pose专题

每日AIGC最新进展(54):中科大提出Pose引导的图像生成模型、韩国科技学院提出发型控制模型、北大提出风格生成数据集CSGO
Diffusion Models专栏文章汇总:入门与实战 GRPose: Learning Graph Relations for Human Image Generation with Pose Priors 在过去的研究中,基于扩散模型的人工生成技术在根据特定条件合成高质量人像方面取得了显著进展。然而,尽管之前的方案引入了姿势先验,现有方法仍然在高质量图像生成和稳定的姿势对齐上存

【python】OpenCV—Single Human Pose Estimation
文章目录 1、Human Pose Estimation2、模型介绍3、基于图片的单人人体关键点检测4、基于视频的单人人体关键点检测5、左右校正6、关键点平滑7、涉及到的库函数scipy.signal.savgol_filter 8、参考 1、Human Pose Estimation Human Pose Estimation,即人体姿态估计,是一种基于计算机视觉和深度学习的技

基于 YOLOv8n-pose 模型的图像特征提取,可用于识别特定的姿态
目录 1. __init__ 方法:初始化类的实例 2. save_pose_feat 方法: 3. load_db_pose_feat 方法: 4. cal_similarity 方法: 实现了一个基于 YOLOv8n-pose 模型的图像特征提取和相似性比较系统。它可以从图像中提取人体关键点信息,并将其保存为特征文件。然后,通过计算输入图像与数据库中图像特征的相似度,确定输入

Mediapipe holistic pose 以及 blazepose 的前端开发
文章目录 参考: 参考: 1、blazepose:https://github.com/tensorflow/tfjs-models/tree/master/pose-detection/src/blazepose_mediapipe

AlphaPose姿态估计论文翻译和代码解读RMPE: Regional Multi-Person Pose Estimation
姿态估计模型AlphoPose模型的论文 或者论文V3版 ICCV2017接收,上海交大和腾讯优图的论文 代码 ,基于pytorch或者Tensorflow 如果想了解姿态估计的简单概述,可以点击我的另一篇综述文章 RMPE: Regional Multi-Person Pose Estimation Abstract 自然场景的多人姿态估计是一个极大的挑战。虽然最好的人类检测器已经有很好的

拥挤场景多人姿态估计论文梗概及代码CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark
姿态估计是视频动作分析识别的基础工作,我有一篇小综述讲了姿态估计相关技术路线的发展,可以点这个链接看。 本文是MVIG大佬们发表在CVPR2019上的一篇论文,上号交通大学,基于AlphaPose思路,进一步提升了拥挤情况下准度 代码:github点这,基于Pytorch,是实时多人姿态估计系统 论文:论文点这 论文第二版点这 Abstract 多人姿态估计是大量计算机视觉任务的基础,近年来也

姿态估计Rethinking on Multi-Stage Networks for Human Pose Estimation论文梗概及代码解读
2018年COCO关键点检测冠军算法MSPN,姿态估计,Top-down的技术路线 应该是截止2019年10月26日时开源的最好的姿态估计算法之一了 旷世出品 代码链接点这,是基于Pytorch的 论文链接点这 摘要 姿态估计方法以基本形成one-stage 和 multi-stage两个路线 多阶段看上去更适合任务,但是现在多阶段的性能还是不如单阶段的 我们论文就来研究这个问题,我们讨论当下
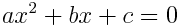
Pose-Graph SLAM 中对误差函数的理解
误差函数: ; 是状态向量,每个x代表机器人的位置(也可以是landmark的位置); 给定一个,我们就能根据测量方程计算出一个估计观测量,而实际测量量是通过传感器测量计算出来的; 这两个观测量之间存在一个err

【软件安装11】抓取姿态检测 Grasp Pose Detection (GPD) 与 gpd_ros 安装Ubuntu18.04
文章目录 一、GPD 教程1.1、依赖要求1.2、安装GPD1.3、使用GPD1.3.1 为点云文件生成抓取 1.4、参数1.5、可视1.6、神经网络的输入通道1.7、CNN框架1.8、Network Training1.9、抓取图像/描述符1.10、故障排除提示 二、gpd_ros 教程2.1 安装gps_ros流程:2.2 使用gpd_ros 抓取姿态检测(GPD

配置 human_pose_estimation_demo 的开发环境
配置 human_pose_estimation 的开发环境 主要讲述如何在 VS2017 IDE 里面配置 OpenIVNO 的演示案例 human_pose_estimation_demo 开发环境。 1. 开发环境说明 系统版本:windows 10OpenVINO 版本:2020 1IDE :VS2017 2. 创建项目 打开 VS017 ,新建项目,在新建项目时选择空项目 然后

