泛读专题

论文泛读: TransNeXt: Robust Foveal Visual Perception for Vision Transformers
文章目录 TransNeXt: Robust Foveal Visual Perception for Vision Transformers论文中的知识补充非QKV注意力变体仿生视觉建模 动机现状问题 贡献方法 TransNeXt: Robust Foveal Visual Perception for Vision Transformers 论文链接: https://o

C++程序设计之泛读概总
本书系统地介绍C++的语法规则和面向过程、面向对象的程序设计方法。内容包括:C++语言概述,运算符、表达式和语句,控制结构,数组、结构体和共用体,函数,指针,类和对象,类的继承,多态性,输入/输出和异常处理。

【自考】信息系统开发与管理(一)——泛读
自考,能够很好的锻炼我们的快速阅读的能力,可是我的阅读速度还是很慢,不过这次强制自己必须在规定时间内完成一定的页数。速度是比以前快一些了,只是泛读了一遍,基本上没有太多的印象,总结也是按照书上的总结的。 这次自考报了三科《信息系统开发与管理》、《数据库原理》、《网络经济与企业管理》。因为刚刚做完学生信息 管理系统,所以先看的《信息系统开发与管理》。做完系统之后,再来
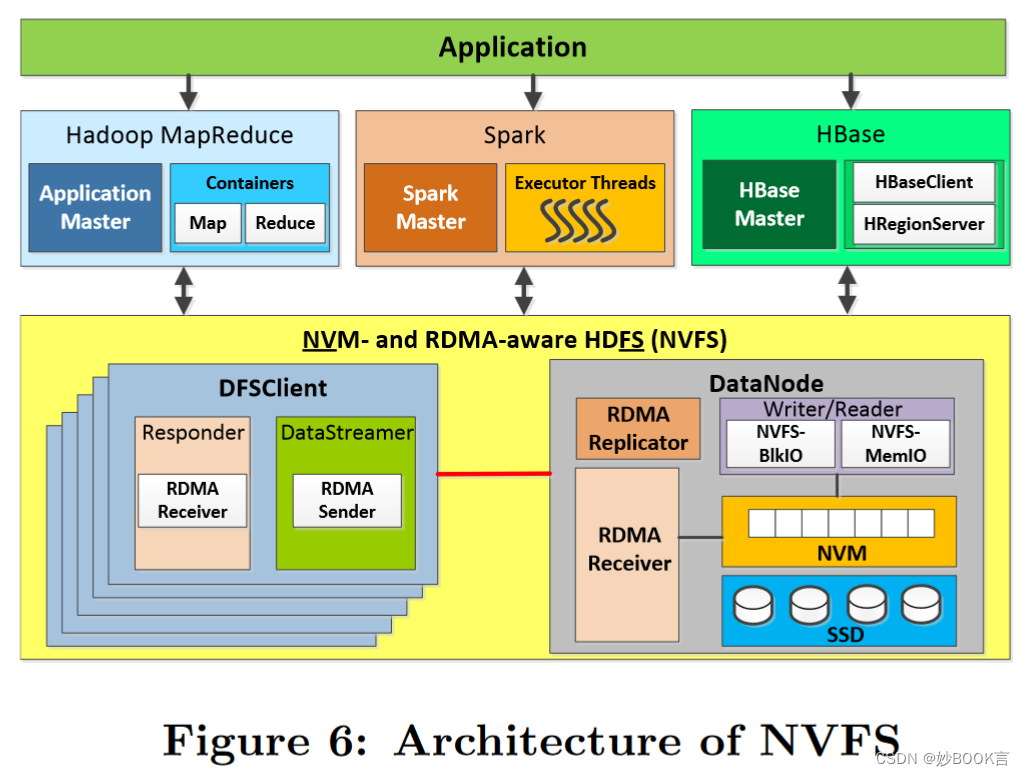
High Performance Design for HDFS with Byte-Addressability of NVM and RDMA——论文泛读
ICS 2016 Paper 分布式元数据论文阅读笔记整理 问题 非易失性存储器(NVM)提供字节寻址能力,具有类似DRAM的性能和持久性,提供了为数据密集型应用构建高通量存储系统的机会。HDFS(Hadoop分布式文件系统)是MapReduce、Spark和HBase的主要存储引擎。尽管HDFS最初是为商品硬件设计的,但它越来越多地被用于HPC(高性能计算)集群。HPC系统的性能要求使HDF
