scalable专题

pytest fixtures: explicit, modular, scalable 中文版
随着编程生涯的增长,会越来越发现,基本出现在中文相关资料的相关技术文章,靠谱的太少,老外的相反,真的是有种月亮还是外国的圆的感觉,最近想闲下来事情不多的时候,翻译一些,自己用到的,特别有用处的一些技术文章。前边的一篇JAVA NIO是第一篇,这将是第二篇。 python是一门特别容易上手,使用的语言,并且得益于其庞大的第三方库,使其具有其他脚本语言不具有的更多能力。或许这是众多软件使用pyth
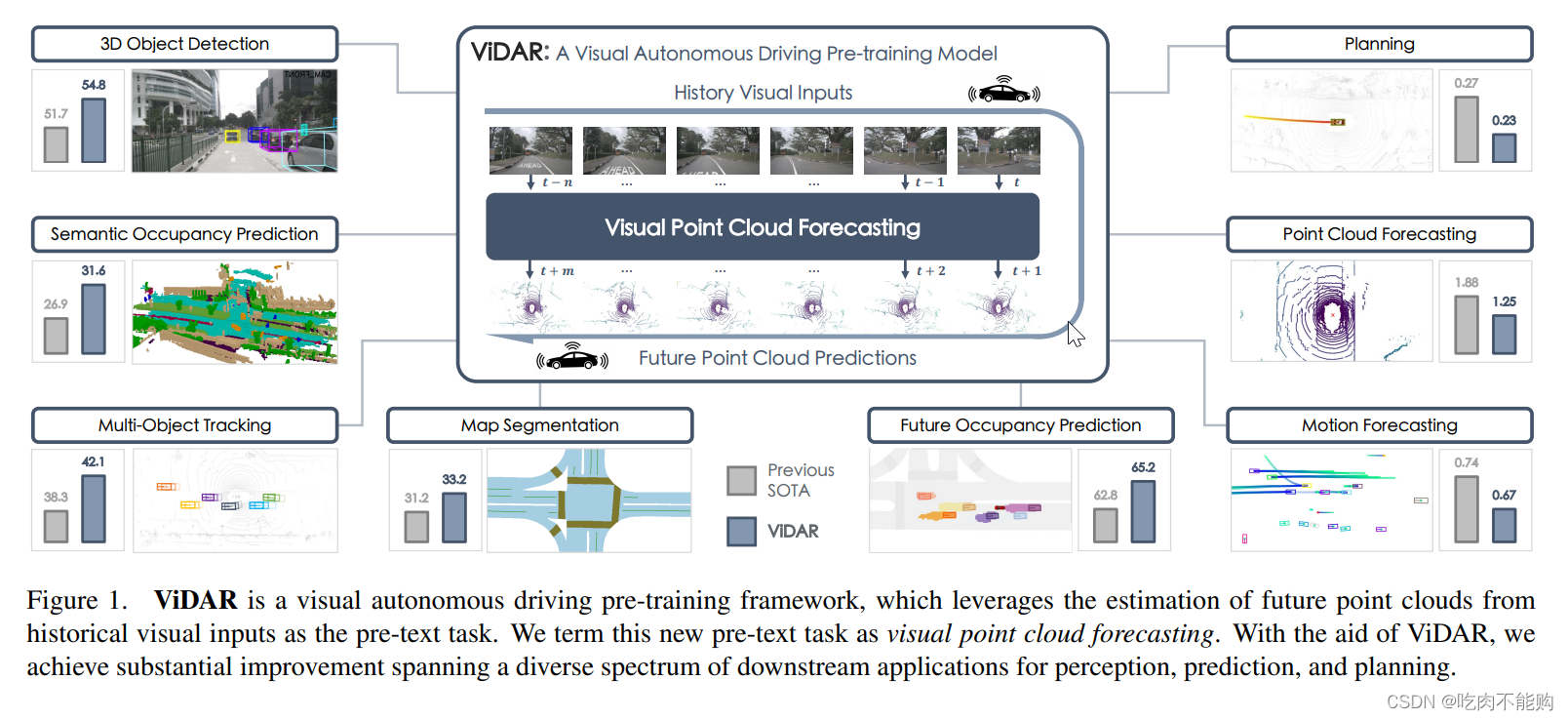
论文《Visual Point Cloud Forecasting enables Scalable Autonomous Driving》详细解析
论文《Visual Point Cloud Forecasting enables Scalable Autonomous Driving》详细解析 摘要 该论文提出了一种新的预训练任务,称为“视觉点云预测”(Visual Point Cloud Forecasting),从历史视觉输入中预测未来的点云。论文介绍了ViDAR模型,通过这种方法显著提高了多种下游任务(如感知、预测和规划)的性能。
Guerrilla Capacity Planning: A Tactical Approach to Planning for Highly Scalable Applications and Se
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp In these days of shortened fiscal horizons and contracted time-to-market schedules, traditional approac
