个不同的分布上进行预训练时,它可能只会带来有限的结果。与之前的工作不同,作者的关键想法是选择那些使预训练分布更接近目标分布的数据。作者展示了在某些条件下,这种方法对微调任务的最优性。作者在一系列不同任务(NLU、NLG、零样本)中展示了作者方法的功效,模型规模达到27亿,证明它始终超越其他选择方法。此外,作者提出的方法比现有技术快得多,在单个GPU小时内可扩展到数百万样本。作者的代码是开源的1。尽管微调在提高各种任务性能方面具有显著潜力,但其相关成本常常限制了其广泛应用;通过这项工作,作者希望为成本效益高的微调奠定基础,使其好处更加易于获得。
图1:两阶段微调的好处。所有展示的设置均达到相同的任务性能。在CoLA数据集(Wang等人,2018年)上进行评估。
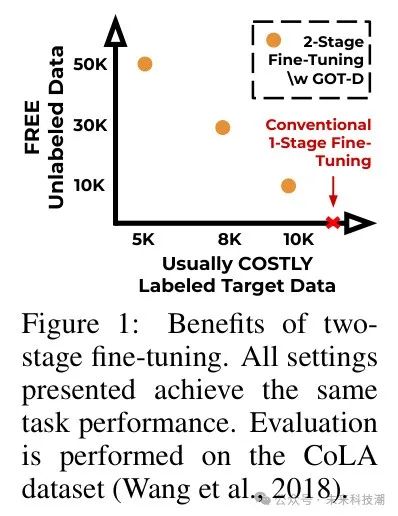
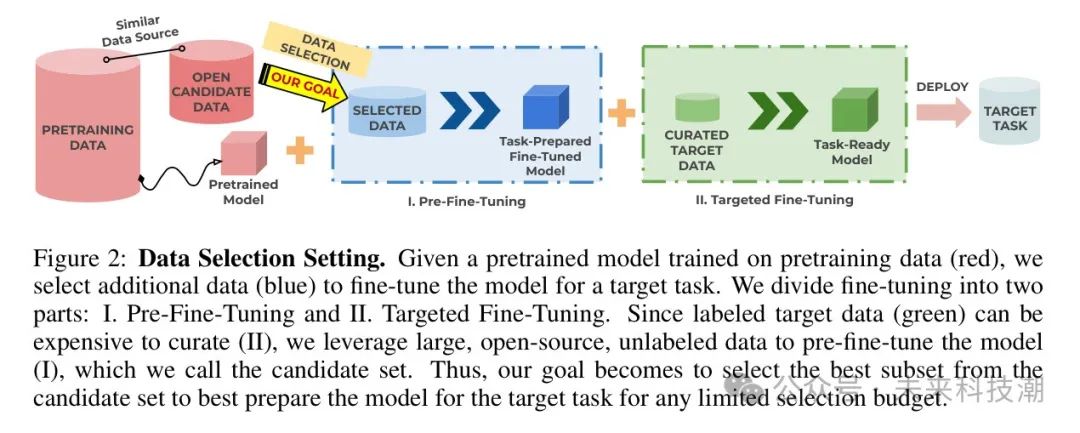
预训练的大语言模型(LLM)在广泛的AI应用中变得不可或缺(Devlin等人,2018年;Touvron等人,2023年;Wang等人,2022b年)。通常,为了将这些模型适应于特定应用,需要进一步进行微调。这一过程中持续存在的挑战是针对那些标注良好的数据集稀疏的新兴、及时的任努。例如,GPT模型因安全问题被标记(Wang等人,2023年,2022a年),要求立即进行集中干预。尽管专家标注的安全数据集将提供理想的解决方案,但其获取既成本高昂又耗时。一种实际的替代方法,如图2所示,是首先从大量的开放、未标注数据中提取相关样本,然后在这些样本上对预训练模型进行微调。作者将这一初始步骤称为预微调。然后,预微调模型在进一步的针对特定任务的数据上进行微调,作者将其称为针对性微调阶段。这种两阶段微调方法旨在利用来自大量未标注开放数据的相关样本(如图1所示)。在本文中,作者深入探讨了大语言模型的两阶段微调方法。作者的目标是设计一个在预微调阶段进行样本选择的策略,确保预微调模型为针对性微调做好准备。尽管关于数据选择的研究已经很多(Ghorbani和Zou,2019年;Mirzasoleiman等人,2020年;Borosso等人,2020年),但许多现有技术仅适用于小规模数据集,因为这些技术常常依赖于重新训练模型并反向传播梯度。最近的研究(Xie等人,2023年)开始探索大规模语言数据的选择。这些研究的核心思想是选择那些仅与目标分布匹配的样本。然而,这个想法忽略了预训练分布:它们选择的样本可能仍然包括在预训练数据中已经得到很好表示的那些,而这些样本对微调的贡献可能很小,使得数据效率通常不令人满意。实际上,在低选择预算的情况下,使用现有方法在目标任务性能上的改进是微不足道的。作者将相关工作的扩展讨论留给附录A。
作者将与预微调数据选择相关的挑战总结如下:
- **任务有效性(G1):**选定的数据本质上应提高目标任务的性能。
- **数据效率(G2):**在有限的选定预算内,预微调应提高性能,考虑到随着样本量的增加,微调LLM的费用也会增加。例如,使用OpenAI的API推荐设置,在100K个小样本集(最大长度为128个token的短样本)上微调一个175B的GPT-3模型(davinci-002),其费用为1500美元a。
- **可扩展性(G3):**数据选择方法应适用于开放语言数据集的大小,并可以在有限的计算资源下完成。
- **泛化性(G4):**数据选择方案应适用于各种用例,无需进行大量修改,并能提供一致的性能提升。
为了解决这些挑战,作者引入了GOT-D(最优传输梯度数据选择),这是一种针对预微调的可扩展数据选择策略。作者的关键思想是优先选择那些最有效地将预训练分布推向目标数据分布的样本。直观地说,用这些样本微调预训练模型将提升其在目标数据集上的性能。在一定的假设下,作者证明了这种直觉的有效性,从而为作者的方法奠定了坚实的理论基础。尽管确切的预训练数据集并不总是可以访问,但众所周知,LLM主要利用常见的开放源进行预训练(Touvron等人,2023;Liu等人,2019)。因此,作者可以利用这些源来形成一个候选数据集,作为预训练分布的代理。
图2:数据选择设置。给定一个在预训练数据(红色)上训练的预训练模型,作者选择额外的数据(蓝色)来微调模型以应对目标任务。作者将微调分为两部分:I.预微调和II.针对性微调。由于标注的目标数据(绿色)在(II)中可能需要昂贵的整理,作者利用大型开源未标注数据来对模型进行预微调(I),作者称之为候选集。因此,作者的目标是在任何有限的选定预算内,从候选集中选择最佳子集,以最好地准备模型应对目标任务。
作者使用最优传输(OT)距离来衡量候选数据集与目标数据集之间的距离。通过距离的梯度可以找到拉扯一个分布向另一个分布的方向,该梯度可以从OT的对偶解中推导出来。通过整合熵正则化(Cuturi, 2013)和动量(Sutskever等人,2013)等优化技术,并利用并行GPU计算,作者可以高效地计算包含数百万样本的数据集的OT对偶解,在单个GPU上只需几分钟就能完成选择(解决G3)。作者的方法在多种任务上的有效性得到了验证,与现有数据选择方法相比,一致性表现出最佳性能(解决G4),特别是在仅5万样本的低选择预算下(解决G2)。在选定数据上的预微调相较于传统的一阶段微调显示出显著性能优势(解决G1),使用1万个样本将GPT-2的毒性水平降低了30%(第3.1节),并且在使用15万个样本时,将8个特定领域任务的平均性能(Gururangan等人,2020)提高了1.13%(第3.2节)。此外,作者还评估了在零样本任务中,该方法对高达27亿参数模型的有效性,仅用4万个样本作者的方法就将任务性能提升了13.9%。作者通过每种方法可视化了所选数据。作者的方法优先选择那些在预训练数据集中高度未被体现但对目标任务却很重要的样本,这为与目标任务的模型对齐提供了更直接的益处(附录E)。
Problem formulation
在给定的一个大型语言模型 ,在大量数据集 上进行预训练之后,作者考虑一个数据选择问题,旨在从大量可用的 未标注 数据集 中识别样本——称为候选数据集——用于 的无监督微调,或预微调。作者假设 的组成与 接近。尽管 的确切组成通常不公开,但众所周知,大型语言模型在预训练期间主要使用常见的开源数据(Touvron et al., 2023; Liu et al., 2019b),例如 Pile 数据集(Gao et al., 2020)。因此,这些开源数据集可用于构建 。值得注意的是,这些资源是免费在线开放的,无需额外的数据收集成本。与 类似, 由根据数据来源大致划分为不同领域子集的原始、未标注数据组成。
令 表示数据集中的样本数量。作者希望将原始模型 适应到有限的一组精选目标数据集 上的新任务。 通常与任务高度相关,包含高质量的标注(标签),但数据大小 非常小,不足以进行有效的任务适应——这对于许多新兴任务(例如,减少模型输出中的有害内容,为新产品建立客服机器人)尤为如此。 包括用于训练和测试的两个部分,分别表示为 和 。测试数据在开发阶段通常被保留,只有训练数据可以访问。作者的目标是基于目标训练数据 从 中选择一组 未标注 数据 ,在原始模型 上进行预微调,以获得任务适应模型 。然后,作者在目标训练数据 上对 进行微调,以获得准备部署任务的模型 。与直接在目标训练数据 上对原始模型 进行微调,得到 相比,本文考虑的两阶段微调方法进一步利用原始 未标注 数据中的信息来辅助任务适应。作者旨在识别 ,使得 在保留的测试数据集 上实现最佳性能提升。形式上,数据选择问题可以描述为
