rdma专题

配置InfiniBand (IB) 和 RDMA over Converged Ethernet (RoCE) 网络
配置InfiniBand (IB) 和 RDMA over Converged Ethernet (RoCE) 网络 服务器端配置 在服务器端,你需要确保安装了必要的驱动程序和软件包,并且正确配置了网络接口。 安装 OFED 首先,安装 Open Fabrics Enterprise Distribution (OFED),它包含了 InfiniBand 所需的驱动程序和库。 sudo

InfiniBand (IB) 和 RDMA over Converged Ethernet (RoCE)
在超算网络环境中,InfiniBand (IB) 和 RDMA over Converged Ethernet (RoCE) 是两种重要的网络技术,它们旨在提供高性能、低延迟的数据传输能力,适用于大规模并行计算任务。下面是对这两个技术的具体名词解释和应用场景的详细说明。 InfiniBand (IB) 名词解释 InfiniBand (IB):InfiniBand 是一种高性能计算和企业数据


RDMA over Ethernet用于Meta规模的分布式AI训练
摘要: 近年来,AI模型的计算密度和规模迅速增长,推动了构建高效可靠专用网络基础设施的需求。本文介绍了Meta公司基于RDMA over Converged Ethernet(RoCE)的分布式AI训练网络的设计、实施和运营。 我们的设计原则涉及对工作负载的深入理解,并将这些见解转化为各种网络组件的设计:网络拓扑 - 为支持AI硬件平台的世代快速演进,我们将基于GPU的训练分离到专门的"后端"

RDMA技术详解——RDMA优缺点
1.1. RDMA的优势 传统的TCP/IP技术在数据包处理过程中,要经过操作系统及其他软件层,需要占用大量的服务器资源和内存总线带宽,数据在系统内存、处理器缓存和网络控制器缓存之间来回进行复制移动,给服务器的CPU和内存造成了沉重负担。尤其是网络带宽、处理器速度与内存带宽三者的严重"不匹配性",更加剧了网络延迟效应。 RDMA技术,最大的突破是将网络层和传输层

RDMA技术详解——RDMA的三种实现方式
RDMA作为一种host-offload, host-bypass技术,使低延迟、高带宽的直接的内存到内存的数据通信成为了可能。目前支持RDMA的网络协议有: 1、InfiniBand(IB): 从一开始就支持RDMA的新一代网络协议。由于这是一种新的网络技术,因此需要支持该技术的网卡和交换机。 2、RDMA过融合以太网(RoCE): 即RDMA over Ethernet, 允许通过以太网执

RDMA技术详解——DMA和RDMA概念
1.1 DMA DMA(Direct Memory Access,直接内存访问)是一种能力,允许在计算机主板上的设备直接把数据发送到内存中去,数据搬运不需要CPU的参与。如下图所示 红线部分为传统内存访问,需要通过CPU进行数据copy来移动数据,通过CPU将内存中的Buffer1移动到Buffer2中。在DMA模式:可以同DMA Engine之间通过硬件将数据从Buffe

