videos专题

SAM 2: The next generation of Meta Segment Anything Model for videos and images
https://ai.meta.com/blog/segment-anything-2/ https://github.com/facebookresearch/segment-anything-2 https://zhuanlan.zhihu.com/p/712068482

【论文阅读】Single-Stage Visual Query Localization in Egocentric Videos
paper: code: 简介: 长篇自我中心视频的视觉查询定位需要时空搜索和指定对象的定位。之前的工作开发了复杂的多级管道,利用完善的对象检测和跟踪方法来执行 VQL(视觉查询定位)。然而,每个阶段都是独立训练的,管道的复杂性导致推理速度缓慢。我们提出了 VQLoC,这是一种新颖的单阶段 VQL 框架,可进行端到端训练。我们的关键思想是首先建立对查询视频关系的整体理解,然后以单次方式执行时
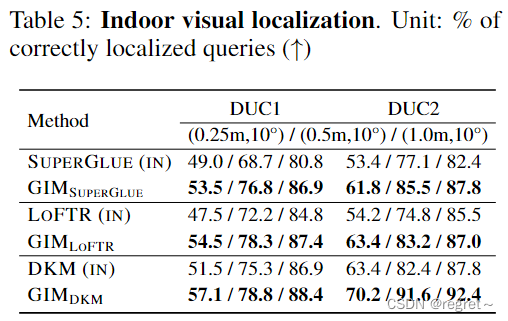
GIM: Learning Generalizable Image Matcher From Internet Videos
【引用格式】:Shen X, Yin W, Müller M, et al. GIM: Learning Generalizable Image Matcher From Internet Videos[C]//The Twelfth International Conference on Learning Representations. 2023. 【网址】:https://arxiv.or

