本文主要是介绍Multi-human Fall Detection and Localization in Videos,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
背景:深度学习对人类行为和活动识别应用的好处的探索一直存在延迟。在这些领域中,跌倒检测因其出色的公用事业而受到关注。跌倒检测可以在养老院、有公共摄像头的区域和独居老人的家中等设施中实施,因为绝大多数与跌倒有关的死亡发生在这些地点。
目标:YOLO目标检测算法与时间分类模型和卡尔曼滤波跟踪算法相结合,用于检测视频流上的跌倒。
方法:采用本文方法时,需要进行以下步骤:(1)在图像中定位发生跌倒的区域;(2)跟踪和提取由跌倒构成的时序图像的特征,并形成与给定的人相关的一系列动作;(3)建立对连续序列图像进行分类和时序信息聚合的模型。基于这些步骤,本文提出的方法创建了两个版本,YOLOK+3DCNN和YOLOK+2DCNN+LSTM。
结果:将所提出的模型与文献中使用已知度量的其他方法进行了比较,使用自定义数据集和最先进的模型进行的实验模拟表明,使用所提出的方法可以在大多数评估指标中获得最佳结果。
1.介绍
根据美国疾病控制和预防中心(CDC, 2017年)的数据,每年有五分之一的老年人跌倒后受到严重伤害,如骨折或头部受伤。因此,考虑到居住在养老院的老年人,数据显示,平均每人每年发生6次跌倒(Rubenstein等人,1990年),其中65%的跌倒发生在家中,26%的跌倒发生在公共道路上(Maldonado等人,2016年)。总的来说,每年有160多万老年人遭受与跌倒有关的伤害。如果能够及早发现跌倒,以减少受伤风险,那么就可以通过适当的行动计划和快速反应来挽救生命。
事实上,随着年龄的增长,人们更容易因跌倒而受伤。导致这种结果的因素有几个,包括独居、女性、视力或听力问题、走路不稳、鞋子不平整(Cavalcante et al., 2015)。基于这些因素,Yang和Sanford(2012)指出,有些地方值得特别注意,如卧室和浴室,这是老年人更常去的地方。因此,这些地方,以及在瓷砖上,被报道为跌倒可能发生的主要地点。导致这种情况恶化的另一个特点是,许多老年人独自生活或一天中大部分时间都是独自一人。因此,当这些人摔倒时,他们需要很长时间才能得到帮助。因此,对这一群体的监测将具有极大的价值。
许多养老院都有监控摄像头,但是,由于居民多,员工少,持续监控是不现实的。此外,在一些养老院,尽管有摄像头,但没有员工监控他们。因此,记录下来的图像仅用于进一步调查导致事故发生的事实。
考虑到这些事实的重要性,必须对人类跌倒作出一个技术定义,将其归类为一种行为或活动。这种区别对于指导我们的研究至关重要。一些作者,如Moeslund等人(2006)和Kruger (Poppe, 2010),将动作原语定义为一种可以在肢体层面上描述的原子运动类型,因此,动作一词指的是身体的各种各样的运动,从简单的、原始的到周期性的,活动指的是代表一个复杂运动的几个连续动作。
相比之下,Turaga等人(2008)将动作定义为一个人在短时间内(以秒为单位)完成的简单运动模式。我们采用的定义是,一个动作只需要几秒钟就能发生,而不需要对场景进行长时间的分析。因此,我们将跌倒定义为一种动作。在这篇论文中,我们的目标是专门检测跌倒的一般情况和独立的条件或场景,在他们已经发生。
尽管研究跌倒检测很重要,但目前还没有针对这一特定任务的图像存储库,这使得这成为一个复杂的问题。
由于实际可用的数据并不多,可用的数据集通常是通过人工数据或有意生成的动作生成的,例如Auvinet et al.(2010)和Kwolek and Kepski(2014)中描述的数据集。这种产生的动作导致了与人们日常生活中可能发生的动作不匹配的动作,消除了预期动作的自然性。还需要注意的是,大多数可用的数据集只在图像中有标签,不包括界定动作发生的特定区域的框。因此,很少有数据集具有Gu等(2018)和Yao等(2011)提供的数据集的特征。
还应该注意的是,基于可穿戴传感器的方法通常依赖于附着在用户身体上的加速度计。基于环境传感器的跌倒检测系统使用内置的外部传感器,可以是压力传感器、声学传感器或肌电图传感器(Zigel等人,2009;Cheng等,2012)。因此,模型变得依赖于许多传感器,它们的安装和校准不是微不足道的。
因此,基于计算机视觉的视频监控方法对老年人的侵入性更小,更方便,并且具有可扩展性,可用于其他目的,如通过监控实现安全。根据研究,大多数基于传感器的策略,如加速计,有很高的误报率。
本文研究的问题是人体跌倒的检测。利用深度学习和计算机视觉技术,提出了一种精确的跌倒检测系统,该系统可以在最多样化的环境中使用传统的IP摄像机进行实时执行。
图1显示了本文方法在AVA数据集上执行的一些分类结果。人们正在跌倒或已经跌倒的场景用红色的方框突出显示,人们处于其他位置而没有被描述为跌倒或跌倒的场景用绿色的方框突出显示。在每个框的顶部都有一个数字,它指的是跟踪索引,用于跟踪图像过程中的每个人。然后,指定描述被检测人员所属类别的文本(Fall或No Fall)。

为了实现这一目标,YOLO结合3DCNN提取时间特征,并使用卡尔曼滤波来聚焦场景中的个体。给出了实验结果,对于在AVA、Multiple camera和UR Fall数据集上模拟的实验,使用本文提出的方法时,根据所使用的评估指标达到了最领先的水平。我们还建立了一个使用真实跌倒图像的数据集来提高模式的训练。本工作中开发的软件的脚本、指标和源代码可以在GitHub.1上找到。(Available at https://github.com/mouglasgit/DeepFallDetection.)
