meta专题

Vue3+vite中使用import.meta.glob
前言: 在vue2中支持require导入模块或文件但是在vue3中已经不支持require导入了,为此vite提供了一个全新的方法import.meta.glob方法来支持批量导入文件 import.meta.glob 匹配到的文件默认是懒加载的,通过动态导入实现,并会在构建时分离为独立的 chunk。如果你倾向于直接引入所有的模块(例如依赖于这些模块中的副作用首先被应用

「深入理解」HTML Meta标签:网页元信息的配置
「深入理解」HTML Meta标签:网页元信息的配置 HTML的<meta>元素用于提供关于HTML文档的元数据(metadata),这些信息对于浏览器和其他处理HTML文档的应用程序来说是非常有用的,如:<base>、<link>、<script>、<style> 或 <title>。 <meta>标签通常放置在文档的<head>部分,不直接向用户展示内容,而是提供给浏览器

RDMA over Ethernet用于Meta规模的分布式AI训练
摘要: 近年来,AI模型的计算密度和规模迅速增长,推动了构建高效可靠专用网络基础设施的需求。本文介绍了Meta公司基于RDMA over Converged Ethernet(RoCE)的分布式AI训练网络的设计、实施和运营。 我们的设计原则涉及对工作负载的深入理解,并将这些见解转化为各种网络组件的设计:网络拓扑 - 为支持AI硬件平台的世代快速演进,我们将基于GPU的训练分离到专门的"后端"

SAM 2: The next generation of Meta Segment Anything Model for videos and images
https://ai.meta.com/blog/segment-anything-2/ https://github.com/facebookresearch/segment-anything-2 https://zhuanlan.zhihu.com/p/712068482

html中meta标签的http-equiv的典型用法(转)
Meta http-equiv属性详解(转) 博客分类: Web综合 HTML 浏览器 IE Cache 搜索引擎 http-equiv顾名思义,相当于http的文件头作用,它可以向浏览器传回一些有用的信息,以帮助正确和精确地显示网页内容,与之对应的属性值为content,content中的内容其实就是各个参数的变量值。 引用 meat标签的http-equiv属性语法格

【网络安全】Instagram 和 Meta 2FA 绕过漏洞
未经许可,不得转载。 文章目录 漏洞概述技术细节Meta 2FA 绕过步骤Instagram 2FA 绕过步骤总结 漏洞概述 该漏洞允许攻击者在具有受害者Facabook账户权限的情况下,绕过 Meta 的双重身份验证 (2FA) 机制,实现账户接管;并且也能够绕过 Instagram 的双重身份验证 (2FA) 机制,实现账户接管。 技术细节 该漏洞存在的原因是在

<meta name=“robots“ content=““>介绍
是一个 HTML 元素,用于指示搜索引擎爬虫(如 Googlebot)如何处理网页的索引和抓取。它可以控制搜索引擎对页面的访问和索引行为。 content 属性可以包含以下指令: index:允许搜索引擎索引该页面(默认行为)。noindex:不允许搜索引擎索引该页面。follow:允许搜索引擎跟踪页面上的链接(默认行为)。nofollow:不允许搜索引擎跟踪页面上的链接。 例如: <m
one model / ensemble method /meta-algorithm 迁移学习算不算ensemble method
鉴于object detection COCO数据集的论文经常出现 single-model 也就是说,这是一个对网络的分类,呢它是什么意思,有什么特点。相对应的另一类是什么。就是下面介绍的ensemble learning。 不过比如说网络初值是用别人的网络训练好的数值,一定意义来讲是在优化空间找到一个初值,对于自己网络的结果的影响究竟有多大,也就是说,用随机初始网络得到的结果是否有不同,有多
与扎克伯格Meta同赛道,NFTBomb打造NFT协议生态
2021年,元宇宙的概念火爆全球。 事实上,在如今这个信息爆炸的时代,时时都有新概念,新名词诞生:Z时代,二次元,XR世界…诸如此类种种,刺激着人们的感官和内心。而元宇宙,作为其中的“现象级概念”,一出现便自带光环,成功破圈。 而就在2021年10月29日,Facebook CEO马克.扎克伯格正式宣布,要将公司更名为“Meta”,取自于Metaverse(元宇宙),是元的意思。而这,也恰恰彰