【论文通读】VideoGUI: A Benchmark for GUI Automation from Instructional Videos
VideoGUI: A Benchmark for GUI Automation from Instructional Videos 前言AbstractMotivationVideoGUIPipelineEvaluation ExperimentsMain ResultsAnalysis Conclusion 前言 数字智能体的探索又来到了新的阶段,除了常见的桌面工具如PPT,
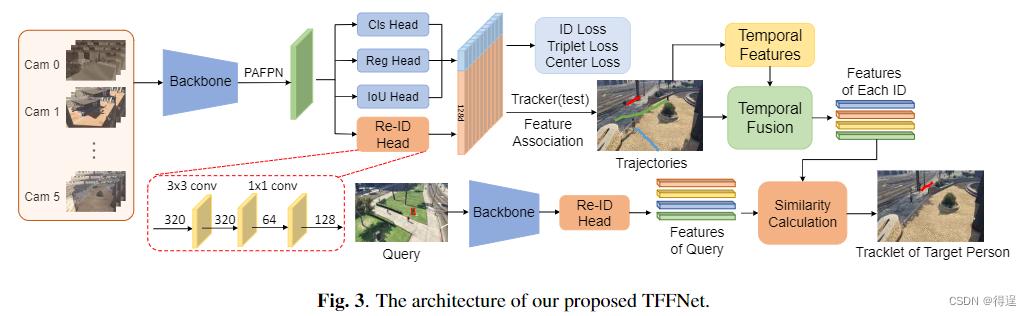
视频行人搜索 (Person Search in Videos)
文章目录 视频行人搜索 (Person Search in Videos)图像行人搜索存在问题Video PS 定义MTA-PS数据集First person search dataset in videosComplicated ambient conditions and realistic monitoring scenariosPrivacy insensitivity 方法
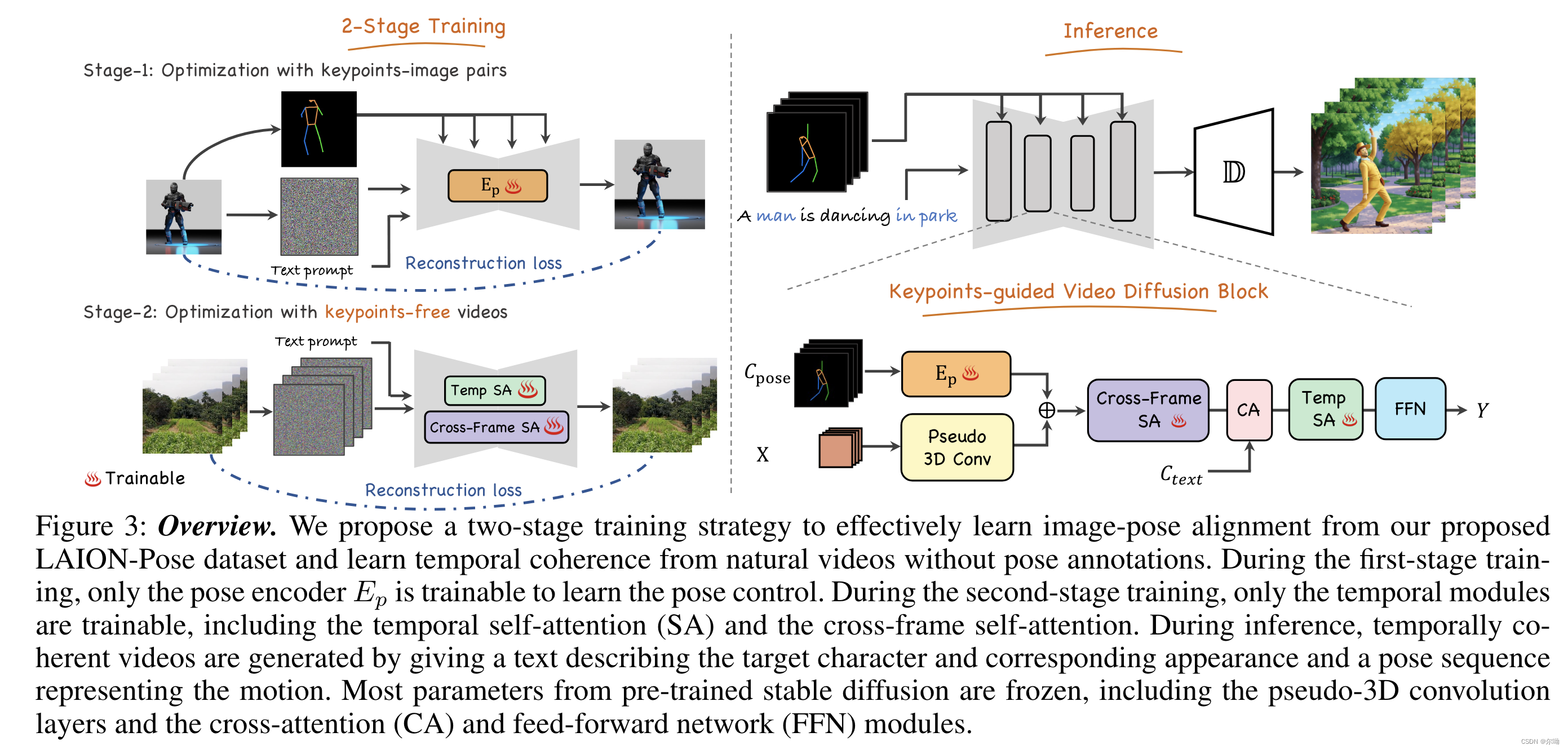
Follow Your Pose: Pose-Guided Text-to-Video Generation using Pose-Free Videos
清华深&港科&深先进&Tencent AAAI24https://github.com/mayuelala/FollowYourPose 问题引入 本文的任务是根据文本来生成高质量的角色视频,并且可以通过pose来控制任务的姿势;当前缺少video-pose caption数据集,所以提出一个两阶段的训练,可以利用image-pose数据和pose free video数据;第一阶段首先使用p
![[深度学习论文笔记]Temporal Localization of Fine-Grained Actions in Videos by Domain Transfer from Web Images](https://img-blog.csdnimg.cn/20190103195855504.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTAxNTg2NTk=,size_16,color_FFFFFF,t_70)
[深度学习论文笔记]Temporal Localization of Fine-Grained Actions in Videos by Domain Transfer from Web Images
[ACM MM 15] Temporal Localization of Fine-Grained Actions in Videos by Domain Transfer from Web Images Chen Sun, Sanketh Shettyy, Rahul Sukthankary and Ram Nevatia from USC & Google paper link Moti

