本文主要是介绍论文精度笔记(二):《Deep Learning based Face Liveness Detection in Videos 》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 论文题目
- 摘要
- 1.介绍
- 2.人脸欺骗检测方法
- 3.实验工作
- 4.总结
论文题目
《Deep Learning based Face Liveness Detection in Videos 》
参考文献2017 IEEE(International Artificial Intelligence and Data Processing Symposium (IDAP))
《视频中基于深度学习的面部表情检测》本人自译,转载译本需经许可!!!!!
摘要
人脸是重要的生物特征量,可用于访问基于用户的系统。由于可以通过移动摄像头和社交网络轻松获得人脸图像,因此基于用户的访问系统应具有强大的抵御欺骗性面部攻击的能力。换句话说, 一个可靠的基于人脸的访问系统可以确定输入人脸的身份和活跃性。为此,已经提出了各种基于特征的欺骗面部检测方法。这些方法通常针对输入图像应用一系列处理,以检测面部的生动度。本文提出了一种基于深度学习的欺骗人脸检测算法。两种不同的深度学习模型用于实现这一目标,即局部感受野(LRF)-ELM和CNN. LRF-ELM是最近开发的模型,其中包含卷积和池化层,而全连接层则使模型快速。但是,CNN包含一系列卷积和池化层。此外,CNN模型可能具有更多完全连接的层。在两个流行的欺骗性面部检测数据库NUAA和CASIA上进行了一系列实验。然后比较所获得的结果,并且对于两个数据库,LRF-ELM方法均产生更好的结果。
索引词-人脸识别,人脸欺骗检测,深度学习,CNN,LRF-ELM
1.介绍
人脸识别在用户身份验证中起着至关重要的作用,并且对于许多基于用户的系统来说都是必不可少的[1]。在过去的十年中,人脸识别在许多领域得到了快速发展[2]。面部识别系统面临着各种类型的面部欺骗攻击,例如打印攻击,重播攻击和3D掩饰攻击[3]。
帕特尔(Patel)等人。研究了手机上的面部欺骗检测,他们使用移动面部欺骗数据库开发了可在Android移动操作系统上运行的原型,作者还建立了一个名为MSU MSF的欺骗性人脸数据库,其中包含1,000多个主题[3]。Wen等。提出了一种有效的面部欺骗检测算法。作者的目标是设计一种具有快速响应能力的,具有良好泛化能力的系统。 图像失真分析是算法中提取特征向量的关键作用。功能包括镜面反射,模糊,色度矩和颜色多样性。打印的照片攻击和重播的视频攻击用作面部欺骗攻击,以确定是活着的还是欺骗的面孔。多任务支持向量机(SVM)分类器被用于分类任务[4]。Tirunagari等。开发了一种面部反欺骗检测算法。他们通过使用一种称为动态模式分解(DMD)的算法来捕获视频的内容,以捕捉生动的提示,例如眨眼,嘴唇移动和其他面部动态。为了证明该算法的有效性,在三个公共数据库上进行了实验研究[5]。 在文献中,Komulainen等人。率先研究了面部动态纹理以进行面部欺骗检测。引入了一种通过使用局部二进制模式(LBP)算法来学习面部纹理的结构的方法。在两个公共数据库上的实验显示了实验结果超越了2013年的最先进技术[6]。 Tan等。提出了一种实时且非侵入式的面部欺骗检测方法。他们的方法涉及对Lambertian模型的分析。为了实现该方法,在各种光照条件下收集了一个包含15个对象的大型面部欺骗数据库。 通过标准网络摄像头捕获了50,000多张照片图像。对所提出方法的评估为欺骗检测提供了有希望的性能[7]。张等。发布了包含50个主题的面部反欺骗数据库。该数据库涵盖了三种类型的攻击,并包括三种成像质量,在第三节中进行了详细描述。为了在分类过程中做出最终决定,使用了SVM。作者希望该数据库能为将来的面部欺骗工作提供帮助[8]。