与以前的方法相比,提出的方法有以下优点:
•与其他使用陀螺仪或加速度计的工作不同,本文提出的方法只使用RGB图像。因此,没有必要添加具有侵入性的可穿戴传感器。此外,许多庇居所已经安装了监控摄像头,可以在拟议的方法中重复使用。
•由于我们可以用相同的镜头同时检测到几个跌倒,使用图像中人物的位置,我们可以过滤感兴趣的区域中检测到的区域,以满足模型。相反,在Kwolek和Kepski (2014), Nogas et al. (2018), Lu et al. (2018), Debard et al.(2011)和Ali et al.(2013)中,使用了整个图像,不能很好地检测出多人。此外,这些型号对噪声非常敏感,因此,仅通过CNN或手工制作的特征,很难从场景中过滤合并的数据。
•所提出的方法对来自照明或校准的噪声不太敏感;一旦人的检测被证明对这些问题是稳健的,模型的其他层就可以被提供正确的信息。然而,基于手工特征的模型依赖于场景和对质量、轮廓等敏感信息的校准。这些方法对来自照明的噪音也很敏感,会造成虚报。
•与检测身体部分的模型(如姿态估计)相比,我们提出的方法也有优势。我们的人体检测模型能更好地处理处于不同位置或被遮挡的人。相比之下,位姿估计模型在这些情况下有困难(Chu等人,2021)。重要的是要考虑到人体检测模型通常更容易标记和更轻量级的操作。
相关的方法对于被校准的准时数据集更好。然而,当在大多数不同的场景中应用这些模型时,就失去了很多通用性,如果将这些模型安装在疗养院的不同房间中,那么使用这些模型将是不可行的,因为房间中会有不同的场景视角。因此,独立于场景的模型更有优势。
2. 相关工作
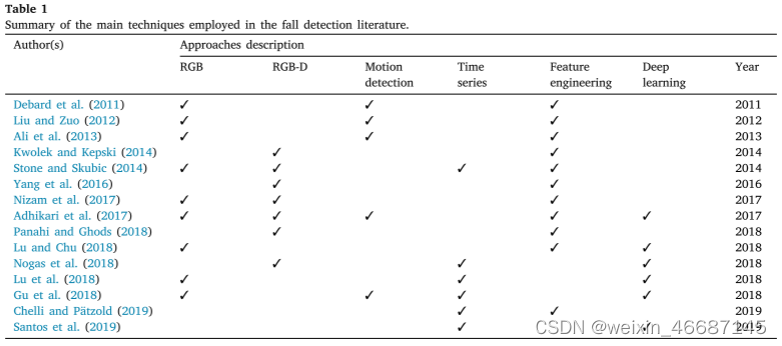
历史上,视觉动作识别被划分为小主题,如(i)手势识别(Erol et al., 2007;Pavlovic等人,1997年);(ii)面部表情识别(Zhao et al., 2003);(iii)视频分析中的运动行为识别(Hu et al., 2004)。然而,全身动作通常结合不同的动作,需要一个统一的方法来融合身体不同部分的运动。表1总结了所提出的方法。到2018年,特征工程已经在几部作品中得到应用,但此后被深度学习方法所取代。另一个广泛使用的资源是图像深度信息,例如来自微软Kinect摄像头的信息。
Liu和Zuo(2012)提出了一种基于场景特征的跌倒检测方法,如人体宽高比、人体有效面积比、不同帧的中心变化率等。作者着重于提高准确性,同时减少分类错误。这种工作的优点是它的执行时间快。此外,它不是一个复杂的模型,不需要太多的数据进行训练。然而,这种方法的一个缺点是对场景中的变化很敏感,因为所有的参数都是为形式和场景的透视图配置的。因此,考虑到这种方法不使用鲁棒分类器,这大大降低了泛化。
Lu和Chu(2018)提出了一种用于养老院的基于图像的跌倒检测系统。作者们关注的是在坐着和从椅子上站起来时发生的摔倒。用物体检测器来识别图像中的人体,然后测量其相对于附近椅子的位置。该系统根据人与椅子之间的水平和垂直距离确定了可能的跌倒。该方法的优点之一是只使用一个对象分类器,从而减少了对下落物分类的步骤数。也没有必要为跌倒创建特定的数据集,因为可以使用已经训练过的模型,从文献中已有的几个数据集中检测人。这种方法的一个缺点是,必须有一把椅子靠近被监视的人;另一个缺点是,这种策略只依赖于单一的图像来检测跌倒,因为它没有捕捉运动和身体动力学来测量速度。特别是当使用这种方法时,日常姿势可能会与跌倒姿势混淆。
Debard et al.(2011)使用四个不同位置和角度的摄像机来建立训练模型数据集。该模型使用中值滤波器进行背景减除,然后利用形态学运算对人的区域进行分割,有了分割的信息,四个特征被用来检测跌倒:人与图像大小的比例,重心的移动速度,头部的移动速度。提取的特征被输入到SVM分类器,这样就可以推断可能的跌倒。为这项研究构建的数据集是不同的,因为它使用了来自多个相机配置文件的图像,这对社区来说是一个有价值的功能。该模型还具有推理速度快的特点。在这个工作中,背景减法的使用被强调为一个缺点,因为图像中会出现噪声。这项工作是基于支持向量机SVM的,它会导致类之间的最优全局分离(Cristianini和shaw - taylor, 2000)。这导致新样本的泛化程度较低,对训练后的数据集的特征表示不充分(Weston et al., 2000)。Ali et al.(2013)通过使用媒体过滤器来更有效地去除背景,进行了一些改进。
