models专题

论文翻译:arxiv-2024 Benchmark Data Contamination of Large Language Models: A Survey
Benchmark Data Contamination of Large Language Models: A Survey https://arxiv.org/abs/2406.04244 大规模语言模型的基准数据污染:一项综述 文章目录 大规模语言模型的基准数据污染:一项综述摘要1 引言 摘要 大规模语言模型(LLMs),如GPT-4、Claude-3和Gemini的快

论文翻译:ICLR-2024 PROVING TEST SET CONTAMINATION IN BLACK BOX LANGUAGE MODELS
PROVING TEST SET CONTAMINATION IN BLACK BOX LANGUAGE MODELS https://openreview.net/forum?id=KS8mIvetg2 验证测试集污染在黑盒语言模型中 文章目录 验证测试集污染在黑盒语言模型中摘要1 引言 摘要 大型语言模型是在大量互联网数据上训练的,这引发了人们的担忧和猜测,即它们可能已

速通GPT-3:Language Models are Few-Shot Learners全文解读
文章目录 论文实验总览1. 任务设置与测试策略2. 任务类别3. 关键实验结果4. 数据污染与实验局限性5. 总结与贡献 Abstract1. 概括2. 具体分析3. 摘要全文翻译4. 为什么不需要梯度更新或微调⭐ Introduction1. 概括2. 具体分析3. 进一步分析 Approach1. 概括2. 具体分析3. 进一步分析 Results1. 概括2. 具体分析2.1 语言模型
![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)
[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval
引言 今天带来北京智源研究院(BAAI)团队带来的一篇关于如何微调LLM变成密集检索器的论文笔记——Making Large Language Models A Better Foundation For Dense Retrieval。 为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。 密集检索需要学习具有区分性的文本嵌入,以表示查询和文档之间的语义关系。考虑到大语言模

ModuleNotFoundError: No module named ‘diffusers.models.dual_transformer_2d‘解决方法
Python应用运行报错,部分错误信息如下: Traceback (most recent call last): File “\pipelines_ootd\unet_vton_2d_blocks.py”, line 29, in from diffusers.models.dual_transformer_2d import DualTransformer2DModel ModuleNotF
阅读笔记--Guiding Attention in End-to-End Driving Models
作者:Diego Porres1, Yi Xiao1, Gabriel Villalonga1, Alexandre Levy1, Antonio M. L ́ opez1,2 出版时间:arXiv:2405.00242v1 [cs.CV] 30 Apr 2024 这篇论文研究了如何引导基于视觉的端到端自动驾驶模型的注意力,以提高它们的驾驶质量和获得更直观的激活图。 摘 要 介绍

The Llama 3 Herd of Models【论文原文下载】
关注B站可以观看更多实战教学视频:hallo128的个人空间 The Llama 3 Herd of Models【论文原文】 点击下载:原文下载链接 摘要 现代人工智能(AI)系统由基础模型驱动。本文介绍了一组新的基础模型,称为 Llama 3。它是一群原生支持多语言、编码、推理和工具使用的语言模型。我们最大的模型是一个密集型 Transformer,具有 405 B {40

教育LLM—大型教育语言模型: 调查,原文阅读:Large Language Models for Education: A Survey
Large Language Models for Education: A Survey 大型教育语言模型: 调查 paper: https://arxiv.org/abs/2405.13001 文章目录~ 原文阅读Abstract1 Introduction2 Characteristics of LLM in Education2.1.Characteristics of LLM

VideoCrafter1:Open Diffusion models for high-quality video generation
https://zhuanlan.zhihu.com/p/677918122https://zhuanlan.zhihu.com/p/677918122 视频生成无论是文生视频,还是图生视频,图生视频这块普遍的操作还是将图片作为一个模态crossattention进unet进行去噪,这一步是需要训练的,svd除此之外,还将图片和noise做拼接,这一步,很多文生视频的方式通过通过这一步来扩展其成

Large Language Models(LLMs) Concepts
1、Introduction to Large Language Models(LLM) 1.1、Definition of LLMs Large: Training data and resources.Language: Human-like text.Models: Learn complex patterns using text data. The LLM is conside

models模型添加字段
1、模型添加字段 2、进行迁移 python manage.py makemigrations 3、python manage.py migrate 成功。 4、添加数据。

