本文主要是介绍Learning Normal Dynamics in Videos with Meta Prototype Network 论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章信息:发表在cvpr2021

原文链接:
Learning Normal Dynamics in Videos with Meta Prototype Network
- 摘要
- 1.介绍
- 2.相关工作
- 3.方法
- 3.1. Dynamic Prototype Unit
- 3.2. 视频异常检测的目标函数
- 3.3. 少样本视频异常检测中的元学习
- 4.实验
- 5.总结
- 代码复现:
摘要
在视频异常检测领域,基于自动编码器(Auto-Encoder,AE)的帧重构(当前或未来帧)方法是一种流行的技术。通过在正常数据上进行训练,模型通常能够将异常场景的重构误差与正常场景相比显著增大。之前的一些方法在自动编码器中引入了内存存储库(memory bank),以编码跨训练视频的各种正常模式。然而,这些方法会消耗大量内存,并且无法处理在测试数据中出现的未见过的新场景。
在我们的工作中,我们提出了一种动态原型单元(Dynamic Prototype Unit,DPU),用于实时将正常动态编码为原型,而无需额外的内存成本。此外,我们引入了元学习到我们的动态原型单元,形成了一种新颖的少样本正常性学习器,即元原型单元(Meta-Prototype Unit,MPU)。这使得我们的系统能够通过仅消耗少量迭代即可快速适应新场景。我们在多个基准数据集上进行了广泛的实验,结果表明我们的方法在性能上优于当前最先进的方法,证明了我们方法的有效性。
1.介绍
作者的主要工作是在视频异常检测(VAD)领域,提出了一种新的方法。首先,他们介绍了视频异常检测的背景和重要性,尤其是在公共安全监控中的关键作用。然后,作者指出了目前的异常检测方法中存在的问题,即对“异常”的定义概念不确定,难以收集所有可能异常的数据。因此,异常检测通常被制定为一种无监督学习问题,旨在通过学习模型仅利用正常数据中的规律模式。作者指出,Deep Auto-Encoder(AE)是视频异常检测的流行方法,通常用于对历史帧建模并重构当前帧或预测未来帧。
为了解决传统方法中存在的问题,作者提出了一种动态原型单元(DPU),用于实时编码正常动态并形成原型。他们还引入了元学习到DPU,形成了一种少样本正常性学习器,称为Meta Prototype Unit(MPU)。MPU通过学习目标模型的初始化,并在推断过程中通过少量参数更新调整到新场景,从而提高了场景适应能力。
主要贡献包括:
- 提出了动态原型单元(DPU),用于学习表示正常数据的多样性和动态模式。
