本文主要是介绍UniAudio 1.5:大型语言模型(LLMs)驱动的音频编解码器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大型语言模型(LLMs)在文本理解和生成方面展示了卓越的能力,但它们不能直接应用于跨模态任务,除非进行微调。本文提出了一种跨模态上下文学习方法,使未进行进一步训练的LLMs能够在少量示例的情况下,无需任何参数更新就能完成多种音频任务。核心思想是通过将音频模态压缩到训练有素的LLMs的令牌空间中,减少文本和音频之间的模态异质性。这样,音频表示可以被视为一种新的语言,LLMs可以通过几个示例学习这种新语言。
1 UniAudio 1.5 系统
UniAudio 1.5 系统是基于 LLM-Codec 模型和预训练 LLMs 构建的,能够以少量样本解决多种音频任务。
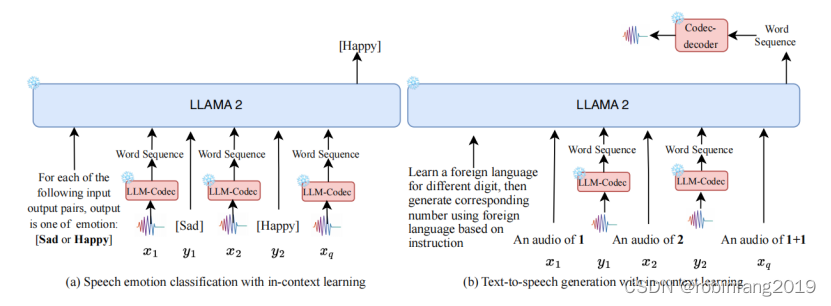
1.1 LLM-Codec 模型
LLM-Codec模型将音频信号转换为LLMs的词汇表中的令牌序列。这种转换不仅保持了音频的高重建质量,而且还减少了文本和音频之间的模态差异性,首次将音频数据量化到LLMs的表示空间的工作。通过将音频压缩到LLMs的令牌空间中,音频序列可以被视为一种新的语言,使得预训练的LLMs能够通过几个示例来学习这种新的语言。
1.1.1 模型架构
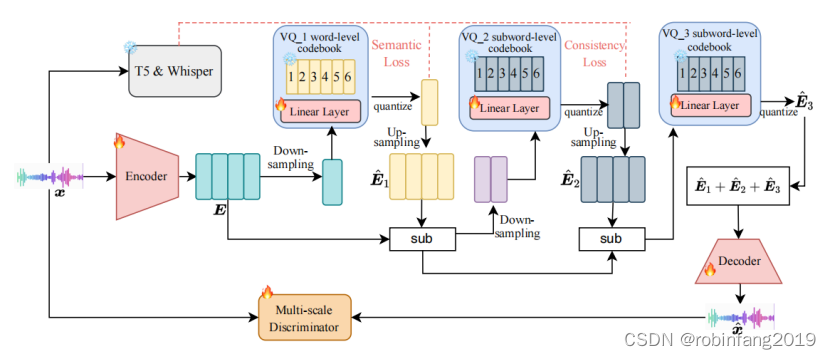
- 编码器: 将音频信号编码成潜空间表示,包含多个卷积层和 Transformer 层。
- 解码器: 将潜空间表示解码成音频信号,结构类似于编码器,但使用转置卷积层进行上采样。
- 量化器: 包含三个残差 VQ 层,分别编码语义信息、粗粒度声学信息和残差声学信息。
- 判别器: 评估重构音频的质量,包含多个卷积层。
1.1.2 关键技术
1.1.2.1 多尺度残差矢量量化 (RVQ)
LLM-Codec模型的技术核心是一个语义引导的多尺度残差向量量化(RVQ)基础的编解码器,在不同 VQ 层编码不同粒度的信息,平衡完整性和紧凑性。
具体来说,编解码器模型包含三个残差VQ层,每一层都针对不同粒度的音频信息进行编码:
第一个VQ层尝试编码语义信息,这一层能够用较少的令牌保存音频的语义内容。为了实现这一点,使用了一个插值函数来将编码器特征下采样到较小的维度,然后通过这一层获得量化的嵌入。
第二个VQ层尝试编码粗粒度的声学信息。在这之前,首先将第一个VQ层的量化特征上采样回原始维度,然后通过计算残差特征来获取粗粒度的声学信息。
第三个VQ层旨在编码剩余的声学信息。首先根据前两层的量化特征计算残差特征,然后直接对每一帧应用VQ操作,而不进行任何下采样。
1.1.2.2 词级码本
语义级别的信息可以用较少的令牌来保存,而声学级别的信息则需要更多的令牌。这种多尺度设置不仅减少了令牌序列的长度,而且为不同类型的任务提供了灵活的选择。例如,在音频理解任务中,我们可能只使用语义级别的VQ层。
1.1.2.3 语义损失及一致性损失
在训练损失方面,本文的方法基于生成对抗网络(GAN)的目标,同时优化生成器(包括编码器、量化器和解码器)和鉴别器。对于生成器,其训练损失包括三部分:(1)重建损失项、(2)对抗性损失项(通过鉴别器)、(3)语义和一致性损失。