在本文中,提出了一种基于深度学习的欺骗人脸检测技术。为了实现这一目标,我们使用了两种不同的深度学习模型,即LRF-ELM和CNN。 LRF-ELM模型包含一个卷积层,一个池化层和一个全连接层。此外, CNN模型具有五个卷积层和三个完全连接的层。 整流线性单元(RELU)和局部响应归一化层位于第一和第二卷积层之后。 模型中还有五个最大池化层,它们遵循一些卷积层。有两个dropout 层,在第一个和第二个全连接层之后(概率为0.5), 最后,loss层用作最后一层。面部欺骗检测已从打印攻击和重播攻击方面进行了分析。在两个流行的欺骗性面部检测数据库NUAA和CASIA上进行了一系列实验。
本文的组织结构如下:在第二部分中,简要介绍了深度学习模型的组成部分。工作的核心是第三部分,其中提供了数据库,深度学习模型和实验结果。此外,所有实验结果和相关比较均在第三部分之内。最后的结论和未来的工作计划将在第四部分给出。
2.人脸欺骗检测方法
在文献中,作者通常使用一种人脸欺骗检测框架,该框架首先处理一个特征提取阶段,然后是一个分类阶段。在目前的工作中,目标是使用一个紧凑的结构,其中特征提取和分类阶段相结合。为此,我们考虑了最近比较流行的深度CNN和LRF-ELM方法。深层模型的详细介绍如下。该方法的流程图如图1所示。

图1:给出了该方法的流程图
A.深度模型的简要理论
本节简要回顾了deep模型的理论。关于LRF-ELM和CNN模型的更详细的解释见[9,10]。一个通用的深度学习模型由卷积层、池化层和全连接层组成。
1)卷积层:这一层被称为CNN架构的核心层。在这一层中有一组可学习的filters。在这一层。在CNN的训练过程中,每个滤波器都在前向传递中对输入体积的宽度和高度进行卷积。卷积操作之后,构造了滤波器的二维激活映射。结果,这个网络学习filters,当他们在输入的空间位置看到特定类型的特征时就会激活。
2)池化层:CNN架构的另一个重要概念是池化。它形成了一个非线性下采样层。池化操作可以用几个非线性函数来处理。最大池化似乎是最常见的方法,即将输入图像分割成一组不重叠的矩形子区域。对于每个子区域,以最大值作为输出。池化操作减小了输入的空间大小,也减少了网络中的参数量和计算量。
3)全连接层:经过若干个卷积层和池化层,分类过程在一个全连接层进行处理。处于完全连接层中的神经元与前一层的所有激活都有全连接。它们的激活可以通过矩阵乘法和偏置偏移来计算。
3.实验工作
如前所述,我们考虑了CNN和LRF-ELM两种深度模型。LRF-ELM模型包含一个卷积层、一个池化层和一个全连接层。此外,CNN模型有五个卷积层和三个完全连通的层。整流线性单元(RELU)和局部响应归一化层在第一和第二卷积层之后。在模型中还有五个最大池层,它们遵循一些卷积层。在第一层和第二层完全连接的层之后有两个dropout 层,概率为0.5。最后,loss层用作最后一层。值得一提的是,对于LRF-ELM模型,所有输入图像的大小调整为32×32像素,对于CNN模型,其大小调整为224×224像素。
为了评估所提出方法的性能,在两个公众面部欺骗数据库上进行了实验。表I中列出了NUAA和CASIA数据库的比较。有关数据库的相关信息,请参阅A和B小节。
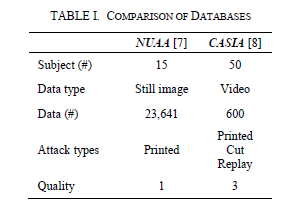
表I.数据库比较
A. NUAA数据库
NUAA数据库通过使用通用网络摄像头来区分照片中的真实面孔。它是在不同的照明条件和地点收集的。这项工作中有十五个类别。 作者捕获了两种类型的图像:称为“客户”的实时主题图像和称为“冒名顶替者”的照片[7]。 Client归一化和Imposter归一化图像的样本如图2所示。

