本文主要是介绍High Performance Design for HDFS with Byte-Addressability of NVM and RDMA——论文泛读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ICS 2016 Paper 分布式元数据论文阅读笔记整理
问题
非易失性存储器(NVM)提供字节寻址能力,具有类似DRAM的性能和持久性,提供了为数据密集型应用构建高通量存储系统的机会。HDFS(Hadoop分布式文件系统)是MapReduce、Spark和HBase的主要存储引擎。尽管HDFS最初是为商品硬件设计的,但它越来越多地被用于HPC(高性能计算)集群。HPC系统的性能要求使HDFS的I/O瓶颈成为重新思考其NVM存储体系结构的关键问题。
挑战
内存存储正越来越多地用于HPC系统上的HDFS[3,20],但使用这些内存进行存储可能会导致计算性能下降,原因是计算和I/O之间对物理内存的竞争。研究[3,20,27]提出了内存中的数据放置策略,以提高写入吞吐量。但是内存中的数据放置使得持久性任务具有挑战性。NVM不仅可以增加整体内存容量,还可以提供持久性,同时显著提高性能。
-
将NVM用于HDFS的替代技术有哪些?
-
HDFS中基于RDMA的通信能否在HPC系统上利用NVM?
-
如何重新设计HDFS以充分利用NVM的字节寻址能力来提高I/O性能?
-
能否为Spark和HBase提出先进、经济高效的加速技术,以在HDFS中利用NVM?基于NVM的HDFS是否也可以用作突发缓冲层,用于在Lustre等并行文件系统上运行Spark作业?
本文方法
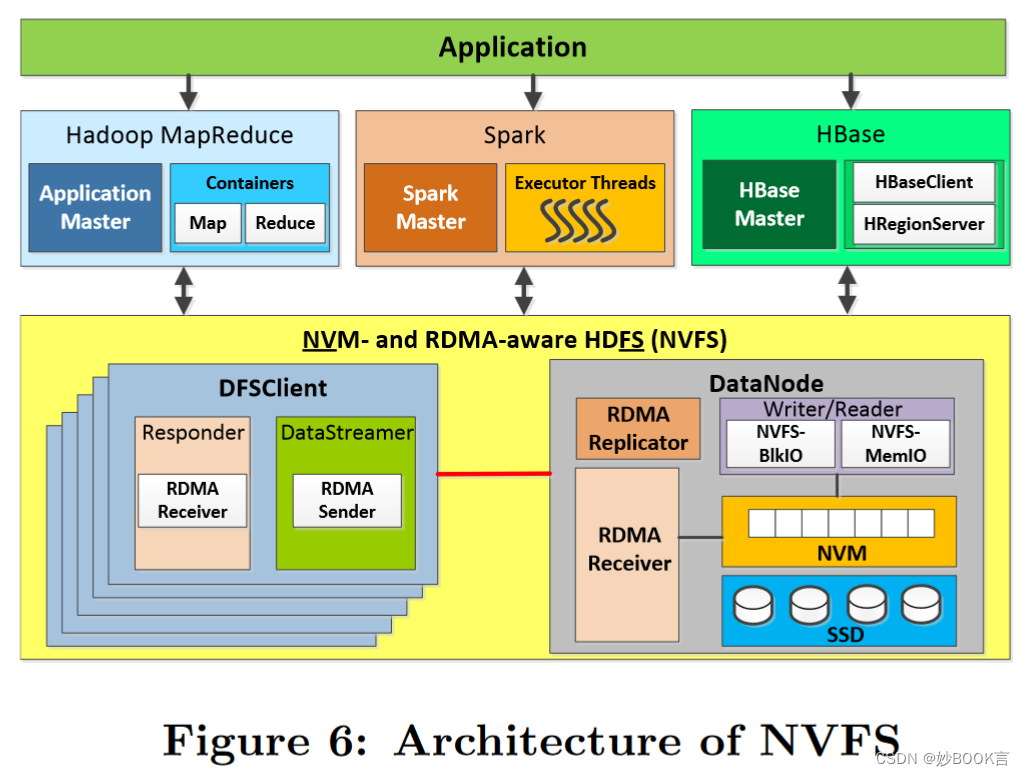
本文提出了一种新的HDFS设计,称为NVFS(NVM和RDMA感知HDFS),以利用NVM的字节寻址能力进行基于RDMA(远程直接内存访问)的通信。
-
通过从NVM分配内存用于基于RDMA的通信,最大限度地减少了计算和I/O的内存争用。
-
重新设计了HDFS存储体系结构,以利用NVM的内存语义进行I/O操作(HDFS写入和读取)。
-
为HBase和Spark提供了经济高效的加速技术,利用基于NVM的HDFS设计,仅将HBase预写日志和Spark作业输出存储到NVM。
-
使用基于NVM的HDFS作为突发缓冲区的增强功能,用于在Lustre等并行文件系统上运行Spark作业。
-
提出了使用NVFS设计作为突发缓冲区,用于在Lustre等并行文件系统上运行Spark作业。
性能评估表明,设计可以将HDFS的写入和读取吞吐量分别提高4倍和2倍,基准测试的执行时间最多减少了45%。与HDFS相比,将SWIM工作负载的总体执行时间减少了18%,作业38的最大效益为37%。对于Spark TeraSort,本文的方案可获得高达11%的性能增益。HBase插入、更新和读取操作的性能分别提高了21%、16%和26%。基于NVM的突发缓冲区可以将Spark PageRank的I/O性能比Lustre提高24%。
总结
针对利用NVM优化HDFS,本文提出NVFS(NVM和RDMA感知HDFS),以利用NVM的字节寻址能力进行基于RDMA的通信。包括四个技术:(1)从NVM分配内存用于RDMA通信,减少了计算和I/O的内存争用。(2)重新设计HDFS存储体系结构,以利用NVM的内存语义进行I/O操作。(3)在底层文件系统中仅针对作业输出和预写日志(WAL)使用NVM来加速Spark和HBase。(4)使用NVFS作为突发缓冲层的增强功能,用于在并行文件系统(如Lustre)上运行Spark作业。
这篇关于High Performance Design for HDFS with Byte-Addressability of NVM and RDMA——论文泛读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!

![Java实现将byte[]转换为File对象](/front/images/it_default.jpg)