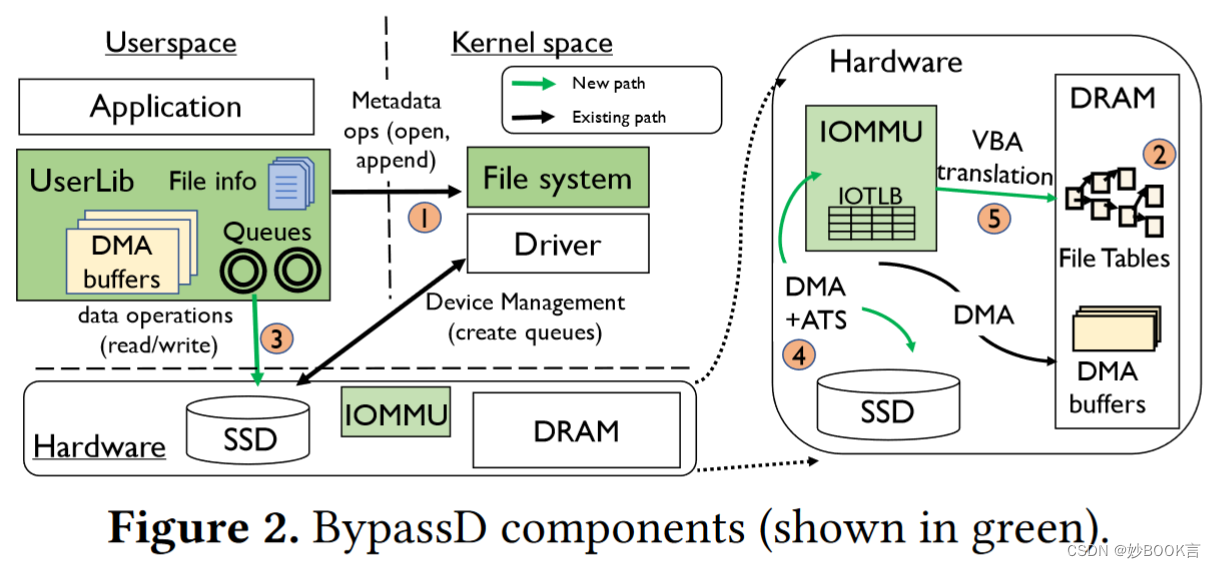
BypassD: Enabling fast userspace access to shared SSDs——论文泛读
ASPLOS 2024 Paper 论文阅读笔记整理 问题 现代存储设备,如Optane NVMe SSD,提供几微秒的超低延迟和每秒数千GB的高带宽,导致内核软件I/O堆栈是开销的主要来源。例如,Optane SSD可以在4𝜇s内返回4KB块,而通过标准Linux内核读取块几乎需要8𝜇s。 现有方法局限性 减少软件开销的方法主要分为两类: 对内核存储堆栈的优化:优化I/O调度[1
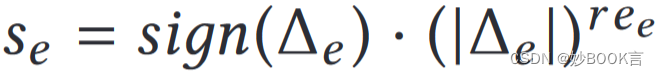
Boosting Cache Performance by Access Time Measurements——论文泛读
TOC 2023 Paper 论文阅读笔记整理 问题 大多数现代系统利用缓存来减少平均数据访问时间并优化其性能。当缓存未命中的访问时间不同时,最大化缓存命中率与最小化平均访问时间不同。例如:系统使用多种不同存储介质时,不同存储介质访问时间不同;系统使用NUMA架构时,不同处理器单元访问时间不同。现有的策略隐含地假设统一的访问时间,但在存储、web搜索和DNS解析等领域,访问时间是可变的。 本

###好好好#####论文泛读·Adversarial Learning for Neural Dialogue Generation
导读 这篇文章的主要工作在于应用了对抗训练(adversarial training)的思路来解决开放式对话生成(open-domain dialogue generation)这样一个无监督的问题。 其主体思想就是将整体任务划分到两个子系统上,一个是生成器(generative model),利用seq2seq式的模型以上文的句子作为输入,输出对应的对话语句;另一个则是一个判别器(di

