本文主要是介绍RDMA over Ethernet用于Meta规模的分布式AI训练,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要:
近年来,AI模型的计算密度和规模迅速增长,推动了构建高效可靠专用网络基础设施的需求。本文介绍了Meta公司基于RDMA over Converged Ethernet(RoCE)的分布式AI训练网络的设计、实施和运营。
我们的设计原则涉及对工作负载的深入理解,并将这些见解转化为各种网络组件的设计:网络拓扑 - 为支持AI硬件平台的世代快速演进,我们将基于GPU的训练分离到专门的"后端"网络。路由 - 训练工作负载本身会造成负载不平衡和突发性,因此我们部署了路由方案的多个迭代以实现近乎最优的流量分配。传输 - 我们概述了最初尝试使用DCQCN进行拥塞管理,但后来改用集合通信库本身来管理拥塞。运营 - 我们分享了在大规模AI网络运营方面的经验,包括我们开发的工具和故障排查案例。
1. 引言
人工智能(AI)在图像识别、自然语言处理和推荐系统等领域的普及引入了新的通信需求时代。特别是分布式训练,对数据中心网络基础设施施加了最大的压力。例如,一个典型的生成式AI任务可能需要在数周内紧密协调数千个GPU。构建能够满足这一日益增长需求的可靠、高性能的网络基础设施,需要重新评估数据中心网络设计。
分布式训练中的GPU间通信通常包括两个阶段。在每个容纳4-8个GPU的训练节点中,这些GPU使用NVLink[26]等高速传输互连,通常称为"节点内通信"。当训练任务需要额外的GPU时,"节点间通信"将通过网络进行。业界通常采用两种设计方法进行此节点间通信。一种利用标准TCP/IP或改进的socket实现(如fastsocket[7])。然而,由于CPU开销和延迟增加,这种方法容易导致性能下降。第二种设计方法涉及专有互连,如InfiniBand[23]、NVSwitch[26]、Elastic Fabric Adaptor[2]和Inter-rack ICI[8]。虽然这些方法可显著提高性能,但其专有特性限制了部署灵活性。
当Meta引入基于GPU的分布式训练时,我们决定为这些GPU集群构建专门的数据中心网络。我们选择RoCE[11]作为节点间通信传输。选择RoCE的原因如下:
-
RoCE遵循已建立的RDMA verbs语义,这为训练工作负载社区所熟知。这确保了现有训练应用程序的无缝过渡,并便于开发新应用程序。
-
通过利用以太网,我们可以采用现有数据中心设计组件和工具的很大一部分。这使我们能够使用基本一致的Clos网络设计构建网络,并通过重用现有工具简化运营。
-
整个技术栈都基于开放标准,并得到多个供应商的支持,确保了我们网络基础设施的兼容性和灵活性。
我们积累了设计和运营RoCE网络的丰富经验,总结如下:
专用后端网络:我们专门为分布式训练构建了专用后端网络。这使我们能够独立于其余数据中心网络进行演进、运营和扩展。为支持大型语言模型(LLM),我们将后端网络扩展到数据中心规模,例如将拓扑感知集成到训练任务调度器中。
