本文主要是介绍【计算机图形学】General Flow as Foundation Affordance for Scalable Robot Learning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
对General Flow as Foundation Affordance for Scalable Robot Learning的简单理解
文章目录
- 1. 做的事
- 2. 作为Affordance的General Flow
- 2.1 General Flow Affordance
- 2.2 General Flow属性
- 3. 智能体不可知的和规模感知的General Flow预测
- 3.1 General Flow标签获取
- 3.2 规模感知的预测模型
- 3.3 可缩放的重平衡Loss计算
- 3.4 增强Zero-Shot的鲁棒性
1. 做的事
文章预测的“流”提供了可运动的几何和物理引导,进而促进在真实世界场景中稳定的零样本技能迁移。文章框架特征的优势在于:
-
Scalability
-
Universality:可以操纵多个物体类别,包括刚性、铰接、软的物体(布料等)
-
Stable Skill Transfer:提供稳定的动作推理
2. 作为Affordance的General Flow
2.1 General Flow Affordance
操纵任务由功能性抓取和后续动作组成。文章主要关注后面的任务。引入“General Flow”作为Affordance,为下游任务在几何和物理方面提供综合的、可运动的引导。
General Flow定义:给定感知观察 S S S,任务指令 I I I,对 N q N_q Nq个三维查询点 Q ∈ R N q × 3 Q∈R^{N_q×3} Q∈RNq×3,general flow F ∈ R N q × T × 3 F∈R^{N_q×T×3} F∈RNq×T×3表示这些点在未来 T T T个时间步下的轨迹。

2.2 General Flow属性
提供了以下好处:
-
Scalability:General Flow的概念可以直接在不同的数据上使用,如人类视频数据集,规避对大规模真实机器人数据访问的挑战。将物理表示为未来策略是一种资源高效的运动力学抽象
-
Universality:跨多个物体类别的物理运动的统一抽象表示。能够为广泛的应用提供支持,预测取决于语言指令,允许单个场景的多种执行行为
-
Stable Skill Transfer:来自两个方面的好处。首先是General Flow比起预训练和粗运动轨迹来说,提供了丰富的几何和物理引导。其次是对真实世界数据的依赖消除了sim-to-real的gap。
考虑到这些点,作者假设General Flow为基础机器人学习提供了可伸缩的预测目标,类似于大语言模型中的“文本标记”(读不懂)
3. 智能体不可知的和规模感知的General Flow预测
首先设计了pipeline从RGBD人类视频数据集中提取flow标签。为管理可变的轨迹长度,考虑真实世界噪声,聚集了核心设计以提升模型的对预测规模的感知和鲁棒性。
3.1 General Flow标签获取
介绍了从两种不同数据集中获取flow标签的方法。
3D注释数据集:利用数据集的详细3D标签,随机采样运动物体上的点,使用GT pose和相机参数计算未来位置
无注释的RGBD视频:执行HOI(人类-物体-交互)分割获得运动物体的Mask。在Mask内采样点,使用TAP(Tracking Any Point)来追踪未来的2D轨迹。General Flow的3D标签通过在空间和时间维度进行反向投影确定。
3.2 规模感知的预测模型
自然语言指令 I I I,场景点云特征 P s ∈ R N s × 6 P_s∈R^{N_s×6} Ps∈RNs×6(XYZ位置+RGBD属性),空间查询点 N q ∈ R N q × 3 N_q∈R^{N_q×3} Nq∈RNq×3。目标是预测一个轨迹集,或“流”,表示为 F ∈ R N q × T × 3 F∈R^{N_q×T×3} F∈RNq×T×3。For the i-th query point p i ∈ R 3 i ∈ R^3 i∈R3 , its trajectory is defined as F i ∈ R T × 3 F_i ∈ R^{T ×3} Fi∈RT×3 , with the absolute position