An introduction to BeeGFS-2018 v2.0——论文泛读
Paper 分布式元数据论文阅读笔记整理 BeeGFS介绍 BeeGFS是并行集群文件系统,提供高性能和可扩展性,高度的灵活性,并为健壮性和易用性而设计。在多个服务器之间透明地分布用户数据,将所有磁盘和服务器的容量和性能聚合在一个命名空间中。 开源代码:Home - BeeGFS - The Leading Parallel Cluster File System 架构 BeeGFS由四
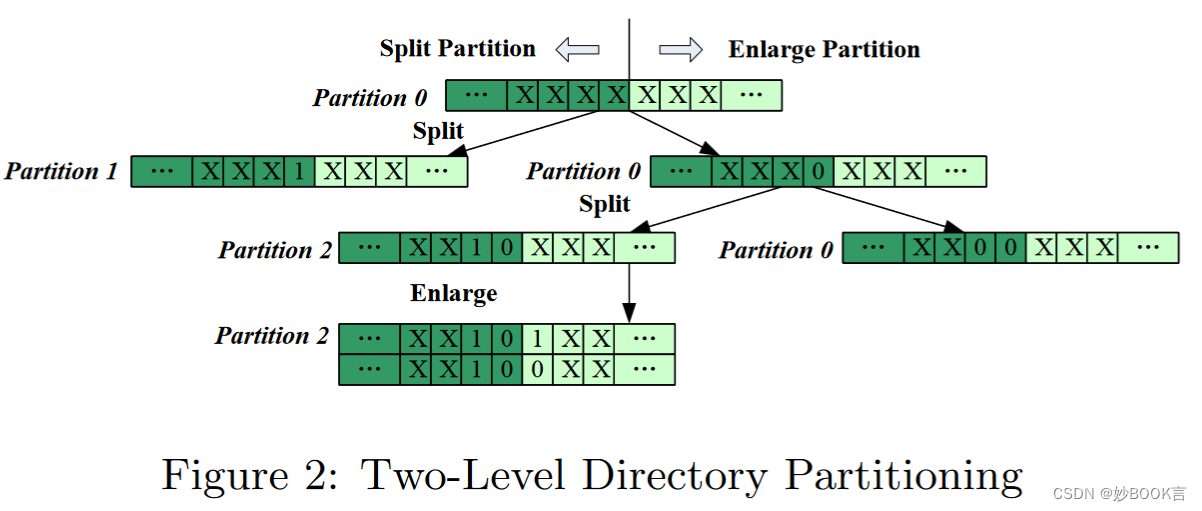
Adaptive and Scalable Metadata Management to Support A Trillion Files——论文泛读
SC 2009 Paper 分布式元数据论文阅读笔记整理 问题 越来越多的应用程序需要文件系统来有效地维护数百万个或更多的文件。如何在大量文件和大目录中提供高访问性能,是集群文件系统面临的一大挑战。受到静态目录结构的限制,现有的文件系统在这种使用中效率低下。 