路由方案演进:鉴于默认ECMP(等成本多路径)路由及其替代方案在我们早期阶段的性能不佳,我们部署了中心化流量工程和增强型ECMP方案的组合,以实现训练工作负载的最优负载分配。
集合通信的拥塞控制:我们发现在RoCE部署中调整主流拥塞控制方案DCQCN以显著提高分布式训练任务的集合通信完成时间非常具有挑战性。相反,我们设计了一种通过集合通信库进行接收方驱动的流量准入,以实现卓越的性能。这涉及协同调整集合通信库配置和底层网络配置,以实现最佳性能。
我们成功扩展了RoCE网络,从原型演进到部署多个集群,每个集群容纳数千个GPU。这些RoCE集群支持广泛的生产分布式GPU训练任务,包括排序、内容推荐、内容理解、自然语言处理、生成式AI模型训练等工作负载。我们此前分享了支持多达32,000个GPU的RoCE集群的高层设计。[18]
尽管RoCE此前一直是网络研究的主题[3,6,9,19],但其主要应用历来是存储网络。很少有文献论述RoCE在大规模AI训练场景中的部署。本文深入探讨了在每个集群中将RoCE网络扩展到互连数千个GPU的细节。我们的经验表明,通过很好地理解工作负载并仔细设计网络的每个组件,包括拓扑、路由、传输和运营工作流,RoCE可以支持大规模AI训练。
本工作不涉及任何伦理问题。
2. 背景
2.1 分布式模型训练
通过将模型和/或输入数据分片到多个GPU,使用各种并行策略来扩展分布式训练。典型的训练过程涉及重复训练迭代。每次迭代包括前向传递以生成损失,反向传递以计算梯度,以及优化器步骤以更新参数。涉及的GPU需要在每次迭代中多次同步梯度或更新的参数。这个同步过程需要在几毫秒内在GPU之间传输大量数据,并在多次迭代中重复,直到模型收敛。这需要能够提供高带宽和低延迟、可预测延迟的网络。
2.2 RoCE和集合通信
RDMA 是一种硬件辅助通信加速的行业标准。RDMA 实现了"verbs"API,如读取和写入。与基于TCP/IP的通信相比,在基于TCP/IP的通信中,数据包需要在复制到内存之前发送到内核,而RDMA绕过发送方和接收方的内核,直接从/向应用程序内存传输数据。RoCEv2是一个实现RDMA的协议:RDMA verbs消息被封装在以太网/IPv6/UDP数据包中,并通过常规以太网网络传输。封装/解封是在RDMA NIC硬件中处理的。
集合通信库充当训练工作负载和NIC之间的软件抽象层,通过verbs API进行接口。它将collectives 1(例如AllReduce)转换为逻辑拓扑实现(例如Ring或Tree),并进一步将其分解为使用verbs调度GPU之间的点对点数据事务。为实现最佳性能,这些事务需要GPU到RDMA NIC支持。例如,NCCL[25]使用RDMA写入操作实现所有集合算法和点对点语义。每个GPU到GPU的成对事务可以通过多个通道,每个NIC到NIC的成对事务可以通过多个队列对(QP)。
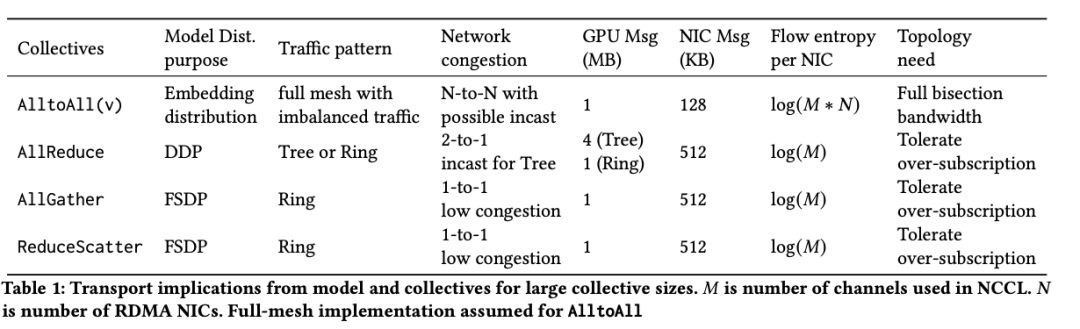