Stone和Skubic(2014)使用微软的Kinect在家庭环境中检测跌倒。该方法分为两个阶段:(1)在第一阶段,通过对人的跟踪,构建时间序列的运动信息,将RGB-D图像分割为垂直事件;(ii)在第二阶段,基于序列数据,使用决策树集合预测可能的跌倒。作者将可用的数据集划分为10个样本批,以训练每个决策树来创建集合。这项工作的主要优点是,它是第一个使用RGB-D深度图像来检测跌倒的。值得注意的是,尽管模型增加了更多的动力学特性,但缺点是,并不是所有环境都有这样的监控设备,在实际应用中,监控摄像机更为常见。此外,基础决策树的数据特征的微小变化会导致模型的不稳定性,使其更加敏感(Li and Belford, 2002)。最后,还需要注意的是,训练树集是耗时的(Hashemi等人,2008年)。
在Yang等人(2016)的研究中,作者使用了来自微软Kinect传感器的3D深度图像来检测老年人跌倒的情况。深度图像通过中值滤波对背景和目标进行预处理。在深度图像中运动个体的轮廓是通过背景帧的减法实现的。使用水平和垂直投影直方图统计信息将深度图像转换为视差图。利用𝑉视差图提供初始平面的信息,并利用最小二乘方法估计平面方程。利用一组矩函数对深度图像中人体的形状信息进行分析。通过计算椭圆系数来确定物体的方向。本文工作的主要优点是,与地面相关的特征是用视差图表示的。但是,通过背景减法提取运动的效率不是很高,而且对图像中的光照和噪声非常敏感。
Nizam等人(2017)提出了一种基于从微软Kinect传感器中提取的人体速度和位置的人体跌倒检测系统。首先,逐帧提取主体和平面图并跟踪,然后使用跟踪的身体关节来测量相对于先前位置的速度,最后,通过身体位置来确认在异常速度后是否所有关节都在地板上,这一策略与Kwolek和Kepski(2014)以及Panahi和Ghods(2018)所使用的策略相似,可以突出计算这个人的速度和位置作为优势。事实上,这些特征的提取在跌倒检测中是必不可少的。然而,也有一些缺点。例如,需要进行一次检查,确定所有关节是否都在地面上;因此,某些类型的跌倒可能会被忽视。另一个缺点是计算速度的不准确性,因为它是基于头到地面的欧氏距离,这种计算方法对相机的FPS很敏感,并且依赖于相机保持静止。
Adhikari等人(2017)通过微软Kinect图像使用2DCNN进行姿态检测,解决了跌倒检测问题。作者创建了一个新的集中在室内环境的数据集。该方法结合使用RGB-D图像的背景减法、深度信息和由2DCNN分类的姿势来确定是否发生了跌倒。这项工作的两个主要优点是(i)创建一个新的跌倒检测数据集和(ii) RGB-D图像与2DCNN的结合。然而,事实上,在这个工作中使用背景减法是一个缺点,因为它不是一个有效的技术结合运动。此外,为单个场景使用两个通道会为模型产生额外的成本。
Nogas等人(2018)断言,跌倒很少发生,基于这一点,使用监督分类技术来估计可能的跌倒是具有挑战性的。采用了一种基于学习的半监督方法,将跌倒检测问题定义为异常检测问题。深度时空卷积自动编码器使用非入侵性的检测模式来学习异常活动的空间和时间特征。作者在三个公开可用的数据集上测试了提出的框架,这些数据集是通过非入侵性传感模式和热深度相机收集的。本文介绍了利用自动编码器将跌倒当作异常处理的优点。该模型的一个缺点是增加了计算成本,因为增加了与自动编码器相关的重构步骤。此外,最好的指标是通过使用深度相机的图像实现的,这增加了对该设备的依赖。
由于具有真实跌倒图像的数据集很难获得,Lu等人(2018)开发了一个仅使用运动学视频的3DCNN。由于2DCNN只能用于编码空间信息,作者认为采用3D卷积网络可以从时间序列中提取运动特征,这对跌倒检测很重要。采用基于长短时记忆(LSTM)的空间视觉注意方法,进一步定位每帧感兴趣区域。该研究的优点是将注意力机制与LSTM相结合,提高了模型的性能。但是,由于这种模型需要实时运行以快速抢救跌倒者,因此3DCNN与LSTM的结合是一个缺点,它使得模型的计算成本更高,无论是训练还是推理都是如此。另一个缺点是,模型是使用动作识别数据集训练的。因此,使用不完全与跌倒相关的数据集进行训练可能会对其他类型的日常行为产生一些偏差。
Gu et al.(2018)提出了一个由几类动作组成的新数据集,其中有一类指的是跌倒。他们基于Peng和Schmid(2016)的工作提出了一种算法,该算法使用RCNN (Ren et al., 2015)来融合两个支路的信息。第一个支路是inception 3D (I3D),它是由carira和Zisserman(2017)提出的,提供RGB图像。第二个支路是I3D,它使用经过光流预处理的相同图像来捕捉场景之间的运动。关于本文的优点,我们可以强调创建一个带有关键帧标记的新数据集和多个支路的组合,这在动作检测文献中是众所周知的,但这是一种创新的跌倒检测策略。缺点是,由于数据集不是专门用于检测跌倒,其他几个类属于不同的动作,跌倒的样本数量比较不均衡。此外,大多数图像都来自电影,其中跌倒的所有动态都是模拟的。一些滤镜去除了场景与监控摄像头拍摄的真实图像相比的自然感。