挑战 如何有效地组织和维护非常大的目录,每个目录都包含数十亿个文件。 如何为拥有数十亿或数万亿文件的大型文件系统提供高元数据性能
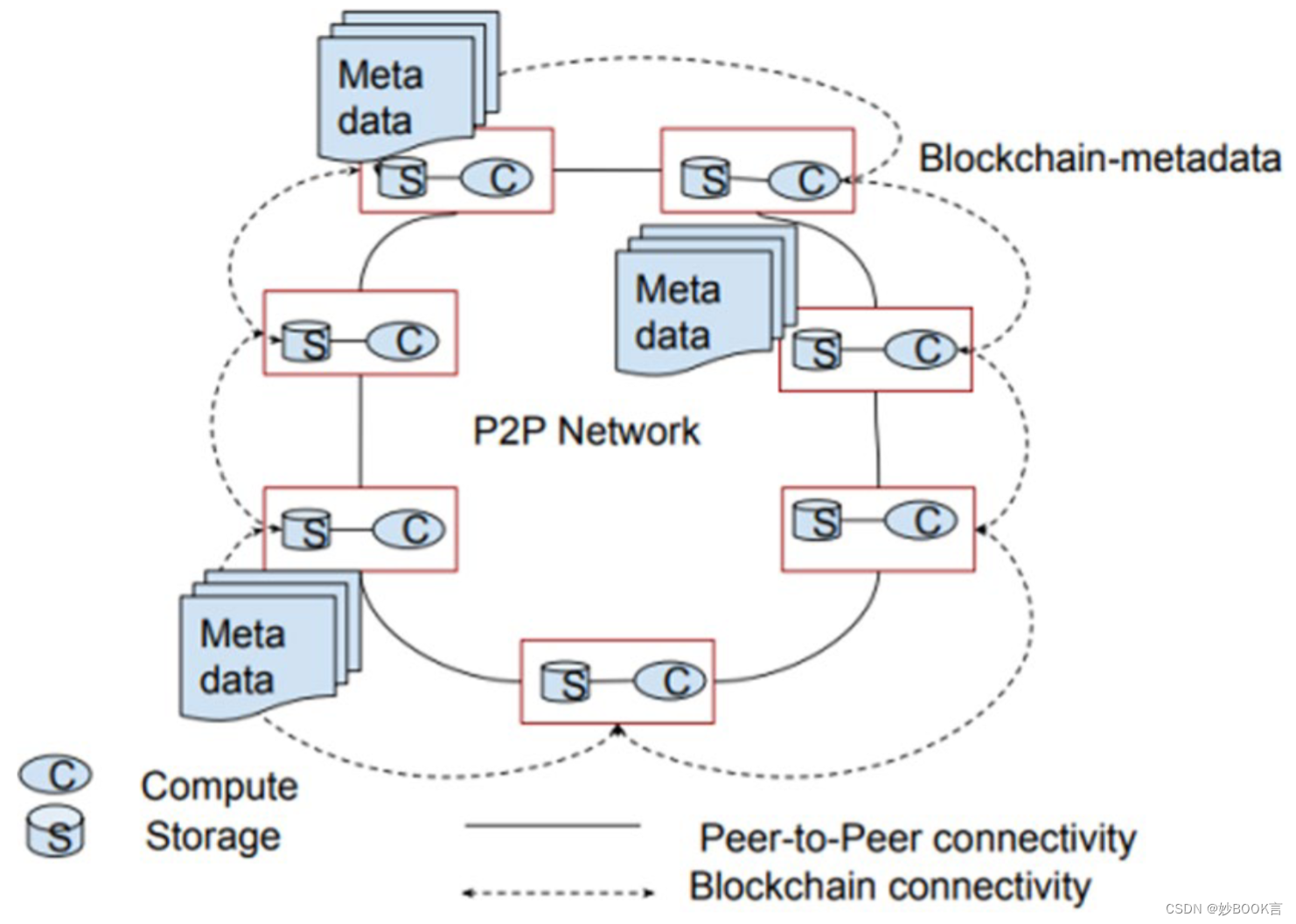
A Novel Distributed File System Using Blockchain Metadata——论文泛读
Wireless Personal Communications 2023 Paper 分布式元数据论文阅读笔记整理 问题 随着来自不同来源(如在线社交媒体、物联网、移动数据、传感器数据、黑匣子数据等)的大量数据以指数级的速度增长,集群计算已成为数据处理中不可避免的一部分。分布式文件系统定义了不同的方法来在不同的集群计算节点之间分发、读取和删除文件。但流行的分布式文件系统(如Google fi
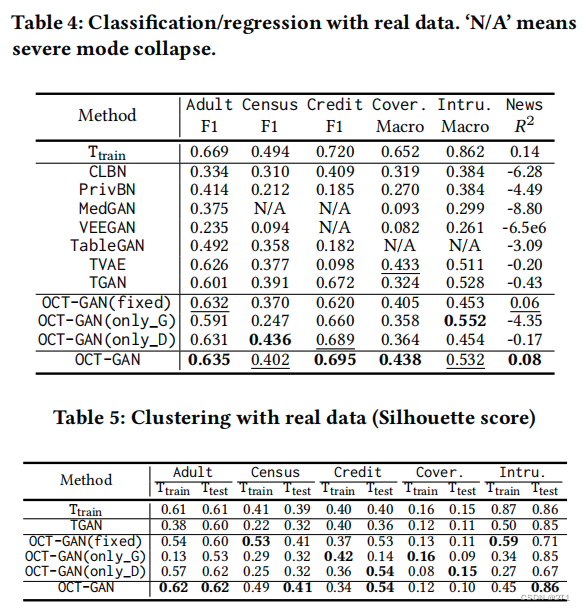
【论文泛读】OCT-GAN(WWW’21)