表1提供了用于分布式训练的主要collectives的特性以及每个collective的具体要求。首先,collective由并行策略确定。例如,分布式数据并行(DDP)[14]使用AllReduce,全分片数据并行(FSDP)[41]使用AllGather和ReduceScatter。排名模型(如DLRM[21]) 使用AlltoAllv(一种矢量化的AlltoAll)来分发用于模型并行的嵌入。
其次,collectives会产生各种网络流量模式。例如,AlltoAllv在所有端点之间形成全网状流量模式,可能导致高临时拥塞。然而,其大量活跃流简化了路由,降低了使用哈希方案的持续拥塞风险。
第三,collective操作的逻辑拓扑选择会影响网络拥塞和GPU之间的数据交换。例如,作为Ring与Tree实现的AllReduce在拥塞和哈希碰撞方面有独特的影响。NCCL根据GPU数量和消息大小等因素优化具体选择。但是,这种方法有局限性,包括由于硬编码配置文件导致的潜在不准确性,在某些消息大小或大规模作业下的次优性能,以及在某些实现中collective算法的无关性。
2.3 训练工作负载
为了了解生产中实际观察到的集合通信,我们利用Chakra [33]收集了2023年第四季度约30K个随机选择的训练作业的集合统计信息。
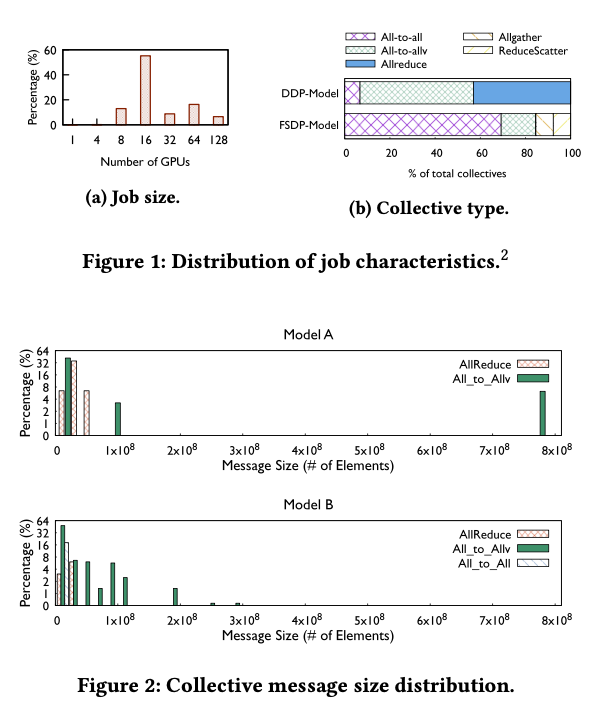
图1a显示了我们收集的作业规模分布。值得注意的是,我们在分析中不包括超过128个GPU作业的长尾,因此排除了LLM作业。然而,我们在下面指出,由于多维并行性,对多达128个GPU的作业规模进行分析对大型LLM作业仍然具有高度相关性。该分布表明,大多数作业规模是8的倍数。这是因为我们将8个GPU安装到每台主机上,不推荐部分主机利用率。为了展示不同模型使用的集合体的多样性,我们按类型细分集合体。如图1b所示,AllReduce和AlltoAll(v)在基于DDP的模型中占主导地位,而AllGather和ReduceScatter是FSDP中的基本集合体。消息大小是在集合通信操作中传输的数据元素量。我们选择两个不同的模型,观察到消息大小分布差异很大(如图2所示)。不同模型传输的数据量和流量模式也各不相同。这促使我们在以下部分中解释路由和传输选择。
作业规模趋势:在撰写本文时,排序模型的规模大致在8-256个GPU左右。展望未来,更大的GPU作业正变得越来越普遍,它们消耗的GPU小时数正逐渐上升。这是由于排序模型的模型规模呈上升趋势,而且对于LLM,这种趋势更加明显。例如,Llama3的一个大型变体在我们24,000个GPU的RoCE集群上使用了16,000个GPU进行训练。[18]
每个collective的GPU数量趋势:无论是排序作业还是LLM,每个collective操作的GPU数量并没有以与作业规模相同的速度扩展。这是由于在部署大型模型时使用了多维并行性。即使运行涉及数万个GPU的作业,这也有助于将最大的collective中的GPU数量限制在数百个。出于这个原因,在本文的其余部分,我们专注于涉及16-128个GPU大小范围的collective操作。