基于RDMA的nfs服务
背景 ib网卡+nfs服务实现简单的存储共享,暂时顶替还未上线的存储设备,同时也解决 单纯的使用scp rsync等不支持rdma协议拷贝无法正确使用ib网络 说明 前提是系统上已配置安装好ib网卡驱动,且ib网络正常使用,配置参考 https://blog.csdn.net/qq_43652666/article/details/141422514 大部分步骤网上都有,但是如何将RDMA
RDMA驱动学习(一)- 用户态到内核态的过程
最近梳理了一下rdma用户态到内核态传参的流程,会基于ibv_create_cq接口介绍一下ioctl版本的流程,代码基于mlnx-ofa_kernel-5.4。 用户态 用户态和内核态传的参数包含两部分,用户执行create_cq会传一些标准的参数,比如队列长度cqe,ibv_comp_channel channel等,还有另外厂商自己的参数,比如mlx5会传cq buffer的地址等。 用
k8s volcano + deepspeed多机训练 + RDMA ROCE+ 用户权限安全方案【建议收藏】
前提:nvidia、cuda、nvidia-fabricmanager等相关的组件已经在宿主机正确安装,如果没有安装可以参考我之前发的文章GPU A800 A100系列NVIDIA环境和PyTorch2.0基础环境配置【建议收藏】_a800多卡运行环境配置-CSDN博客文章浏览阅读1.1k次,点赞8次,收藏16次。Ant系列GPU支持 NvLink & NvSwitch,若您使用多GPU卡的机型,
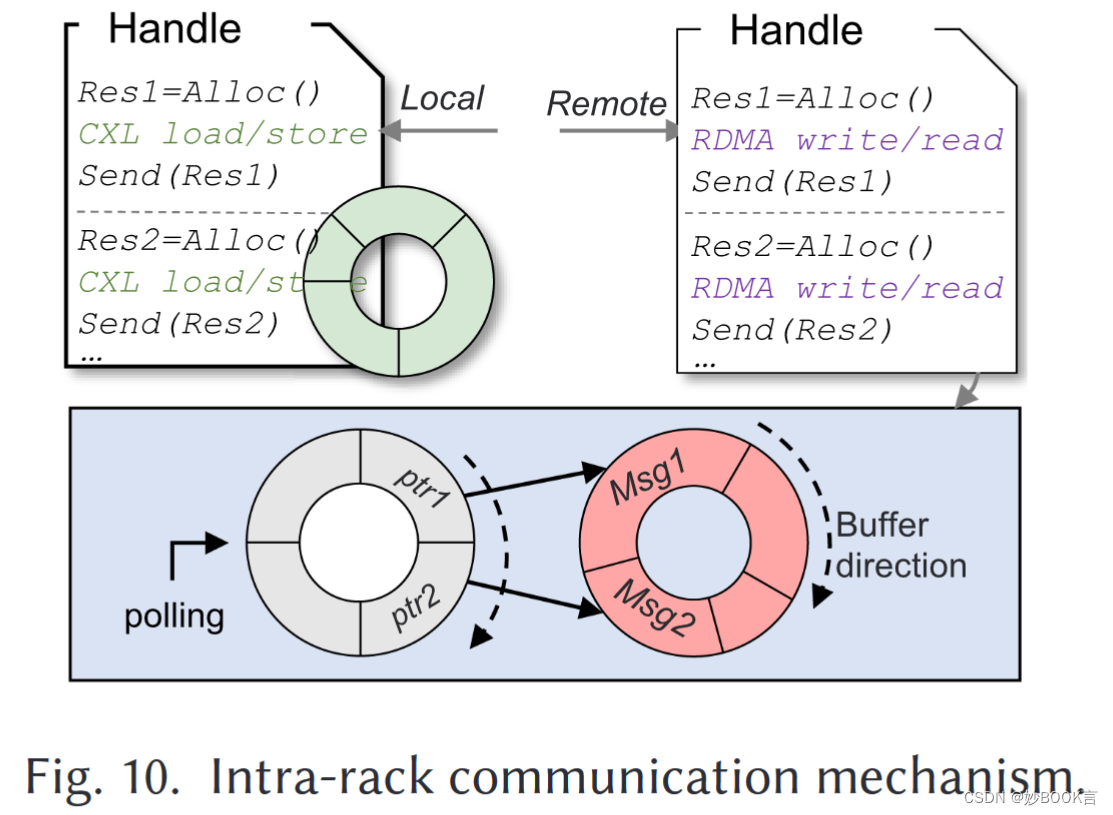
Rcmp: Reconstructing RDMA-Based Memory Disaggregation via CXL——论文阅读
TACO 2024 Paper CXL论文阅读笔记整理 背景 RDMA:RDMA是一系列协议,允许一台机器通过网络直接访问远程机器中的数据。RDMA协议通常固定在RDMA NIC(RNIC)上,具有高带宽(>10 GB/s)和微秒级延迟(~2μs),这些协议得到了InfiniBand、RoCE和OmniPath等公司的广泛支持[20, 47, 62]。RDMA基于两种类型的操作原语提供数据传输
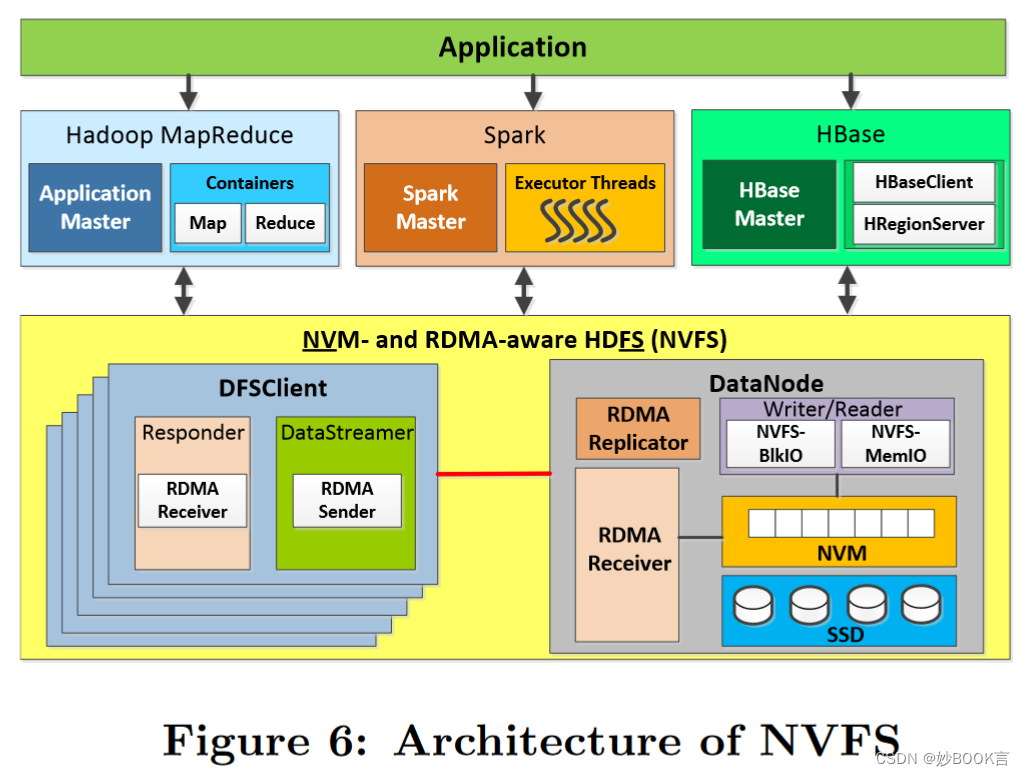
High Performance Design for HDFS with Byte-Addressability of NVM and RDMA——论文泛读
ICS 2016 Paper 分布式元数据论文阅读笔记整理 问题 非易失性存储器(NVM)提供字节寻址能力,具有类似DRAM的性能和持久性,提供了为数据密集型应用构建高通量存储系统的机会。HDFS(Hadoop分布式文件系统)是MapReduce、Spark和HBase的主要存储引擎。尽管HDFS最初是为商品硬件设计的,但它越来越多地被用于HPC(高性能计算)集群。HPC系统的性能要求使HDF