Ubuntu Desktop 更改默认应用程序 (Videos -> SMPlayer)
Ubuntu Desktop 更改默认应用程序 [Videos -> SMPlayer] References System Settings -> Details -> Default Applications 概况、默认应用程序、可移动介质、法律声明 默认应用程序,窗口右侧列出了网络、邮件、日历、音乐、视频、照片操作的默认应用程序。 点击 Videos 右侧的下拉

ubuntu22.04@laptop OpenCV Get Started: 002_reading_writing_videos
ubuntu22.04@laptop OpenCV Get Started: 002_reading_writing_videos 1. 源由2. Read/Display/Write应用Demo3 video_read_from_file3.1 C++应用Demo3.2 Python应用Demo3.3 重点过程分析3.3.1 读取视频文件3.3.2 读取文件信息3.3.3 帧读取&显示

2018 Multi-University Training Contest 10 Problem L.Videos(最小费用流)
题意:一个video拥有四个属性-----开始时间,结束时间,happiness,type,给定K个人,一部片子只能被一个人看,一个人连续看x次同类型的片子(x>=2)会失去x*W的happiness,问K个人一天内看video的最大happiness和. 首先我们将一个video看作一个点. 之后,由于限定了连续看同类型的片子会掉happiness,所以我们这里引入一个拆点,点

EMNLP 2020 Beyond Instructional Videos: Probing for More Diverse Visual-Textual Grounding on YouTube
动机 从无标签的网络视频中进行预训练已经迅速成为在许多视频待处理任务中实际获得高性能的的手段。通过预测语音内容和自动语音识别(ASR) token之间的grounded关系来学习特征。然而,先前的训练前工作仅限于教学录像;作者希望这个领域是相对“容易”的:在教学视频中,演讲者通常会引用文字描述的目标/动作。即期望视频帧和ASR token中的语义信息在教学视频中可以很容易地关联起来。相似模型是否

Multi-human Fall Detection and Localization in Videos
摘要 背景:深度学习对人类行为和活动识别应用的好处的探索一直存在延迟。在这些领域中,跌倒检测因其出色的公用事业而受到关注。跌倒检测可以在养老院、有公共摄像头的区域和独居老人的家中等设施中实施,因为绝大多数与跌倒有关的死亡发生在这些地点。 目标:YOLO目标检测算法与时间分类模型和卡尔曼滤波跟踪算法相结合,用于检测视频流上的跌倒。 方法:采用本文方法时,需要进行以下步骤:(1)在图像中定位发生
![[CVPR-23] PointAvatar: Deformable Point-based Head Avatars from Videos](https://img-blog.csdnimg.cn/direct/e7733eed2c3b442d8833c5b6f5529209.png)
[CVPR-23] PointAvatar: Deformable Point-based Head Avatars from Videos
[paper | code | proj] 本文的形变方法被成为:Forward DeformationPointAvatar基于点云表征动态场景。目标是根据给定的一段单目相机视频,重建目标的数字人,并且数字人可驱动;通过标定空间(canonical space)和形变空间(deformation space)表征场景。其中,标定空间中的任意点坐标,首先映射至FLAME空间,通过对应FL

Learning Normal Dynamics in Videos with Meta Prototype Network 论文阅读
文章信息:发表在cvpr2021 原文链接: Learning Normal Dynamics in Videos with Meta Prototype Network 摘要1.介绍2.相关工作3.方法3.1. Dynamic Prototype Unit3.2. 视频异常检测的目标函数3.3. 少样本视频异常检测中的元学习 4.实验5.总结代码复现: 摘要 在视频异常检测领域