![[论文精读]Masked Autoencoders are scalable Vision Learners](https://img-blog.csdnimg.cn/direct/339a52553e2447ffa8b06a7d8d7d0fef.png)
[论文精读]Masked Autoencoders are scalable Vision Learners
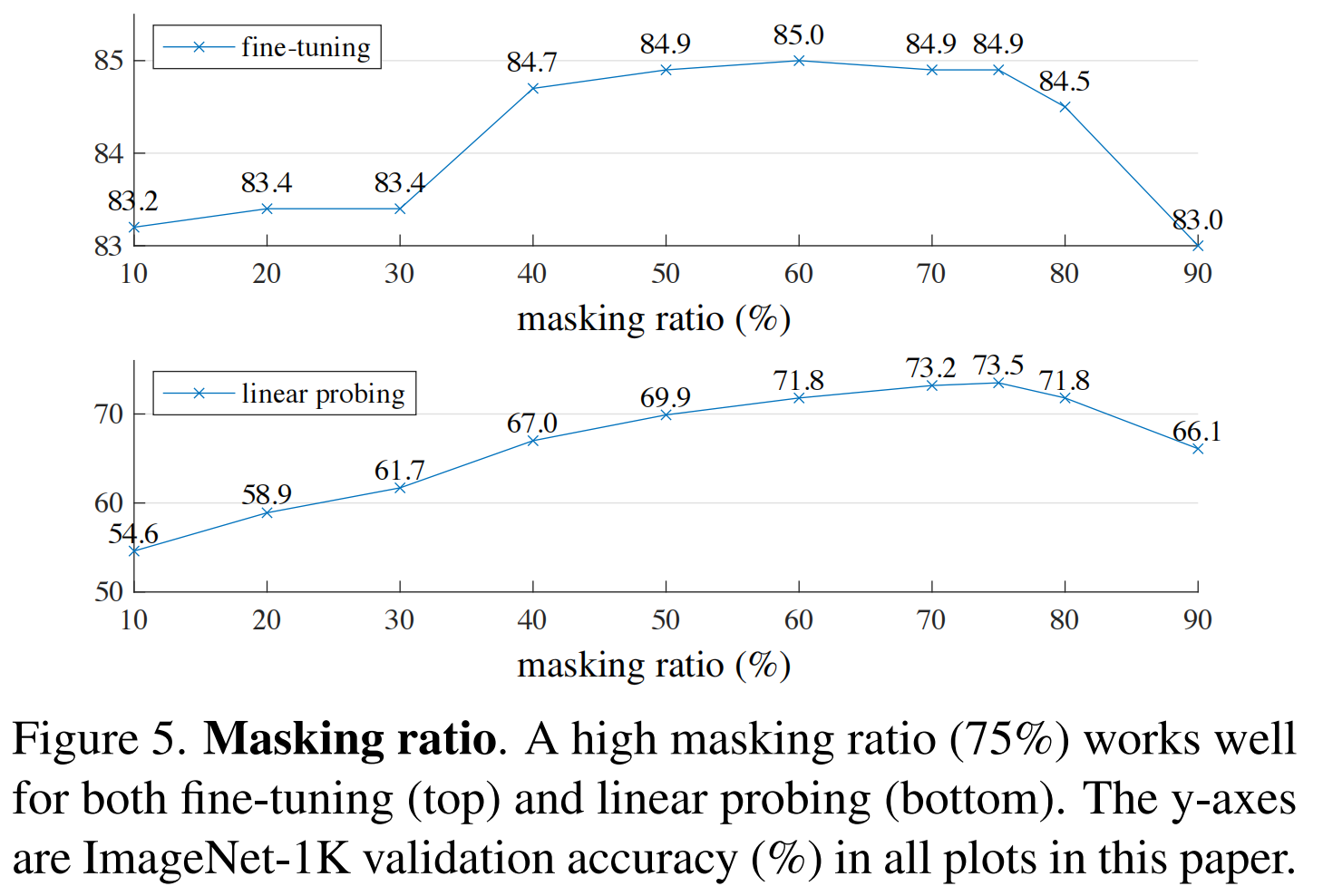
摘要本文证明了掩码自编码器(MAE)是一种可扩展的计算机视觉自监督学习算法。我们的 MAE方法很简单:我们盖住输入图像的随机块并重建缺失的像素。它基于两个核心设计。首先,我们开发了一个非对称编码器-解码器架构,其中一个编码器仅对块的可见子集(没有掩码标记)进行操作,以及一个轻量级解码器,该解码器从潜在表示和掩码标记重建原始图像。其次,我们发现如果用比较高的掩盖比例掩盖输入图像,例如75%,这会产生

Node2vec: Scalable Feature Learning for Networks(KDD16)
Node2vec: Scalable Feature Learning for Networks(KDD16)阅读笔记 作者:斯坦福大学 Aditya Grover,Jure Leskovec 研究内容 研究问题:学习网络的特征表示,将节点映射到低维空间,并且最大程度的保留节点的邻居信息。现有方法的不足:不能获取和表示网络中连接模式的多样性diversity研究方法:提出node2vec
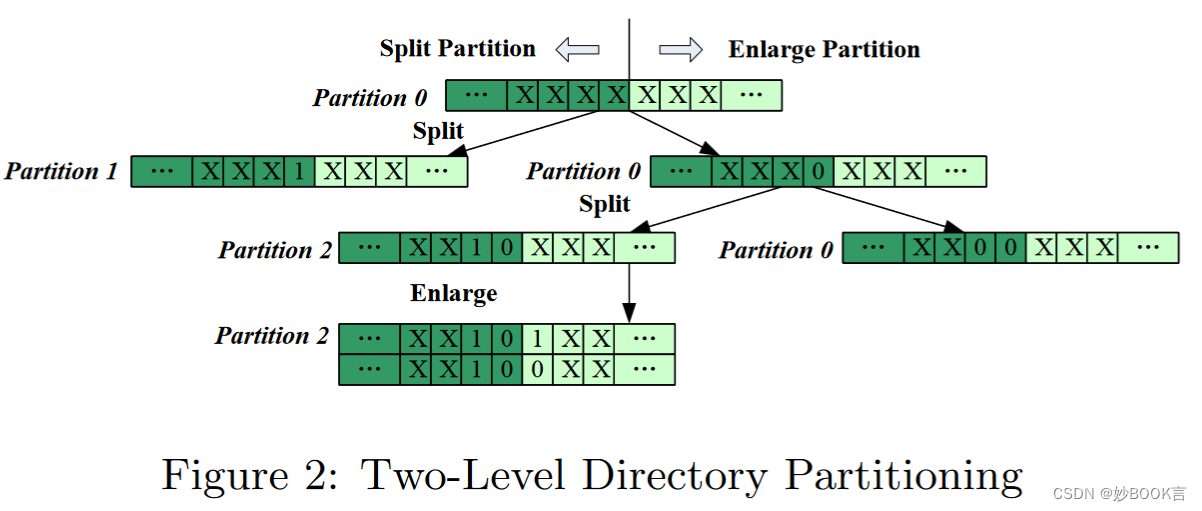
Adaptive and Scalable Metadata Management to Support A Trillion Files——论文泛读