图2:NUAA数据集的样本图片,第一行和第三行是客户规范化,第二行和第四行是冒名顶替者标准化
在这项实验工作中,使用了几何归一化的灰度面部图像数据库。归一化的数据库包含用于客户测试的3,362个在线主题和用于客户培训的1,743个在线主题。此外,它还有5,761张用于冒名顶替者测试的照片和1,748张用于冒名顶替者训练的照片。数据库中的每个图像均具有8位灰度级(64×64像素),并且规范化数据库中的图像总数为12,614。
B.CASIA数据库
由Zhang等人建立的CASIA面部欺骗数据库由50个主题组成。为了从假脸攻击中确定活脸[8]。为此设计了三种攻击,分别是打印照片攻击,剪切照片攻击和视频重播攻击。来自视频图像的攻击类型显示在图3的第二,第三和第四行中。
使用三个不同的相机为数据库捕获三个不同的成像质量视频(低分辨率,正常分辨率,高分辨率)。低分辨率视频的尺寸为480×640像素,普通分辨率的像素为640×480像素。但是,尽管高分辨率视频的原始大小为1920×1080像素,但为节省计算成本,作者将其裁剪为1280×720像素。视频质量显示在图3的第一,第二和第三栏中。
在安排数据库时,每个主题都有一组12个视频(3个直播,9个假冒),如图3所示。测试部分数据库的30个主题,因此360个视频。
对于训练部分,有240个视频为20个受试者录制。数据库共有600个视频,如表一所示。

图3. CASIA数据库的样本图像。第1行:实时,第2行:打印照片攻击,第3行:剪切照片攻击,第4行:视频重播攻击。第1列:低分辨率,第2列:普通分辨率,第3列:高分辨率。
C.性能评估
在两个数据库上都使用两个深度模型进行了实验。 LRF-ELM模型的卷积层包含40个大小为5×5的滤波器。 LRF-ELM方法的正则化参数(C)选择为0.2。 LRF-ELM模型的批处理大小分配为500。此外,CNN模型的三个卷积层包含64个大小为11×11的滤镜,256个大小为5×5的滤镜和256个大小为3×3的滤镜。 CNN模型的学习参数固定为0.001,并且批次大小选择为25。
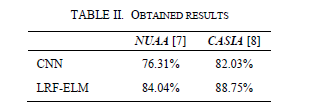
表二:获得的结果
所得结果列于表二。 LRF-ELM模型为两个数据库都产生更高的精度值。对于NUAA数据库,LRF-ELM模型的正确分类率为84.04%,而CNN模型的正确分类率为76.31%。换句话说,LRF-ELM模型产生的准确度提高了近8%。对于CASIA数据库,可以看到类似的性能。与CNN模型相比,LRF-ELM模型产生的准确结果高出近6%。
4.总结
在本文中,对面部表情的检测进行了比较研究。面部活动度检测是数字取证环境中的热门话题,在该环境中,需要基于面部的访问系统的可靠性。随着深度学习工具的发展,越来越多的实际应用正在被提出。 在这项工作中,本文的作者开发了一种基于深度学习的面部欺骗检测系统。流行的深度学习方法(LRF-ELM和CNN)用于面部表情检测。在这项研究中使用了两个广泛使用的面部活动度检测数据库。 获得的结果表明,对于两个数据库,LRF-ELM方法均产生了更准确的结果。此外,LRF-ELM方法的训练时间比CNN模型的训练时间短。在未来的工作中,作者计划通过使用不同的深度模型来增强CNN的性能。另外,计划是使用各种尺寸的面部图像,以提高CNN模型的质量。
这篇关于论文精度笔记(二):《Deep Learning based Face Liveness Detection in Videos 》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







