本文主要是介绍【论文泛读25】用于极端多标签文本分类的驯服预处理变压器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
贴一下汇总贴:论文阅读记录
论文链接:《Taming Pretrained Transformers for Extreme Multi-label Text Classification》
一、摘要
我们考虑极端的多标签文本分类(XMC)问题:给定一个输入文本,从一个大的标签集合中返回最相关的标签。例如,输入文本可以是Amazon.com的产品描述,标签可以是产品类别。XMC是NLP社区中一个重要而又具有挑战性的问题。最近,深度预训练的变压器模型在许多自然语言处理任务上取得了最先进的性能,包括句子分类,尽管标签集很小。然而,由于大输出空间和标签稀疏问题,天真地将深度变换器模型应用于XMC问题会导致次优性能。在本文中,我们提出了X-Transformer,这是第一个针对XMC问题微调深度转换器模型的可扩展方法。所提出的方法在四个XMC基准数据集上实现了新的最先进的结果。
二、结论
在本文中,我们提出了X-Transformer,这是第一个用于微调Deep Transformer模型的可扩展框架,它在四个XMC基准数据集上改进了最先进的XMC方法。我们进一步将X-Transformer应用于现实应用程序product2query预测,显示出对竞争对手Parabel线性模型的显著改进。
三、XMC
极端多标签文本分类
Extreme Multi-label text Classification
给定一个输入文本实例,从一个巨大的标签集合中返回最相关的标签,其中标签的数量可能在数百万或更多。
XMC本质上是一个工业规模的文本分类问题,是机器学习和自然语言处理(NLP)领域最重要和最基本的课题之一。
- 计算挑战
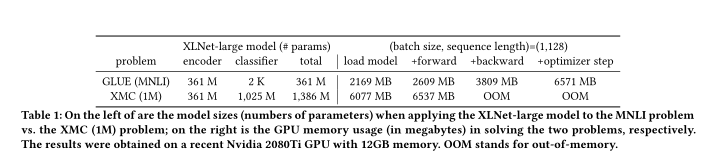
- 标签稀疏导致输出空间过大
ELMo使用一个(双向LSTM)模型对大量未标记的文本数据进行预处理,以获得内容化的单词嵌入。
X-Transformer
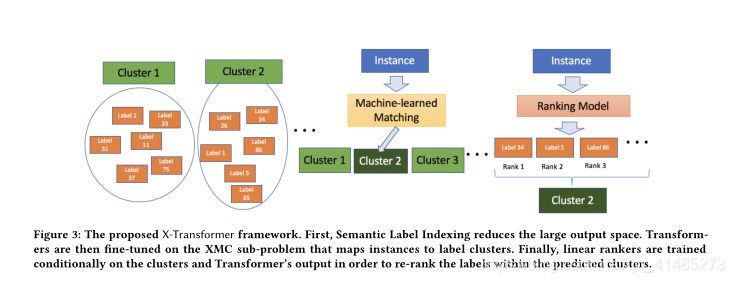
提出了X-Transformer,这是一种克服上述问题的新方法,成功地针对XMC问题微调了深层Transformer模型。X-Transformer由语义标签索引组件、深度神经匹配组件和集成排序组件组成。首先,语义标签索引(SLI)通过标签聚类将原始的棘手的XMC问题分解成一组输出空间小得多的可行子问题,这缓解了标签稀疏性问题,如图1右侧所示。第二,深度神经匹配组件为每个SLI诱发的XMC子问题微调变换器模型,导致从输入文本到标签簇集合的更好映射。最后,集成排序组件在来自转换器的实例到集群分配和神经嵌入上被有条件地训练,并且被用来汇集从各种SLI引起的子问题中得到的分数,用于进一步的性能改进。


代码地址:Github代码
相关工作
- Sparse Linear Models
- Deep Learning Approaches
- BERT
- Word2vec
- Keyword recommendation system
这篇关于【论文泛读25】用于极端多标签文本分类的驯服预处理变压器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