SC 2009 Paper 分布式元数据论文阅读笔记整理 问题 越来越多的应用程序需要文件系统来有效地维护数百万个或更多的文件。如何在大量文件和大目录中提供高访问性能,是集群文件系统面临的一大挑战。受到静态目录结构的限制,现有的文件系统在这种使用中效率低下。 挑战 如何有效地组织和维护非常大的目录,每个目录都包含数十亿个文件。 如何为拥有数十亿或数万亿文件的大型文件系统提供高元数据性能
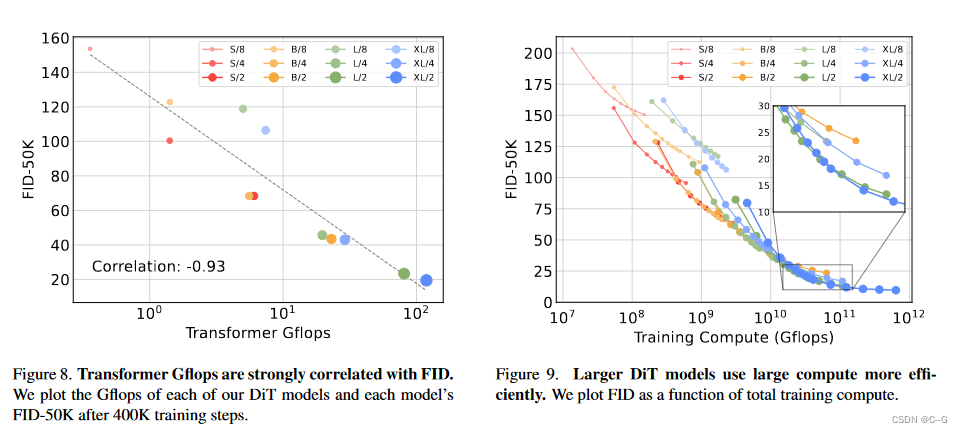
15、Scalable Diffusion Models with Transformers
简介 官网 DiT(Diffusuion Transformer)将扩散模型的 UNet backbone 换成 Transformer,并且发现通过增加 Transformer 的深度/宽度或增加输入令牌数量,具有较高 Gflops 的 DiT 始终具有较低的 FID(~2.27),这样说明 DiT 是可扩展的(Scalable),网络复杂度(以 Gflops 度量)与样本质量(以 FID
【计算机图形学】General Flow as Foundation Affordance for Scalable Robot Learning
对General Flow as Foundation Affordance for Scalable Robot Learning的简单理解 文章目录 1. 做的事2. 作为Affordance的General Flow2.1 General Flow Affordance2.2 General Flow属性 3. 智能体不可知的和规模感知的General Flow预测3.1 Genera
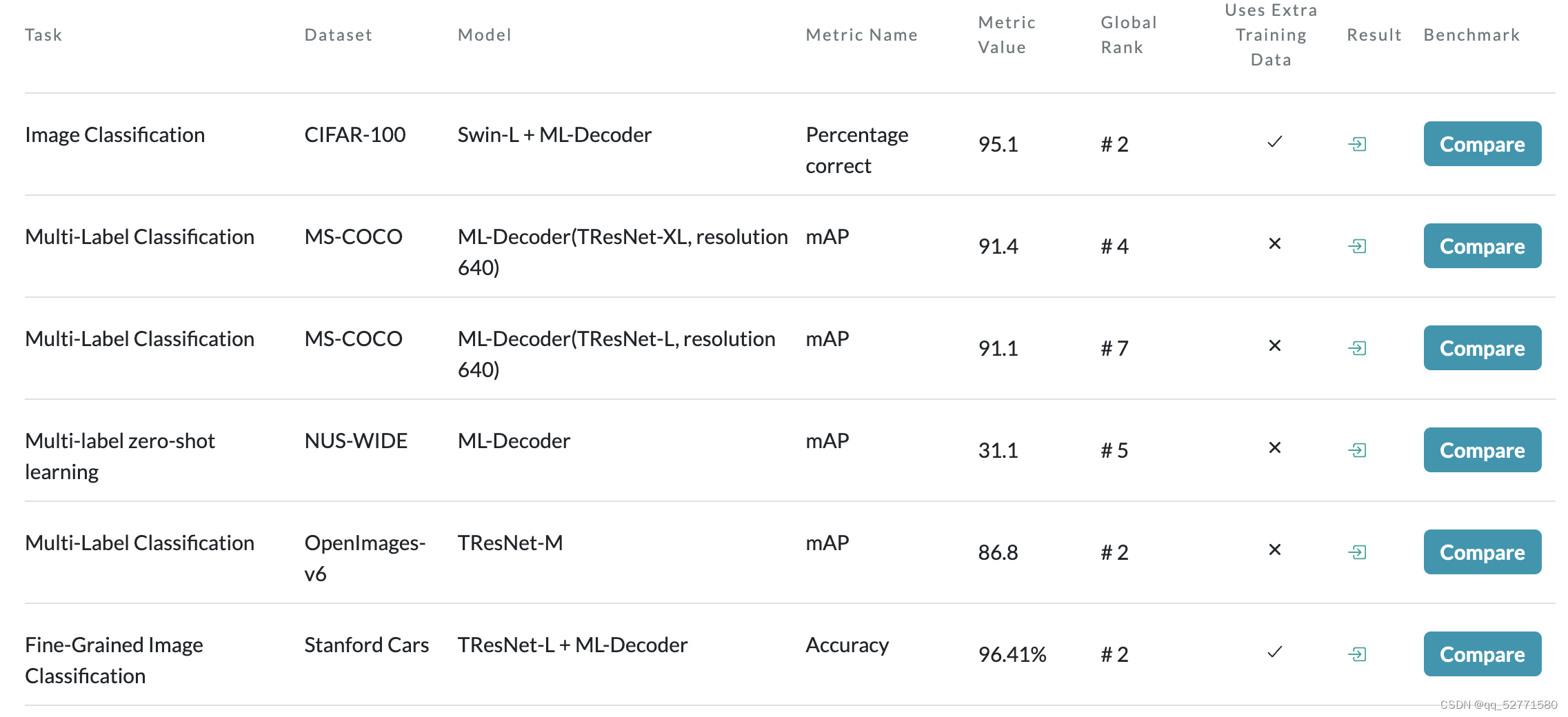
ML-Decoder: Scalable and Versatile Classification Head