其中 表示用于评估模型 在测试数据 上的某种损失函数,其最小化器 是期望的最佳数据选择解决方案,可提供最佳模型性能。
为了反映现实世界的限制,作者也限制了所选数据的大小。例如,OpenAI将其模型的微调上限设置为5亿个标记(tokens)2,在默认设置下4个周期,这大约适合带有128个标记长度的10万短样本。作者将这视为实际的资源限制,并将所选数据的大小限制在一个阈值以下——即 ,其中 表示预微调数据大小的预指定阈值,这个阈值远小于标注数据的大小。这个限制还突显了作者的问题设置与之前工作(Xie等人,2023年;Gururangan等人,2020年)之间的一个关键区别,后者在相当于甚至显著大于预训练数据 的大量数据上继续对预训练模型进行无监督训练,这个过程通常被称为继续预训练。与继续预训练相反,作者考虑了一个实际场景,其中必须谨慎管理选择预算。
最优传输与数据选择
最优传输(Optimal Transport,OT)距离(Villani,2009年),以及其他分布差异度量,对于数据选择问题并不陌生。理论上存在一些结果,为训练数据和验证数据之间的分布距离作为下游模型性能的有效代理提供了正式保证(Redko等人,2020年)。从分析的角度来看,与其他度量(如KL散度(Kullback和Leibler,1951年)或最大平均差异(Szekely等人,2005年))相比,OT享有优势(是一个有效度量;与稀疏支持分布兼容;在分布支持变形方面是稳定的(Genevay等人,2018年;Feydy等人,2019年)。给定在空间 上的概率测度 ,OT距离定义为 ,其中 表示两个分布 和 之间的耦合集合, 是一个对称的正定成本函数(且 )。
现有理论结果表明,两个分布之间的OT距离为模型在一个分布上训练并在另一个分布上评估时的性能差异提供了一个上限(Courty等人,2017年;Shen等人,2018年;Just等人,2023年),这主要基于Kantorovich-Rubinstein对偶性(Edwards,2011年)。对于给定的模型 ,令 表示 的某个损失函数,该函数在训练样本 和验证样本 上是 -Lipschitz的。令 表示经验分布 和 之间的OT距离,并以 -范数作为成本函数 。那么,模型的训练损失和验证损失之间的差距可以通过OT距离进行如下界定:
对于使用经验风险最小化训练的现代机器学习模型,模型通常被训练至在训练样本上收敛并达到近乎为零的训练损失,即 。在这种情况下,训练数据与验证数据之间的OT距离为模型的验证性能提供了一个直接的代理,这已在几项研究(Kang等人,2023年)中得到经验验证。这立即为数据选择问题提供了一个原则性的方法——选择使给定验证集的OT距离最小的训练样本,或,也应该最小化期望中的验证损失。值得注意的是,对于其他距离度量也可以建立类似的结果(Redko等人,2020年)。因此,原则上,人们也可以基于其他度量最小化训练和验证之间的分布距离来选择数据。实际上,这种“分布匹配”思想已经成为几项研究(Pham等人,2020年;Everaert和Potts,2023年)的基础。
Data selection for fine-tuning
上述的“分布匹配”想法在其本身立场上是合理的,尽管它并不直接适用于微调问题。这个想法依赖于一个隐含的假设,即模型在训练时将收敛于所选数据集,反映出其潜在的分布,从而在该分布上达到最小的损失。这个假设对于从零开始训练是可行的。然而,在用比预训练数据少得多的数据微调LLM的情况下,通常在单个周期和较小的学习率下(Liu等人,2019b)就能在目标分布上取得最佳性能。微调数据的损失在完成时通常仍然远离零,而微调后的模型实际上反映的是预训练数据和微调数据加权的组合分布。作者将其形式化为以下引理。
引理1(微调模型的实际数据分布)。:对于一个在上通过经验损失最小化损失进行预训练的模型,当在小数据上进行轻微微调(即,单个周期或几个周期)的低数据情况下,其中,等同于将微调模型向最小化新损失的方向移动,其中比例是一个常数,加权组合是微调模型的有效数据分布.
证明在附录B.1中提供。微调模型用有效数据分布来描述,它是微调数据和预训练数据的加权组合。这也与实证结果(Hernandez等人,2021)一致,其中加权组合效果通过缩放法则中的“有效数据大小”来建模。由方程2,微调模型的目标任务损失因此被上界。这揭示了“分布匹配”想法的局限性:仅对微调数据最小化OT距离,即,并不能最佳地优化下游性能。特别是,在微调的低数据情况下,其中,通常相当小,由于与之间较大的不匹配,"分布匹配"想法可能不那么有效,如图3所示。因此,人们必须考虑预训练数据的分布,并选择最佳的微调数据以使其尽可能接近目标任务分布.

**作者的方法。**鉴于在数据选择时无法获得保留的测试数据,作者用与之同分布的任务训练数据来替代它。因此,式1中的数据选择目标转化为最小化和之间的OT距离。对于大型语言模型(LLMs),预训练数据主要基于常见的开放源数据,作者可以用它来构建。因此,对于现成的LLMs,通常可以假设大致与预训练数据集的分布相匹配,使得它们之间的距离相对较小——即对于某些小的,有。因此,候选数据集可以作为预训练数据集分布的代理。作者将作者提出的方法形式化为以下定理。
定理1(在低数据环境下对预训练模型进行微调的最优数据选择)。:对于在上通过经验损失最小化训练的模型,其损失在训练样本上是k-Lipschitz的,一个与预训练数据分布大致匹配的候选数据集,使得,以及与目标任务测试数据同分布的目标任务训练数据,在低数据环境下对小型数据集进行轻度微调(即单个周期或几个周期),其中,最优的微调数据选择可以通过OT问题的梯度给出,它最能最小化在目标任务上微调模型的理论损失上限。
其中 是预期的测试损失, 是通过微调模型最小化的训练损失, 是微调模型的有效数据分布 与目标任务分布 之间的 距离,该距离通过最优数据选择 来最小化。
图3:考虑一个在大规模语料库上预训练的大型语言模型(LLM),其中包含的猫的例子和的狗的例子。目标任务由的猫的例子和的狗的例子组成。模型对狗的知识相对缺乏将成为其在目标任务上的性能瓶颈。在将LLM部署到目标任务之前,作者从可用的数据集中选择样本进行轻量级的预热预微调,以更好地准备模型掌握目标任务知识。通过匹配分布到目标任务来选择数据,最终将选择的猫的例子和的狗的例子,其中只有的狗的例子会有帮助。在数据量很小的微调情况下,这种进一步的数据效率损失阻止了模型实现最佳可能的性能提升。作者的基于梯度的选择将选择的狗的例子,这最能帮助模型弥补其知识的不足。在这种情况下,作者的方法能够将微调的数据效率翻倍,这将转化为在下游任务上性能提升的增加。