开源SLAM框架学习——OpenVSLAM源码解析:全局优化模块(global optimization module):回环检测、pose-graph优化、global-BA优化
这篇博客主要介绍OpenVSLAM的全局优化模块(global_optimization_module),该模块是单独运行在一个线程中的。它主要执行的工作是:SLAM的回环检测,以及回环成功之后的回环矫正,还包括紧随着回环检测成功之后的pose graph优化和全局的BA优化。 1.全局优化模块入口 说是全局优化模块,其实也就是一个普通的类。对于类,第一步肯定就是实例化构造对象,全局优化模块的
初步研究Pose_300W_LP datasets.py
mat文件参数解读 Color_para:颜色参数,用于描述图像的颜色属性,比如图像的亮度、对比度等信息。 亮度属性、对比度属性、饱和度属性(颜色越鲜艳)、色调属性(色调越偏向蓝色)、色温属性(色温越高,色彩偏白)、色调偏移属性(颜色的相对变化程度)、标志位或者缩放因子 Exp_para:表情参数,用于描述人脸的表情状态,比如微笑、皱眉等。 Illum_para:光照参数,用于描述图像中的光

KITTI数据中pose含义
Folder ‘poses’: The folder ‘poses’ contains the ground truth poses (trajectory) for the first 11 sequences. This information can be used for training/tuning your method. Each file xx.txt contains a N
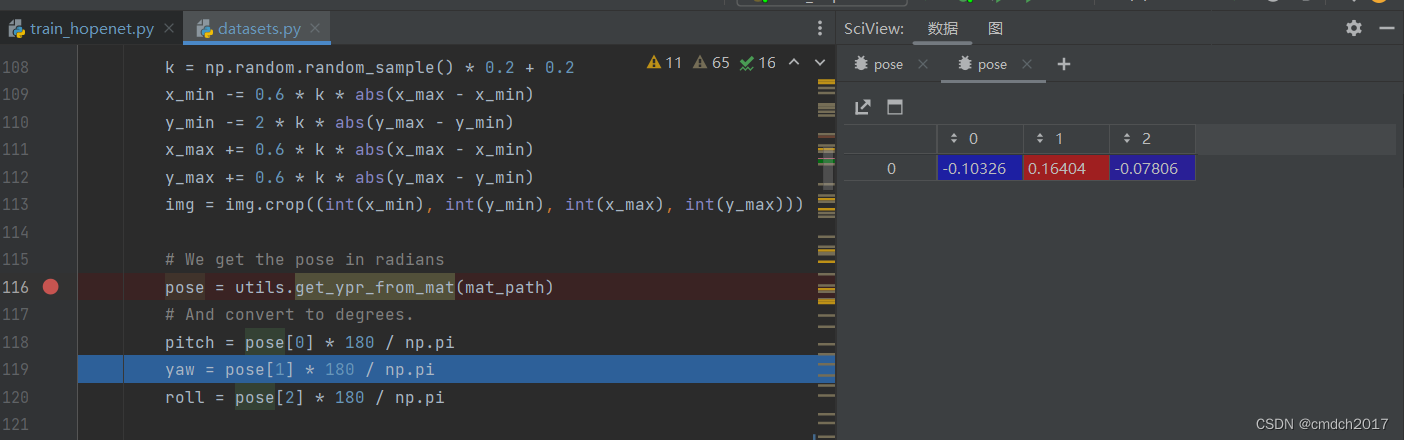
Follow Your Pose: Pose-Guided Text-to-Video Generation using Pose-Free Videos
清华深&港科&深先进&Tencent AAAI24https://github.com/mayuelala/FollowYourPose 问题引入 本文的任务是根据文本来生成高质量的角色视频,并且可以通过pose来控制任务的姿势;当前缺少video-pose caption数据集,所以提出一个两阶段的训练,可以利用image-pose数据和pose free video数据;第一阶段首先使用p