关于RDMA传输的基本流量控制
Basic flow control for RDMA transfers | The Geek in the Corner (wordpress.com) 文心一言 已经介绍了使用发送/接收操作和RDMA读写操作,那么现在是一个很好的机会来结合这两种方法的元素,并讨论一般的流量控制。还会稍微谈谈RDMA带有立即数据的写操作(IBV_WR_RDMA_WRITE_WITH_IMM),并且将通过一
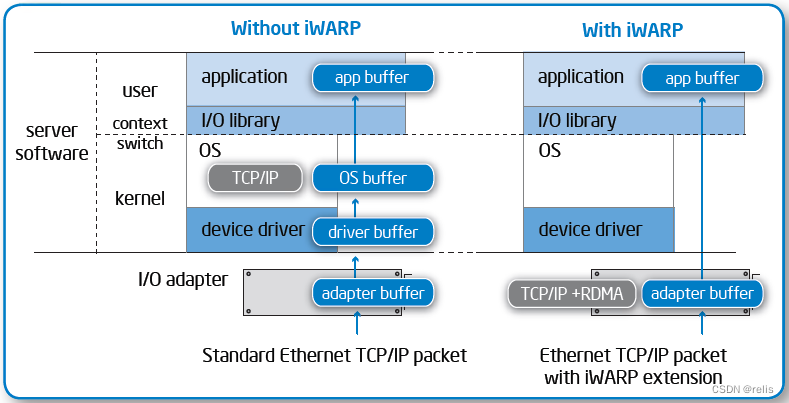