Jayoung Kim, Jinsung Jeon, Jaehoon Lee, Jihyeon Hyeong, Noseong Park Yonsei University 原文传送 摘要 表格数据的生成,为人们增加了训练数据。最先进的方法在数据不平衡分布和模式崩溃问题上还不令人满意。主要贡献: 鉴别器有一个ODE层来提取一个隐藏的向量演化轨迹进行分类;轨迹由在不同层(或时间)𝑡𝑖上提
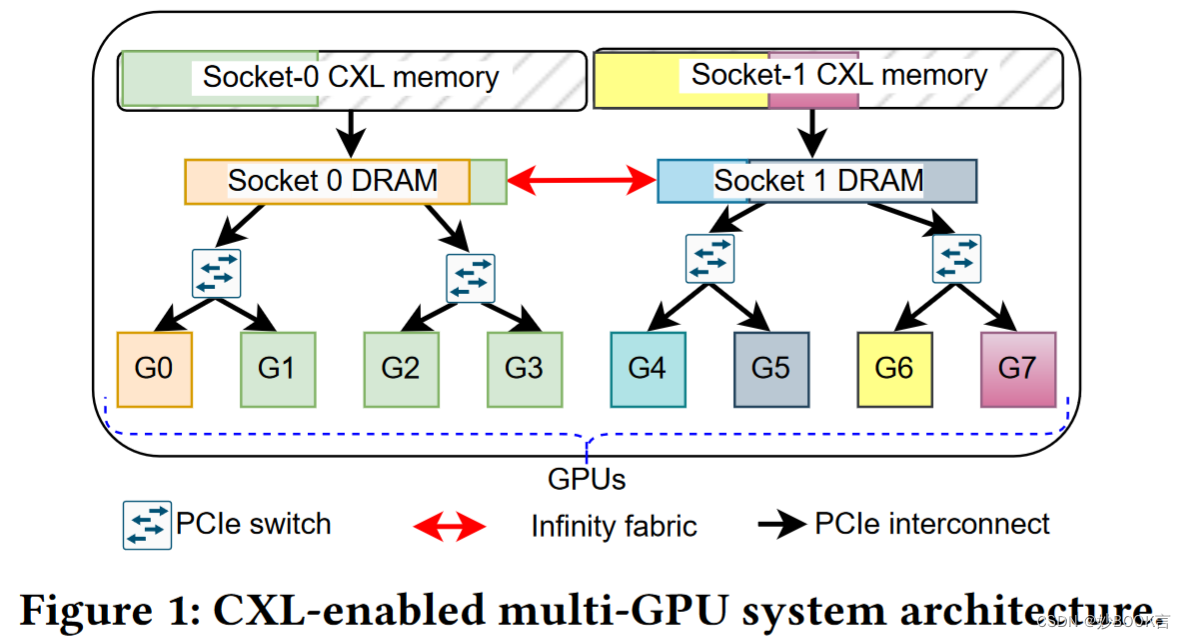
Accelerating Performance of GPU-based Workloads Using CXL——论文泛读
FlexScience 2023 Paper CXL论文阅读笔记整理 问题 跨多GPU系统运行的高性能计算(HPC)工作负载,如科学模拟和深度学习,是内存和数据密集型的,依赖于主机内存来补充其有限的板载高带宽内存(HBM)。为了促进在慢速设备到主机PCIe互连之间更快的数据传输,这些工作负载通常将内存固定在主机系统上,但对同一节点的对等GPU上运行的工作负载的主机内存造成内存容量限制。(预留部