备注1:证明在附录B.2中提供。这个想法是选择那些能够最小化微调模型的有效数据分布与目标数据分布之间的最优传输(OT)距离的数据。在数据量较少的条件下,其中对有效数据分布的更新很小(即),上界中的OT距离可以通过沿更新方向的一阶泰勒近似来近似,这样就可以直接从其梯度中获得OT距离的最小化器。方程式4中的偏微分是关于中每个样本概率质量的OT距离梯度。这个梯度表明了沿着中每个样本的方向OT距离将如何变化——即如果作者增加中某个样本的存在,OT距离将相应地增加或减少多少。是具有最大负梯度的样本集,增加这些样本的存在将最快速地减少到目标任务的最优传输距离,这转化为下游性能的提升。对于OT问题,获取这种梯度信息相对简单。由于最优传输问题本质上是一个线性规划,它在其对偶解中自然编码了梯度,可以使用(Just et al., 2023)提出的校准方法免费恢复。因此,人们只需要解决一个OT问题,对梯度进行排序,并选择对应于最大负值的样本。然后选择就完成了,对于数百万个样本,使用最先进的OT求解器(Cuturi et al., 2022)和GPU实现只需几分钟。
上述推导利用了选择候选数据来近似预训练数据在分布上的假设。在实践中,这一假设的实际要求是宽松的,在一般情况下是可以满足的。一个局限性是,作者的方法并不适用于那些需要与预训练数据的范围相差甚远的领域知识的任务。例如,将仅在英语文学上进行预训练的大语言模型(LLMs)适应到需要编程语言专业知识的任务。在这种情况下,这种小规模的非监督微调无论如何都不会有效(Hernandez et al., 2021)。
3 Evaluation
在本节中,作者实证验证了作者所提出方法在实际应用场景中的有效性。作者包含了三种不同的用例来验证所提出的方法,并展示其实用性和潜力:一个模型解毒的自然语言生成任务(第3.1节),8个具有预定义领域(生物医药/计算机科学/新闻/评论)的自然语言理解任务(第3.2节),以及8个来自GLUE基准(Wang等人,2018)的通用自然语言理解任务,这些任务没有预定义的领域(第3.3节)。这些案例代表了趋势需求,并涵盖了多样化的下游场景。作者将通用实验设置、 Baseline 方法和运行时分析的细节推迟到附录中。
Model detoxification with unlabeled data
LLMs被发现容易生成有毒的输出,包括粗鲁、剖析或露骨内容(McGuffie和Newhouse,2020;Gehman等人,2020;Wallace等人,2019;Liang等人,2022)。鉴于这些担忧,近年来减少模型输出中的毒性水平越来越受到关注(Wang等人,2022;2023)。基于DAPT,Gehman等人(2020年)提出通过对精选的干净样本数据集进行微调来净化模型,这些样本被标记为最低的毒性分数。尽管这种方法很有效,但它需要大量精心制作的干净数据集,这限制了其适用性。鉴于一个小的标记数据集,包含干净的(正面)或有毒的(负面)样本,作者的方法可以从 未标注 数据的池中选择样本,使模型倾向于正面样本或远离负面样本。
**评估设置。**成功的模型净化应有效降低毒性水平,而不会实质性损害模型的实用性。遵循以前的研究(Wang等人,2022;2023),作者在微调后评估模型的毒性和质量。
对于毒性评估,作者从RealToxicityPrompts(RTP)数据集(Gehman等人,2020年)中随机抽取10K个有毒和10K个非有毒提示,并采用广泛认可的自动毒性检测工具Perspective API3进行毒性评估,这是事实上的基准。具有TOXICITY分数的内容被归类为有毒,而分数的则被视为非有毒4。作者的评估利用两个关键指标:预期最大毒性_和_毒性概率。具体来说,_预期最大毒性_通过从每个提示的25个生成中提取最大分数来区分最坏情况下的毒性,这些生成因随机种子而异,然后对所有提示的峰值值进行平均。同时,毒性概率_估计生成有毒语言的实证频率,量化在整个25次生成过程中至少引发一次有毒延续的可能性。在整项研究中,除非另有说明,作者采用核采样(Holtzman等人,2019年)生成多达20个 Token ,与(Gehman等人,2020年;Wang等人,2022年)保持一致。为了消除毒性评估的影响,作者还包括使用OpenAI的ModernAPH5作为替代毒性度量。对于质量评估,作者检查LM的_perplexity_和_utility。《perplexity》(PPL)使用来自OWTC语料库的10k样本进行评估,作为生成语言的流畅性指标。《utility》通过LM在零样本学习框架内的下游任务表现来衡量。这包括8个不同的任务,包括问题回答、阅读理解和常识推理。作者展示了LM在这些任务上的平均准确率。完整描述和结果见附录C.4。
方法与 Baseline 。作者使用GPT-2(基础版,124M)作为作者的基础模型。作者考虑了5种方法:GOT-Dclean(作者的),GOT-Dcontrast(作者的),RTP,DSIR和RANDOM。RTP(Gehman等人,2020年)使用Perspective API评估每个样本的毒性分数,并选择分数最低的样本。对于GOT-Dclean(作者的)和DSIR,使用2.5K个清洁样本作为选择的目标,这些样本的TOXICITY ;对于GOT-Dcontrast(作者的),使用2.5K个有毒样本作为选择负面目标,这些样本的TOXICITY 。由于候选数据集只有一个领域,作者在添加随机选择 Baseline RANDOM时排除了DAPT Baseline 。用于选择候选数据集的是OpenWebTextCorpus(OWTC),这与GPT-2的预训练领域相同。用于选择的数据与评估中使用的提示完全不相交。作者执行了大小为10K和20K的数据选择,然后用学习率为的3个时期对基础GPT-2模型进行微调。关于实现和微调过程的详细信息可以在附录C.4中找到。
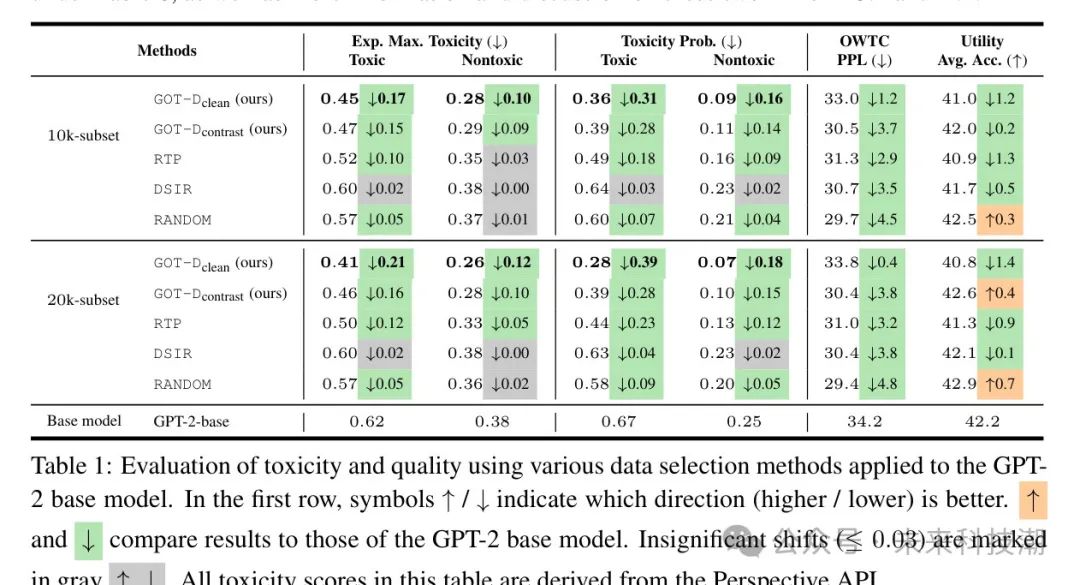
结果。作者在Perspective API下的评估结果在表1中呈现。与原始GPT-2相比,作者提出的数据选择方法显著降低了毒性。特别是对于20K子集,对于有毒提示,作者的方法将最坏情况下的毒性降低了;对于非有毒提示,降低了。作者观察到,对于有毒提示,毒性概率从降低到;对于非有毒提示,从降低到。作者强调,GPT-2是在一个40GB文本语料库(Radford等人,2019年)上预训练的。因此,使用精心挑选的仅20K的子集就能显著降低毒性,证明了作者提出的数据选择方法的有效性。这种显著的降低并没有在RTP和DSIR或随机选择中得到匹配。值得注意的是,在实现这些毒性降低的同时,下游任务的平均准确度只出现了轻微下降,从降到。最后,作者的方法在Moderation API评估下也取得了最佳性能,突显了作者方法的鲁棒性。由于篇幅限制,作者在附录中的表6中包含了Moderation API的结果,并在C.4和D.1中提供了有关这两个API的更多信息与讨论。
作者对来自Huggingface的base-uncased模型通过 Mask 语言建模(MLM)进行训练,遵循在 未标注 领域特定数据上训练的标准设置,即 Mask %的标记。作者考虑两种设置:(1)作者应用 Baseline 方法和GOT-D,有一个固定的选择预算为K样本,从附录C.1中定义的语料库中进行选择;(2)作者模拟一个更加“受限资源”的场景,其中作者将选择预算限制为K,下游训练数据大小限制为5K标记样本。所有MLM模型都在其选择的数据上训练了一个epoch。
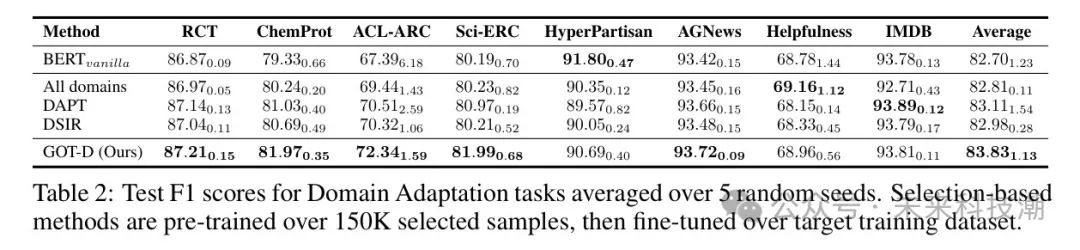