![YOLOv8_pose的训练、验证、预测及导出[关键点检测实践篇]](https://img-blog.csdnimg.cn/direct/08c95a911bfd49b38b2aa59a3b7b822b.png)
YOLOv8_pose的训练、验证、预测及导出[关键点检测实践篇]
1.关键点数据集划分和配置 从上面得到的数据还不能够直接训练,需要按照一定的比例划分训练集和验证集,并按照下面的结构来存放数据,划分代码如下所示,该部分内容和YOLOv8的训练、验证、预测及导出[目标检测实践篇]_yolov8训练测试验证-CSDN博客是重复的,代码如下: """随机划分训练集和验证集"""import osimport rand
Realtime_Multi-Person_Pose_Estimation训练问题
https://blog.csdn.net/kkae8643150/article/details/102711101 前言 最近在研究Realtime_Multi-Person_Pose_Estimation的训练和再训练的过程。 参考 https://blog.csdn.net/qq_38469553/article/details/82119292 以及官方github https://
Creating a Pose Control *
为模型设置一个初始的姿势姿态。选择模型的根节点,打开属性编辑器。在选项菜单中选择"ERC Freeze..."。这允许你捕获当前姿势与默认姿势的差异,并将其存储为一个新的参数控制器。为新控制器设置一个唯一的内部名称和显示标签名称。使用属性移动器将新创建的控制器移动到合适的分组下(比如手部姿势控制器就移动到"手部"分组)。测试新的控制器,确保它可以在参数选项卡中正常工作,控制模型姿势。 详细文档连
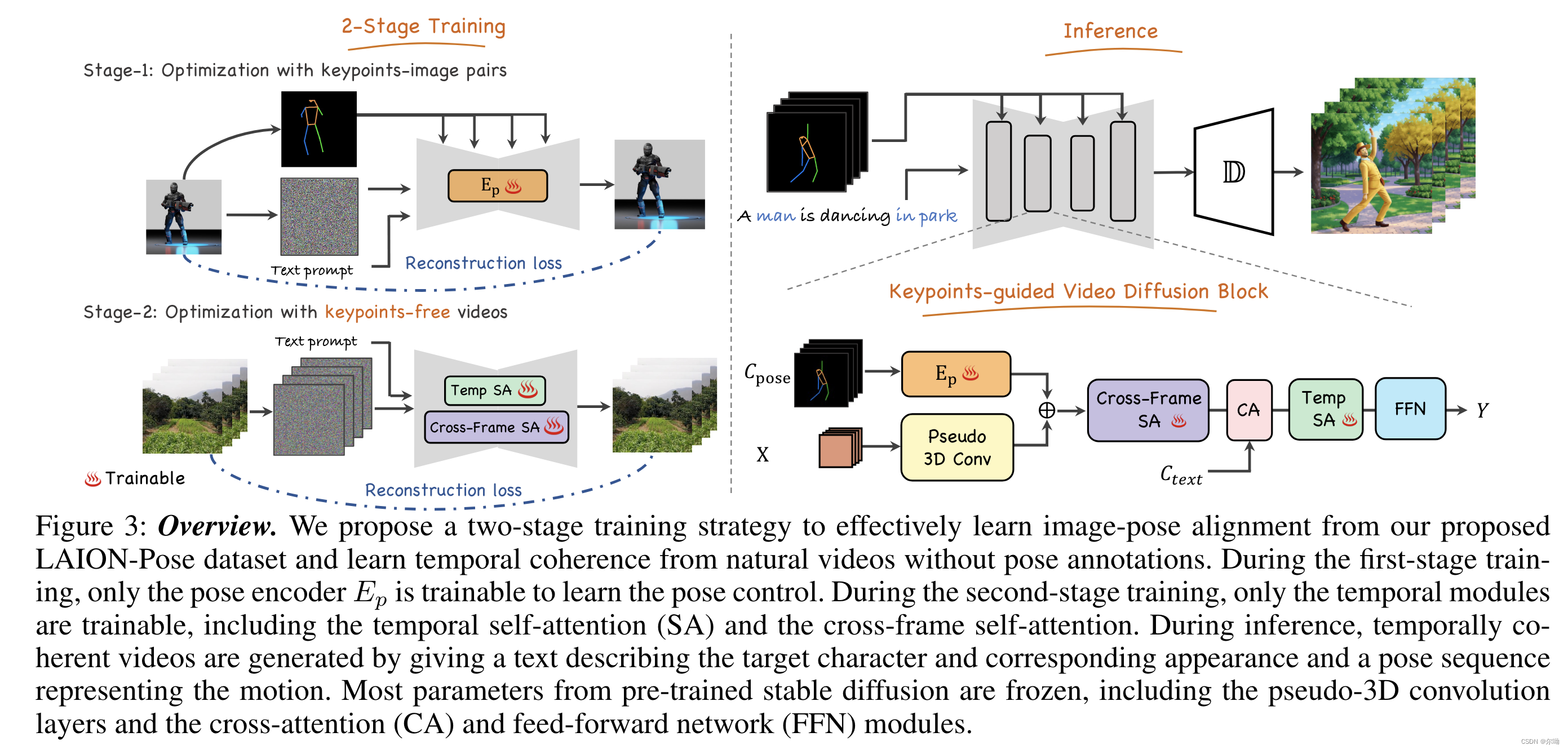
YOLOv8-pose针对视频实时提取打印对应关节点序号及坐标
因为我在找如何提取YOLOv8-pose的关键点的时候,大多都是针对静态图像,视频直接套用不太行,因此就改进了一下,如下: 初步代码: import torch # 导入PyTorch库import cv2 as cv # 导入OpenCV库并重命名为cvimport numpy as np # 导入NumPy库并重命名为npfrom ultralytics.data.augmen