优化数据以提升大模型RAG性能思路:Meta Knowledge for RAG的一个实现思路
传统的RAG系统通过检索然后阅读框架来增强LLMs,但存在一些挑战,如知识库文档的噪声、缺乏人工标注信息、长文档的编码问题以及用户查询的模糊性。 因此可以采用数据为中心的增强方法,我们可以看看最近的一个工作。 一、Meta Knowledge for RAG 最近的工作,《Meta Knowledge for Retrieval Augmented Large Language Models

One-Shot Visual Imitation Learning via Meta-Learning
发表时间:CoRL 2017 论文链接:https://readpaper.com/pdf-annotate/note?pdfId=4667206488817680385¬eId=2408726470680795136 作者单位:University of California, Berkeley Motivation:为了使机器人成为可以执行广泛工作的通才,它必须能够在复杂的非结构化

andorid 配置文件中的meta—data的用法
<meta-data android:name="string" android:resource="resource specification" android:value="string" /> 这是该元素的基本结构.可以包含在 <activity> <activity-alias> <service> <receive

语言图像模型大一统!Meta将Transformer和Diffusion融合,多模态AI王者登场
【导读】 就在刚刚,Meta最新发布的Transfusion,能够训练生成文本和图像的统一模型了!完美融合Transformer和扩散领域之后,语言模型和图像大一统,又近了一步。也就是说,真正的多模态AI模型,可能很快就要来了! Transformer和Diffusion,终于有了一次出色的融合。 自此,语言模型和图像生成大一统的时代,也就不远了! 这背后,正是Meta最近发布的Tran
HTML5 meta 的使用
<!DOCTYPE html><!-- 使用 HTML5 doctype,不区分大小写 --><html lang="zh-cmn-Hans"><!-- 更加标准的 lang 属性写法 http://zhi.hu/XyIa --><head> <!-- 声明文档使用的字符编码 --> <meta charset='utf-8'> <!-- 优先使用 IE 最新版本和 Ch
html 头文件 meta的使用
meta是用来在HTML文档中模拟HTTP协议的响应头报文。meta 标签用于网页的<head>与</head>中,meta 标签的用处很多。meta 的属性有两种:name和http-equiv。name属性主要用于描述网页,对应于content(网页内容),以便于搜索引擎机器人查找、分类(目前几乎所有的搜索引擎都使用网上机器人自动查找meta值来给网页分类)。这其中最重要的是descripti
UPROPERTY(meta = (BindWidget))的含义
UPROPERTY 中的 meta = (BindWidget) 标记的作用是将 C++ 类中的变量(widget成员变量)与蓝图中的UI 元素(widget元素)进行绑定(例如 Button、TextBlock 等)。 这个标记主要在 UUserWidget 的子类中使用,用于确保在蓝图中创建的控件能够在 C++ 中直接访问和操作,即实现二者相互绑定。 BindWidget 的作用 绑定蓝
AS Duplicate files copied in APK META-INF/DEPE
错误: Error:Execution failed for task ':k-9:transformResourcesWithMergeJavaResForRelease'. > com.android.build.api.transform.TransformException: com.android.builder.packaging.DuplicateFileException: Du