在第二阶段,作者在模型中添加了一个分类头,以在领域特定数据集上进行训练和评估。作者考虑了跨越4个领域的8个标记数据集进行作者的下游任务:生物医药(RCT (Dernoncourt Lee, 2017),ChemProt (Kringelum et al., 2016)),计算机科学论文(ACL-ARC (Jurgens et al., 2018),Sci-ERC (Luan et al., 2018)),新闻(HyperPartisan (Kiesel et al., 2019),AGNews (Zhang et al., 2015)),评论(Helpfulness (McAuley et al., 2015),IMDB (Maas et al., 2011)),如Gururangan等人(2020年)所整理。评估的指标是所有数据集的宏F1分数,除了ChemProt和RCT使用微F1分数,如(Beltagy等人,2019年)。有关其他设置和超参数选择,请读者参考附录C.5。
** Baseline 方法。**作者将GOT-D与四个不同的 Baseline 进行了比较:BERT(纯),它直接在可用的目标训练集上对预训练的模型进行微调,作为预期性能的下界;所有领域,其中预训练数据从候选集中的所有领域均匀选择;DAPT(Gururangan等人,2020年)和DSIR(Xie等人,2023年),与GOT-D有相同的选择预算以进行公平比较。所有 Baseline 也使用相同的模型:bert-base-uncased。对于受限资源实验(表3),作者选择“curated-TAPT(带精选领域数据集的TAPT,TAPT/c (Gururangan等人,2020年))”代替DAPT,因为DAPT是为大型预训练语料库设计的,而TAPT/c固有的选择较小的语料库。
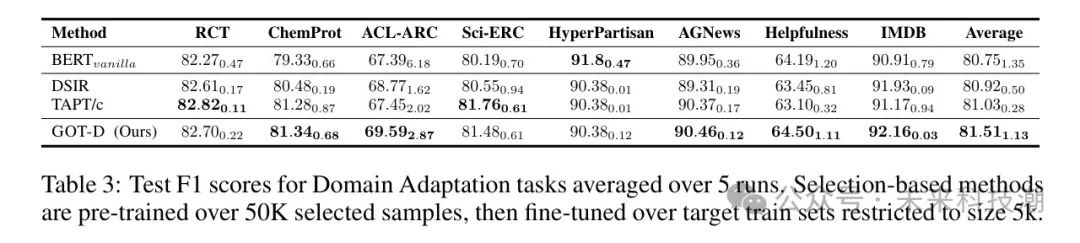
**结果。**从表2中作者可以观察到,GOT-D在平均性能上超过了其他选择 Baseline ,在15万选择预算的情况下,比普通的bert-base模型提高了大约1.2%,比DAPT和DSIR Baseline 提高了大约0.7%到0.9%。结果表明,即使有其他 Baseline ,一个小的预微调语料库也足以使性能获得显著提升,超过普通的BERT。仔细观察,作者注意到对于有帮助性、IMDB、AGNews和RCT的数据集,可用的标记训练集相对较大,因此相对于bert-base模型的性能提升有限。相反,ChemProt、ACL-ARC和Sci-ERC数据集目标训练数据较小,性能提升较大(例如,在ACL-ARC中提高了约5%)。作者发现,从所有领域随机选择预训练数据(随机 Baseline )可以提高性能,但与其他方法相比,这些提升是微不足道的。受到在较小数据集上进行域适应改进较大的启发,作者将所有训练集的大小限制为5K,以创建资源受限的环境。此外,作者只为无监督MLM预训练选择了50K个样本。表3的结果显示,在Vanilla BERT以及DSIR和TAPT/c的平均性能上,GOT-D在这个设置中显著提高了性能。
Task-adaption without a pre-defined domain
大型语言模型(LLMs)展现出了解决多样化和复杂任务的能力(Ge等人,2023年;Bubeck等人,2023年)。为了衡量这种能力,引入了一个标准化的基准测试——通用语言理解评估(GLUE)(Wang等人,2018年),它通过一系列具有挑战性的数据集测试模型的自然语言理解(NLU)能力。作者将这个基准应用于评估在作者选择的数据上微调后的LLM能多大程度提高模型的NLU能力。
实验设置。 在此,作者的任务是选择数据以微调bert-base模型(由Huggingface(Wolf等人,2019年)提供)。接下来,作者通过在八个GLUE任务上调整模型来评估GLUE基准。对于每个任务,作者测量每个任务测试集上的准确度,除了CoLA数据集,作者报告Matthew的相关系数。结果是在三个随机种子上的平均值,并在下标中报告标准差。
在这里,作者为5万预算引入了两种数据选择设置。首先,在通过 Mask 语言建模(MLM)微调BERT模型后,作者进一步在最多5千训练数据的每个GLUE任务上对其进行微调(表4(下));其次,在通过MLM微调BERT模型后,作者进一步在包含全部训练数据的每个GLUE任务上进行微调(表4(上))。作者将作者的数据选择性能与 Baseline 方法进行了比较:BERT,作者没有提供 未标注 数据,直接在任务上进行微调,DSIR和TAPT/c。附加的结果和超参数设置可以在附录C.6中找到。
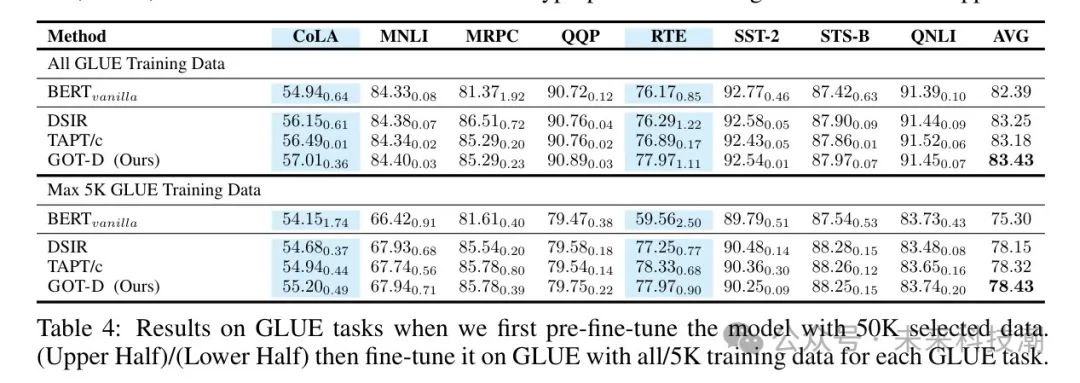
结果。 从表4可以看出,在两种设置下,作者的方法在平均性能上始终优于其他数据选择方法,并且分别比vanilla BERT模型提高了和。这表明无论数据选择预算如何,作者的方法不仅可以超越vanilla模型的性能,还可以超越当前最先进的数据选择方法,从而进一步提高模型的NLU性能。此外,作者注意到作者的选择方法在初始性能低于其他任务的CoLA上获得了更大的改进(约2%),在RTE上获得了约18%的改进。由于其他任务在vanilla模型上已经获得了很高的性能,即使提供了更多的微调数据,也没有太大的提升空间。而初始性能较低的任务(蓝色)允许微调实现更多的改进。另外,作者的方法在获得更高的平均GLUE分数方面始终击败其他方法。原因是作者在数据选择的计算中包含了预训练数据的额外信息,这允许对每个特定任务进行更明智的数据选择。另一方面,其他方法通过直接匹配任务分布找到数据点,而没有关于预训练模型中使用的数据分布的额外信息,这可能会影响任务性能。作者的方法GOT-D在各种设置中在平均GLUE分数上建立了稳定的优势,证明了在提高这些任务性能方面是一种更合适的数据选择方法。如表4(上)所示,在任务特定的标记数据较少的情况下,这些数据往往很难整理,作者可以通过添加精心选择的廉价的 未标注 数据来获得更多的性能提升。
4 Conclusions
作者引入了预微调作为一种通用范式,以利用开放、 未标注 的数据来提高任务适应性能。作者强调了在预微调背景下传统数据选择方法的局限性,并提出了一种新的原则性方法(GOT-D),它有效地将预训练分布向目标分布转变,而不仅仅是与目标对齐。作者展示了作者的方法在多种任务上的性能优势和速度优势,能够高效地扩展到数百万样本。##致谢
RJ和ReDS实验室感谢亚马逊-弗吉尼亚理工大学高效和健壮机器学习倡议、美国国家科学基金会提供的资助,资助编号分别为IIS-2312794、IIS-2313130和OAC-2239622。作者感谢美国弗吉尼亚州布莱克斯堡弗吉尼亚理工大学的Ming Jin教授和Peng Gao教授提供慷慨的计算资源。
Appendix A Extended related work
B.1 引理1的证明 B.2 定理1的证明 C 实验细节 C.1 模型和数据集 C.2 数据选择方法的实现 C.3 运行时分析 C.4 关于解毒实验的进一步细节 C.5 关于领域适应任务的进一步细节 C.6 关于GLUE任务的进一步细节和结果 D 讨论 D.1 对Perspective API和Moderation API的分析 D.2 泛化与实施讨论 E 使用更大模型对零样本任务的实验 E.1 实验设计 E.2 AGNews数据集的结果 E.3 BoolQ数据集的结果