xdp、dpdk、rdma能在同一网卡上同时使用吗?
文心一言 XDP、DPDK和RDMA是三种不同的技术,它们各自在Linux网络性能优化中扮演了不同的角色。关于它们能否在同一网卡上同时使用,我们需要考虑以下几个方面: XDP(eXpress Data Path): XDP是Linux内核提供的高性能、可编程的网络数据包处理框架。它直接接管网卡的RX方向数据包,通过在内核运行eBPF指令来快速处理报文并无缝对接内核协议栈。XDP不是内核旁路,而
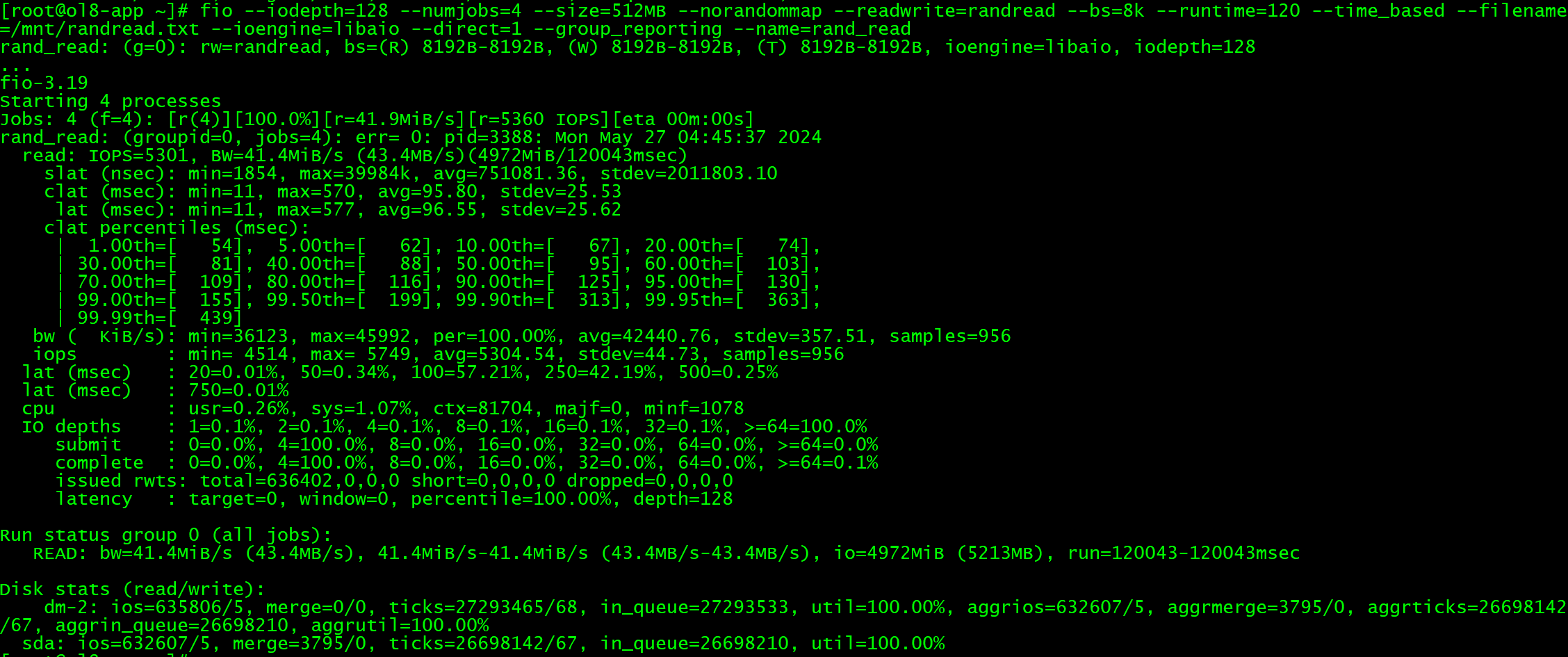
据库管理-第196期 实战RDMA(20240528)
数据库管理196期 2024-05-28 数据库管理-第196期 实战RDMA(20240528)1 环境2 操作系统配置3 配置NVMe over RDMA4 挂载磁盘处理并挂载磁盘: 5 RDMA性能测试6 iSCSI部署7 iSCSI性能测试8 性能对比总结 数据库管理-第196期 实战RDMA(20240528) 作者:胖头鱼的鱼缸(尹海文) Oracle ACE A