在Santos等人(2019)的工作中,在物联网(IoT)的云计算环境中,使用了卷积网络来检测跌倒。提出的模型被称为CNN-3B3Conv。然而,这种分析不是通过图像来进行的,而是通过传感器来进行的,比如终端用户的加速度计,而加速度计是嵌入在人体中的智能手机或智能手表。这种方法的主要优点是速度,因为训练和执行是由传感器数据执行的。缺点是,由于该方法仅基于传感器,使用加速度计数据,信息量大大减少,使其对任何运动都更加敏感。它还迫使用户使用身体上的传感器。因此,每个传感器只能监视一个人,而且校准并不简单。
Chelli和Pätzold(2019年)也使用了加速度计的数据来感知角速度,通过K-nearest neighbour (KNN)、人工神经网络(ANN)和集合袋树(EBT)等机器学习模型来检测下落。使用传感器数据的优点是它们比视频流具有更低的维数,并且它们的训练和执行速度都是高速的。通过对神经网络模型、EBT模型和KNN模型的比较,可以看出这些模型在这类问题中的特点。如前所述,其主要缺点是在身体中使用传感器,从数据中提取的特征很少,而且校准困难。
最后,Ren和Peng(2019)对跌倒检测相关工作进行了文献综述,其中一些在本文中已经进行了描述。我们的文献综述集中于使用相机作为传感器的跌倒检测方法。Wang et al.(2020)对可穿戴设备和传感器融合进行了完整的综述。
在审查过的论文中,图像或视频中只检测到一个人的跌倒。如果现场有多人在场,系统就不能用来跟踪不同的坠落情况。大多数提出的方法都使用深度信息。然而,这种设备在室内并不常见。在庇护所或房屋中发现监控摄像头更为常见。
3.提出的方法
在本节中,将对所提议的方法进行初步描述。我们在3.1节中介绍了提出的方法的体系结构,然后在3.2节中解释了训练过程。
3.1.架构
我们的视频中多人跌倒检测与定位模型由两个阶段组成:(1)跟踪阶段,即识别并跟踪视频中每个人的运动;(2)分类阶段,即对前一阶段产生的每个人体帧序列做出是否跌倒的判断。
3.1.1.跟踪阶段
跟踪阶段如图2所示。首先,检测网络接收输入视频的全帧序列,检测网络用于为每一完整帧生成包含代表人体区域的框。时间序列的区域与给定的人是用来产生个性化的人体框架序列,时间信息被用来更好地利用卡尔曼滤波器对那些人体帧序列进行空间对齐(Cuevas等人,2005;卡尔曼,1960)。
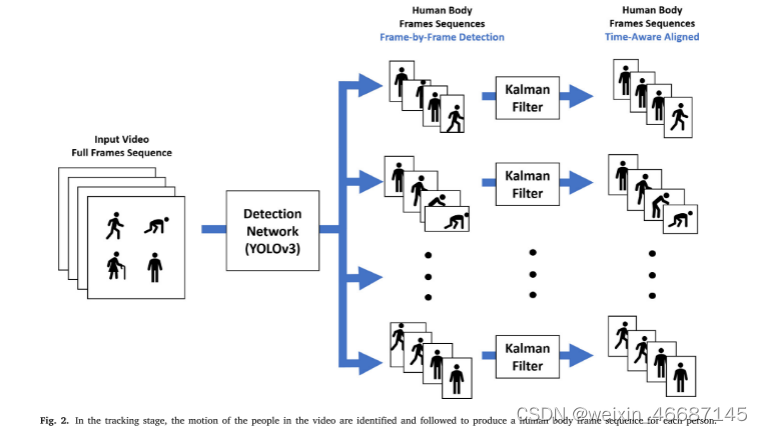
除了允许在视频中呈现的每个人的定位,这随后使我们能够单独决定是跌倒还是不跌倒,跟踪阶段有助于提高性能,通过关注人体和删除不必要的背景信息(Matikainen et al., 2009;Messing等人,2009)。我们将解决方案的这一阶段称为YOLOK,以表明它基本上由YOLO检测器和卡尔曼滤波器组成。
卡尔曼滤波器可以(Kalman, 1960)使递归估计状态成为可能,所以每一个估计都是由之前的估计计算出来的。因此,只需要存储之前的估计,因为离散时间下的线性动态系统可以用一对方程来描述:
其中是状态向量;
为观测向量;
为测量矩阵;
为测量噪声。
我们用单位矩阵来完成状态的转换。误差协方差矩阵定义为,其中:
因此,我们可以将误差定义为系统当前状态的结果与通过状态的最小均方误差预测的预期结果之间的差值。首先,我们用矩阵
假设匀速初始化模型,初始值𝑑𝑡= 1,其中协方差矩阵构型如下:
因此,我们采用了由解耦扩展卡尔曼滤波器(DEKF)训练的线性化动态模型(Haykin, 2004)。因此,卡尔曼滤波器遵循DEKF的标准实现,使用位置来输入观测向量,进行在线预测,更新当前状态,并向卡尔曼滤波器添加一个新度量。
在本文中,我们使用线性化版本的卡尔曼滤波器,它被用来显著降低计算复杂度,因为,正如Haykin(2001)所描述的,我们忽略了在协方差矩阵的主对角线上的更新权值。因此,我们需要通过向量的偏导数将模型线性化,得到:
为了计算偏导数,我们使用实时回归学习算法。因此,根据Puskorius和Feldkamp(1991)的工作,我们可以用以下方程组来实现卡尔曼滤波器:
为真实状态;
是通过𝑛−1的预测;
为转换因子,将滤波后的创新向量
和误差向量
联系起来;
被用来估计观测向量;
是卡尔曼增益,它决定了用来更新状态估计的修正;
为创新向量,即期望响应与估计之差
;
是表示误差协方差的矩阵,该协方差随时间传播。
传播误差协方差矩阵,状态的初始值是根据图像中人物的位置(𝑥,𝑦)计算出的质心(𝑐)和(𝑤,ℎ)的宽度和高度来定义的。
观察到的变量为被测人群的质心及其比例;在每一个新的分类预测中,我们根据被检测到的人通过卡尔曼滤波的运动,更新系统的观察向量来预测人的定位。