自然语言处理(NLP)-子词模型(Subword Models):BPE(Byte Pair Encoding)、WordPiece、ULM(Unigram Language Model)
在NLP任务中,神经网络模型的训练和预测都需要借助词表来对句子进行表示。传统构造词表的方法,是先对各个句子进行分词,然后再统计并选出频数最高的前N个词组成词表。通常训练集中包含了大量的词汇,以英语为例,总的单词数量在17万到100万左右。出于计算效率的考虑,通常N的选取无法包含训练集中的所有词。因而,这种方法构造的词表存在着如下的问题: 实际应用中,模型预测的词汇是开放的,对于未在词表中出现的词

论文笔记:LONG-FORM FACTUALITY IN LARGE LANGUAGE MODELS
Abstract 当前存在问题,大模型在生成关于开放主题的事实寻求问题的时候经常存在事实性错误。 LongFact 创建了LongFact用于对各种主题的长形式事实性问题进行基准测试。LongFact是一个prompt集包含38个领域的数千条提示词,使用GPT-4生成。 Search-Augmented Factuality Evaluator(SAFE) SAFE利用大模型将一个相应拆

【论文阅读】Stealing Image-to-Image Translation Models With a Single Query(2024)
摘要 Training deep neural networks(训练深度神经网络) requires(需要) significant computational resources(大量计算资源) and large datasets(大型数据集) that are often confidential(机密的) or expensive(昂贵的) to collect. As a resul
![[SimCLR v2] Big Self-Supervised Models are Strong Semi-Supervised Learners](https://i-blog.csdnimg.cn/direct/4cc9701420354cecb5eba7197a705453.png)
[SimCLR v2] Big Self-Supervised Models are Strong Semi-Supervised Learners
1、目的 借助无监督预训练来提升半监督学习的效果 2、方法 1)unsupervised/self-supervised pretrain -> task-agnostic -> big (deep and wide) neural network可以有效提升准确性

Language Models are Unsupervised Multitask Learners
摘要 自然语言处理任务,如问答、机器翻译、阅读理解和摘要,通常在任务特定的数据集上使用监督学习来处理。当在一个名为WebText的数百万网页的新数据集上训练时,我们证明了语言模型在没有任何明确监督的情况下开始学习这些任务。在不使用127,000多个训练示例的情况下,当以文档和问题为条件时,语言模型生成的答案在CoQA数据集上达到55的F1值 -匹配或超过4个基线系统中的3个的性能。语言模型的能力

论文速览【LLM】 —— 【ORLM】Training Large Language Models for Optimization Modeling
标题:ORLM: Training Large Language Models for Optimization Modeling文章链接:ORLM: Training Large Language Models for Optimization Modeling代码:Cardinal-Operations/ORLM发表:2024领域:使用 LLM 解决运筹优化问题 摘要:得益于大型语言模型

Code Llama: Open Foundation Models for Code论文阅读
整体介绍 Code Llama 发布了3款模型,包括基础模型、Python 专有模型和指令跟随模型,参数量分别为 7B、13B、34B 和 70B。这些模型在长达 16k tokens 的序列上训练。都是基于 Llama 2。 作者针对infilling (FIM) 、长上下文、指令专门做了微调 long-context fine-tuning (LCFT). codellama细节 C

论文辅助笔记:Large Language Models are Zero-Shot Next LocationPredictors
论文理论部分:论文笔记:lunLarge Language Models are Zero-Shot Next LocationPredictors-CSDN博客 2 Data 2.1 Dataset类 2.2 下载文件 2.3 get_dataset 2.4 get_trajectories trajectory_split暂时略去 # save the tes
扩散模型 (Diffusion Models) 及其在生成式建模中的应用简介
近年来,生成式建模领域的发展令人瞩目,各种新颖的模型架构不断涌现,其中扩散模型(Diffusion Models)因其在图像生成任务中的卓越表现而备受关注。本文将介绍一种常见的扩散模型:DDPM(Denoising Diffusion Probabilistic Models),并探讨其工作原理及应用。 一、什么是扩散模型? 扩散模型是一类生成模型,旨在通过模拟数据分布逐步生成逼真的样本。其核