1、引言 论文链接:https://openaccess.thecvf.com/content/WACV2023/papers/Ridnik_ML-Decoder_Scalable_and_Versatile_Classification_Head_WACV_2023_paper.pdf 因为 transformer 解码器分类头[1] 在少类别多标签分类数据集上表现得很好,但

ElasticSearch学习篇10_Lucene数据存储之BKD动态磁盘树(论文Bkd-Tree: A Dynamic Scalable kd-Tree)
前言 基础的数据结构如二叉树衍生的的平衡二叉搜索树通过左旋右旋调整树的平衡维护数据,靠着二分算法能满足一维度数据的logN时间复杂度的近似搜索。对于大规模多维度数据近似搜索,Lucene采用一种BKD结构,该结构能很好的空间利用率和性能。 本片博客主要学习常见的多维数据搜索数据结构、KD-Tree的构建、搜索过程以针对高维度数据容灾的优化的BBF算法,通过读论文学习BKD结构原理,总结对数算法
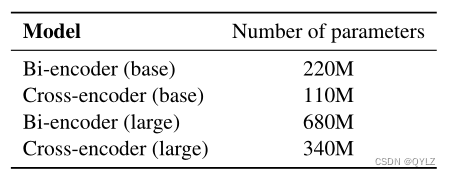
论文:Scalable Zero-shot Entity Linking with Dense Entity Retrieval翻译笔记(实体链接)
文章目录 论文标题:通过密集实体检索实现可扩展的零镜头实体链接摘要1 引言2 相关工作3 定义和任务制定4 方法4.1 双编码器4.2 交叉编码器4.3 知识蒸馏 5 实验5.1 数据集5.2 评估设置和结果5.2.1 零点实体链接5.2.2 tackbp-20105.2.3 WikilinksNED Unseen-Mentions 5.3 知识蒸馏 6 定性分析7 结论A 训练细节和超参数

【论文精读】MAE:Masked Autoencoders Are Scalable Vision Learners 带掩码的自动编码器是可扩展的视觉学习器