Remote Photoplethysmograph Signal Measurement from Facial Videos Using Spatio-Temporal Networks
前言 前期方法的缺陷 早期rPPG研究多数为“提取—分析”的两阶段方法,首先检测或跟踪人脸以提取rPPG信号,然后分析并估计相应的平均HR。缺点:1)基于纯经验知识自定义的面部区域,不一定是最有效的区域,这些区域应该随数据而变化。2)有些方法中使用了手动制作的特征或过滤器,可能使重要的心跳信息丢失。 前期使用的深度学习方法也可能有一下缺点:1)HR估计任务被视

TOF摄像机视频中的运动分割(MOTION SEGMENTATION IN VIDEOS FROM TIME OF FLIGHT CAMERAS)
摘要: 本文研究了深度摄像机视频序列中独立运动物体的运动估计和分割问题。具体地,我们提出了一种基于距离流和光流约束方程融合的运动估计算法。流场用于推导长期点轨迹。分割技术根据运动和深度相似性将轨迹分组为时空对象。我们展示了用飞行时间摄影机拍摄的真实场景的结果。 1.介绍: 本文分析了飞行时间(TOF)摄像机拍摄的视频序列中的短期和长期运动。我们通过综合距离流和光流来估计视频中两
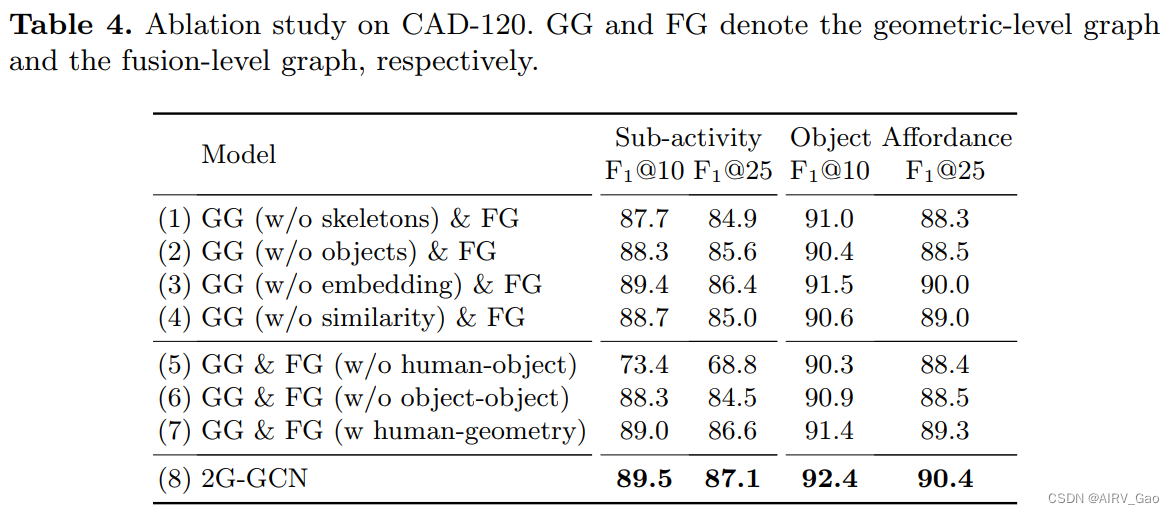
2G-GCN:Multi-person HOI Recognition in Videos
Geometric Features Informed Multi-person Human-object Interaction Recognition in Videos解读 摘要简介 2. Related Work2.1 图像中的HOI检测2.2 视频中的HOI识别2.3 HOI识别数据集2.4 几何特征为HOI分析提供信息 3. 多人HOI数据集(MPHOI-72)4. Two-le
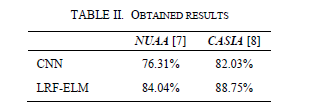
论文精度笔记(二):《Deep Learning based Face Liveness Detection in Videos 》
文章目录 论文题目摘要1.介绍2.人脸欺骗检测方法3.实验工作4.总结 论文题目 《Deep Learning based Face Liveness Detection in Videos 》 参考文献2017 IEEE(International Artificial Intelligence and Data Processing Symposium (IDAP))