为了优化模型的流,我们使用了一个固定大小的视频缓冲区,其中填充了直接来自流而没有任何处理的帧。当缓冲区被填满时,将执行预测。对于每一个预测,缓冲区中出现的帧集被发送去处理(YOLO+Kalman filter)和分类(3DCNN)。当新的图像出现时,删除最旧的图像以添加最新的图像。因此,总会有一个恒定的流量需要实时分类。
3.1.2.分类阶段
分类阶段如图3所示。由于前一阶段的人体框架不一定具有相同的尺寸(即高度和宽度),所以在进行实际分类之前,有必要对其尺寸进行标准化。因此,我们首先向这些帧添加反射填充。随后,我们调整尺寸,将其标准化为104 × 104像素的正方形。在这些程序之后,我们有时间意识地对齐视频中人体标准化方框序列的每个人。
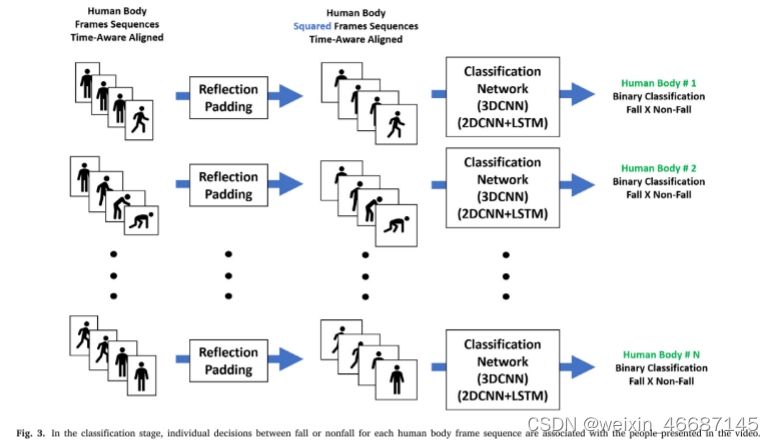
由于box的大小在整个图像中可能会有所不同,所有与被跟踪的人有关的跌倒检测都将按比例缩放至104。为了获得这个值,我们在不同尺度下进行了一些模拟,在速度-精度权衡方面,使用104的尺寸获得了最佳结果。我们使用反射填充,这样所有的图像都有相同的宽高比。
在调整大小之前,图像是物体检测器发现的box的大小。给定跌倒被检测到的区域,使用基于卡尔曼滤波器构建的跟踪器将人的图像分组为图像序列。然后,我们用边界填充这些尺寸,直到图像具有相同的尺寸𝑁乘以𝑁的比率,其中𝑁是被检测对象的最大尺寸。因此,假设人的宽度𝑊,高度𝐻为:
此时,我们可以将前面步骤生成的基于时间感知对齐的人体标准化方框序列解释为三维体或二维图像的时间序列。因此,我们提供了两个选项来执行这一阶段的最后一步,它包括多个跌倒或非跌倒分类。
因此,我们为整个端到端可训练架构提出了两种选择。
第一个选项被称为YOLOK+3DCNN,它使用YOLOK跟踪阶段和基于3DCNN分类块的分类阶段创建。
第二个选项被称为YOLOK+2DCNN+LSTM,它是将YOLOK跟踪阶段与基于2DCNN+LSTM分类块的分类阶段结合起来创建的。
Schindler and Gool (Schindler and Gool, 2008)认为,考虑到跌倒的动作发生的时间很短,用最小的8帧组成一系列动作被证明是最适合捕捉快速动作的。因此,我们的目标是在真实环境中使用该系统,因为摔倒通常发生得很快,所以如果我们将摔倒视为一种动作类型,只需要少量帧。然而,根据Schindler和Gool(2008), 1到7帧的简短视频片段就足以识别基本的动作。
3.1.3.视频流
除了使用录制的视频外,我们的方法还可以很容易地应用于媒体视频流,例如由IP摄像机提供的视频。为了实现这一点,我们提供了一个循环的帧缓冲区,其中一个线程提供来自流的帧。然后,另一个线程消耗循环缓冲区中的间隔。
3.2.训练阶段
使用该架构完成的训练分为三个部分:(i)预训练,我们使用ImageNet的预训练模型来迁移学习到YOLO模型;(ii)使用从带有VOC的数据集生成的标签和创建的数据集来训练YOLO找到目标对象的box;(3)训练模型提取时间特征。
3.2.1.ImageNet预训练
为了获得更好的模型性能,我们使用ImageNet 1000-class (Russakovsky et al., 2015)上预训练的模型作为特征提取器,使用DarkNet-53 (Redmon和Farhadi, 2018)框架进行训练。通常,需要更详细的图像信息进行检测。因此,图像分辨率从ImageNet标准的224 × 224提高到416 × 416。
在DarkNet-53架构中,使用了连续的3 × 3和1 × 1卷积层。我们使用在ImageNet中预先训练的卷积层的权值作为特征提取器。受到Qiwei等人(2019)工作的启发,我们设计了DarkNet-53如何与YOLO的其余部分交互。图4显示了DarkNet-53与YOLOv3相结合的体系结构。DBL模块的构建由卷积层、批处理归一化层和leaky ReLU层组成。另一个元素是ResUnit,它包含了零填充层,后面跟着带有残差块的向前DBL结构。为了在分辨率上处理不同的对象大小,在YOLO中有三个独立的输出y1、y2和y3。因此,可以预测三种不同尺度的box。该模型使用金字塔网络从这些尺度中提取特征,这提高了对小目标的检测(chong - yi et al., 2017)。
3.2.2.使用自定义数据集训练
需要注意的是,有必要通过构建一个由于涉及图像的版权问题而不能向公众提供的数据集来补充用于训练体系结构的数据集。然而,我们在提出方法的同时提供了权重,我们创建的数据集包含了每个跌倒的标识符,通过连续的时间图像跟踪跌倒发生的区域。因此,建立整个数据集,对图像中出现跌倒的位置进行分类,并对后续图像中出现相关的区域时间序列进行跟踪。没有为问题找到具有这些特征的数据集。