Appendix A Extended related work 2024-05-09-02-59-02
数据选择问题已经在各种应用中得到了广泛研究,如视觉(Coleman等,2019;Kaushal等,2019;Killamsetty等,2021;Mindermann等,2022),语音(Park等,2022;Rosenberg等,2023),以及语言模型(Coleman等,2019;Mindermann等,2022;Aharoni & Goldberg,2020),近年来引起了越来越多的关注。
现有的针对语言数据选择的工作主要集中在为预训练进行数据选择(Brown等,2020;Gururangan等,2020;Hoffmann等,2022)或从零开始,或进行持续预训练——在大小与预训练数据相当甚至更大的数据集上对预训练模型进行无监督的持续训练。在这些设置中,数据选择预算的规模从数百万到数十亿样本不等。例如,Gururangan等(2020)表明,在特定领域的数据集上继续对模型进行预训练可以提高其在该领域任务上的性能;Xie等(2023)使用带有10K个箱的重要性重采样在简单的双词特征上进行选择,为领域/任务自适应预训练选择数百万样本。这些数据选择方法在为细调选择数据时表现不佳,后者的规模通常要小得多。在百万以下的选择规模下,它们的性能提升往往变得微不足道。特定问题启发式方法(Chowdhery等,2022)采用简单的标准来区分给定语言模型在特定数据集上的数据质量。例如,Brown等(2020);Du等(2022);Gao等(2020)使用二分类器来确定样本是否接近被认为是高质量“正式文本”。这类方法在数据选择上的有效性通常局限于特定用例,并且容易在迁移到不同问题时失败(Xie等,2023)。这种方法通常需要依赖数据的非平凡调整,因此与作者的目标——为一般问题设计自动化数据选择 Pipeline ——是正交的。
微调LLM对于将预训练模型定制到特定用例至关重要。它可以显著提高模型的下游性能(Gururangan等人,2020年),或者在不需要大量计算的情况下使模型的输出与人类偏好保持一致(Ouyang等人,2022年;Christiano等人,2017年)。高效的方法如LORA(Hu等人,2021年)允许仅训练部分参数,以在比从零开始训练所需数据小得多的情况下有效地更新模型。传统上,微调样本的选择依赖于人工策划或简单的方法。例如,策划的TAPT(使用策划的领域数据集的TAPT,TAPTc(Gururangan等人,2020年)),DAPT(Gururangan等人,2020年)的一种变体,通过寻找与目标任务最近的邻居来选择用于任务适应的数据,通常最终会选择大量重复的样本。尽管有前景的潜力,但选择微调数据的原则性方法仍然在很大程度上是空白的。
一种流行的方法是通过匹配分布来选择数据,其中理论结果(从领域适应中广泛可得)为训练数据和验证数据之间的分布距离作为下游模型性能的有效代理提供了正式保证(Redko等人,2020年)。Xie等人(2023年)表明,目标任务与模型训练的领域之间的KL散度与模型的下游性能高度相关,而Everaert & Potts(2023年)使用迭代梯度方法通过最小化KL散度来修剪训练样本。Kang等人(2023年)使用最优传输直接从每个源的训练数据组成预测模型性能。Pham等人(2020年)使用不平衡最优传输(UOT)从预训练数据集中选择样本以增强图像分类任务的微调数据集。这些方法通常不适用于从语言数据集中选择样本的可扩展性。Everaert & Potts(2023年)能够应用于k个簇,而对几百万个样本进行聚类则使用了每个带有个CPU的台服务器。Pham等人(2020年)需要从原始OT问题中获得传输图,这对于即使是10k个样本也很难解决,因此也依赖于聚类。Kang等人(2023年)找到了多个数据源的最佳组成,而不是选择样本。数据估值方法旨在衡量每个样本对模型性能的贡献,这自然为数据选择提供了一个可行的工具。值得注意的是,基于模型的Shapley(Jia等人,2019年;Ghorbani & Zou,2019年),LOO(Ghorbani & Zou,2019年;Koh & Liang,2017年)方法,以及模型无关的方法(Just等人,2023年;Kwon & Zou,2023年)。尽管在各自的应用中取得了丰硕的成果并提供了有价值的见解,但众所周知,这些方法通常存在可扩展性问题。基于模型的方法需要重复进行模型训练,并且通常难以应用于几千个样本。一个最近的例子,Schoch等人(2023年)使用采样方法来加速Shapley风格的 方法,以选择微调LLM的数据,并扩展到选择k个子集。很难想象将其应用于实际语言数据集的规模。Just等人(2023年)利用OT问题的梯度提供了一种高效的数据估值度量方法,但基于梯度的选择并不一定与目标分布对齐,通常情况下性能一般。CoresetsBorsos等人(2020年);Mirzasoleiman等人(2020年)旨在找到一个代表性的样本子集以加快训练过程,这可以表述为一个优化问题。这个过程相当计算密集,并且难以在语言应用的实际规模上应用。
Appendix B Proofs
附录B证明部分的开头。
Proof of Lemma 1
定理2(对微调模型的 有效数据分布(重述))。
对于在上通过经验损失最小化损失进行预训练的模型,在低数据环境下对小型数据集进行轻度微调(即,单个周期或几个周期),其中,等同于将微调模型向最小化新损失的方向移动,其中比例常数,加权组合是微调模型的有效数据分布。
证明:设预训练模型由参数表示,微调模型由参数表示。由于是通过在预训练数据上最小化损失函数得到的,作者有
由于是损失函数的最小值,根据最优化条件,在非退化情况下,必须是预训练数据上损失函数的局部最小值,使得
当基于梯度优化器在数据上进行微调时,模型参数沿着最小化微调数据上的损失的方向更新,可以表示为
不失一般性,假设损失函数在数据上是可加的(例如,交叉熵损失),使得
然后,作者有
这表明微调步骤将最小化上损失的预训练模型向最小化数据混合上的新损失的方向移动。对于有限步骤的轻度微调,微调模型本质上最小化数据的加权组合,其中比例取决于微调强度(例如,学习率、步数等)。_
Proof of Theorem 1
定理2(在低数据环境下微调预训练模型的最优数据选择(重述)) ._ 对于一个在 上通过经验损失最小化损失 进行预训练的模型 ,该损失在训练样本上是 -Lipschitz 的,一个候选数据集 大致匹配预训练数据 的分布,满足 ,以及目标任务训练数据 与目标任务测试数据 同分布,当在低数据环境下对小型数据集 进行轻微微调(即单个周期或几个周期)时,最优的微调数据选择可以通过一个OT问题的梯度给出_
这最能最小化微调模型 在目标任务 上的损失的理论上界
其中 是期望的测试损失, 是通过微调模型最小化的训练损失, 是微调模型的有效数据分布 与目标任务分布 之间的OT距离,该距离通过最优数据选择 最小化.