系列文章目录 【论文精读】Transformer:Attention Is All You Need 【论文精读】BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding 【论文精读】VIT:vision transformer论文 文章目录 系列文章目录一、前言二、文章概览(一)研究背

MAE——「Masked Autoencoders Are Scalable Vision Learners」
这次,何凯明证明让BERT式预训练在CV上也能训的很好。 论文「Masked Autoencoders Are Scalable Vision Learners」证明了 masked autoencoders(MAE) 是一种可扩展的计算机视觉自监督学习方法。 这项工作的意义何在? 讨论区 Reference MAE 论文逐段精读【论文精读】_哔哩哔哩_bilibili //
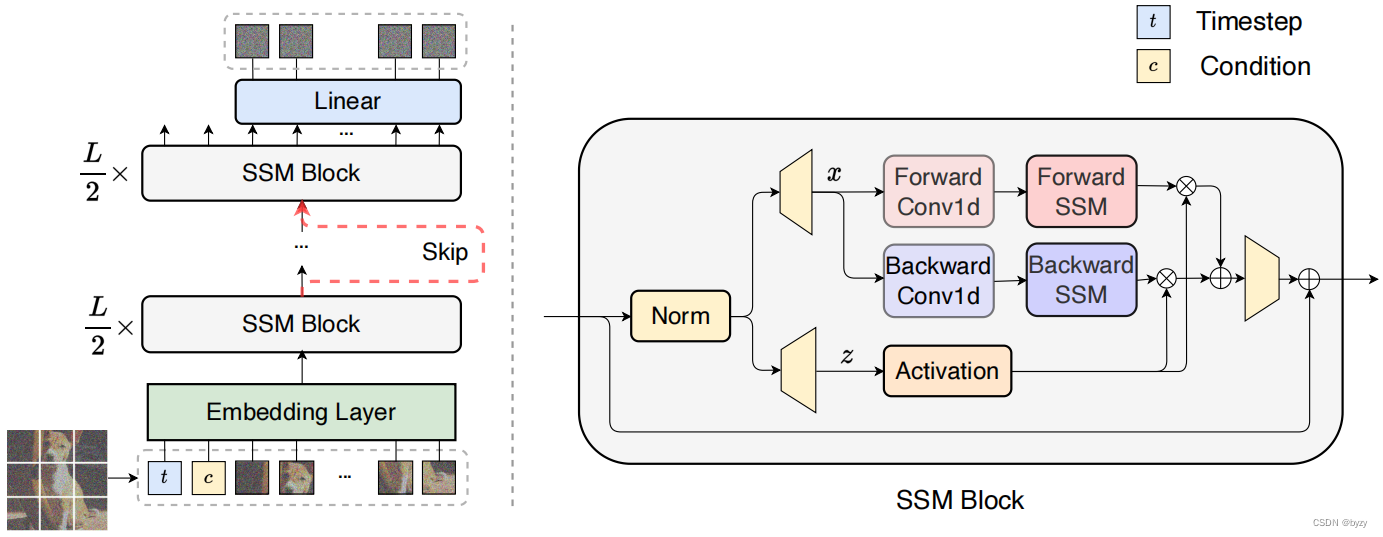
【论文笔记】Scalable Diffusion Models with State Space Backbone
原文链接:https://arxiv.org/abs/2402.05608 1. 引言 主干网络是扩散模型发展的关键方面,其中基于CNN的U-Net(下采样-跳跃连接-上采样)和基于Transformer的结构(使用自注意力替换采样块)是代表性的例子。 状态空间模型(SSM)在长序列建模方面有极大潜力。本文受Mamba启发,建立基于SSM的扩散模型,称为DiS。DiS将所有输入(时间、条件和
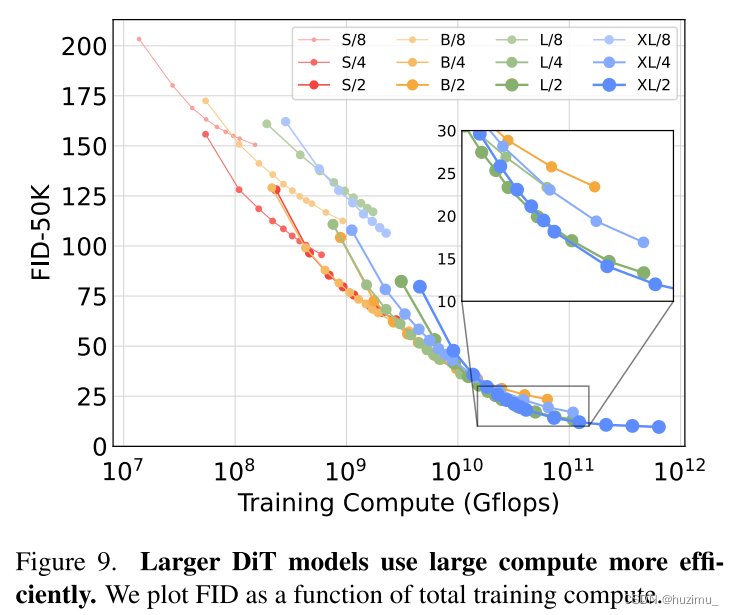
论文阅读:Scalable Diffusion Models with Transformers
Scalable Diffusion Models with Transformers 论文链接 介绍 传统的扩散模型基于一个U-Net骨架,这篇文章提出了一种新的扩散模型结构,将U-Net替换为一个transformer,并将这种结构称为Diffusion Transformers (DiTs)。他们还发现,transformer的规模越大(通过Gflops衡量),生成的图片的质量越好(F