Mysql数据库中将cmf_videos表中covers字段中的//video替换为/video
update `cmf_videos` SET `covers` = REPLACE(`covers`, '//video', '/video') WHERE INSTR(`covers`,'//video') > 0
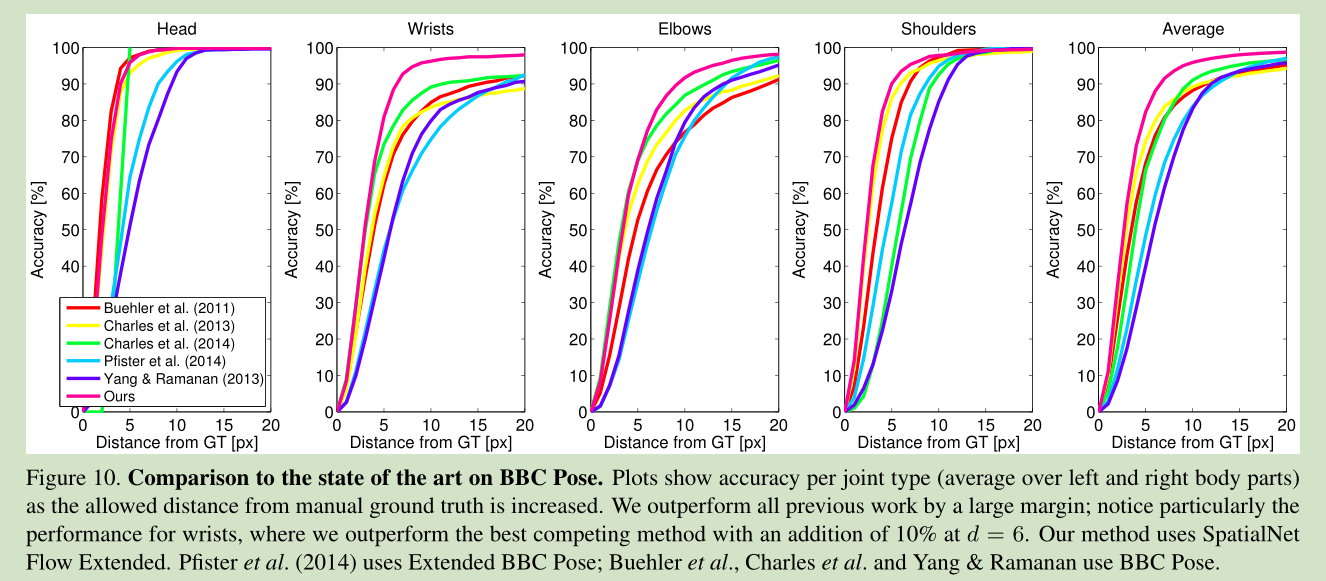
Flowing ConvNets for Human Pose Estimation in Videos
ICCV 2015 code available http://www.robots.ox.ac.uk/~vgg/software/cnn_heatmap/ 本文主要用CNN网络来进行人体姿态估计,加入了temporal 信息以提高精度。 网络框架如下: 本文对于关节位置的估计提出了一个 heatmap概念,而不是一个坐标的回归。这样做可以提高关节定位的鲁棒性。 Spatial fu
[姿态预测] Flowing ConvNets for Human Pose Estimation in Videos
ICCV 2015 code available http://www.robots.ox.ac.uk/~vgg/software/cnn_heatmap/ 本文主要用CNN网络来进行人体姿态估计,加入了temporal 信息以提高精度。 网络框架如下: 本文对于关节位置的估计提出了一个 heatmap概念,而不是一个坐标的回归。这样做可以提高关节定位的鲁棒性。 Spatial fusi

论文阅读:《Flowing ConvNets for Human Pose Estimation in Videos》ICCV 2015
概述 本文主要用CNN网络来进行人体姿态估计,加入了temporal 信息以提高精度。本文的四个贡献: 1. 提出了一个更深的CNN网络(相比于Alex-Net),不同于之前的回归坐标,而是回归heatmap,这样可以提高关节点定位的鲁棒性,并且更利于在训练过程中的可视化观察。 2. 提出一种空间融合层,用来学习隐式空间模型,即用来提取关节点之间的内在联系 3. 使用光流信息,用来对准