2.4 挑战
在为分布式AI训练需求构建RoCE网络时,我们面临几个挑战。
训练模型的快速演进:训练模型的快速演进需要将网络带宽提高到400Gbps及以上,并将规模扩展到数万个GPU。虽然早期的排序作业规模目前还不大,但众所周知,LLM训练同时占用数万个加速器[8],排序作业也在增长[39]。在这种规模下构建网络,同时保持GPU间通信的高性能,是一个巨大的挑战(第3节)。

流量模式的低熵:如表2所示,分布式训练中的流量模式在UDP 5元组中表现出低熵。这是第 2.2 节中讨论的集合通信的结果。通常,一个GPU仅被一个训练作业占用,其逻辑拓扑通常是稀疏的。这导致在路由中均匀分配流量以实现最佳性能方面存在重大挑战(第4节)。
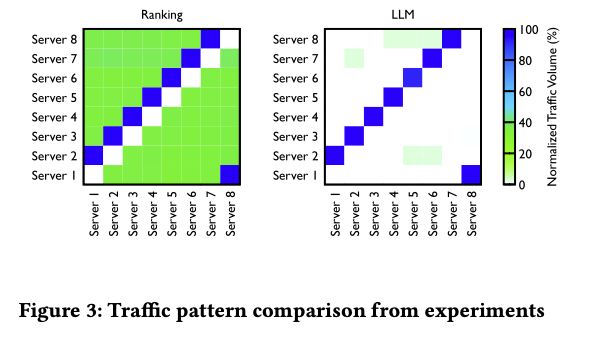
不同级别的网络拥塞:分布式训练产生独特的全网格和分层流量模式(如 Ring 或 Tree),它们都会产生不同模式的拥塞,如表2中的缓冲区占用情况所示。这些流量模式可以在图3中看到。对于以前的 RDMA 部署,没有标准的最佳实践来处理这种流量模式的拥塞(第5节)。
协同调优的需求:集合通信库,如NCCL,可能由于开发人员环境与生产环境的差异而无法与RoCE互连实现开箱即用的最佳性能。这需要协同调优集合通信库和网络配置,以实现最佳性能(第6节)。低熵流量模式可能导致少数网络路径比其他路径承载更多流量,从而在这些路径上产生持续拥塞。此外,即使完美分配流量,AlltoAll等集合通信流量模式也会产生微突发。虽然这两种模式都可能对性能产生负面影响,但这两个问题的确切表现形式和解决方法是不同的。因此,我们在(第4节)中介绍了前一个问题的解决方案,在(第5节)中介绍了后一个问题的解决方案。
3. 硬件
在本节中,我们介绍了用于训练节点和网络的硬件,为运行在其上的软件系统奠定基础。
3.1 训练节点
训练模型和数据集规模的增加使得将训练过程限制在单个GPU中变得不可行。它还需要增加计算和内存,给网络带来了巨大需求,因此需要专门设计的扩展系统。
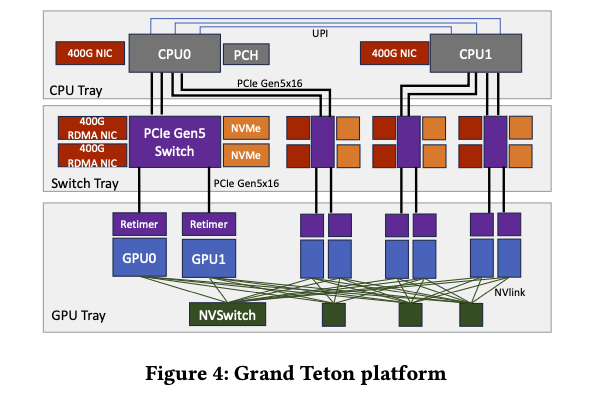
训练节点设计的第一代ZionEX[20]将通用CPU与NVIDIA A100 GPU结合在一起。Grand Teton[17]是更新的一代,基于H100 GPU。除了GPU NVLink互连之外,ZionEX和Grand Teton都使用类似的系统架构。图4描述了Grand Teton的内部结构。该节点分为3个托盘–CPU托盘容纳2个CPU和前端NIC,交换机托盘容纳4个PCIe Gen5交换机、NVMe存储以及8个RDMA NIC,GPU托盘容纳8个GPU。GPU使用NVSwitch[26]完全连接。GPU和NIC之间存在1:1映射。对于使用少于8个GPU的训练作业,GPU在节点内相互通信而无需网络操作。对于更大的作业,RDMA NIC支持GPUDirect技术,因此GPU到GPU流量可以绕过主机和主机内存瓶颈。