论文翻译:Benchmarking Large Language Models in Retrieval-Augmented Generation
https://ojs.aaai.org/index.php/AAAI/article/view/29728 检索增强型生成中的大型语言模型基准测试 文章目录 检索增强型生成中的大型语言模型基准测试摘要1 引言2 相关工作3 检索增强型生成基准RAG所需能力数据构建评估指标 4实验设置噪声鲁棒性结果负面拒绝测试平台结果信息整合测试平台结果反事实鲁棒性测试平台结果 5 结论 摘要
DENOISING DIFFUSION IMPLICIT MODELS(DDIM 去噪扩散隐式模型公式推导)
DENOISING DIFFUSION IMPLICIT MODELS(DDIM 去噪扩散隐式模型公式推导) DDIM思想,去掉DDPM去噪过程的马尔可夫性质,达到跳步去噪的目的。DDIM思想实现方法:假设一个不服从马尔可夫的逆向去噪转移分布 P ( x t ∣ x t − 1 , x 0 ) ∼ N ( k x 0 + m x t , σ 2 I ) P(x_t \mid x_{t-1},x_
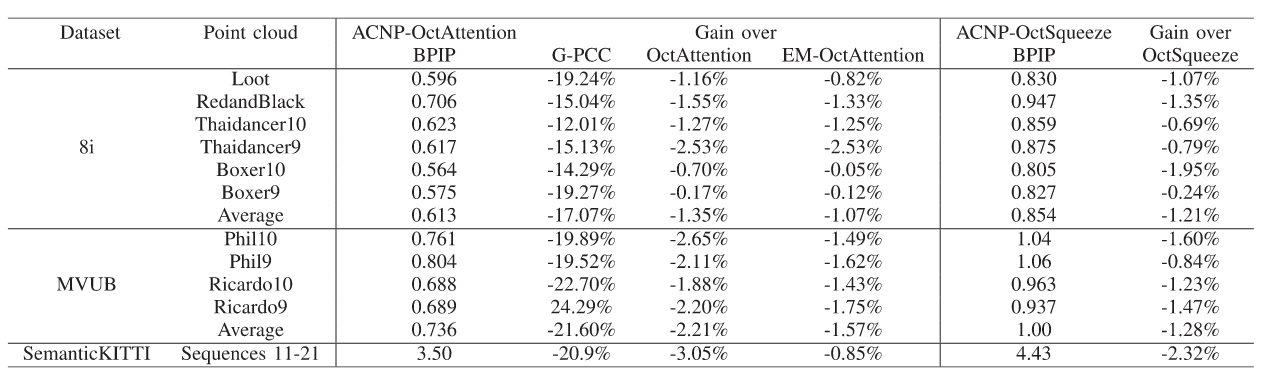
Enhancing Octree-Based Context Models for Point Cloud Geometry Compression 论文笔记
1. 论文基本信息 发布于: IEEE SPL 2024 2. 创新点 分析了基于 one-hot 编码的交叉熵损失函数为什么不能准确衡量标签与预测概率分布之间的差异。介绍了 ACNP 模块,该模块通过预测占用的子节点数量来增强上下文模型的表现。实验证明了ACNP模块在基于八叉树的上下文模型中的有效性。 3. 背景 现有上下文模型的局限性: 现有的上下文模型使用交叉熵作为损失函

Django 2.1.7 模型管理器 models.Manager 以及 元选项
上一篇Django 2.1.7 模型的关联 讲述了关于Django模型一对多、多对多、自关联等模型关系。 在查询数据的时候,对于某种固定的查询,例如视图之类的查询,通用类型的查询每次都需要写一遍,有没有一个地方可以将这类通用的查询抽象出来,进行模型的业务管理呢? 这时候就要看看模型的管理器了。 参考文献 https://docs.djangoproject.com/z

Retrieval-Augmented Generation for Large Language Models A Survey
Retrieval-Augmented Generation for Large Language Models: A Survey 文献综述 文章目录 Retrieval-Augmented Generation for Large Language Models: A Survey 文献综述 Abstract背景介绍 RAG概述原始RAG先进RAG预检索过程后检索过程 模块化RAGMo