本文主要是介绍Follow Your Pose: Pose-Guided Text-to-Video Generation using Pose-Free Videos,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 清华深&港科&深先进&Tencent AAAI24
- https://github.com/mayuelala/FollowYourPose
- 问题引入
- 本文的任务是根据文本来生成高质量的角色视频,并且可以通过pose来控制任务的姿势;
- 当前缺少video-pose caption数据集,所以提出一个两阶段的训练,可以利用image-pose数据和pose free video数据;
- 第一阶段首先使用pose-image pair来训练pose encoder,第二阶段使用pose free video来训练时序模块;
- methods
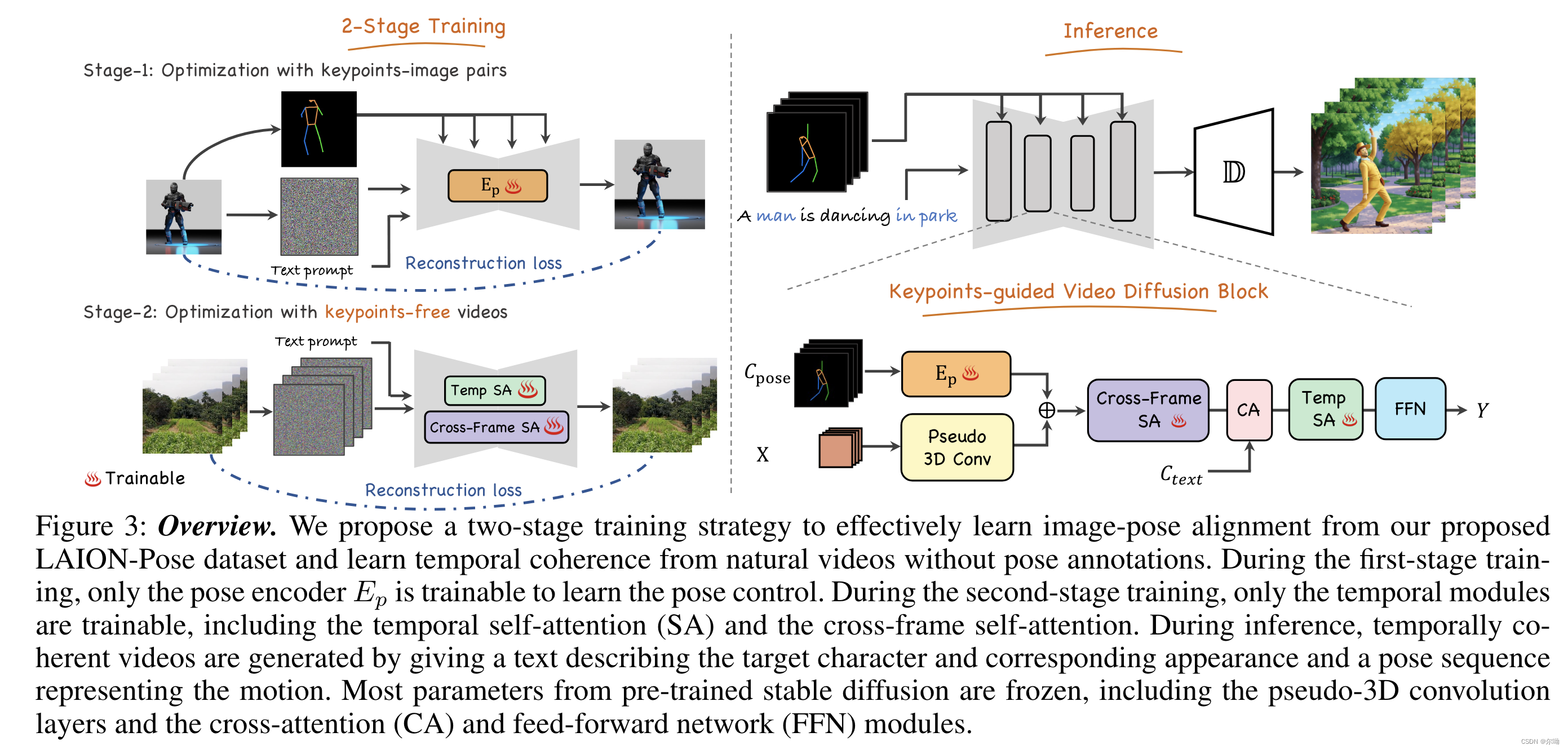
- 将任务分解为两个子问题,首先image-pose pair数据来实现pose控制,视频数据来实现帧间的一致性;
- 训练阶段1Pose-Controllable Text-to-Image Generation:pose encoder模块 E p E_p Ep
- 训练阶段2Video Generation via Pose-free Videos:时序模块;
- 实验
- Laion-Pose训练第一阶段,HDVILA第二阶段;
这篇关于Follow Your Pose: Pose-Guided Text-to-Video Generation using Pose-Free Videos的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