3.2 网络
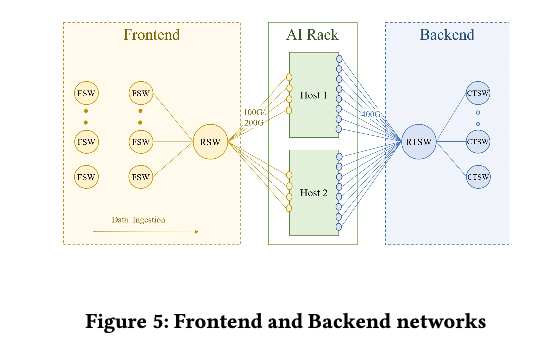
训练集群依赖两个独立的网络:前端网络(FE)用于数据摄取、检查点和日志记录等任务,后端网络(BE)用于训练,如图5所示。
前端网络:训练机架连接到数据中心网络的FE和BE。FE有一个网络层次结构[1]–机架交换机(RSW)、结构交换机(FSW)和更高层次–容纳存储仓库,为GPU提供训练工作负载所需的输入数据。我们确保机架交换机上有足够的入口带宽,以免阻碍训练工作负载。
后端网络:BE是一个专门的结构,以非阻塞架构连接所有RDMA NIC,在集群中任意两个GPU之间提供高带宽、低延迟和无损传输,而不管它们的物理位置如何。该后端结构使用RoCEv2协议,该协议将RDMA服务封装在UDP包中,以便通过网络进行传输。
3.3 演进
我们的BE网络经历了几次转变。最初,我们的GPU集群使用简单的星型拓扑,几个AI机架通过一个中央以太网交换机连接。运行不可路由的RoCEv1协议。这种设置在GPU规模和交换机冗余方面有明显的局限性。因此,我们迅速过渡到基于结构的架构,以实现更好的可扩展性和更高的可用性。
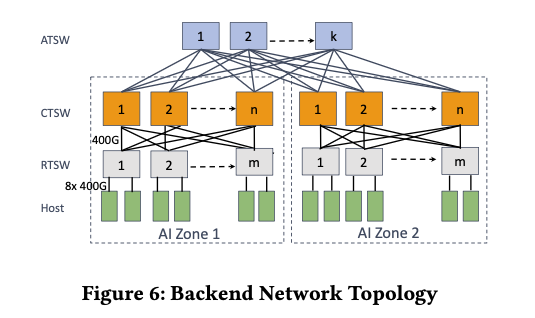
AI区:我们为AI机架设计了两级Clos拓扑,称为AI区,如图6所示。用作叶交换机的机架训练交换机(RTSW)使用基于铜缆的DAC电缆为机架内的GPU提供扩展连接。主干层由模块化集群训练交换机(CTSW)组成,在集群中所有机架之间提供横向扩展连接。CTSW在机箱中的端口上具有静态划分的深缓冲区。RTSW通过单模光纤和400G可插拔收发器连接到CTSW。
数据中心规模和拓扑感知调度:AI区旨在以非阻塞方式支持大量互连GPU。然而,LLM等新兴AI进展需要比单个AI区提供的更大的GPU规模。为了适应这一点,我们设计了一个聚合器训练交换机(ATSW)层,将数据中心大楼中的CTSW连接起来,将RoCE域扩展到单个AI区之外。请注意,按照设计,跨AI区连接是过度订阅的,网络流量使用ECMP进行平衡。为了缓解跨AI区流量的性能瓶颈,我们增强了训练作业调度器,以便在将训练节点划分为不同AI区时找到"最小割",从而减少跨AI区流量,进而缩短集合通信完成时间。调度器通过学习GPU服务器在逻辑拓扑中的位置来推荐秩分配。
3.4 讨论
在部署RoCE时,前端网络和后端网络的分离是一个早期的重大设计决策。这主要是由于我们预计这两个网络将独立演进。此外,分离AI训练流量简化并加速了路由和传输设计迭代,因为这两个网络承载的流量具有非常不同且经常相互冲突的要求。最后,物理分离确保了对延迟敏感的RoCE操作的理想网络环境。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

这篇关于RDMA over Ethernet用于Meta规模的分布式AI训练的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