Scalable IO in Java
原文地址: http://gee.cs.oswego.edu/dl/cpjslides/nio.pdf 《Scalable IO in Java》是java.util.concurrent包的作者,大师Doug Lea关于分析与构建可伸缩的高性能IO服务的一篇经典文章,在文章中Doug Lea通过各个角度,循序渐进的梳理了服务开发中的相关问题,以及在解决问题的过程中服务模型的演变与进化,文

页面适应电脑和手机屏幕initial-scale 1:0 user-scalable=yes
[html] view plain copy <meta name="viewport" content
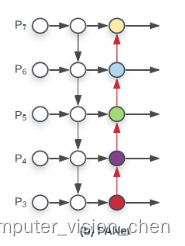
EfficientDet:Scalable and Efficient Object Detection中文版 (BiFPN)
EfficientDet: Scalable and Efficient Object Detection EfficientDet:可扩展和高效的目标检测 摘要 模型效率在计算机视觉中变得越来越重要。本文系统地研究了用于目标检测的神经网络架构设计选择,并提出了几个关键的优化方法来提高效率。首先,我们提出了**加权双向特征金字塔网络(BiFPN),可以轻松快速地进行多尺度特征融合;其次,我们
【ICCV 2022】(MAE)Masked Autoencoders Are Scalable Vision Learners
何凯明一作文章:https://arxiv.org/abs/2111.06377 感觉本文是一种新型的自监督学习方式 ,从而增强表征能力 本文的出发点:是BERT的掩码自编码机制:移除一部分数据并对移除的内容进行学习。mask自编码源于CV但盛于NLP,恺明对此提出了疑问:是什么导致了掩码自编码在视觉与语言之间的差异?尝试从不同角度进行解释并由此引申出了本文的MAE。 恺明提出一种用于计