证明:从等式2的 Kantorovich-Rubinstein 对偶性,作者有了测试损失和训练损失之间的差距上界由训练数据和测试数据之间的OT距离界定。
在目标任务训练数据 与 同分布的前提下,作者有
进一步地,考虑到候选数据集 与预训练数据 的分布大致匹配,即 ,作者有
在低数据微调方案中,其中 且权重 合理地小,作者进行一阶泰勒近似,其中
然后,通过最小化OT距离可以给出最优的微调数据选择 :
其中 表示在下游任务上的预期测试损失, 表示微调模型最小化的预期损失,它相当小,使得上述预期测试损失的上界主要由OT距离决定。不等式 (6) 表示:
哪个最能最小化在目标任务 上微调模型 损失期望的理论上界。
Appendix C Experimental details
附录C 实验细节部分的开头。
Models and datasets
模型与数据集部分开始。
c.1.1 Models
在第3.1节中,作者对未经指令调整或RLHF的GPT-2(1.24亿基础版)文本补全模型进行了评估。对于GPT-2,作者依赖Hugging Face Transformers库(Wolf等人,2019)。GPT-2在大量的互联网文本上进行预训练,这些文本主要来源于社交平台Reddit上分享的链接,总计约40GB。
BERT-base-uncased:BERT是一个基于Transformer的LLM,由谷歌在2018年首次引入(Devlin等人,2018)。BERT使用 Mask 语言建模(MLM)在Toronto BookCorpus(8亿单词)和英文维基百科(25亿单词)上进行预训练。BERT包含1.1亿个参数,由12个编码器组成,每个编码器有12个双向自注意力头。可以从流行的Huggingface库中下载BERT模型6。Hugging Face库还提供了多种工具,有助于构建LLM训练流程,例如它们的分词器和训练器方法。distilBERT-base-uncased:(Sanh等人,2019)是谷歌BERT系列LLM的扩展——提出了原始BERT的简化版本。它是一个较小的通用语言模型,有6600万个参数——通过从更大的基于Transformer的模型(BERT)进行预训练进行提炼。DistilBERT使用与BERT相同的语料库进行训练,并采用知识提炼中常见的师生框架。
c.1.2 Datasets
3.1节中用于NLG任务的候选数据集: 设置与以前的工作(Gehman等人,2020年)保持一致——作者使用OpenWebTextCorpus(OWTC)(Gokaslan和Cohen,2019年)作为候选数据集,以选择3.1节中实验的数据。作者丢弃少于个字符(约个标记)的样本,并将其余样本截断到个字符,最终得到大约M个密集个标记的样本。作者考虑的选择预算从k到k,相应的选择比例在之间。
3.2节和3.3节中用于NLU任务的候选数据集: 遵循(Xie等人,2023年)的设置,作者构建了候选数据集以替换The Pile Gao等人(2020年),因版权问题该数据集已不再可用。作者包含了7个最常用的高质量文本领域:AmazonReviews、Pubmed、arxiv、OWTC、RealNews、Wikipedia、BookCorpus,其中Pubmed和arxiv分别是生物医学和计算机科学的科学论文数据集。Amazon Reviews主要由少于个字符的评论组成——因此作者在每个样本中拼接多个评论,然后将其截断到个字符(约个标记);对于其他原始样本远长于个字符的语料库,作者将每个原始样本截断为多个个字符的样本。作者从每个领域获取个样本以避免选择比例过于极端,最终得到大约个密集个标记的样本。作者考虑的选择预算范围从k到k,选择所有领域时的选择比例在之间,选择单一领域时的比例在之间。
- OpenWebTextCorpus(OWTC)是一个源自Reddit帖子中链接的英文网络文本的语料库,这些链接获得了或更高的“karma”(即,人气)分数。可在以下网址获取:https://skylion007.github.io/OpenWebTextCorpus/
- AmazonReviews是关于亚马逊产品的客户反馈数据集,主要用于情感分析。可在以下网址获取:https://huggingface.co/datasets/amazon_us_reviews
- BookCorpus是来自不同未发表作者的11,038本免费小说书籍的集合,涵盖16个副体裁,如浪漫、历史和冒险。根据https://yknzhu.wixsite.com/mweb编译
- Pubmed包含来自PubMed数据库的篇与糖尿病相关的出版物,分为三个类别,带有个引文链接的网络。可在以下网址获取:https://www.tensorflow.org/datasets/catalog/scientific_papers
- Arxiv是一个包含1.7百万篇arXiv文章的数据集,适用于趋势分析、推荐系统、类别预测和知识图谱创建。可在以下网址获取:https://www.tensorflow.org/datasets/catalog/scientific_papers
- RealNews是一个包含来自CommonCrawl的新闻文章的大型语料库,仅限于谷歌新闻索引的5000个新闻领域。可在以下网址获取:https://github.com/rowanz/grover/blob/master/realnews/README.md
- Wikipedia是从维基百科转储中收集的数据集,每个数据集按语言分割。可在以下网址获取:https://www.tensorflow.org/datasets/catalog/wikipedia
c.1.3 Evaluation Metrics
作者在第3节中定义了以下指标(M1-M4),以实证量化每个目标满足的程度。
- 任务有效性(M1): 预微调模型与原始模型在目标任务上部署时的性能增益,通过来衡量。
- 数据效率(M2): 选取的数据大小限制在KK的范围内,在实验中进行评估。作者衡量在这一数据量上建立的性能增益。
- 可扩展性(M3): 作者衡量并比较了每种方法的时间与资源使用情况。
- 泛化能力(M4): 作者在不同的场景下以相同的设置应用每种方法,并检验它们性能的一致性。
Implementation for data selection methods
OT选择(作者的方法):首先,作者对每个域数据集进行快速的领域相关性测试,从每个域数据集中随机抽取10k个样本,并计算每个样本到目标任务数据的OT距离。作者从具有最小OT距离的两个域(各1M个)中随机选择2M个样本来构建重采样的候选数据集。作者尝试过用5M个样本来构建候选数据集,但观察到的评估结果没有差异。作者使用在目标任务上微调的蒸馏BERT来嵌入候选数据集,在单个A100 GPU上耗时不到1小时。然后,在嵌入空间中解决目标任务数据与候选数据集之间的OT问题,从其对偶解中获取梯度,并选择梯度最大的负样本。作者使用ott-jax(Cuturi等人,2022年)作为OT求解器,它利用GPU进行加速计算。
DSH.(Xie等人,2023年) 首先,作者对原始数据进行预处理,将候选数据重新格式化和分块成指定长度,并按照原文应用质量过滤器。利用处理后的候选数据和质量过滤器,作者计算了候选数据集和目标任务数据在n-gram特征空间中的相应重要性权重估计器。然后,计算了候选数据集中每个样本的重要性分数。这是通过日志重要性权重加上IID标准Gumbel噪声实现的。随后选择了重要性分数最高的样本。
DAPT. 最初,DAPT(Gururangan等人,2020年)涉及在一个大型领域特定语料库上进行预训练(最小的领域有2.2M个样本)。作者将DAPT的实现调整为在保持相同的选择策略的同时限制选择预算,并在这些选择上进行预训练。虽然原始的DAPT实现使用私有数据进行预训练,但作者从作者的语料库中相关领域进行采样。这个 Baseline 假设可以访问领域特定的 未标注 数据。
TAPT/c. 遵循DAPT论文中的原始设置,将选择的范围细化到目标任务领域的域数据集。首先,在从假设的域数据集中随机抽取的1M个示例上训练轻量级预训练模型VAMPIRE(Gururangan等人,2019年),然后用它来嵌入整个域数据集。然后,在这个嵌入空间上选择个最近的邻居,其中由选择预算决定。
所有领域:这个 Baseline 模拟了一个数据集的领域未知的设置——因此作者从每个领域等比例选择。作者将数据选择预算平等地分配到每个域数据集,并进行均匀抽样。
Runtime analysis
在3.1节和3.2节的实验中,作者记录了具有非平凡计算需求的数据选择方法的时间,包括GOT-D(作者的方法)、DSIR、TAPT/c。本研究旨在展示作者的方法与其他相关数据选择 Baseline 相比的可扩展性。
对于GOT-D(作者的方法),作者使用了一块Nvidia A100 GPU。对重采样候选数据的初始域相关性测试需要分钟来完成。作者使用大型批量大小在目标任务数据上对蒸馏BERT模型进行少量轮次的微调,这需要分钟。作者使用微调后的模型嵌入个例子的重采样数据集,这需要小时。在目标任务数据与候选数据之间解决OT问题需要分钟。