- 语义损失:使用预训练 T5 模型提取音频的全局语义表示,引导第一层 VQ 层编码语义信息。
- 一致性损失:在早期的实验中,发现LLM-Codec的训练不稳定,模型容易崩溃。一个原因是设计了一个显著的下采样率,并且在训练中固定了码本,这增加了训练的难度。为了解决这个问题,本文提出了一致性损失来维持训练的稳定性。使用预训练 Whisper 编码器提取帧级特征,引导第二层 VQ 层编码粗粒度声学信息,提高训练稳定性。
1.2 UniAudio 1.5与UniAudio系列的联系和区别
UniAudio 1和UniAudio 1.5都旨在构建一个通用的音频基础模型,以处理所有类型的音频任务,但它们的侧重点不同。UniAudio专注于音频生成任务,如文本到语音、文本到音乐、歌声生成等。而UniAudio 1.5则侧重于通过探索基于大型语言模型的少量示例学习能力,来处理音频理解和生成任务。
UniAudio 1.5保留了UniAudio的基本组件,例如用于将音频模态转换为离散表示的音频编解码器,以及用于处理音频理解任务的解码器仅变换器骨干网络。然而,UniAudio 1.5利用了:
- 预训练的LLMs通过上下文学习来解决音频理解和生成任务。
- 一个由LLM驱动的音频编解码器,将音频数据量化到LLMs的令牌空间。
构建一个能够处理任何音频任务的多模态音频基础模型是UniAudio系列的最终目标。在UniAudio 1.0中,我们展示了构建一个通用模型用于不同类型的音频生成任务的可能性,但它存在以下限制:
- 不能有效解决音频理解任务。
- 无法在训练或微调阶段解决未见过的音频任务。
UniAudio 1.5展示了使用预训练的LLMs同时进行音频理解和生成任务的可能性。
2 实验
2.1 实验设置
2.1.1 训练数据
- 语音数据: 使用 MLS 数据集的一部分进行训练。
- 声音数据: 使用 AudioCaps 数据集进行训练。
- 总时长: 约 2k 小时音频数据。
2.1.2 模型设置

- 编码器和解码器: 由卷积层和 Transformer 块组成。
- 量化器: 使用 3 个残差向量量化 (RVQ) 层。
- 下采样率: 第一个 RVQ 层为 4,第二个 RVQ 层为 2。
- VQ 层初始化: 使用 LLAMA2 7B 模型的词汇表初始化 VQ 层。
- 潜在维度映射: 将 LLAMA2 的潜在维度从 4096 映射到 512。
- 参数固定: 训练过程中 VQ 层的参数固定。
2.1.3 评估指标
- 重建性能: 使用 PESQ 和 STOI 评估。
- 音频理解任务: 使用准确率 (ACC) 评估。
- 音频生成任务: 使用特定任务的指标评估。
2.1.4 评估数据集
本文为每项任务选择了常用的测试数据集,并构建了N路K样本测试对。
- 语音情感分类: 使用 ESD 数据集进行 2-way K-shot 实验评估。
- 声音事件分类: 使用 ESC50 数据集进行 2-way 和 3-way K-shot 实验评估。
- 动态-SUPERB 基准测试: 使用 Dynamic-SUPERB 基准测试进行评估。
- 简单文本转语音生成: 使用 FSDD 数据集进行评估。
- 简单语音降噪: 使用 VCTK 数据集和 NoiseX-92 数据集进行评估。