- 引入元学习到DPU,将其改进为少样本正常性学习器(MPU),通过少量参数和更新迭代赋予模型快速适应能力。
- 在多个无监督异常检测基准上,作者的DPU-based AE实现了新的最先进性能,并验证了MPU在少样本设置中的适应能力。
下图为方法概述:
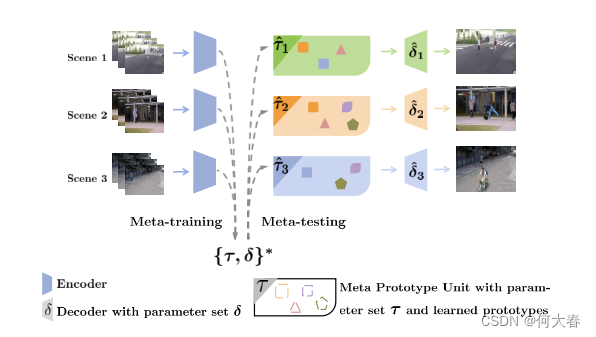
图1:方法概述。(1)设计了一个动态原型单元(Dynamic Prototype Unit,DPU),用于学习编码正常动态的一组原型;(2)引入元学习方法,将DPU构建为一个少样本正常性学习器——元原型单元(Meta-Prototype Unit,MPU)。它通过学习目标模型的初始化,并在推断过程中通过参数更新调整到新场景,提高了场景适应能力。
2.相关工作
-
异常检测问题:由于异常数据的缺失和标注成本昂贵,视频异常检测被划分为几种学习问题,其中无监督设置假设只有正常训练数据,而弱监督设置可以访问具有视频级标签的视频。作者关注实际应用中更为实际的无监督设置。先前的方法主要基于稀疏编码、马尔科夫随机场、混合动态纹理、混合概率主成分分析模型等,而深度学习,尤其是卷积神经网络(CNNs),在视频异常检测方面取得了成功。
-
深度Auto-Encoder和问题:许多方法使用深度Auto-Encoder(AE)来建模正常模式并重构视频帧。然而,这些方法可能面临“过度泛化”问题,即有时异常帧也可以被良好地预测为正常帧。一些方法引入了记忆库来处理此问题,但这会带来额外的内存成本。
-
提出的方法:提出了一种动态原型单元(DPU),用于实时编码正常动态并形成原型。为了解决记忆库的内存成本问题,作者采用了一种注意机制来测量正常程度。此外,作者引入了元学习技术到DPU模块中,使其具备快速适应新场景的能力。
-
注意机制:注意机制被广泛应用于许多计算机视觉任务,包括通道注意和空间注意。作者利用注意机制来测量空间局部编码向量的正常性,并使用它们生成编码正常模式的原型项。
-
少样本学习和元学习:在少样本学习中,研究人员旨在模仿人类的快速学习能力,即只需少量数据示例就能快速适应新场景。作者引入了元学习技术,将DPU模块改进为Meta Prototype Unit(MPU),使其具备快速适应能力。与其他简单任务的元学习方法不同,作者的方法针对视频异常检测进行了精心设计。
总体而言,作者的工作主要集中在提出一种新颖的方法,利用动态原型单元(DPU)和元学习技术,以实现对视频异常检测中新场景的快速适应。
3.方法
3.1. Dynamic Prototype Unit
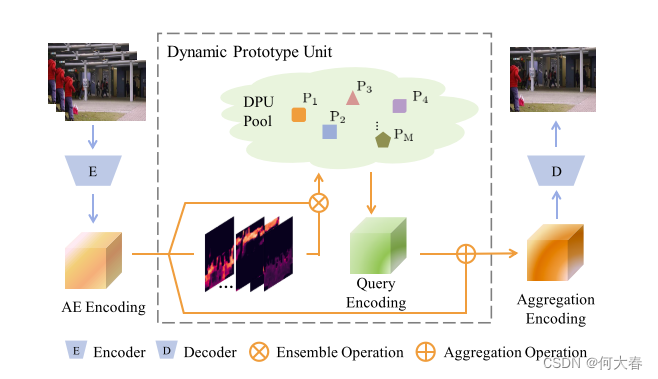