为了建立一个适用于各种环境的鲁棒的跌倒检测模型,我们建立了一个数据集,用于近似这类问题所需的特征。这些被分类的视频在互联网上搜索,并从各种媒体中提取出来,以更好地代表数据。我们从安全摄像机、手机镜头、电影片段等多个角度,搜索摄像机拍摄的视频,以及俱乐部、体育赛事等场景。
然后,为了数据集的准备,我们开发了一个工具,它可以通过在图像中每个人的周围画一个方框来标记他们,通过添加类和索引来获得他们的坐标以及他们的宽度和高度,这样就可以在后续的图像中对图像进行时间序列地跟踪。这个工具可以在GitHub(https://github.com/mouglasgit/LabelImagensVOC.)上找到,在标记图像的过程中,增加了非跌倒等级的偏差,因为,正如前面提到的,人们可以假设有更多不同的姿势可能被描述为非跌倒等级,这使得跌倒等级对微小的变化很敏感。
3.2.3.目标数据集微调
为了增加创建的数据库中的条目数量,并改善数据集的多样性,我们将涉及人的图像从VOC3和COCO4数据集中分离出来。我们通过一个脚本提取指向这个人的类,以纠正新图像中可能出现的不一致性。一旦这个过程完成,我们就完成了数据集并训练了所提出的模型。
我们使用批次大小为4,初始学习速率为1e−3(0.001),根据验证数据集度量降低了初始学习速率。我们还通过对图像两侧应用15度旋转,并随机调整图像大小,使其变小或增大20%,来增加数据集中的条目数量。然后,整个模型被训练为500个epoch。
需要考虑的一点是用户隐私保护的重要性。在一些私密的环境中,如浴室甚至卧室,经常会发生许多跌倒,保护人们的隐私是很重要的,这在使用RGB图像时是不可能做到的。我们考虑在这样的环境中使用RGB-D相机来解决这个问题,因为它允许使用RGB-D相机生成的图像深度通道来训练模型。由于人体剪影包含了足够多的特征,所以许多基于手工制作的特征的作品都使用了成功的人物剪影。使用这种方法,相同的所提出地体系结构是适用的,只是输入数据的类型发生了改变。
4. 实验评估
在本节中,描述了使用所提出的模型所获得的实验和结果。在第4.1节中,我们详细介绍了所使用的数据集;在第4.2节中,我们执行两个分析,首先,我们分析了完整的模型,展示了不同参数和配置下的一些结果,然后,我们将所提出模型的最佳配置与4.1节中讨论的数据集进行比较。在第4.3节中,我们使用所提出的模型演示了一些场景。
4.1.数据集
我们在三个标准数据集上进行了实验,使用互联网图像的数据集和在3.2.2节中讨论的自定义数据集。其他三个数据集将在章节4.1.1、4.1.2和4.1.3中讨论。
4.1.1.AVA数据集
AVA数据集提供音频和视频注释,以提高对人类活动的理解。注释的视频剪辑为15分钟长。需要注意的是,每个剪辑都是手动标注的;这一责任不只是留给机器学习算法。大多数样本由电影片段组成,从而确保了人类活动数据集的多样性(Gu等人,2018年)。
AVA数据集的特征是它有80个原子视觉动作。图像中的每个人都收到一个不同的标签。总共有430个时长为15分钟的电影片段被贴上了标签。动作在空间和时间上都有位置,因此有1.62万个数据可供下载。
4.1.2.多个相机的跌倒数据集
多个相机的跌倒数据集包含了从8个互联网协议(IP)型摄像机拍摄的24个记录场景。这个数据集的主要特征是每个相机都有不同的视角。
数据划分如下:前22个场景对应的是跌倒事件与日常生活图像的混合;最后两个视频是由日常生活事件组成的。该数据集可供下载。
4.1.3.UR跌落检测数据集
UR跌落检测数据集是由Rzeszow大学计算建模跨学科中心开发的。这个数据集是几个视频的集合,总共有70个序列的图像,其中30个是人跌倒的视频,40个是日常活动的视频。来自微软Kinect摄像头的两个传感器捕捉到了图像。这些图像的其他数据也被捕捉到,并通过传感器(如加速计)提供。因此,用日常生活活动(ADL)标记的事件类型仅用一个设备记录,在本例中是摄像机0和加速度计。
对数据集进行组织,使每一行包含一个RGB和深度图像序列,其中考虑了相机0和相机1,它们分别平行于地板和天花板。相机和加速度计同步数据也可以下载。
4.2.结果与分析
在本节中,描述了实验和结果,以选择所提出的模型的最佳参数配置。此外,我们将提出的模型与文献中的其他模型进行了比较。
4.2.1.模型变量比较
我们比较了提出的模型的两个版本:YOLOK+ 3DCNN和YOLOK+2DCNN+LSTM。在准确度和精度指标方面,使用后一种模型获得的结果略好一些。然而,使用YOLOK+3DCNN可以获得更好的ROC曲线下面积(0.8454)和召回结果,此外,该模型的速度更快,训练时间达到了5倍的速度。