使用libibverbs构建RDMA应用
本文是对论文Dissecting a Small InfiniBand Application Using the Verbs API所做的中英文对照翻译 Dissecting a Small InfiniBand Application Using the Verbs API Gregory Kerr∗College of Computer and Informa

Glusterfs之rpc模块源码分析(下)之RDMA over TCP的协议栈工作过程浅析
http://blog.csdn.net/wanweiaiaqiang/article/details/7566779 第一节 RDMA概述 随着网络带宽和速度的发展和大数据量数据的迁移的需求,网络带宽增长速度远远高于处理网络流量时所必需的计算节点的能力和对内存带宽的需求,数据中心网络架构已经逐步成为计算和存储技术的发展的瓶颈,迫切需要采用一种更高效的数据通讯架构。
![[RDMA]重传(二)——导致重传的Error](https://img-blog.csdnimg.cn/9cafc55a6d2c4843a643f18e963c3662.png)
[RDMA]重传(二)——导致重传的Error
2 导致重传的Error 导致重传的Error主要有四类,如下表: Table a. Error Type ConditionDescription Local Ack Timeout Error 对端Ack丢失或回复过慢而超时,本端重传,产生重复包本端Req在传输网络中阻塞而超时,本端重传,对端对重传包回复Ack后,第一次Req才被对端收到,产生重复包(ghost packet) 本端
k8s infiniband 和 RoCE(RDMA over Converged Ethernet)
1. 部署 Mellanox/k8s-rdma-shared-dev-plugin 说明:文中用到的镜像是自定义的,文末有其Dockerfile 文件。 克隆代码 git clone https://github.com/Mellanox/k8s-rdma-shared-dev-plugin.git 查看网卡的 vendors 查看 网卡的bdf lspci |grep -i mell
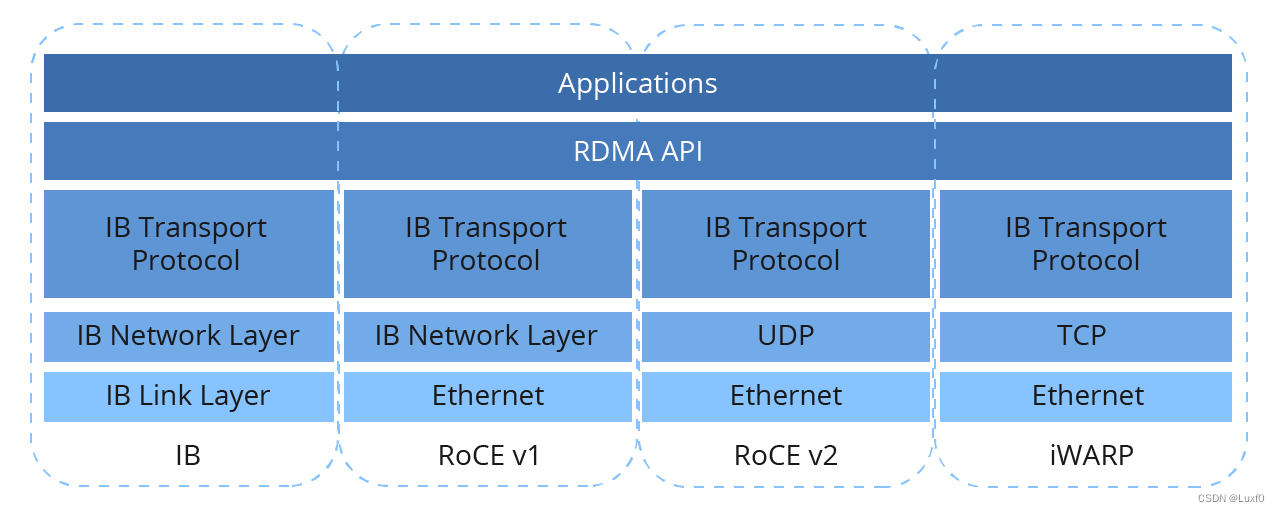
【硬件相关】RDMA网络类别及基础介绍
文章目录 一、前言1、RDMA网络协议2、TCP/IP网络协议 二、RDMA类别1、IB2、RoCE3、iWARP 三、RDMA对比1、优缺点说明a、性能b、扩展性c、维护难度 2、总结说明 一、前言 roce-vs-infiniband-vs-tcp-ip RoCE、IB和TCP等网络的基本知识及差异对比 分布式存储常见网络协议有TCP/IP和RDMA两种,传统TC