图2:基于DPU模型的框架。提出的动态原型单元(DPU)被嵌入到一个自动编码器(AE)中,用于学习编码正常动态的原型。这些原型是通过在AE编码的基础上利用正常度权重进行引导而获得的,而AE编码的正常度权重是通过完全可微的注意机制生成的。然后,一个正常度编码映射(绿色)被重构为学习到的原型的编码。它进一步与AE编码映射聚合,用于后续的帧预测。
简单来说,DPU就是一个注意力机制,将DPU插入到AE中对特征图进行权重重新计算。DPU首先得到多个对应输入编码特征每个元素位置的注意力图,然后分别得到对应的多个原型特征向量。通过对原型向量的查询和提取,就可以得到加强后的特征图。
3.2. 视频异常检测的目标函数
整个架构通过过去的几帧预测未来的一帧,损失函数由两个部分组成,一个是预测帧的损失,另一个是重构特征图的损失,重构特征图的损失也就是DPU中产生的损失。

其中 L f r a L_{fra} Lfra是帧预测损失, L f e a L_{fea} Lfea是DPU重构特征图的损失,λ是超参数。损失函数的具体计算参考原论文。
3.3. 少样本视频异常检测中的元学习
结合元学习理论,把DPU变成为元学习原型组件。可以理解为通过元学习,将别的训练集得到的模型快速应用到样本少的模型上面。
4.实验
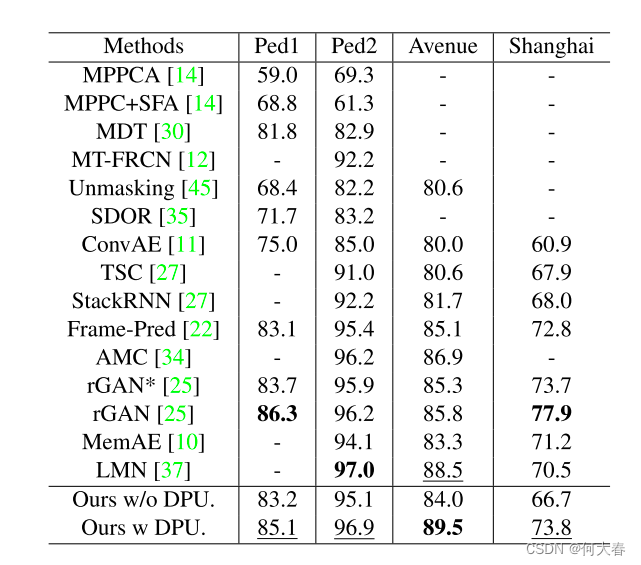
第一个实验是作者在4个数据集上测试了带有DPU单元的网络,对比结果如下:
第二个实验是测试元学习的效果:作者在Shanghai Tech和UCF crime数据集的模型通过元学习应用在别的数据集上
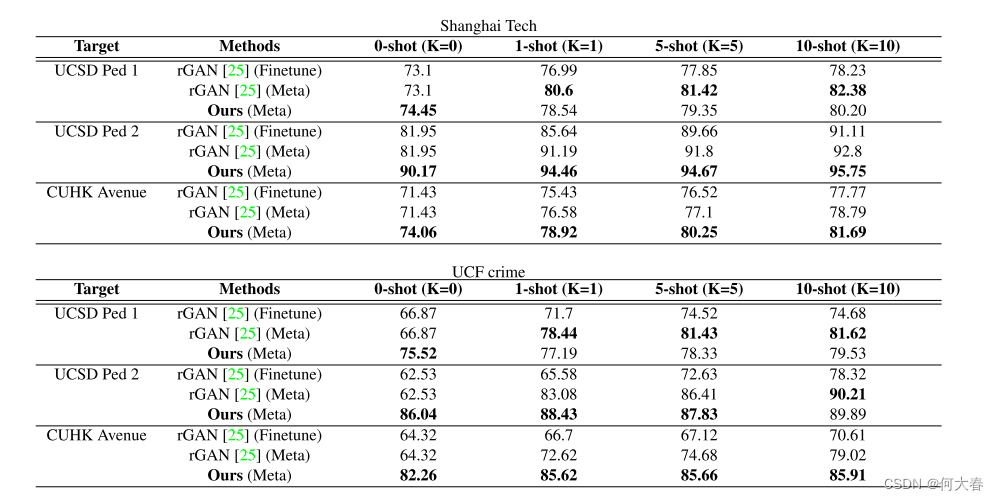
可以看出,结果都还可以。
5.总结
在这项工作中,我们引入了一个原型学习模块,通过使用注意机制来明确建模视频序列中的正常动态,以进行无监督的异常检测。该原型模块是完全可微的,并以端到端的方式进行训练。在不额外消耗内存的情况下,我们的方法在无监督设置下在各种异常检测基准上实现了最先进的性能。此外,我们利用元学习技术将原型模块改进为一个少样本正常性学习器。广泛的实验评估证明了该场景适应方法的有效性。
代码复现:
我在ped2数据集上复现了DPU的结果,但是效果和作者的差了10个百分点。有没有复现成功的大佬帮帮忙,是不是我没有正确设置训练的参数。下图是我的结果,用的是epoch=300的模型,当然epoch=1000时效果也没上90,最好的时候是将近89吧。

我也根据作者的代码逻辑换了一个数据集,效果也不是很好。想换自己的数据集的同学如果遇到困难可以一起交流。
这篇关于Learning Normal Dynamics in Videos with Meta Prototype Network 论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)