at time t t t represented as F t i ∈ R 3 F_t^i ∈ R^3 Fti∈R3 for t = 1 , 2 , ⋅ ⋅ ⋅ , T t = 1, 2, · · · , T t=1,2,⋅⋅⋅,T。 F 0 i F^i_0 F0i是查询点 p i p^i pi的输入位置。因为预测相对位移的效果会比预测绝对唯一的要好,所以预测 △ p t i = F t i − F t − 1 i △p^i_t=F^i_t-F^i_{t-1} △pti=Fti−Ft−1i for t = 1 , 2 , . . . , T t=1,2,...,T t=1,2,...,T。每个查询点 p i p_i pi的策略长度被定义为 L e n ( F i ) = ∑ t = 1 T ∣ ∣ △ p t i ∣ ∣ Len(F^i)=\sum^T_{t=1}{||△p^i_t||} Len(Fi)=∑t=1T∣∣△pti∣∣。
real-world flow预测的主要挑战是,不同查询点策略长度的方差。在打开保险柜任务中,门上的点的策略会比保险柜体上的策略要长。为解决这个问题应用Total Length Normalization(TLM)来均匀缩放轨迹。对于预测目标 { △ p t i ∣ t = 1 , . . T } \{△p^i_t|t=1,..T\} {△pti∣t=1,..T},定义缩放 L i L_i Li和归一化目标 { △ n t i } \{△n^i_t\} {△nti}为:$△ni_t=\frac{△pi_t}{L_i} $ where L i = L e n ( F i ) L_i=Len(F^i) Li=Len(Fi)。消融实验证明TLM的归一化方法比其他方法更好。
接着,描述模型结构如下

指令将通过CLIP编码器转化为予以特征,并通过MLP压缩维度(得到维度 D I D_I DI),与点的特征进行对齐。
场景点云 P s P_s Ps包括3D位置和RGB值。查询点云 P q P_q Pq用一个可学习的Embedding E ∈ R 3 E∈R^3 E∈R3来代表RGB值,它作为一个查询标识符,对所有实例查询点保持不变。
首先连接对齐的文本特征和点云特征,连接场景点特征和查询点特征,构建了合并点云特征 P M ∈ R ( N s + N q ) × ( 3 + 3 + d I ) P_M∈R^{(N_s+N_q)×(3+3+d_I)} PM∈R(Ns+Nq)×(3+3+dI)。合并特征通过PointNeXt进行编码,通过一个输出头来提取几何信息,查询点的特征被作为Conditional VAE的条件变量,生成最终的预测 △ n ^ t △\hat{n}_t △n^t和 L ^ \hat{L} L^。
3.3 可缩放的重平衡Loss计算
对于打开保险箱任务,大部分点是静态的(保险箱箱体上的点)。直接用这些数据训练会导致预测平稳轨迹剧烈都懂,这是由于数据集的规模不平衡导致的。为了避免这个问题,在数据集之间应用scale rebalance。
首先,使用K-Means算法通过规模 L i L^i Li来聚类每个数据点的general flow。最终获得 N r N_r Nr个聚类。表示每个聚类的原始点比例为 { r i ∣ i = 1.. N r } \{r_i|i=1..N_r\} {ri∣i=1..Nr}。除了具有最多点数量的聚类外,对所有其他的聚类执行重新采样,重采样分布通过:
r ‾ i = e r i / τ ∑ i = 1 N r e r i / τ \overline{r}_i=\frac{e^{r_i/\tau}}{\sum^{N_r}_{i=1}e^{r_i/\tau}} ri=∑i=1Nreri/τeri/τ
从而得到相对于原始分布更平滑的分布,设置 τ = 1 \tau=1 τ=1。
最后的loss由重建loss,规模回归loss,VAE KL-divergence loss组成。为了最小化累积错误,使用MSE loss来恢复累积位移。最后loss为:
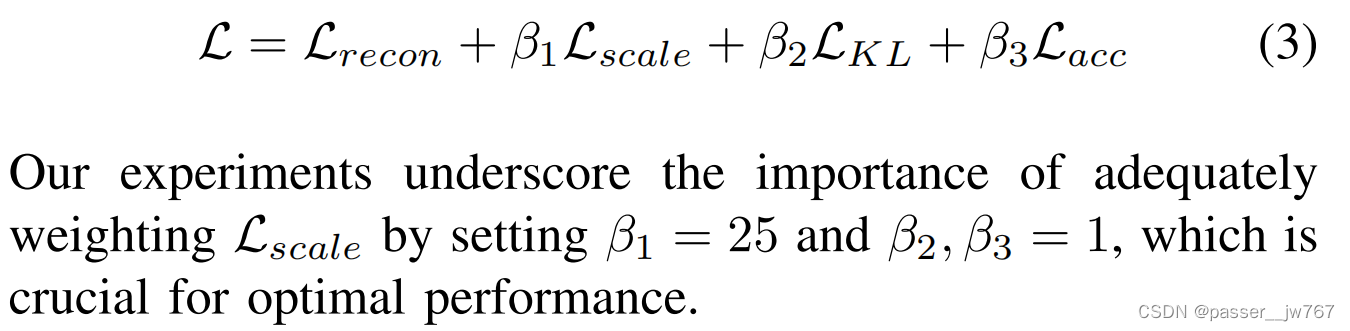
3.4 增强Zero-Shot的鲁棒性
两种技术增强零样本泛化鲁棒性:
-
Hand Mask(HM)增强:在训练数据中遭遇人手遮挡,在deployments中遭遇机械臂遮挡。因此,最关键的是提升模型对自遮挡的弹性。为了解决此问题,对于输入场景的点云,操纵手部点的存在,选择了三种方法,分别赋予0.5,0.2和0.3的概率:删除所有手部点、保持所有的手部点、采样手部随机的锚点并保留与锚点>12厘米的点。
-
Query Point Sampling(QPS)增强:不同下游应用需要不同的点采样方法。因此模型需要适应不同的查询点分布,以次增强训练过程。在每一次训练迭代中,用两种规则来选定查询子集,基于0.7和0.3的概率:随机采样;随机采样锚点并选择离锚点最近的特定数量的点
实验证明了这种增强的有效性
这篇关于【计算机图形学】General Flow as Foundation Affordance for Scalable Robot Learning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!