一文读懂GPU通信互联技术:到底什么是GPUDirect、NVLink、RDMA?
大家过年好哈,我是老猫,猫头鹰的猫。 在之前的文章中,我们详细介绍过PCIe、RDMA、NVlink、CXL等互联技术。 但很多小伙伴在后台留言,想让我更系统的介绍GPU的通信互联技术,毕竟单篇技术的介绍,并不能让大家对GPU互联技术有一个系统全面的了解。 所以,今天我们就通过这篇文章来详细的介绍下GPU通信互联技术。 为什么需要GPU互联技术? 我们都知道,在GPU未出现前,C
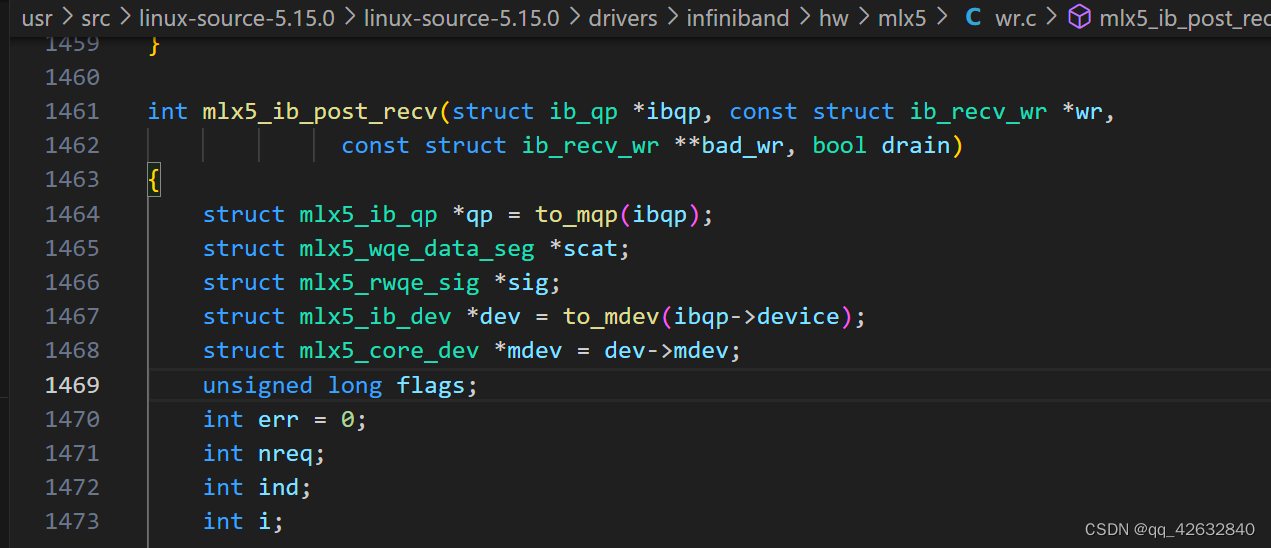
RDMA内核态函数ib_post_recv()源码分析
接上文,上文分析了内核rdma向发送队列添加发送请求的函数ib_post_send,本文分析一下向接收队列添加接收请求的函数ib_post_recv。其实函数调用流程与上文类似,不再重复说明,可参考链接。 函数调用过程 最终会调用到这个函数 下面是这个函数的完整代码 int mlx5_ib_post_recv(struct ib_qp *ibqp, const struct ib_recv_
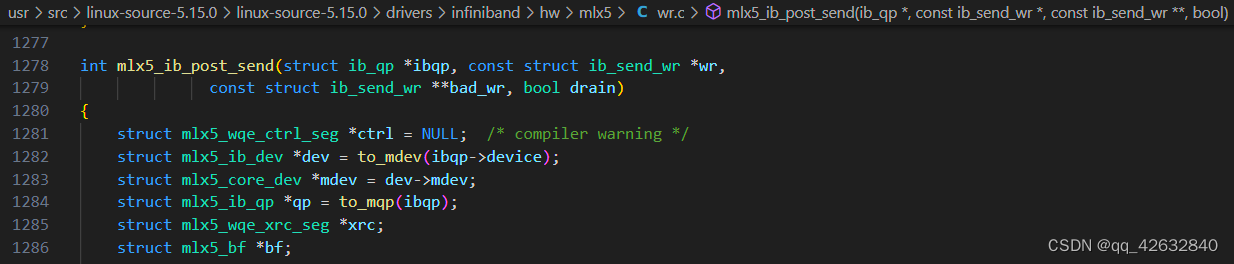
RDMA内核态函数ib_post_send()源码分析
最近调用linux内核下RDMA的Verb API ib_post_send()出现了问题,因此从源码分析一下这个函数的调用过程。 我使用的内核版本为5.15.0-94 这是函数ib_post_send的头文件定义,这个函数的意义是向发送队列提交发送请求,他会调用qp对应设备的post_send操作 post_send是一个函数指针 post_send函数的具体实现在infiniband驱动程