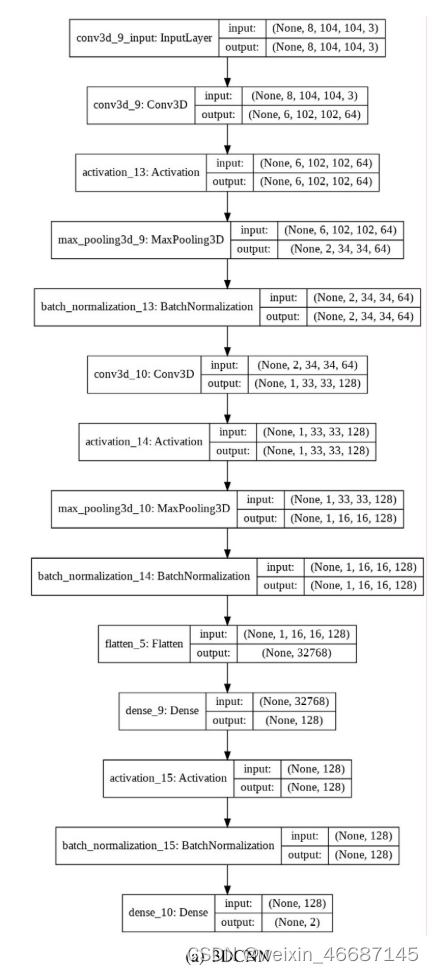
图5(a)和图5(b)分别为3DCNN和2DCNN+LSTM时间分析的模型体系结构。在第一行中,可以观察到与待分析的流段相关的图像数量,定义值为8,每个图像的输入分辨率定义值为104 × 104。在到达最后一层之前,也可以观察到其他层中张量的形状。我们使用softmax激活两个神经元,这涉及到跌倒或非跌倒的分类。
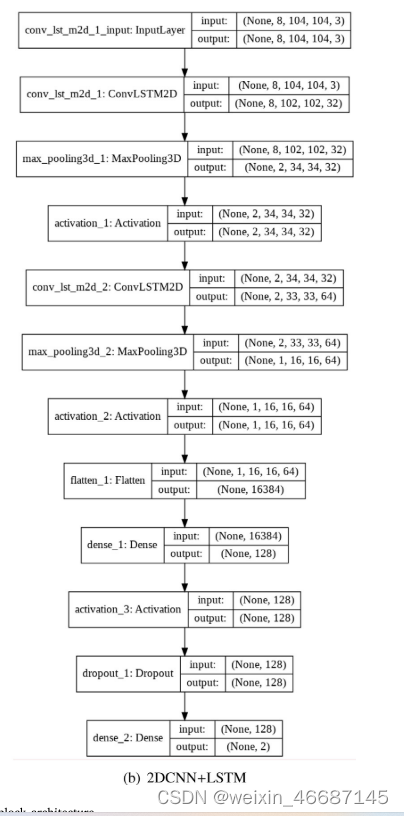
最后,在最后一步中,将时域模型与目标检测器和卡尔曼滤波器相结合,完成该方法的训练。使用的学习算法为Adadelta,学习率为0.05,采用二元交叉熵损失函数。
提出的时间处理方法受到两个架构的启发:(i)第一个是VGG-16 (Simonyan和Zisserman, 2014);但是,由于预期算法具有良好的计算性能,因此删除了一些层。因此,我们发现模型剪枝不会影响模型的性能。(ii)第二项是Nogas等人(2018)的工作,使用自动编码器实现了良好的性能和准确性。此外,去除重建层,并基于网格搜索对压缩层进行微调。
在网格搜索中,使用32和1024的值来定义神经元的数量,总是以2为基数的倍数,找到的最佳值为128。我们验证了训练集中的指标比验证集中的执行得更好。因此,我们使用批处理归一化来减少过拟合。
Li等人(2018)推荐使用卷积核大小为3 × 3的过滤器。这些作者认为,这种配置可以用来捕捉场景中人们运动时从状态到状态的转换特征。我们使用Adadelta算法对模型进行训练,该算法在上述数据集中表现出了更好的性能。
在两个模型的最后一层,我们测试了sigmoid和softmax激活函数。使用softmax激活函数,3DCNN和2DCNN+LSTM都获得了更好的结果。表2是基于3DCNN和2DCNN+LSTM在不同窗口大小下生成的某些类型的数据集的对比分析。
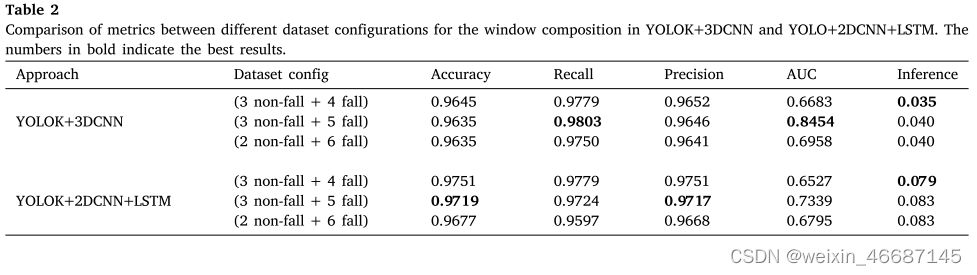
这种比较的目的是验证在用于训练的样本中产生不同数量的跌倒和非跌倒数据集之间的任何相关差异造成的不同效果。显示最有希望的结果的配置如下:
•3张非跌倒图像与4张跌倒图像(3张非跌倒+ 4张跌倒)连接在一起,总共一个大小为7的时间窗口;
•3张非跌倒图像与5张跌倒图像(3张非跌倒+ 5张跌倒)连接在一起,总共一个大小为8的时间窗口;
•2张非跌倒图像与6张跌倒图像(2张非跌倒+ 6张跌倒)连接在一起,总共一个大小为8的时间窗口。
通过这种方式,我们可以生成一个数据集,其中每个窗口有更多的跌倒帧,使模型对跌倒的假警报不那么敏感。如表2所示,有些值非常接近。然而,使用(3非跌倒+ 5跌倒)窗口,3DCNN的召回率为0.9803,AUC为0.8454;这些值是这些模拟创建的数据集中占比最大的。我们还注意到,当窗口样本中涉及跌倒的图像数量减少时,模型变得不那么敏感,有时在发生跌倒时无法发出警报。然而,当更多的图片涉及到摔倒时,模型变得更加敏感,甚至在没有摔倒的特定场景中发出警报。
我们在GTX 1060 TI上进行了模拟;对于由YOLOK+3DCNN组成的模型版本,平均执行时间为0.040 s,总帧数为25 FPS,而对于YOLOK+2DCNN+ LSTM,平均执行时间为0.083 s,总帧数为12 FPS每秒,如表2的Inference列所示。
4.2.2.比较替代方法
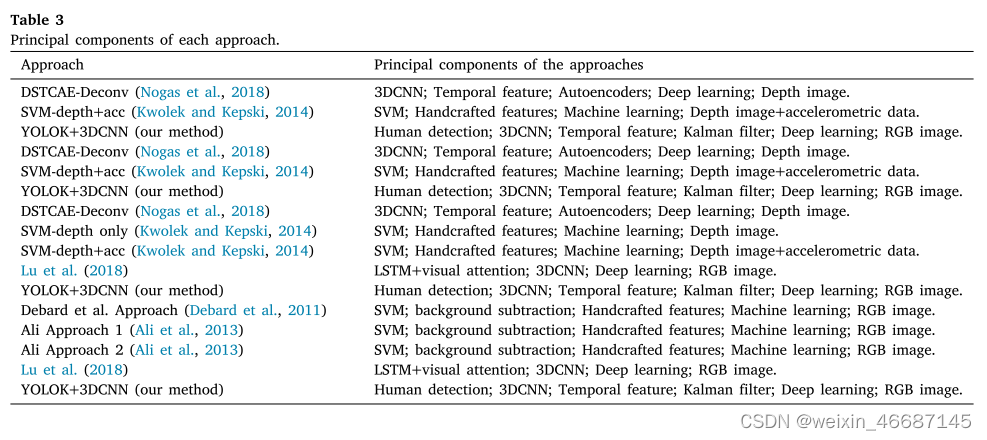
我们将相关的比较工作分为三类:(i)模型只使用特征工程和简单的机器学习算法,如svm深度方法(Kwolek和Kepski, 2014)和Ali方法(Ali et al., 2013);(ii)使用深度学习的方法,如DSTCAE-Deconv (Nogas et al., 2018)和Lu et al.(2018)提出的方法;(iii)使用前面提到的方法,将RGB图像与来自传感器的SVM-depth+acc的数据相结合的方法(Kwolek和Kepski, 2014)。在表3中,对每种方法的组件进行了进一步的详细说明。
在将YOLOK+3DCNN与文献中其他模型进行比较时,进行了几次仿真来测量结果。这些模拟是在4.1节中描述的数据集上进行的。如表4所示,考虑到第二列,前三行为AVA数据集上DSTCAEDeconv (Nogas et al., 2018)、SVM-depth+acc (Kwolek and Kepski, 2014)和YOLOK+3DCNN模型的模拟结果。在接下来的三行代码中,我们展示了对定制数据集的相同模型的模拟。