FusionFS: Fusing I/O Operations using CISCOps in Firmware File Systems——论文泛读
FAST 2022 Paper 元数据论文阅读笔记汇总 问题 现代高带宽和低延迟存储技术,如NVMe SSD[50]和3D Xpoint[6],显著提高了I/O性能,从而提高了应用程序性能。然而,软件和硬件I/O开销,包括系统调用、数据移动、应用程序和操作系统中的通信成本,以及存储硬件延迟(例如PCIe),仍然是充分利用存储硬件功能的致命弱点。 现有方法局限性 一种方法是将文件系统移动到用

多示例论文泛读--2018-1-MIRSVM_ Multi-instance support vector machine with bag representatives
题目 MIRSVM: Multi-instance support vector machine with bag representatives 包代表的多实例支持向量机 符号系统 符号含义 n n n包的个数 m m m示例的个数 d d d示例的属性个数 B = { B 1 , … , B n } \mathcal{B}=\left\{\mathcal{B}_{1}, \ldots,
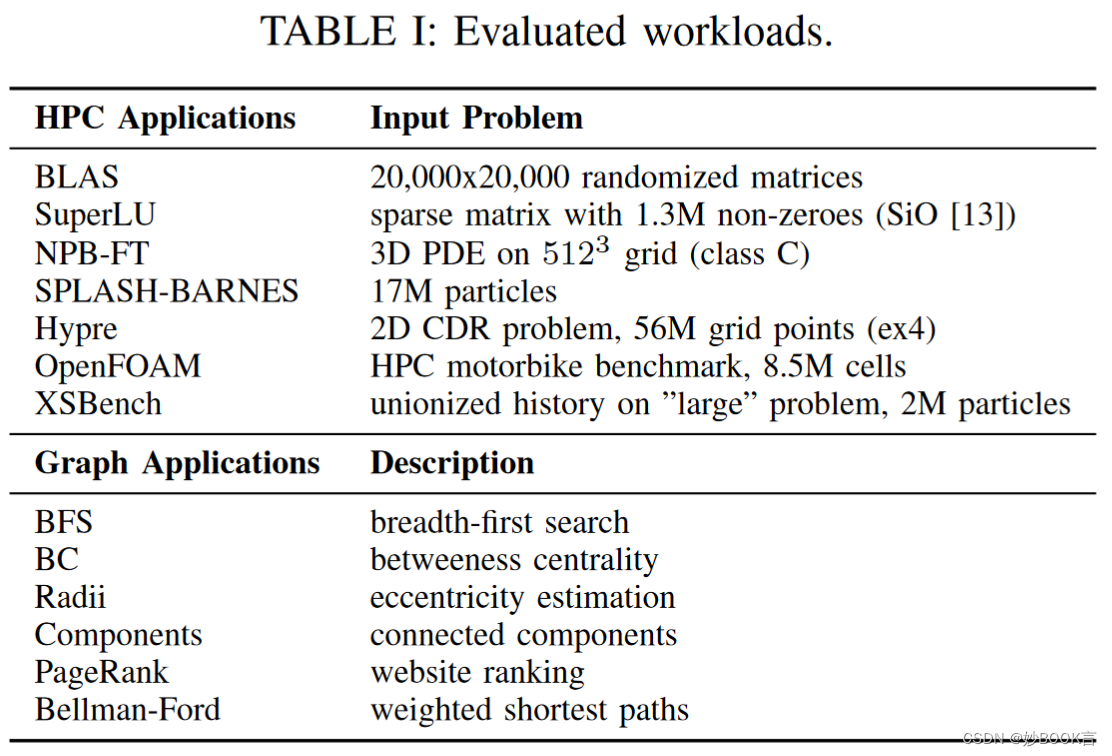
Evaluating Emerging CXL-enabled Memory Pooling for HPC Systems——论文泛读
MCHPC@SC 2022 Paper CXL论文阅读汇总 问题 当前的高性能计算(HPC)系统提供的内存资源是静态配置的,并与计算节点紧密耦合。然而,HPC系统上的工作负载正在演变。多样化的工作负载导致对可配置内存资源的需求,以实现高性能和高利用率。 现有方法局限性 CXL是用于互连处理器、加速器和内存的开放标准。符合CXL标准的硬件提供了对应用程序代码透明的低延迟、高带宽数据访问。一些
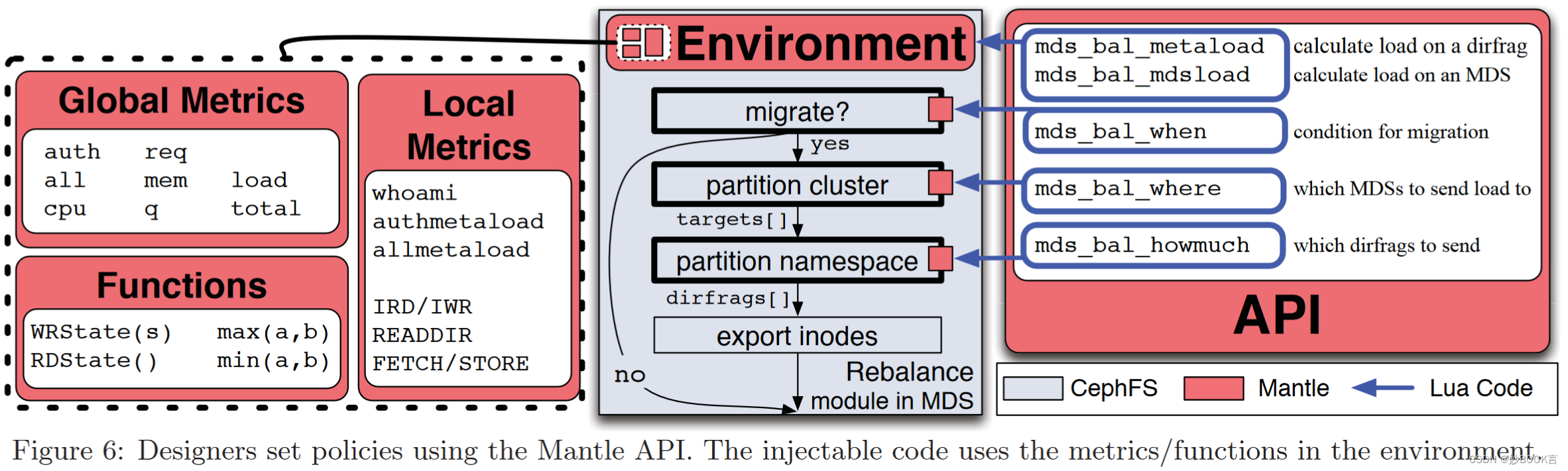
Mantle: A Programmable Metadata Load Balancer for the Ceph File System——论文泛读
SC 2015 Paper 元数据论文阅读汇总 问题 优化Ceph的元数据局部性和负载平衡。 现有方法 提高元数据服务性能的最常见技术是在专用的元数据服务器(MDS)节点之间平衡负载 [16, 25, 26, 21, 28]。常见的方法是鼓励独立增长并减少通信,使用诸如懒惰客户端和MDS同步 [16, 18, 29, 9, 30]、inode路径/权限缓存 [4, 11, 28]、具有局部