2.1.5 基线模型
鉴于专注于探索对未见音频任务的少量学习的工作数量有限,本文选择了BLSP作为音频理解任务的一个基线。由于BLSP是使用连续写作任务进行微调的,并且没有明确引入音频分类任务,因此这些音频分类任务对BLSP模型来说是未见过的。
- 音频理解任务: BLSP 模型和 Dynamic-SUPERB 基准测试中的模型。
- 音频生成任务: 状态-of-the-art 特定模型。
2.2 实验结果
2.2.1 重建性能
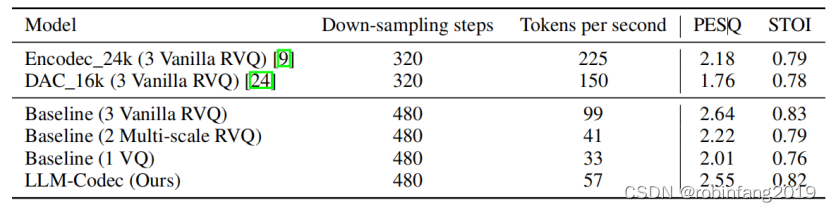
- 与 Encodec、DAC-Codec 等现有音频编解码模型相比,LLM-Codec 在保持较高重建质量的同时,使用了更少的 token。
- LLM-Codec 将 1 秒音频压缩成包含 57 个 token 的序列,显著减少了序列长度。
- 与使用 1 个或 2 个 RVQ 层的基线模型相比,LLM-Codec 的重建性能有所下降,但仍然优于这些模型。
2.2.2 音频理解任务
- 语音情感分类: 在 ESD 数据集上进行的 2-way K-shot 实验表明,LLM-Codec 在不同设置下均取得了优于 BLSP 模型的性能。
- 声音事件分类: 在 ESC50 数据集上进行的 2-way 和 3-way K-shot 实验表明,LLM-Codec 在大多数情况下取得了优于 BLSP 模型的性能。
- 动态-SUPERB 基准测试: 在 4 个音频理解任务上,LLM-Codec 取得了与 Dynamic-SUPERB 基准测试中的模型相当或更好的性能,尤其在鸟鸣声检测任务上取得了显著提升。
2.2.3 音频生成任务
- 简单文本转语音生成: 在 FSDD 数据集上进行的实验表明,LLM-Codec 可以准确地理解查询并生成高质量的语音样本。
- 简单语音降噪: 在 VCTK 数据集和 NoiseX-92 数据集上进行的实验表明,LLM-Codec 可以在没有训练的情况下学习降噪。
2.2.4 消融实验
- 多尺度 RVQ 的影响: 多尺度 RVQ 有效地减少了 token 序列的长度,并提高了下游任务的性能。
- 下采样次数的影响: 较小的下采样率可以提高重建性能,但会增加 token 序列的长度。
- 语义损失的影响: 语义损失有助于提高音频理解任务的性能,但不会影响重建性能。
- 一致性损失的影响: 一致性损失对于保持训练稳定性至关重要。
- 单词级代码本的影响: 使用单词级代码本初始化第一个 RVQ 层可以提高重建性能和分类准确率。
- 代码本更新的影响: 更新代码本会降低下游任务的性能。
- 多尺度 RVQ 中 k1 和 k2 的设置: 适当的 k1 和 k2 设置对于保持重建性能至关重要。
- 代码本使用情况: LLM-Codec 中的代码本得到了充分使用。
2.2.5 可视化分析
- LLM-Codec 的第一个 RVQ 层产生的 token 序列可以有效地表征不同类型声音的语义信息。
- 相同类型的声音具有相似的 token 序列模式,这有助于 LLMs 识别音频类型。
这篇关于UniAudio 1.5:大型语言模型(LLMs)驱动的音频编解码器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