Stacked Hourglass Networks for Human Pose Estimation 用于人体姿态估计的堆叠沙漏网络
Stacked Hourglass Networks for Human Pose Estimation 用于人体姿态估计的堆叠沙漏网络 这是一篇关于人体姿态估计的研究论文,标题为“Stacked Hourglass Networks for Human Pose Estimation”,作者是 Alejandro Newell, Kaiyu Yang, 和 Jia De

论文笔记--Optical Mouse: 3D Mouse Pose From Single-View Video_从单视角视频看x小鼠3D姿态
将这些最初为推断人类三维姿态而开发的技术改编为小鼠。我们预测小鼠的二维关键点,然后根据从数据中学到的先验因素对三维姿势进行优化。 数据获取 连续、多视角和步态。 连续视频数据是来自32个笼子的14天的数据,每个笼子都配备了一个摄像头(Vium)。在黑暗周期中,使用红外线照明。8只动物是一岁的、以c57b6为背景的基因敲除小鼠;8只是一岁的杂合子对照组;8只是一岁的c57b6小鼠;以及8
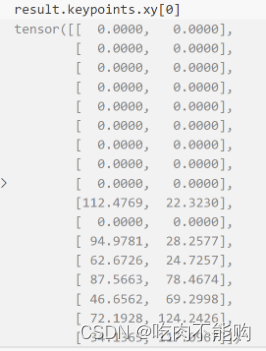
yolov8 pose keypoint解读
yolov8进行关键点检测的代码如下: from ultralytics import YOLO# Load a modelmodel = YOLO('yolov8n.pt') # pretrained YOLOv8n model# Run batched inference on a list of imagesresults = model(['im1.jpg', 'im2.jpg']

Halcon算子学习:create_pose
create_pose 创建3D位姿 ( : : TransX, TransY, TransZ, RotX, RotY, RotZ, OrderOfTransform, OrderOfRotation, ViewOfTransform : Pose) 输入: TransX 沿x轴平移(以[m]为单位)。 默认值:0.1 建议值:-1.0,-0.75,-0.5,-0.25,-0.2,-0.

pose graph 估计实验和机器学习应用场景
玩乐: 用pose graph 估计相机位姿的实验 目前开源的SLAM RGB-D相机方案主要有: DTAM https://github.com/anuranbaka/OpenDTAM DVO https://github.com/tum-vision/dvo_slam RTAB-MAP https://github.com/introlab/rtabmap RGBD-SLAM-V2 htt
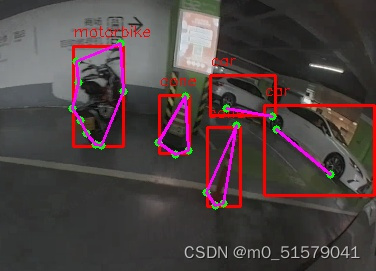
【保姆级教程】YOLOv8_Pose多目标+关键点检测:训练自己的数据集
Yolov8官方给出的是单类别的人体姿态关键点检测,本文将记录如果实现训练自己的多类别的关键点检测。 一、YOLOV8环境准备 1.1 下载安装最新的YOLOv8代码 仓库地址: https://github.com/ultralytics/ultralytics 1.2 配置环境 pip install -r requirements.txt -i https://pypi.t

win10下采用XShell+Xmanager运行lightweight-human-pose-estimation
目录 1.背景 2.系统及软件配置 3.开始工作 4.各种报错以及解决方案 4.1 No module named “XXX” 4.2 ImportError: libGL.so.1: cannot open shared object file: No such file or directory 4.3 qt.qpa.plugin: Could not load the Qt