【RDMA】低时延网络实践---百度高级项目|PFC+ECN
目录 一、数据中心诉求变化 二、网络时延组成 三、降低时延工作重点 1、主机端的加速 2、网络侧流控技术 PFC 和 ECN 低时延网络解决方案 四、对未来的技术展望 1、四个方面进行深度的优化 原文:https://www.sohu.com/a/190664909_210640 配合这个PDF阅读:https://mentor.ieee.org/802.1/dcn
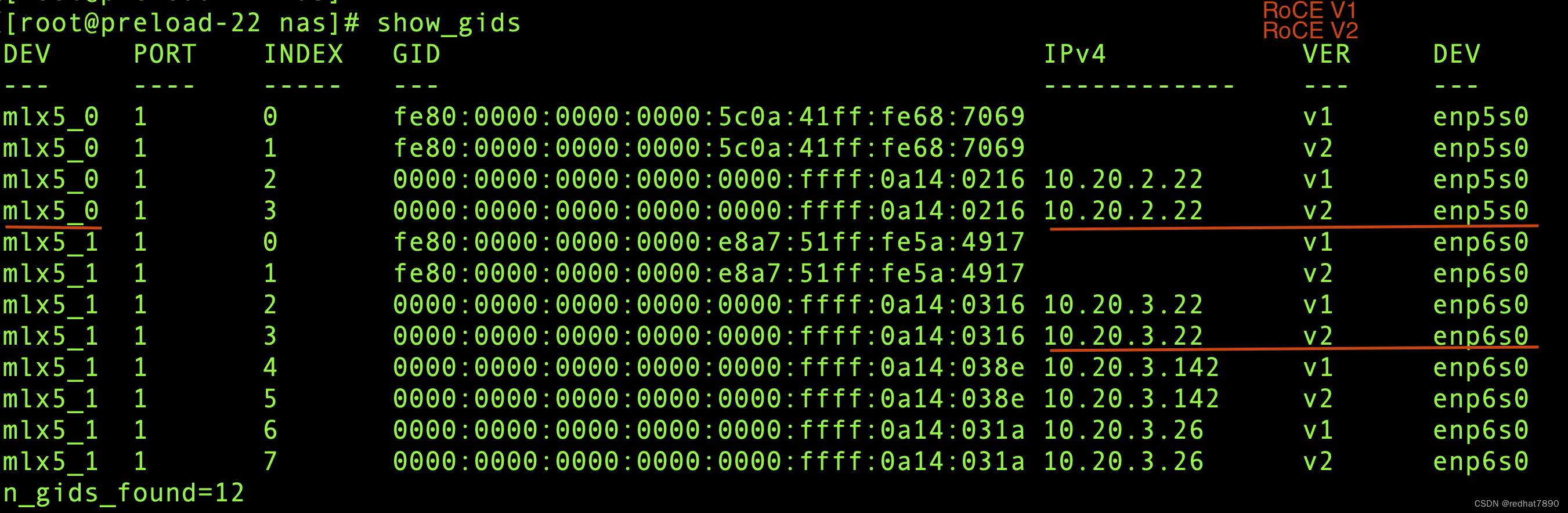
RDMA vs InfiniBand 网卡接口如何区分?
(该架构图来源于参考文献) 高性能计算网络,RoCE vs. InfiniBand该怎么选? 新 RoCEv2 标准可实现 RDMA 路由在第三层以太网网络中的传输。RoCEv2 规范将用以太网链路层上的 IP 报头和 UDP 报头替代 InfiniBand 网络层。这样,就可以在基于 IP 的传统路由器之间路由 RoCE。 RoCE v1协议:基于以太网承载 RDMA,只能部