论文阅读: Masked Autoencoders Are Scalable Vision Learners掩膜自编码器是可扩展的视觉学习器
Masked Autoencoders Are Scalable Vision Learners 掩膜自编码器是可扩展的视觉学习器 作者:FaceBook大神何恺明 一作 摘要: This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision.

Sequential Modeling Enables Scalable Learning for Large Vision Models
目录 一、论文速读 1.1 摘要 1.2 论文概要总结 二、论文精度 2.1 论文试图解决什么问题? 2.2 论文中提到的解决方案之关键是什么? 2.3 论文提出的架构和损失函数是什么? 2.4 用于定量评估的数据集是什么?代码有没有开源? 2.5 这篇论文到底有什么贡献? 2.6 下一步呢?有什么工作可以继续深入? 一、论文速读 1.1 摘要 本
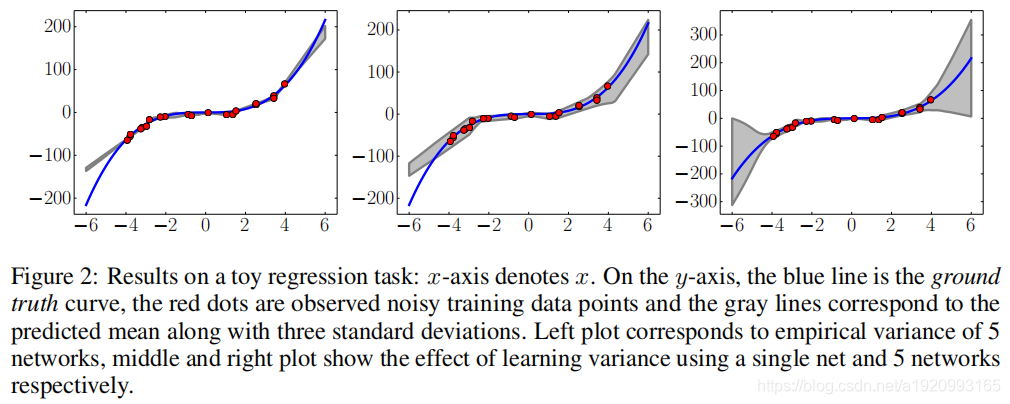
Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles
使用深度神经网络集合预测点的分布 1.摘要 深度神经网络是一个在处理黑盒优化问题时的很好的预测器。然而量化神经网络的不确定性的问题仍然具有挑战且有待解决。 贝叶斯神经网络是目前最先进的估计预测不确定性的方法,然而这些方法都需要对训练过程进行重大修改,与标准(非贝叶斯)神经网络相比计算昂贵。 我们提出了一种贝叶斯神经网络的替代方案,它易于实现,易于并行,并产生高质量的预测不确定性估计。通过分