Unity Meta Quest 开发:关闭 MR 应用的安全边界
社区链接: SpatialXR社区:完整课程、项目下载、项目孵化宣发、答疑、投融资、专属圈子 📕教程说明 这期教程我将介绍如何在应用中关闭 Quest 系统的安全边界。 视频讲解: https://www.bilibili.com/video/BV1Gm42157Zi 在 Unity 中导入 Meta XR SDK,进行环境配置后,打开 Assets > Plugins > An
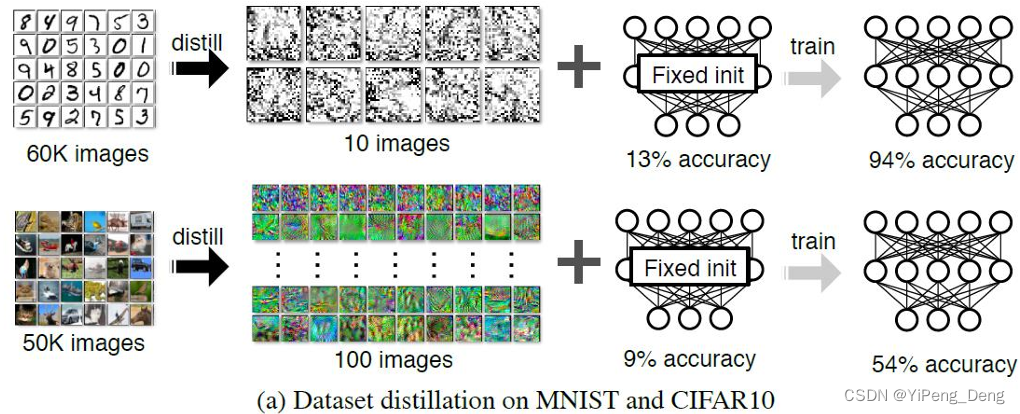
【Deep Learning】Meta-Learning:训练训练神经网络的神经网络
元学习:训练训练神经网络的神经网络 本文基于清华大学《深度学习》第12节《Beyond Supervised Learning》的内容撰写,既是课堂笔记,亦是作者的一些理解。 1 Meta-Learning 在经典监督学习中,给定训练数据 { ( x i , y i ) } i \{(x_i,y_i)\}_i {(xi,yi)}i,我们需要训练一个神经网络 f f f使得 f (
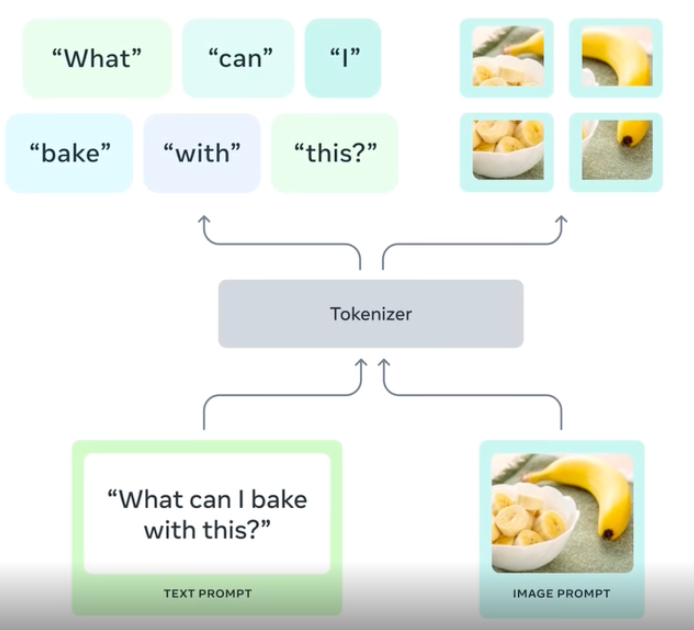
Meta FAIR研究新成果:图像到文本、文本到音乐的生成模型,多标记预测模型以及AI生成语音检测技术
Meta AI研究实验室(FAIR)公开发布了多项新研究成果,包括图像到文本和文本到音乐的生成模型,多词预测模型,以及检测AI生成语音的技术。发布的成果体现了开放性、协作、卓越和规模化等核心原则。公开早期研究工作旨在激发迭代,推动AI负责任发展。 Meta Chameleon系列模型可将文本和图像作为输入,输出任意文本和图像组合。已发布7B和34B模型的关键组件。 发布多词预测预训练
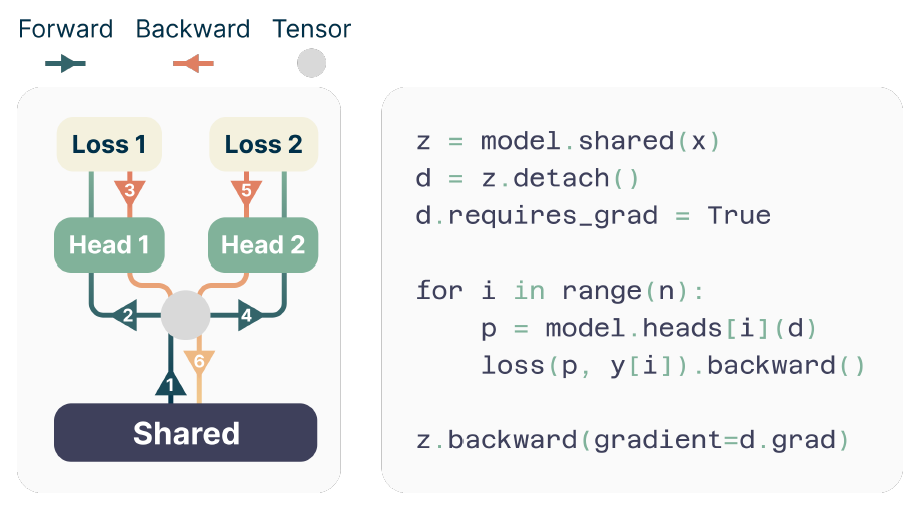
Meta悄咪咪的发布多款AI新模型
大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。 Meta 的基础 AI 研究 (FAIR) 团队发布了一些最新的AI