A machine learning approach for non-blind image deconvolution(泛读)
一.文献名字和作者 A machine learning approach for non-blind image deconvolution, CVPR2013 二.阅读时间 2014年10月20日

Learning a Deep Convolutional Network for Image Super-Resolution(泛读)
一.文献名字和作者 Learning a Deep Convolutional Network for Image Super-Resolution, ECCV2014 二.阅读时间 2014年10月16日 三.文献的贡献点 作者提出了使用CNN来进行图像超分辨率重构,作者分析了超分辨率的主要过程,通过数学表示证明了

论文泛读-故障恢复-1
Network Recovery from Massive Failures under Uncertain Knowledge of Damages ——IFIP Networking Conference (IFIP Networking) and Workshops(2017) 故障类型:由于飓风、地震等造成的网络设备大规模故障 问题:修复受灾网络,直至满足关键服务 方式:从已知节点状态开

【论文泛读25】用于极端多标签文本分类的驯服预处理变压器
贴一下汇总贴:论文阅读记录 论文链接:《Taming Pretrained Transformers for Extreme Multi-label Text Classification》 一、摘要 我们考虑极端的多标签文本分类(XMC)问题:给定一个输入文本,从一个大的标签集合中返回最相关的标签。例如,输入文本可以是Amazon.com的产品描述,标签可以是产品类别。XMC是NLP社区中

论文泛读:Distribution aligning refinery of pseudo-label for imbalanced semi-supervised learning
论文泛读:Distribution aligning refinery of pseudo-label for imbalanced semi-supervised learning

【论文泛读】 DenseNet:稠密连接的卷积网络
【论文泛读】 DenseNet:稠密连接的卷积网络 文章目录 【论文泛读】 DenseNet:稠密连接的卷积网络摘要 Abstract介绍 Introduction相关工作 Related WorkDenseNetResNet稠密连接(Dense connectivity)组合函数(Composite function)池化层(Pooling layers)增长速率(Growth rate

研究生论文阅读方法(包含泛读、略读、精读、深读)
已经好久没有更新博客了,前段时间忙着复现高翔的博客教程(一起来做RGBD),SLAM十四讲也已经看完了一遍(新手还是有点懵)。现在开始看论文,突然没有了方向感。导师在实验室论坛上的论文阅读要求给了我很大的启发,分享给各位,希望大家研究生学习都能充满方向感! 对于其中的十个问题,主要是 文献阅读按照先综述后细化的步骤展开~