对于TAPT/c,作者使用了一块Nvidia A6000 GPU。在目标域的样本上预训练VAMPIRE模型需要小时,嵌入域样本需要小时。选择时间与目标任务样本的数量成比例,从k样本的分钟到k样本的小时。
DSIR是仅限CPU的方法,在AMD EPYC 7763 64核CPU上使用多个核心。计算所有样本的n-gram特征空间需要小时,计算重要性权重需要小时,选择过程需要小时。
Further details on detoxification experiments
作者在第3.1节中对实施细节和完整的实验结果进行了详细阐述。
RELATOXICCPROMPTS数据集(Gehman等人,2020年)引入了一个广泛认可的基准数据集REALTOXICPROMPTS,旨在提供一个标准的评估协议,用于评估LMs的毒性。该数据集源自OWTC语料库,并将每个提取的句子分成两部分:提示和相应的延续。使用Perspective API的分数,数据集被分为两个子集:有毒提示和无毒提示。表5展示了该数据集的一些示例。

毒性评估API 为了确保全面可靠的毒性评估,作者采用了两种最广泛认可的毒性评估API:
- Perspective API:由Jigsaw提供,Perspective API利用机器学习模型识别和评估文本中的有毒语言水平。作者使用此API提供的TOXICITY分数进行评估。
- Moderation API:由OpenAI提供,Moderation API旨在过滤掉可能不安全或不适当的内容,使用先进的语言模型。该模型根据给定的输入文本返回一系列分数,指示仇恨、威胁、骚扰、暴力等。作者在研究中将返回分数中的最大值作为毒性分数。
警告:以下内容包含有毒语言。
在表5中,作者展示了有毒和无毒提示的示例,以及它们从两个API获得的毒性分数。
生成过程在生成过程中,作者将输出限制为最多20个 Token ,并在生成时在句尾(EOS) Token 处截断句子。作者将温度参数设置为1,并采用核采样,p=0.9。为了加快对多个提示的生成过程,作者利用批量生成。微调过程遵循(Gehman等人,2020年;Wang等人,2022a)的配置,作者对LMs进行3个周期的微调。作者使用Adam优化器(epsilon=1e-5,beta-1=0.9,beta-2=0.95)初始lr=2e-5,并将权重衰减设置为0.1。所有实验均使用NVIDIA RTX A6000 GPU进行。
Moderation API的毒性评估结果 使用Moderation API获得的毒性评估结果在6中展示。与从Perspective API获得的结果一致,作者的方法有效地减少了毒性,并且显著优于所有 Baseline 方法。重要的是,应该强调的是,无论是在数据收集阶段还是在数据选择过程中,都没有使用Moderation API。这突显了作者的方法的通用性和鲁棒性,在不针对特定评估工具定制的情况下实现了显著的毒性减少。
效用评估的细节作者包括以下8项任务:
- ANLI(Nie等人,2019年)是一个大规模的NLI基准数据集。
- BoolQ(Clark等人,2019年)是一个带有二元是非回答的问题回答数据集。
- HellaSwag(Zellers等人,2019年)是一个用于评估常识NLI的数据集。
- LAMBADA(Paperno等人,2016年)用于通过词预测任务评估语言模型对文本理解的能力。
- PIQA(Bisk等人,2020年)检查关于物理交互的常识推理。
- RACE(Lai等人,2017年)是一个大规模的阅读理解数据集,包含多项选择题。
- WiC(Pilehvar和Camacho-Collados,2018年)测试上下文中的词义消歧。
- WinoGrande(Sakaguchi等人,2021年)是一个用于共指解析的数据集,包含具有挑战性的winograd schema风格问题。
作者采用了(Gao等人,2021年)的评估框架。表7提供了各种方法在下游任务准确性方面的详细分解。

c.5.1 Unsupervised Pre-training
表6:使用各种数据选择方法对GPT-2基础模型应用审查API进行毒性评估。在第一行,符号表示哪个方向(更低)更好。和将结果与GPT-2基础模型进行比较。变化幅度在无显著变化(定义为变化)的用灰色标记。关于MLM训练的内容在表100.5.1中提及。作者发现,在第C.1节中提到的作者的数据语料库具有理想的标记大小。作者从1e-4的学习率开始,尝试降低以获得更好的预期训练损失。然而作者发现,在大多数情况下,1e-4的学习率是理想的。较大的学习率并没有导致训练损失降低。这与(Gururangan等人,2020年)的观察一致,尽管他们的预训练规模比作者的要大得多。
如第3.2节所述,作者通过GOT-D和相关 Baseline 在两个选择预算 - K和K上进行数据选择的无监督预训练。在此过程中,作者使用了表100.5.1中提到的超参数。在(Gururangan等人,2020年)策划的目标数据集大小不一(Hyperpartisan为个样本,RCT为个样本),作者相应地调整了微调的周期数。对于表2,作者发现对于较大的数据集(IMDB、Helpfulness、AGNews和RCT),在3个周期内达到最佳性能,而其余数据集相当小(小于5K)需要10个周期。与(Xie等人,2023年)的观察保持一致,作者在Reviews领域使用个标记,并将其固定为其他领域(BioMed/CS/News)的。对于表3中的资源受限设置,作者将周期数固定为,因为训练集大小限制为k。对于较大的数据集,使用固定的随机种子随机抽取k训练集。最后,选择度量(遵循(Gururangan等人,2020年)的实施)是F1分数,其中CS/News/Reviews领域的成果包含宏观F1分数,而生物医学领域使用微观F1分数。
c.6.1 Experimental Details and Hyperparameters
对于GLUE评估,作者选择了8个任务(CoLA、MNLI、MRPC、QQP、RTE、SST-2、STS-B、QNLI),并排除了WNLI。
表8:无监督MLM微调的超参数列表。

作者列出了用于MLM微调以及GLUE任务特定微调步骤的超参数。作者注意到这些超参数在所有任务中都被使用。遵循(Liu等人,2019;Xie等人,2023)中的设置,作者改为采用bert-base-uncased-mnli(即,在MNLI数据集上微调的模型)作为RTE和MRPC任务的预训练模型。#### c.6.2 额外结果
作者在表12中提供了在有限的预算下的额外结果,即预微调数据为20K,标记目标数据为5K。

Appendix D Discussion
附录D讨论部分的开头。
Analysis on Perspective API and Moderation API
视角API在模型净化研究中被广泛使用,与人类判断有很好的相关性(Gehman等人,2020;Liang等人,2022;Wang等人,2022a;2023)。然而,它也因潜在的偏见(Gehman等人,2020;Xu等人,2021;Welbl等人,2021)和准确性问题(Wang等人,2022a)而受到关注。此外,由于API会定期更新,随着时间的推移直接比较可能导致不一致。为了说明这一点,作者重新审视了之前的13个提示示例。值得注意的是,这些示例在REALTOXICPROMPTS数据集中的毒性得分最初来源于视角API,而作者最近(截至2023年9月)使用同一API获得的得分显示出显著差异。
考虑到这一点,作者用OpenAI的Moderation API来增强作者对毒性的全面理解。在评估了k个实例样本后,作者发现两个API产生的毒性得分之间存在0.5977的相关性。这种关系在图4中进行了可视化。有趣的是,有些情况下两个API在结果上存在显著分歧,如表14所示。


Generalization and implementation discussion
表10:无监督MLM微调的超参数列表。

表9:有监督MLM微调的超参数列表。

第2.3节中的推导利用了选择候选数据的假设来近似预训练数据在分布上的情况。实际上,对这个假设的实际要求相当宽松,在一般情况下很容易满足。唯一的限制是,作者的方法不适用于需要与预训练数据范围完全不同的领域知识任务。例如,将仅在英语文学上预训练的大语言模型(LLMs)适配到需要编程语言专业知识的任务。在这些情况下,这种小规模的无监督微调无论如何都是无效的。对于数据领域/来源,可以是的超集、子集或在一定程度上有重叠。这似乎与需要构建以近似的观点相矛盾。作者注意到,对于LLMs,预训练数据通常相当大,涵盖各种领域,每个领域的样本都相当丰富。来自不同领域/来源的样本在英语素养或专业知识方面往往比它们出现的要高度相似。例如,BERT仅在包含高质量文本的BookCorpus和Wikipedia样本上进行预训练,这似乎并不包括评论或科学论文。实际上,典型用于评论的非正式语言在BookCorpus的对话中占有很大比例,而像IMDB这样的评论任务与BookCorpus的相似度比精挑细选的评论数据集要高。此外,Wikipedia包含科学论文的大部分元素,如推理逻辑、领域知识、正式引用等。从高层次的角度看,这些常用的数据源在数据分布上通常有相当高的相似性,而用不同组成构建的数据集通常效果或多或少相同。