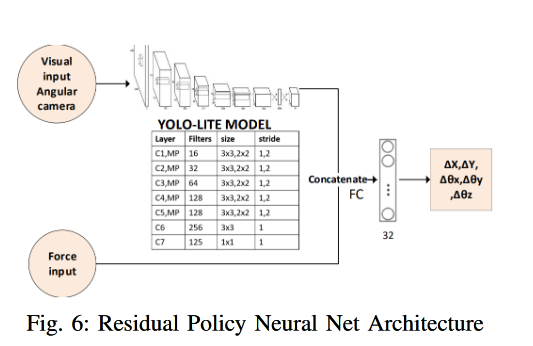
InsertionNet - A Scalable Solution for Insertion 论文阅读
InsertionNet - A Scalable Solution for Insertion 论文阅读 论文地址:InsertionNet - A Scalable Solution for Insertion | IEEE Journals & Magazine | IEEE Xplore 一、要解决什么问题? We introduced a novel framework fo
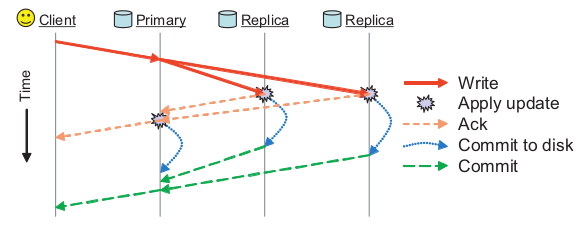
ceph翻译 Ceph: A Scalable, High-Performance Distributed File System
Ceph: A Scalable, High-Performance Distributed File System Ceph:一个可扩展,高性能分布式文件系统 Sage A. Weil Scott A. Brandt Ethan L. Miller Darrell D. E. Long Carlos Maltzahn 摘要 我们开发Ceph,一个分布式文件系统,它提供了优秀的性能
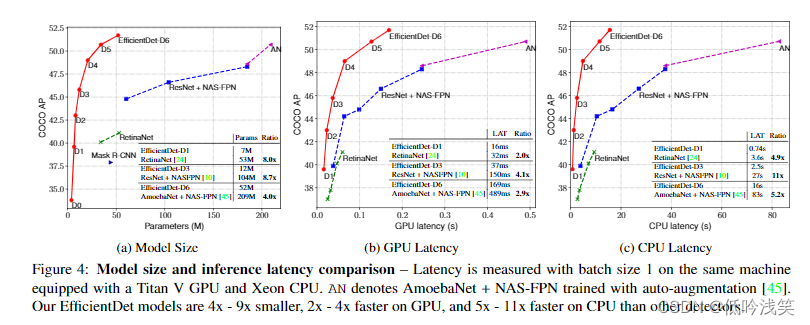
EfficientDet: Scalable and Efficient Object Detection
CVPR2020 V7 Mon, 27 Jul 2020 引用量:243 机构:Google 贡献:1>提出了多尺度融合网络BiFPN 2>对backbone、feature network、box/class prediction network and resolution进行复合放缩,有着不同的性能表现,以适应不同资源和应用。 view