以下几行,DSTCAE-Deconv (Nogas et al., 2018)、仅支持向量机深度(Kwolek and Kepski, 2014)、支持向量机深度+acc (Kwolek and Kepski, 2014)、Lu et al.(2018)和YOLOK+3DCNN是在UR Fall Detection数据集中取得良好结果的主要模型。另一方面,在最后的五行中,Debard et al. (2011) Approach, Ali et al. (2013) Approach 1, Ali et al. (2013) Approach 2, Lu et al.(2018)和YOLOK+3DCNN参考了文献中在Multiple camera数据集上达到最佳效果的主要模型。
从表4可以看出,本文方法在UR Fall Detection和Multiple camera数据集上,在准确度、精度和AUC方面都达到了最好的值。YOLOK+3DCNN和DSTCAE-Deconv (Nogas et al., 2018)具有类似的准确性、召回率和精度结果,与DSTCAE-Deconv (Nogas et al., 2018)和SVM-depth+acc (Kwolek和Kepski, 2014)相比,提出的模型获得了0.9002的AUC,而DSTCAE-Deconv (Nogas et al., 2018)和0.6566。对于我们的自定义数据集,建议的模型在所有分析的指标中获得了更好的结果,如第三行粗体突出显示的那样。从表4可以看出,本文方法在UR Fall Detection和Multiple camera数据集上,在精度、精度和AUC方面都达到了最好的值。YOLOK+3DCNN和DSTCAE-Deconv (Nogas et al., 2018)具有类似的准确性、召回率和精度结果,与DSTCAE-Deconv (Nogas et al., 2018)和SVM-depth+acc (Kwolek和Kepski, 2014)相比,提出的模型获得了0.9002的AUC,而DSTCAE-Deconv (Nogas et al., 2018)和0.6566。对于我们的自定义数据集,提出的模型在所有分析的指标中获得了更好的结果,如第三行粗体突出显示的那样。
对于UR Fall Detection数据集,本文方法的准确率为0.9966,而文献中其他模型的准确率为0.9927、0.9833。在AUC方面,使用本文方法得到的值为0.9614,而使用DSTCAE-Deconv得到的值为0.7200 (Nogas et al., 2018)。对于Multiple camera数据集,我们的方法的精度为0.9822,而文献中其他模型的精度为0.9727、0.9658、0.9544。我们提出的方法设置中的一些小的变化有利于一些指标,但是我们更喜欢优先考虑AUC和recall。
4.3.一些有问题的场景的例子
在执行过程中,我们提出的模型中可能会出现一些不希望出现的情况。例如,如果一个人跌倒了,场景聚焦在一个特定的身体区域,模型可能会错误地对动作进行分类。在图6(a)中,人摔倒了,但结果被归类为未摔倒。另一个问题是当某人快速或笨拙地坐在沙发或椅子上。根据具体情况,这不会被认为是跌倒;但结果归类为下降,如图6(b)所示。在图6(c)中,这个人以传统的方式坐着,并进行了正确的分类。另一个问题是,当这个人在场景中部分可见时。例如,相机朝跌倒的方向移动,导致人们认为这个人是静止的;在图6(d)中,摄像机跟踪人跌倒时的运动。只有当摄像机稳定并聚焦于场景时,才能正确检测到跌倒,如图6(e)所示。最后,当背景中的某些物体导致人的部分遮挡时,可能会出现误检,主要是从腰部以下,如图6(f)所示,其中有一半人被遮挡在房间内。

5.结论
本文提出了一种结合YOLO目标检测算法和时间分类模型的方法,使用卡尔曼滤波来跟踪场景中每个人的跌倒。
实验表明,与许多结合RGB图像、深度图像和传感器图像的方法相比,本文提出的方法仅使用RGB图像可以获得更好的性能。在执行时间方面,考虑到该方法在视频中使用了深度学习,而后者本质上是计算开销更大的模型,因此,该方法可以在GTX 1060 TI显卡上以25帧/秒的速度在线执行,推理时间为0.040 s,因此取得了令人满意的性能。
结合所得到的结果,我们表明,结合卡尔曼滤波和深度学习模型的人体检测模型可以鲁棒地解决跌倒检测问题。然而,人们认为这是一个复杂的问题,主要是因为解决方案必须提供高水平的精度,以及场景、视角的显著可变性,以及可能与跌倒相混淆的人体位置,如蹲和坐。
这篇关于Multi-human Fall Detection and Localization in Videos的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