表11:GLUE任务特定微调的超参数列表。

表12:当作者首先使用20K个选定的数据对模型进行预微调,然后在每个GLUE任务上使用5K训练数据对模型进行微调时,在GLUE任务上的结果。
此外,在实践中,作者通常不需要使用中的所有可用数据来进行选择。微调数据的大小如此之小,以至于它通常总可用数据的1%。这种过度极端的选择比例可能会导致数值问题以及额外的复杂情况,如所选数据单调。对于给定的任务,通常可以筛选出大量来自低质量来源或不相关领域的数据,因为这些样本无论如何都不会被选中。实际上,作者发现选择一个大于一定大小的数据集将不再提供任何好处。因此,在实施作者的数据选择方法之前,作者首先计算目标任务数据与池中每个来源/领域的样本之间的OT距离,以衡量它们与目标任务的关联性,这是相当简单的,因为一个小样本就足够了。然后,作者根据每个来源/领域与目标任务的相关性确定比例,从构建一个重新抽样的候选数据集。这本质上减少了重新抽样的候选数据集与目标任务在分布上的距离。基于此方法的选择融合了基于匹配分布的数据选择方法的特点,这有效地平滑了数据选择问题,并显示出提高解决方案质量的成效。然后,作者对重新抽样的数据集进行标记和嵌入,将它们转换到某个特征空间。通过对进行下采样到,可以在数据选择中用计算资源交换更强的嵌入方案,这对于精细的任务尤其有利。使用单个GPU,可以在一小时内完成重新抽样、嵌入和选择整个过程。## 附录E 使用更大模型的零样本任务实验
Experimental design
在本节中,作者展示了GOT-D在提高LLM零样本学习能力的潜力。作者评估了OpenAI的GPT-2 XL(1500亿)(Radford et al., 2019)和Eleuther AI的GPT-neo(2700亿)(Black et al., 2021),这两种模型广泛应用于零样本学习研究(Li和Qiu,2023;Chang和Jia,2023)。作者的分析包括两个基准任务:AG News(Zhang et al., 2015),一个关注新闻分类的文本分类挑战,以及BoolQ(Clark et al., 2019),一个涉及自然是非问题的问答数据集。
作者模型的评估始于在预微调之前分析其零样本性能。随后进行预微调过程,根据第C.2节详细描述的过程选择一个数据集。数据选择过程与第3.1节中的NLG任务相似。给定几千个** 未标注 **的训练样本(AG News使用SK,BoolQ使用9K)作为目标数据,作者测试不同的数据选择方法(GOT-D、DSIR、TAPT/c)从候选数据集中选择样本以预微调模型。
表13:使用Perspective API(2023年9月)的毒性评分重新审视示例提示,并与REALTOXICPROMPTS数据集的原始评分进行比较。评分之间的显著差异突显了Perspective API评估的不断发展性质。

表14:来自REALTOXICPROMPTS数据集的示例提示,其中Perspective和Moderation API的毒性评分差异很大。
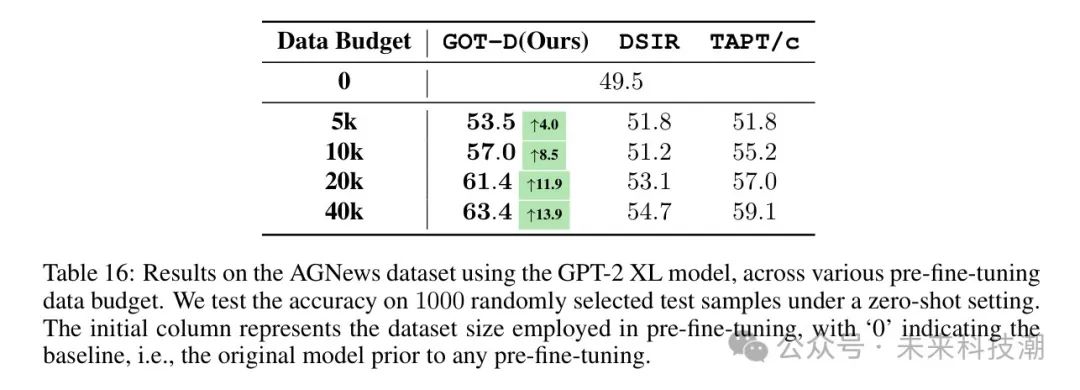
对于在单一数据集OpenWebTextCorpus(OWTC)上进行预训练的GPT-2 XL,作者使用相同的数据作为候选数据集。所有数据选择方法(GOT-D、DSIR、TAPT/c(经过筛选的TAPT/TAPT使用筛选过的数据集))从相同候选数据集中选择。此设置与第3.1节中的NLG任务相同。此外,在设置良好对齐的情况下,作者还消融了用于计算OT距离的嵌入空间选择的影响。作者使用精简版BERT、sentence-transformer(Reimers和Gurevych,2019)和BERT词元对样本进行嵌入测试。GPT-neo(2700亿)在ThePile数据集(Gao et al., 2020)上进行预训练。作者构建了一个包含7个领域样本的替代候选数据集(附录C.1.2)。此设置与第3.2/3.3节中的NLU任务相同。DSIR从所有领域中选择,而GOT-D和TAPT/c从最接近的领域中选择。TAPT/c在两个实验中都使用sentence-transformer进行嵌入。预微调以1e-5的学习率进行,并且仅限于一个周期。作者维持所有其他超参数的默认设置。然后,在没有进一步微调的情况下,作者在目标任务上测试预微调模型的零样本分类准确度,并衡量从每种数据选择方法中获得性能提升。所提出的方法在用40k样本进行预微调后,在AG News上建立了13.9%的性能提升,在BoolQ上建立了6.6%的性能提升,明显优于 Baseline 方法。
零样本学习细节:作者采用OpenICL框架(Wu et al., 2023)来实现零样本学习。为AGNews和BoolQ数据集使用的模板如表15所示。作者采用困惑度推理方法:对于给定的一组候选标签,作者使用LM确定整个实例的困惑度,并选择产生最小困惑度的标签。

Results for dataset AGNews
表15:用于零样本学习的提示。为了说明目的,作者针对每个任务展示了一个示例。作者检查了每个候选者在右侧列中的LM困惑度。
主要结果表16展示了在不同预微调数据预算下,AGNews数据集上的零样本分类准确度。对于GOT-D,作者使用微调后的精简-BERT模型的嵌入来计算OT距离。结果表明,作者提出的方法非常有效,实现了实质性的性能提升。具体来说,当数据预算仅限于5k实例时,作者的方法实现了4%的提升。当数据预算增加到80k实例时,这种性能增益进一步上升到超过13%。值得注意的是,作者的方法在所有数据预算场景下都超过了包括随机选择、DSIR和TAPT/c在内的所有基准模型。这种一致的优势强调了在有限数据资源下,作者方法的鲁棒性和有效性。
关于用于计算OT距离的嵌入空间的消融研究作者提出了一个关于用于计算OT距离的嵌入空间的消融研究,包括精简-BERT、sentence-transformer和Bert-tokens。
轻量级且快速流行的sentence-transformer使用预训练的all-MiniLM-L6-v2模型(具有22M参数)作为主干。它可以在单个GPU上嵌入高达600万个样本/小时,并且在许多NLP任务中通常被认为是句子嵌入的“默认”选项。Token空间不适合OT(例如,在token空间上的距离对释义不是不变的)。作者这里仅列出它进行比较。结果17显示sentence-transformer的性能与精简-BERT大体相当。这表明嵌入空间的选择不是数据选择 Pipeline 的关键部分,任何合理的嵌入空间都应该有效。
案例研究和可视化作者通过一个案例研究展示了作者方法的有效性。作者从通过每种方法(GOT-D、DSIR、TAPT/c)选择的预微调数据以及目标任务数据(AG新闻)和候选数据(OWTC)中随机抽取了1000个样本,进行潜在狄利克雷分配(Blei等人,2003)并可视化第一个主题的词云,如图5所示。

比较显示了一个清晰的对比。DSIR和TAPT/c选择的样本与目标任务数据的分布相匹配。尽管它们忠实地执行了任务,但可以清楚地看到,所选择的样本与模型已经预训练的候选数据的分布有很高的重叠,特别是对于DSIR选择的数据。因此,在如此小的数据预算下,从这些样本的预微调中提供的信息增益自然是微不足道的。
表16:在使用GPT-2 XL模型的AGNews数据集上,针对各种预微调数据预算的结果。作者在零样本设置下对1000个随机选择的测试样本进行准确性测试。初始列表示用于预微调的数据集大小,'0’表示 Baseline ,即任何预微调之前的原始模型。
表17:嵌入空间效果的消融研究。作者在零样本设置下对1000个随机选择的测试样本进行准确性测试。不同的列指的是不同的嵌入方法。

相比之下,GOT-D主要选择正式的商业新闻(例如,“银行”、“市场”和“公司”等关键词)。从词云图中可以看出,这些样本在候选数据集中高度代表性不足,但对于目标任务很重要。用这些样本微调模型,可以直接使模型与目标任务保持一致,这转化为更高的数据效率和效果。这有效地验证了这项工作的想法,并展示了作者提出的方法与分布匹配方法的不同之处。
3.1.2 预微调数据大小的影响
在本节中,作者探讨了预微调数据大小对作者方法性能的影响。如表18所示,在固定的预微调数据预算为k的条件下,作者改变预微调的数据集大小,并在零样本设置下评估模型在BoolQ数据集上的性能。表中初始列表示用于预微调的数据量,'0’表示 Baseline ,即没有任何预微调的原始模型。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。
这篇关于如何使用未标注数据对LLMs进行微调的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