前 OpenAI 首席科学家建「安全超级智能」实验室;Meta 重组元宇宙团队丨 RTE 开发者日报 Vol.228
开发者朋友们大家好: 这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的新闻」、「有态度的观点」、「有意思的数据」、「有思考的文章」、「有看点的会议」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。 本期编辑:@CY,@JLT,@鲍勃 一、有话题的新闻 1、OpenA

【报告分享】家电及3C产品出海白皮书-Meta(附下载)
摘要:报告对中国消费电子产品所面向的全球市场环境进行了系统性的梳理,包括全球的市场规模与结构,主要 国家地区的消费者特点与偏好等关键内容。同时也对家居电子产品、相机及拍摄类产品、可穿戴电子设备这 三大核心品类的发展现状展开了进一步研究。其中,家居电子产品坐拥当前最广阔的消费市场,而新型拍摄 类产品与可穿戴电子设备将成为未来最重要的增长势力。在出海目的地方面,北美与欧洲仍是目前最成熟的 主要市场
转 【「meta name=“description“ content=“」】作用讲解
今天在看别人写的网站代码,发现类似<meta name="Keywords" content="" >、<meta name="Description" content="" >这样的写法,不知道具体代表什么意思,于是上网搜了一下,下面是在网上找到的详细解释。 一、语法: <meta name="name" content="string"> 二、参数解析: 1)name项:常用的选项有Keyw
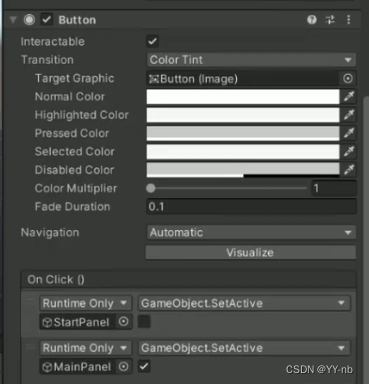
Unity Meta Quest 开发:与 Unity 的 UI 系统进行交互
文章目录 📕教程说明📕教程内容概括📕添加玩家物体📕添加 Canvas 物体和 EventSystem 物体📕修改 Canvas 组件的 Render Mode📕在 Canvas 上搭建 UI 面板📕利用 Interaction SDK 的 Quick Action 快速配置交互功能📕按钮点击事件 此教程相关的详细教案,文档,思维导图和工程文件会放入 Spatial
脑机接口,Meta裁50+高管,大模型文本压缩处理,大模型与推荐系统,Luma AI视频工具亮相
更多内容: https://agifun.love 智源社区 北京线下:基于脑机接口的视觉重建前沿进展丨周六直播·脑机接口读书会 导语 人类70%以上的感知是通过视觉完成的,且有超过1/3的脑组织参与视觉相关的信息处理,因此视觉是极其重要的感知功能。由于外伤和先天后天的疾病造成的视觉损失严重的影响了人们的生存质量,且其中相当一部分疾病和外伤是无法通过眼科矫正或眼科手术来进行恢