本文主要是介绍Adaptive and Scalable Metadata Management to Support A Trillion Files——论文泛读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SC 2009 Paper 分布式元数据论文阅读笔记整理
问题
越来越多的应用程序需要文件系统来有效地维护数百万个或更多的文件。如何在大量文件和大目录中提供高访问性能,是集群文件系统面临的一大挑战。受到静态目录结构的限制,现有的文件系统在这种使用中效率低下。
挑战
-
如何有效地组织和维护非常大的目录,每个目录都包含数十亿个文件。
-
如何为拥有数十亿或数万亿文件的大型文件系统提供高元数据性能。
-
如何为大量并发用户生成的混合工作负载提供高元数据性能。避免元数据缓存低效和元数据服务器之间的负载不平衡。
本文方法
本文提出了一个可扩展、自适应的元数据管理系统。
-
基于可扩展哈希的自适应两级目录分区来管理大目录,根据文件名计算哈希,将哈希的不同部分作为分区信息和分块信息。在第一级中,每个目录被划分为多个分区,分布在多个服务器上,控制元数据服务器之间的分区分布。在第二级中,每个分区被划分为一定数量的元数据块,控制每个分区的大小,任何文件都可以位于两个I/O访问范围内。
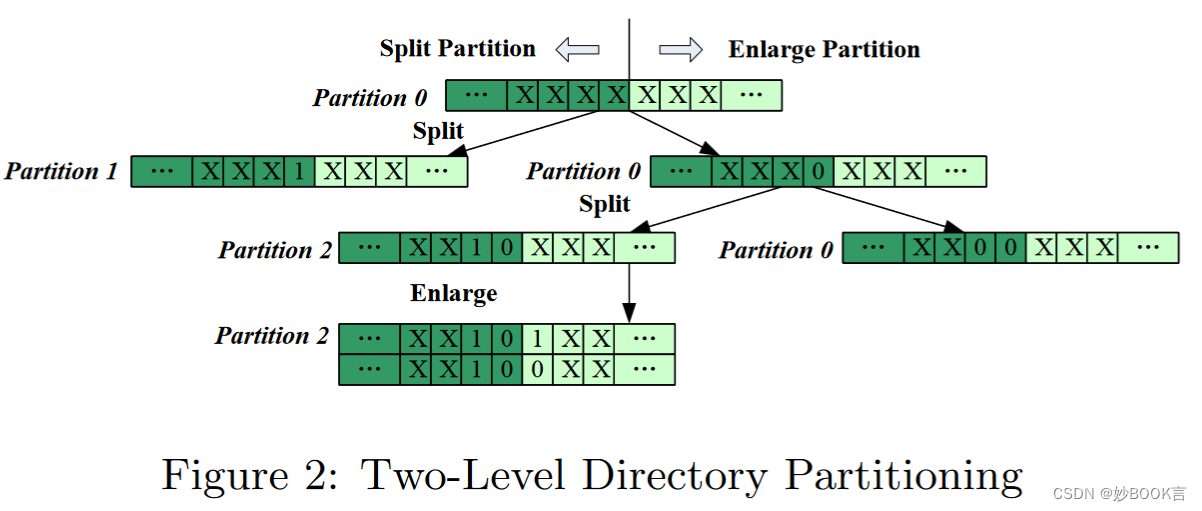
-
在目录中使用细粒度的并行处理,极大地提高了文件创建、删除的性能。使用分区、块这些数据结构作为元数据修改的元数据控制单元,可以同时处理同一目录中的文件创建或删除等更新操作。
-
使用多层元数据缓存管理,提高了服务器上的内存利用率。利用了不同类型元数据的重要性,根据元数据的类型将元数据缓存划分为具有不同替换优先级的多层。最频繁访问的元数据,例如由许多目录条目共享的目录信息和分区信息,将被缓存在存储器中最长的时间。
-
使用基于一致哈希的动态负载平衡机制,使系统能够轻松地上下扩展。
在32个元数据服务器上的性能结果表明,用户级原型实现可以在一个拥有1亿个文件的目录中每秒创建超过7.4万个文件,并可以每秒获得超过27万个文件的属性。此外,在拥有10亿个文件的目录中提供了每秒超过6万个文件创建的峰值吞吐量。
实验
数据集:mdtest
实验对比:吞吐量、CPU计算时间
实验参数:目录大小、服务器数量、负载均衡阈值
总结
针对大目录和海量文件的分布式文件系统元数据性能。提出:(1)基于可扩展哈希使用两级目录分区来管理大目录,根据文件名计算哈希,将哈希的不同部分作为分区信息和分块信息,根据分区和分块信息划分到不同服务器上。(2)使用分区、分块作为元数据修改的单元,同时处理同一目录中的文件创建或删除等更新操作。(3)根据元数据的类型将元数据缓存划分为具有不同替换优先级的多层,分层管理缓存,增加缓存效率。(4)使用基于一致哈希的动态负载平衡机制。
局限性:整体基于哈希划分文件,文件重命名后可能导致大量的数据迁移。基于哈希也难以实现较好的局部性。
这篇关于Adaptive and Scalable Metadata Management to Support A Trillion Files——论文泛读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)


